






转录组广义上指在某一生理条件下,细胞内所有转录组产物的集合,包括:mRNA、ncRNA、rRNA等;狭义上指所有mRNA的集合。因为测的是所有的RNA,因此数据量庞大。以植物为例,基本上每个物种的转录组测出来的基因数目都有上万条。而我们进行RNA-seq的主要目的就是寻找引起处理和对照之间表型差异的关键基因,也就是要通过一些生物信息的分析,从上万条基因中找出2-3个关键基因。因此转录组数据分析的核心思想就是不断的缩小关键基因的范围。
在缩小关键基因的范围时,目前主要有以下三种方法(图1):差异表达分析,聚类分析,WGCNA分析。在我们对count矩阵进行表达定量以后,我们会得到对count矩阵进行矫正后的TPM或者FPKM表达矩阵。TPM和FPKM矩阵中包含了该物种所有基因的表达量。一般都含上万条基因,因此我们要根据自己的实验目的对TPM和FPKM矩阵进行基因数目的缩小,已得到一些关键基因。
第一种缩小基因数目的方法就是对count矩阵进行差异表达分析,根据Fold change和Pvalue筛选出在处理组与对照组之间的差异表达的基因,这样就就可以对基因的数目进行缩小了,因为设置好参数后,差异表达的基因数目往往在1000-2500不等。这样就从上万条基因的范围缩小到了1000-2500的基因范围。
第二种缩小基因数目的方法是进行聚类分析,聚类分析就是根据各个基因的表达量进行聚类,如果基因的表达趋势相似,那就会聚在一起。聚类可以分为热图的聚类以及时序的聚类,时序聚类分析往往用于比较不同时段差异。聚类完成后就可以得到多个cluster,然后根据实验目的和各个cluster的表达模式选择自己想要的关键cluster进行研究,这样也达到了缩小基因数目的目标。
第三中缩小基因数目的方法是加权基因共表达网络分析(WGCNA),但是与前面2种方法不同,WGCNA对样本数目有一定的要求,进行WGCNA分析时的样本数目至少要有15个,因此我们在实验设计是,如果要做WGCNA分析是,一定要多设置处理或者生物学重复数。

图1
经上述生信分析方法,我们虽然讲关键基因的范围从几万条缩小到了几千条甚至是几百条,但从上千条基因里面寻找到2-3条关键基因仍然是个挑战,因此我们还需要对其进行范围的缩小。目前常用的方法是进行富集分析(图2)。
所谓富集分析就是看看经过我们第一步缩小后的上千条基因在那些生物功能(GO富集分析)或者那些通路(KEGG富集分析)。经过富集分析后,我们就可以从富集到的GO term或者Pathway中寻找关键基因,通过一个GO term和Pathway里面的基因往往小于100个,至此我们就又将上千条基因的范围缩小到了100条以内。但是我们还需要将关键的GO term或者Pathway里面的基因进行缩小,直到缩小到2-3个关键基因为止。对GO term或者Pathway里面的基因进行范围的缩小也有两个方法,一种方法是根据基因的注释或者文献来找到GO term或者Pathway里面的关键基因(2-3个),另一种方法需要有相应的表型数据,与GO term或者Pathway里面基因进行相关性分析,找出与表型高度相关的基因。例如在缺磷胁迫处理90天后会引起幼苗的不定根数量增加,因此我们需要在90天时测定各组幼苗不定根的数目,同时也在90天时采样进行RNA-seq。对RNA-seq的数据进行差异表达分析和GO富集分析后,我们发现到了一个与淀粉相关的GO term 被显著的富集,所以就可以将这个与淀粉相关的GO term里的基因与不定根数目进行相关性分析,从而找到了这个淀粉相关的GO term里面与不定根数目具有高度相关性的2-3个关键基因。
当然,我们也可以拿聚类出来的cluster里面的基因或者WGCNA分析出来的module里面的基因进行富集分析,从而找到关键基因。
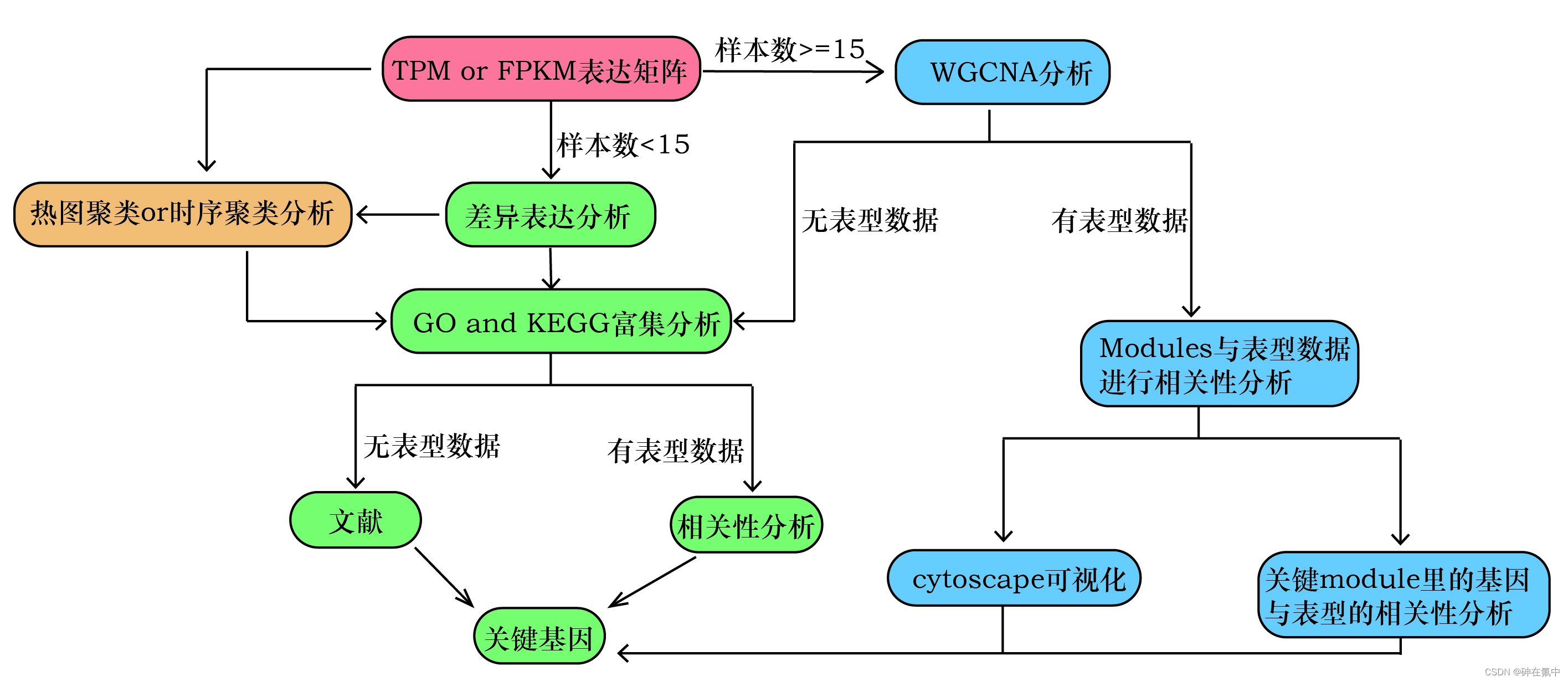
图2
若样本数目大于15,且有相应的表型数据,那么我们就可以直接拿表型数据与WGCNA分析出来的各个module进行相关性分析,找出与表型具有高度相关性的模块,然后拿module里面的基因用cytoscape进行网络可视化分析,从而找到关键的hub基因;也可拿module里面的基因与表型再次进行相关性分析,从而找出某个module里面与表型高度相关的2-3个各关键基因。
在找出2-3个引起处理组和对照组表型差异的关键基因后,我们还需要揭示引起这2-3个关键基因在处理组和对照组之间变化的分析机制(图3)。在DNA层面的分子机制有单核苷酸的变异(SNP),碱基的插入和缺失(InDel),染色体结构的变异(SV),DNA在启动子区域的甲基化等;在RNA层面的分析机制有由信号调控引起的差异表达,可变剪切(AV),以及RNA的修饰等;在蛋白层面的分子机制有翻译丰度的变化以及蛋白质折叠等。
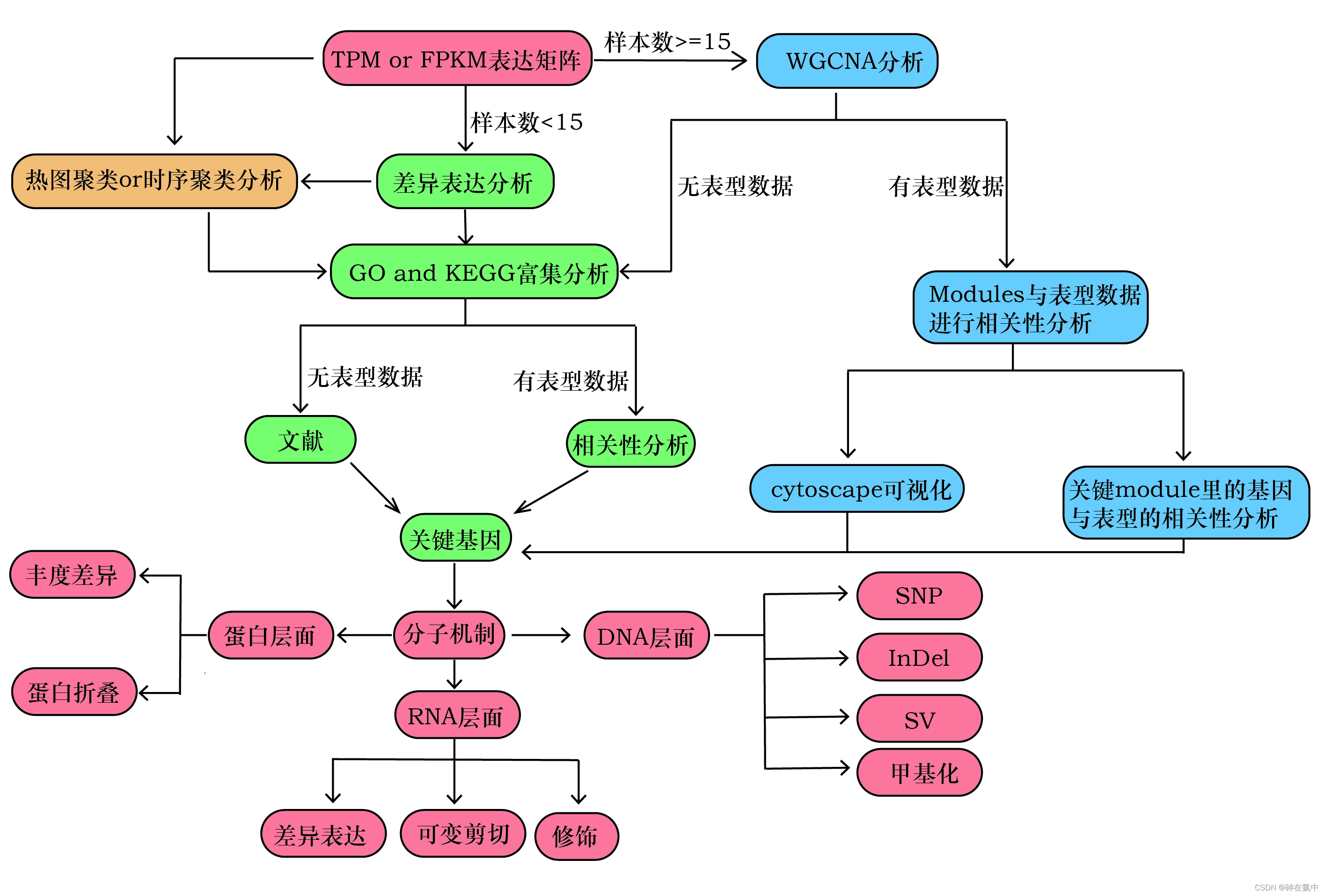
图3














 5677
5677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









