






 本文介绍了Python自然语言处理工具HanLP的入门教程,包括HanLP简介、安装步骤、分词与词性标注的使用,以及关键词提取方法。重点展示了如何在Python中安装和使用HanLP,适合初学者快速上手。
本文介绍了Python自然语言处理工具HanLP的入门教程,包括HanLP简介、安装步骤、分词与词性标注的使用,以及关键词提取方法。重点展示了如何在Python中安装和使用HanLP,适合初学者快速上手。
更多内容点击查看Python 实战 | 文本分析工具之HanLP入门
Python教学专栏,旨在为初学者提供系统、全面的Python编程学习体验。通过逐步讲解Python基础语言和编程逻辑,结合实操案例,让小白也能轻松搞懂Python!
>>>点击此处查看往期Python教学内容
本文目录
一、前言
二、HanLP简介
三、安装HanLP
四、轻松使用HanLP
五、结束语
六、相关推荐
本文共6630个字,阅读大约需要17分钟,欢迎指正!
Part1前言
上期文章我们介绍了文本分析中两个文本关键词提取的方法,并使用 Python 的第三方库 jieba 实现相应的功能。jieba 对于初学者是友好的、简单易上手,实际上除了 jieba,在自然语言处理开源界还有一些主流的工具也值得关注,比如 HanLP、NLTK、SnowNLP 等等,这些开源工具都有各自的特点,具体的性能对比可以参考一些开源测评。本文主要为大家介绍 HanLP 这个工具,一方面是 HanLP 的发展速度是比较迅猛的,对于想要研究或进行文本分析的学者,其无疑是一个很好的选择;另一个方面是得益于 Python 简洁的设计,使用 Python 调用 HanLP 可以节省时间,这也有助于入门 HanLP。
Part2 HanLP 简介
HanLP 是一个由中国开发者何晗(hankcs)于 2014 年开发的自然语言处理库,自发布之后,HanLP 不断更新迭代,进行了许多新功能和性能的优化,Github 上 Star 数量已超过 3w,其在主流自然语言工具包中非常受欢迎。HanLP 具有丰富的功能,可以进行一系列文本分析任务,比如词法分析(分词、词性标注、命名实体识别)、句法分析、文本分类/聚类、信息抽取、语义分析等等。发展至今,HanLP 已经衍生出了 1.x和 2.x 两大版本,本文介绍的是主打追求经典、稳定、高效的 1.x 版本,并且 1.x 版本内部的算法经过了学术界、工业界的考验,已有出版的配套书籍《自然语言处理入门》(作者就是 HanLP 库的开发者),感兴趣的读者可以深入学习。
由于这是第一篇介绍 HanLP 的文章,本文更加侧重以入门为主,主要介绍了在 Python 中安装并使用 HanLP1.x 的方法,以及如何获取 HanLP 的分词器进行分词,当然我们也会在后面的文章中介绍更多关于 HanLP 的功能。
HanLP 开源地址:https://github.com/hankcs/HanLP
Part3 安装 HanLP
在实现 Hanlp 功能之前,首先需要在 Python 中安装它。虽然 HanLP 库是基于 Java 开发的,但也提供了 Python 接口,pyhanlp 就是 HanLP1.x 的 Python 接口,可以自动下载与升级 HanLP1.x,需要注意的是,pyhanlp 兼容的 Python 版本 <= 3.8。
另外还有一点,pyhanlp这个包是依赖于 Java 和 Jpype(提供了 Python 与 Java 之间的桥梁,使得 Python 可以直接访问 Java 类),经过笔者的测试,使用 conda 作为包管理器是更加高效的,这也是官方推荐的安装方法,因为 conda 支持自动安装 Java,不用再额外安装 C++ 编译器;否则就需要手动安装,而仅仅使用 pip 是不能自动完成的。
笔者强烈建议使用 Miniconda,如果你还没有安装它,可以参考这篇文章Python 环境冲突烦?环境移植难?我用 Miniconda,其中还介绍了管理 Python 包以及环境的移植的问题,也许可以帮你解决困扰。
如果你已经装有 Miniconda,且当前环境的 Python 高于 3.8 版本 ,笔者建议新建一个 Python 环境,并在该环境中执行后续命令。代码如下:
# 创建一个名为 xxx 的 Python 环境,版本号为 3.x
conda create -n xxx python=3.x #安装过程中需要根据提示键入命令才能完成
# 新环境安装完成后,需要先使用命令激活,xxx 为环境名
conda activate xxx
安装 Miniconda 并创建虚拟环境之后,先使用如下命令安装依赖的包,代码如下:
conda install -c conda-forge openjdk python=3.8 jpype1=0.7.0 -y
'''
1. openjdk 是 Java 开发工具包的开源版本
2. python=3.8 配置 python 版本为 3.8
3. jpype1=0.7.0 安装指定版本的 jpype1 库
'''
这个安装过程需要耐心等待一段时间。另外,如果有读者运行这行命令时遇到如下问题:
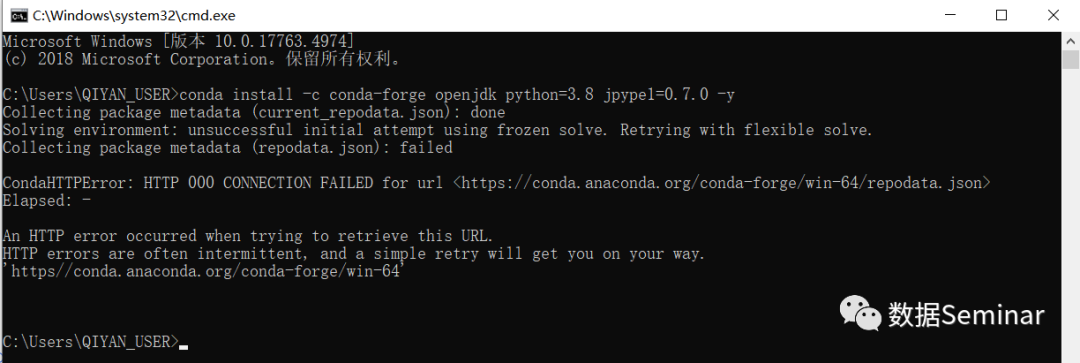
可能原因:需要安装的软件包与环境中其他的软件包有冲突
这里提供两个解决办法:
-
将 conda 更新到最新版本,再执行该命令
conda update conda
conda install -c conda-forge openjdk python=3.8 jpype1=0.7.0 -y
-
如果上一步仍未解决这个问题,可以创建一个新的 conda 环境,在该环境中安装软件包
# 创建一个名为 xxx 的 Python 环境,版本号为 3.x
conda create -n xxx python=3.x
# 激活虚拟环境,xxx 为环境名
conda activate xxx
conda install -c conda-forge openjdk python=3.8 jpype1=0.7.0 -y
我们接着安装pyhanlp库,代码如下:
pip install pyhanlp
然后,输入 hanlp 来验证本次安装,第一次运行会自动下载 HanLP 的 jar 包和数据包到 pyhanlp 的系统路径中。
如果遇到 Java 相关的问题,如下:
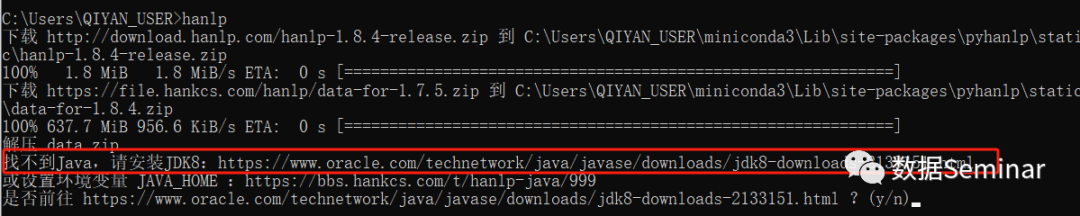
这就表示需要安装 Java 环境(也可能是环境变量的设置问题,笔者建议重新安装),推荐选择 JDK 8 以上版本。
官网:https://www.oracle.com/java/technologies/downloads/#java8
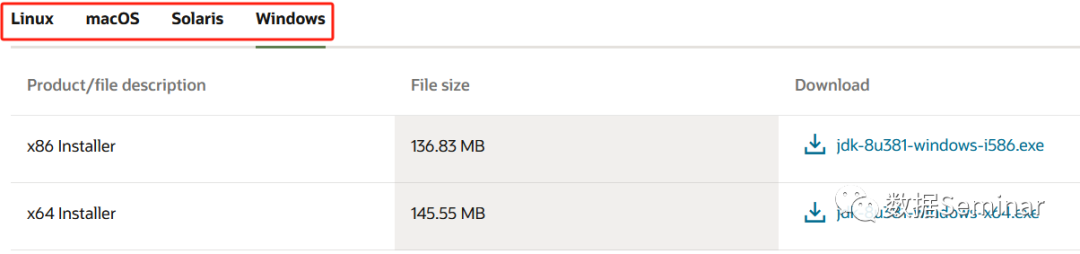
选择符合要求的版本下载并完成安装,然后还需设置 JAVA_HOME 环境变量,参考教程:JDK 环境变量配置[1]。
至此,在命令行输入hanlp验证安装已成功。
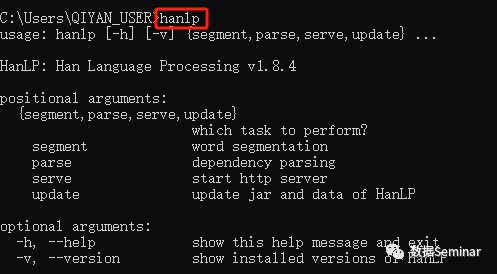
对于入门 HanLP 来说,安装花费的时间应该是最多的...如果你只需要两行代码就成功了,那么你是幸运的。如果你在安装过程中遇到了其他问题,也欢迎前往我们的 Python 交流群提问讨论。
Part4 轻松使用 HanLP
之所以说入门 HanLP 是轻松的,这是因为在完成安装后,HanLP 的常用功能可以通过 HanLP 这个类来调用,不需要创建实例。比如,我们看一下 HanLP 的分词功能如何实现。代码如下:
from pyhanlp import *
print(HanLP.segment('可以说,文心大模型为百度AI原生战略奠定了坚实的技术基础。'))
结果如下:
![]()
上述代码中HanLP.segment()就是通过工具类 HanLP 来调用分词功能。需要注意一点,如果想要输出分词的结果,就要添加print语句,否则返回的结果是一个 Java 的 ArrayList 对象(<jpype._jclass.java.util.ArrayList at 0x1c1f2cd0c40>)。
可以看到上图结果中返回了每个分词结果和其对应的词性,这是因为 HanLP 默认执行词性标注,如果这样的呈现方式不直观,也可以这样做:
for word in HanLP.segment('可以说,文心大模型为百度AI原生战略奠定了坚实的技术基础。'):
print(f'{word.word} \t {word.nature}')
结果如下:

如果不需要词性标注功能,可以设置禁用,代码如下:
# 不显示词性
HanLP.Config.ShowTermNature = False
print(HanLP.segment('可以说,文心大模型为百度AI原生战略奠定了坚实的技术基础。'))
结果如下:
![]()
在上述分词过程中,我们是直接从封装好的 HanLP 类中获取分词器的,使用HanLP.segment()来进行分词,会获取默认的标准分词器——viterbi,这也是最短路径分词(HanLP 最短路径的求解采用 viterbi 算法),除此以外,这种方式还可以获取其他几种分词器,如双数组trie树(dat)、条件随机场(crf)、感知机(perceptron)和 N-最短路径(nshort)。现在我们想将分词器更改为条件随机场,再进行分词,代码如下:
HanLP.Config.ShowTermNature = False
# 更改分词器为 条件随机场 crf
CRFnewSegment = HanLP.newSegment('crf')
print(CRFnewSegment.seg('可以说,文心大模型为百度AI原生战略奠定了坚实的技术基础。'))
#输出内容
'''
[可以, 说, ,, 文心, 大, 模型, 为, 百度AI原生, 战略, 奠定, 了, 坚实, 的, 技术, 基础, 。]
'''
可以看到,使用newSegment函数并传入需要获取的分词器的英文名称就可以更改分词器了。可以看到此时“百度AI原生”被分为了一个词,这是比默认分词器得到的结果更接近理想状态的。
另外,还有一种方式可以获取 HanLP 中的分词器,就是通过JClass 直接获取 java 类再使用,这种方式除了可以上面提到的五种分词器,还能获取一些其他分词器,比如 NLP 分词器、索引分词等等。现在我们想使用 NLP 分词器来分词,看一下效果,代码如下:
NLPTokenizer = JClass('com.hankcs.hanlp.tokenizer.NLPTokenizer')
print(NLPTokenizer.segment('可以说,文心大模型为百度AI原生战略奠定了坚实的技术基础。'))
# 输出内容
'''
[可以, 说, ,, 文心大模型, 为, 百度, AI, 原生, 战略, 奠定, 了, 坚实, 的, 技术, 基础, 。]
'''
从输出结果可以看到,“文心大模型”被分成了一个词,这就是我们希望看到的。实际上,NLP 分词器默认模型训练自 9970 万字的大型综合语料库,是目前已知范围内全世界最大的中文分词语料库,可以想象到,语料库的实际规模是可以决定实际分词效果的,并且模型是具有新词识别功能的,这在一定程度上也提高了分词的效果。另外,如果你需要分析的是特定领域的、针对性较强的文本数据,你还可以在自己的语料库上训练新模型来适应这个新领域。
除了最基本的分词,我们还可以进行关键词提取,提取的文本的内容来自雷锋网文章《百度亮出「武器库」,领跑 AI 原生应用之战》,关键词个数为 5 个,代码如下:
# 读取文本文件,进行简单清洗
with open('./新闻文本.txt', 'r', encoding='utf-8') as file:
# 去除换行符
text = file.read().replace('\n', '')
print(HanLP.extractKeyword(text, 5))
# 输出内容
'''
[应用, AI, 模型, 百度, 李彦宏]
'''
值得一提的是,工具类 HanLP 的静态函数extractKeyword()是对TextRankKeyword.getKeywordList的封装,而TextRankKeyword.java这个文件就是实现 TextRank 算法的,所以HanLP.extractKeyword()其实就是基于 TextRank 算法来提取关键词的。当然,HanLP 也可以基于 TF-IDF 算法来提取关键词,这里就不再介绍了,这两种算法的原理在上期文章有详细的介绍,感兴趣的读者可以自行研究。
Part5 结束语
💡 HanLP 不仅是一个高性能的中文分词工具,还可以进行词性标注、命名实体识别、 依存句法分析等等,本文只是对 HanLP 的基本功能进行了简要介绍,后续我们也会介绍更多关于 HanLP 的内容。如果您在实操过程中遇到了问题或者对文本内容存有疑虑,不妨留言提问,笔者会根据情况提供帮助哦~
另外,如果您也有关于文本分析的实操经验,欢迎给我们留言交流您使用的方法或工具,让我们一起探索更多的技术!
如果你想学习各种 Python 编程技巧,提升个人竞争力,那就加入我们的数据 Seminar 交流群吧(点击阅读原文Python 实战 | 文本分析工具之HanLP入门,加入数据seminar-Python交流学习群),欢迎大家在社群内交流、探索、学习,一起进步!同时您也可以分享通过数据 Seminar 学到的技能以及得到的成果。
参考资料
[1]JDK 环境变量配置: https://www.cnblogs.com/nicholas_f/articles/1494073.html

















 5730
5730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









