







 超级会员免费看
超级会员免费看
任务描述:本教程将通过深度学习的方式实现一个简单的视觉问答模型,视觉问答的任务内容是将一张图片和一个自然语言问题作为输入,结合这两种信息,机器生成一条自然语言答案。本教程通过数据准备,视觉问答模型构建,视觉问答模型训练,视觉问答模型评估,视觉问答模型预测等几个方面展示实现视觉问答系统的整个流程。如下图即为视觉问答的示例。

- 运行环境:Python3.7环境下测试了本教程代码。需要的第三方模块和版本包括:
tensorflow==1.14.0 keras==2.2.5 tqdm==4.47.0 numpy==1.16.0 matplotlib==3.2.2 pandas==1.1.0 spacy==2.3.2 h5py==2.10.0 - 方法概述:本教程包括以下内容:从原始的数据文件中加载数据、对数据进行预处理、文本与图像特征处理、模型训练、模型评估、结果展示。在训练过程中通过可视化监督训练过程。
说明:目前本文档仅作为示例,为了加快训练速度模型较为简单,设置的Epoch数也较少,因此导致模型性能较低。其中对于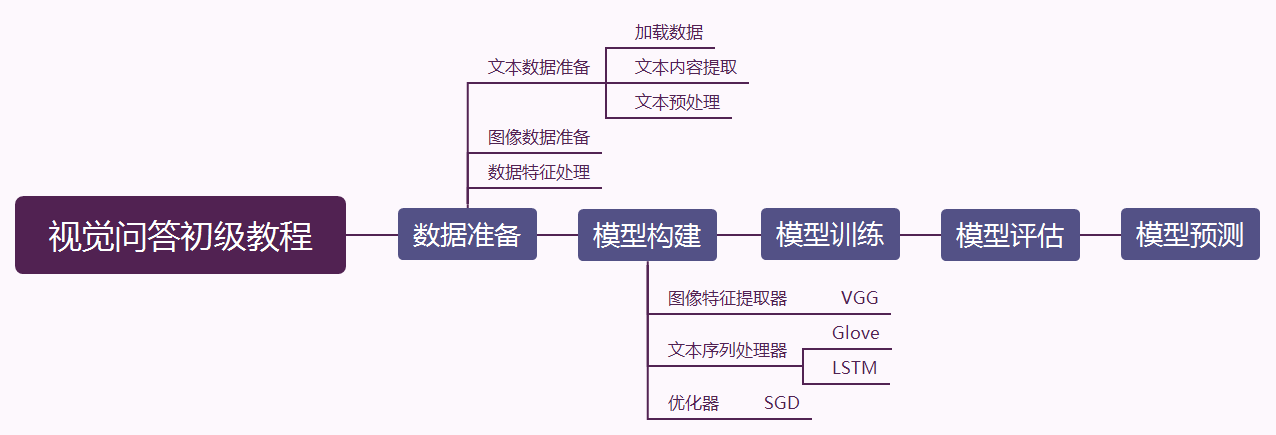

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











