







Multi-Modal Sarcasm Detection in Twitter with Hierarchical Fusion Model(2019 ACL)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
背景
反语(Irony)和讽刺(Sarcasm)是社会媒体中常用的修辞方法。反语是指运用跟本意相反的词语来表达此意,却含有否定、讽刺以及嘲弄的意思,是一种带有强烈感情色彩的修辞格,比如“I absolutely love to be ignored !” 讽刺则是用比喻、夸张等手法对人或事进行揭露、批评或嘲笑,比如“Good thing Trumpis going to bring back all those low education highpaying jobs.”。关于反语和讽刺的关系,可以认为讽刺是包含情绪(比如攻击性情绪)的一种反语[9]。为方便起见,后文统一称之为“反讽”,不再对反语和讽刺进行区分。
反讽识别任务源于文本任务,其目的是:判断一段文档是都含有反讽表达。在文本反讽任务中,主要分为上下文有关反讽与上下文无关反讽。上下文无关的反讽识别仅通过分析目标句判断是否为反讽,不需要结合上下文信息;而上下文有关的反讽识别则通过分析目标句与其上下文来判断是否为反讽。
在上下文无关反讽任务中,占比最大的是“前后情感矛盾式的反讽”(据统计占比69.9%),常用“词对”或“半句对”捕捉反讽的特点。
在上下文有关的反讽任务中,分为使用复杂上下文信息和简单上下文信息的方法。
上述方法仅仅是面向文本的反讽识别,目前,越来越多的社交平台使用多模态信息表达自己的情感,因此,仅适用文本进行反讽识别已不足以满足需求。本文提出了基于 Twitter 的数据集,并提出了层次融合模型,准确率达到83.44%。
一、摘要
文章重点关注了由文本和图像组成的推文的多模态讽刺检测。将文本特征、图像特征和图像属性视为三种模式,并提出了一个多模态的层次融合模型来解决这一任务。首先提取图像特征和属性特征,然后利用属性特性和双向LSTM网络来提取文本特征。然后重建三种模态的特征,并融合成一个特征向量进行预测。(主要贡献)创建了一个基于推特的多模态讽刺检测数据集。对数据集的评估结果证明了提出模型的有效性和这三种模态的有效性(后面有消融实验)。
原文:
“our fusion strategy successfully refines the representation of each modality and is significantly more effective than simply concatenating the three types of features.”
文章的主要贡献:
- 提出了层次融合模型解决 多模态反讽识别 的挑战;
- 创建了一个新的多模式反讽检测数据集(基于 Twitter);
- 定量地展示了每种模态在反讽检测中的意义。为了充分释放图像的潜力,考虑图像属性(—— 一个弥合文本和图像之间的差距的高级抽象信息)。
二、相关工作
- 反讽识别(文本反讽检测)
- 其它多模态任务(包括多模态语义分析,融合,对齐,VQA,图像情感识别等)
三、层次融合模型
在图像和文本的基础上,增加了图像属性模态(Image attribute)(被定义为图像内容的高级概念,用于提高模型性能),然后基于上述三种模态提出了一种多模态层次融合模型,模型的整体框架图如下:
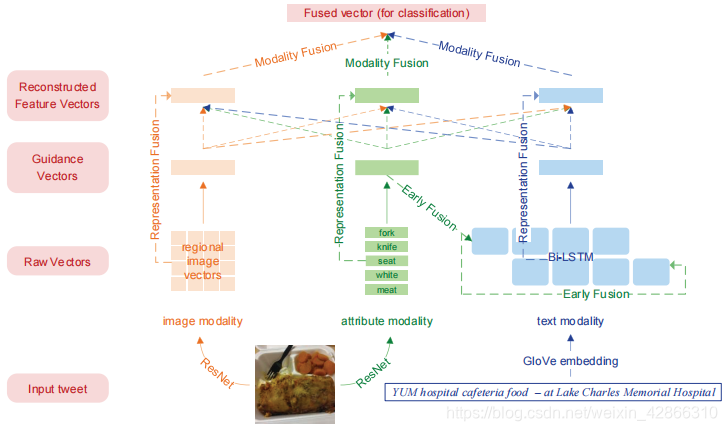
编码层
下面将分别从原始向量(raw vectors)和 指导向量(guidance vectors)的获取进行说明。
图像特征表示
使用预训练和微调的ResNet-50 V2 模型获取原始向量。输入一张图片,将其调整为
448
×
448
448\times 448
448×448,并将其划分为
14
×
14
14\times 14
14×14 的区域向量。每个region
I
i
(
i
=
1
,
2
,
.
.
.
,
196
)
I_i(i=1,2,...,196)
Ii(i=1,2,...,196) 通过 ResNet 模型,得到区域特征表示,也就是原始向量。
v
r
e
g
i
o
n
i
=
R
e
s
N
e
t
(
I
i
)
v_{{region}_i}=ResNet(I_i)
vregioni=ResNet(Ii)
图像的指导向量为所有region向量的平均,即:
v
i
m
a
g
e
=
∑
i
=
1
N
r
v
r
e
g
i
o
n
i
N
r
v_{image}=\frac{\sum_{i=1}^{N_r}v_{{region}_i}}{N_r}
vimage=Nr∑i=1Nrvregioni
其中,
N
r
N_r
Nr 是region的个数,即:
N
r
=
196
N_r=196
Nr=196.
图像属性表示
灵感来源:以前的工作中,利用图像属性预测任务学习模型参数,然后通过共享促进图像表示的学习。
本文直接将属性视为连接 文本 和 图像 的额外模态。利用预训练和微调的ResNet-101 模型,为每个图像预测5个属性
a
i
(
i
=
1
,
2
,
.
.
.
,
5
)
a_i(i=1,2,...,5)
ai(i=1,2,...,5) 并将其 GloVe embeddings当做图像属性的原始向量
e
(
a
i
)
e(a_i)
e(ai)。
通过加权平均,可得到图像属性的 guidance 向量。权重由一个双层神经网络学习得到:
α
i
=
W
2
⋅
tanh
(
W
1
⋅
e
(
a
i
)
+
b
1
)
+
b
2
α
=
s
o
f
t
m
a
x
(
α
i
)
\alpha_i=W_2\cdot \tanh(W_1\cdot e(a_i)+b_1)+b2 \\ \alpha= softmax(\alpha_i)
αi=W2⋅tanh(W1⋅e(ai)+b1)+b2α=softmax(αi)
其 guidance 向量可表示为:
v
a
t
t
r
=
∑
i
=
1
N
a
α
i
e
(
a
i
)
v_{attr}= \sum\limits_{i=1}^{N_a}\alpha_i e(a_i)
vattr=i=1∑Naαie(ai)
文本特征表示
使用双向LSTM (Bi-LATM) 获得文本表示,LSTM 在时间 t 步的操作为:
i
t
=
σ
(
W
i
⋅
x
t
+
U
i
⋅
h
t
−
1
)
f
t
=
σ
(
W
f
⋅
x
t
+
U
f
⋅
h
t
−
1
)
o
t
=
σ
(
W
o
⋅
x
t
+
U
o
⋅
h
t
−
1
)
c
~
t
=
tanh
(
W
c
⋅
x
t
+
U
c
⋅
h
t
−
1
)
c
t
=
f
t
⊙
c
t
−
1
+
i
t
⊙
c
~
t
h
t
=
o
t
⊙
tanh
(
c
t
)
i_t=\sigma(W_i\cdot x_t + U_i \cdot h_{t-1}) \\ f_t=\sigma(W_f\cdot x_t + U_f \cdot h_{t-1}) \\ o_t=\sigma(W_o\cdot x_t + U_o \cdot h_{t-1}) \\ \tilde{c}_t=\tanh(W_c \cdot x_t + U_c \cdot h_{t-1}) \\ c_t=f_t \odot c_{t-1} + i_t \odot \tilde{c}_t \\ h_t=o_t \odot \tanh(c_t)
it=σ(Wi⋅xt+Ui⋅ht−1)ft=σ(Wf⋅xt+Uf⋅ht−1)ot=σ(Wo⋅xt+Uo⋅ht−1)c~t=tanh(Wc⋅xt+Uc⋅ht−1)ct=ft⊙ct−1+it⊙c~tht=ot⊙tanh(ct)其中,
W
,
U
W,U
W,U 是相应的权重矩阵,
x
t
,
h
t
x_t,h_t
xt,ht 分别为 t 时刻的输入状态和隐藏状态。
σ
\sigma
σ 是 sigmoid 函数,
⊙
\odot
⊙ 表示向量的元素对应相乘。
文本的 guidance 向量是每个时刻隐藏状态的平均值:
v
t
e
x
t
=
∑
i
=
1
L
h
t
L
v_{text}=\frac{\sum_{i=1}^L h_t}{L}
vtext=L∑i=1Lht
其中,
L
L
L 是指文本的长度。
融合层
早期融合
在文本分类任务中,Bi-LSTM的初始状态通常被设置为零。但通过注入多模态信息,可能促进对模型对文本的理解。该模型应用非线性变换的图像属性引导向量作为Bi-LSTM的初始状态。
[
h
f
0
;
h
b
0
;
c
f
0
;
c
b
0
]
=
ReLu
(
W
⋅
v
a
t
t
r
+
b
)
\left[h_{f 0} ; h_{b 0} ; c_{f 0} ; c_{b 0}\right]=\operatorname{ReLu}\left(W \cdot v_{\mathrm{attr}}+b\right)
[hf0;hb0;cf0;cb0]=ReLu(W⋅vattr+b)其中,
h
f
0
,
c
f
0
h_{f 0} , c_{f 0}
hf0,cf0 是前向LSTM 初始状态,
h
b
0
,
c
b
0
h_{b 0} , c_{b 0}
hb0,cb0 是后向LSTM 初始状态,[ ; ]是向量连接;ReLu表示修正线性单位激活函数;W 和 b 是权值矩阵和偏差。
注:文章也尝试使用图像引导向量进行早期融合,其中LSTM初始状态与上述的平均值相似,但它表现不是很好,将文章实验中有所讨论。
表示融合
设
X
m
(
i
)
X_m^{(i)}
Xm(i) 是模态m(m是文本,图像或属性) 的
i
t
h
i^{th}
ith 原始向量。这一阶段的关键是计算每个
X
m
(
i
)
X_m^{(i)}
Xm(i) 的参数。它们的加权平均值即为模态m 的新表示。同样地,使用双层神经网络学习参数:
α
m
n
(
i
)
=
W
m
n
2
⋅
tanh
(
W
m
n
1
⋅
[
X
m
(
i
)
;
v
n
]
+
b
m
n
1
)
+
b
m
n
2
α
m
n
=
softmax
(
α
m
n
)
α
m
(
i
)
=
∑
n
∈
{
text, image, attr
}
α
m
n
(
i
)
3
v
m
=
∑
i
=
1
L
m
α
m
(
i
)
X
m
(
i
)
\alpha_{m n}^{(i)}=W_{m n_{2}} \cdot \tanh \left(W_{m n_{1}} \cdot\left[X_{m}^{(i)} ; v_{n}\right]+b_{m n_{1}}\right) +b_{m n_{2}} \\ \alpha_{m n} =\operatorname{softmax}\left(\alpha_{m n}\right) \\ \alpha_{m}^{(i)}=\frac{\sum_{n \in\{\text { text, image, attr }\}} \alpha_{m n}^{(i)}}{3} \\ v_{m}=\sum_{i=1}^{L_{m}} \alpha_{m}^{(i)} X_{m}^{(i)}
αmn(i)=Wmn2⋅tanh(Wmn1⋅[Xm(i);vn]+bmn1)+bmn2αmn=softmax(αmn)αm(i)=3∑n∈{ text, image, attr }αmn(i)vm=i=1∑Lmαm(i)Xm(i)其中,
m
,
n
∈
{
t
e
x
t
,
i
m
a
g
e
,
a
t
t
r
}
m,n\in\{text,image,attr\}
m,n∈{text,image,attr} 表示模态,
α
m
n
(
i
)
\alpha_{m n}^{(i)}
αmn(i) 是指在模态
n
n
n 的指导下,模态
m
m
m 的
i
th
i^{\text {th}}
ith 原始向量对应的权重,
α
m
n
\alpha_{m n}
αmn 包含所有
α
m
n
(
i
)
\alpha_{m n}^{(i)}
αmn(i)。
α
m
(
i
)
\alpha_{m}^{(i)}
αm(i) 是模态
m
m
m 的
i
th
i^{\text {th}}
ith 原始向量 最终的重构权重。
L
m
L_{m}
Lm 是序列
{
X
m
(
i
)
}
\left\{X_{m}^{(i)}\right\}
{Xm(i)}的长度 ;
W
m
n
1
,
W
m
n
2
W_{m n_{1}}, W_{m n_{2}}
Wmn1,Wmn2 是神经网络的权重矩阵,
b
m
n
1
,
b
m
n
2
b_{m n_{1}}, b_{m n_{2}}
bmn1,bmn2 是偏置。
通过将指导向量(guidance vector) v text , v image , v attr v_{\text{text}}, v_{\text{image}}, v_{\text{attr}} vtext,vimage,vattr 进行表示融合,得到每个模态的特征向量,并准备作为下一层的输入。
模态融合
设每个模态m 的特征向量表示为
v
m
v_{m}
vm. 首先将其转换为固定长度的形式
v
m
′
v_{m}^{\prime}
vm′. 采用双层前馈神经网络计算各模态 m 的注意力权值,然后用于变换后的特征向量
v
m
′
v_{m}^{\prime}
vm′ 的加权平均值。最终结果为单一的,固定长度的向量
v
fused
v_{\text {fused }}
vfused 。
α
~
m
=
W
m
2
⋅
tanh
(
W
m
1
⋅
v
m
+
b
m
1
)
+
b
m
2
α
~
=
softmax
(
α
~
)
v
m
′
=
tanh
(
W
m
3
⋅
v
m
+
b
m
3
)
v
fused
=
∑
m
∈
{
text, image, attr
}
α
~
m
v
m
′
\tilde{\alpha}_{m}=W_{m_{2}} \cdot \tanh \left(W_{m_{1}} \cdot v_{\mathrm{m}}+b_{m_{1}}\right)+b_{m_{2}} \\ \tilde{\alpha}=\operatorname{softmax}(\tilde{\alpha}) \\ v_{m}^{\prime}=\tanh \left(W_{m_{3}} \cdot v_{m}+b_{m_{3}}\right) \\ v_{\text {fused }}=\sum_{m \in\{\text {text, image, attr}\}} \tilde{\alpha}_{m} v_{m}^{\prime}
α~m=Wm2⋅tanh(Wm1⋅vm+bm1)+bm2α~=softmax(α~)vm′=tanh(Wm3⋅vm+bm3)vfused =m∈{text, image, attr}∑α~mvm′其中,
α
~
\tilde{\alpha}
α~ 是包含
α
~
m
\tilde{\alpha}_{m}
α~m 的向量,
W
m
1
,
W
m
2
,
W
m
3
W_{m_{1}}, W_{m_{2}}, W_{m_{3}}
Wm1,Wm2,Wm3 是权重矩阵,
b
m
1
,
b
m
2
,
b
m
3
b_{m_{1}}, b_{m_{2}}, b_{m_{3}}
bm1,bm2,bm3 是偏置。
v
m
v_{\mathrm{m}}
vm 是表示融合阶段得到的特征向量。
分类层
分类层:两层全连接的神经网络。
隐藏层和输出层的激活函数分别是元素级ReLu和sigmoid函数。
损失函数是交叉熵。
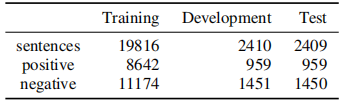
四、数据集与预处理(Preprocessing)
数据来源于 English tweets,包含图片、文本和标签。对数据集进行清理,人工检查 development
set 和 test set 中标签的准确性。
数据集规模(8:1:1):
预处理
- 用符号 < user > 替换提及。
- 用NLTK工具包分隔单词、表情符号和标签。
- 将标签符号# 与 标签 分开,并用小写字母替换大写字母。
- 只在训练集中出现一次的单词和没有在训练集中出现但只在开发集或测试集中出现的单词被某个符号 < unk > 替换。
五、实验
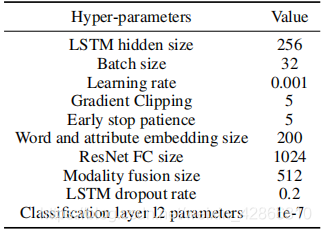
训练设置
预训练模型:ResNet
优化器:Adam optimizer
超参数设置:
结果对比
- 比较层次融合模型与几个baseline的效果
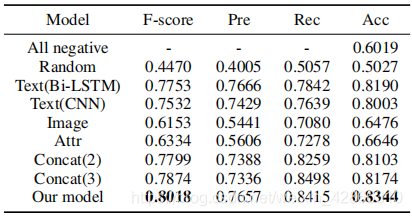
All negative:都(不)是反讽?
Random:随机预测推文是否反讽;
Text(Bi-LSTM):利用双向LSTM仅学习文本表示,预测是否反讽;
Text(CNN):利用CNN 仅学习文本表示,预测是否反讽;
Image:将 ResNet 池化层后的图像向量作为分类层的输入,预测是否反讽;
Attr:将 属性特征向量作为分类层的输入,预测是否反讽;
Concat(2):连接文本特征和图像特征作为分类层的输入,预测是否反讽;
Concat(3):连接所有文本、图像和属性特征作为分类层的输入,预测是否反讽。
结果分析:
- 仅仅通过 图像 和 图像属性 模态得到的效果并不好,但是仅仅用文本得到的效果表现较好,说明文本模态对该任务更加重要。
- 三个模态的拼接效果比两个模态的效果好,说明 图像属性 模态实际上引入了图像外部语义,可以帮助模型提取一些难以直接提取的图像特征。
- 本文的层次融合模型效果更好,说明 这一方法能够更有效的利用三种模态特征。
- 比较层次融合模型与baseline的符号统计
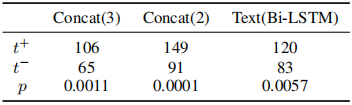
t + t^+ t+:本文方法预测正确,其他方法预测错误的样本数。
t − t^- t−:本文方法预测错误,其他方法预测正确的样本数。
p p p:显著性值。
结果分析:
-
所有显著性水平均小于0.05,提出模型的显著性水平明显优于baseline模型。
注:显著性水平的计算、具体含义及实际意义有待进一步学习。 -
消融实验分析
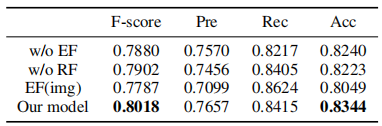
w/o:消除某组成成分; EF:早期融合; RF:表示融合; EF(img):利用图片指导早期融合。
结果分析:
- 早期融合可以提升文本表示。其中,属性 > 图像,说明图像属性是连接图像和文本的桥梁。
- 表示融合 可以细化每个模态的特征表示。同样,有益于模态特征的表示。
实例分析(错误分析)
- 模型预测正确的例子
表明:只有 结合文本和图像信息才可以判断样本是否反讽。 - 视觉注意力:
在表示融合阶段,图像与文本特征表示的显著位置表明, 上述模型可以成功地关注图像的适当部分、句子中的基本单词和重要属性。 - 错误分析

上例预测错误的重要原因:缺乏常识引导,图片中手势与文本中 thanks for 形成明显的反讽。但由于缺乏对上述手势的理解,使得模型的注意力并没有集中在图像的手势。
六、总结
本文提出了一种新的层次融合模型,充分利用三种模态(图像、文本和图像属性)来解决具有挑战性的多模态讽刺检测任务。评估结果表明:本文模型的有效性和这三种模态的有效性。在未来的工作中,可以将其他模态,如音频等纳入讽刺检测任务,也可以将常识在模型中使用常识知识。

















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









