






1 RNN的问题
不擅长学习时序数据的长期依赖关系,因为 BPTT
会发生梯度消失和梯度爆炸的问题。
1.1 梯度消失和梯度爆炸
例子:

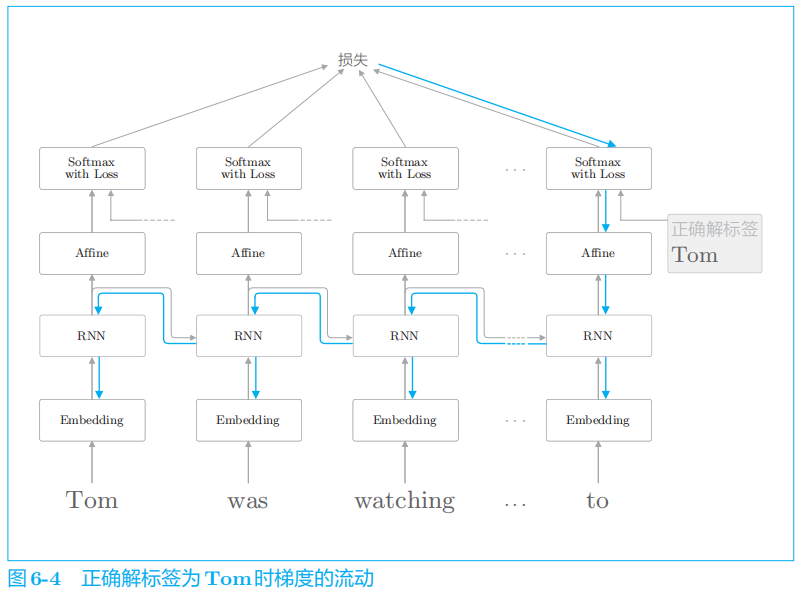
如果这个梯度在中途变弱(甚至没有包含任何信息),则权重参数将不会被更新。
1.2 原因
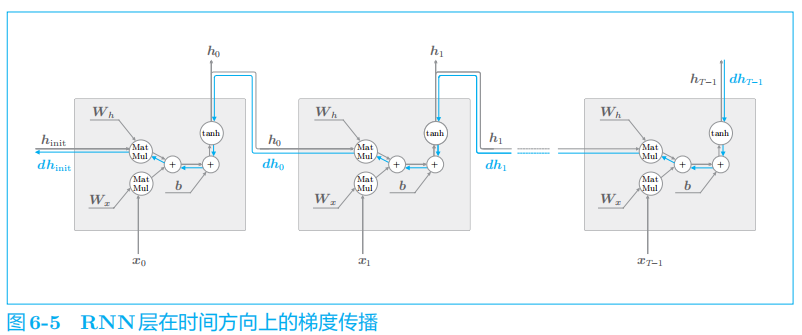
此时,关注时间方向上的梯度,可知反向传播的梯度流经 tanh
、“
+
”和
MatMul
(矩阵乘积)运算。
我们先来看一下
tanh
。
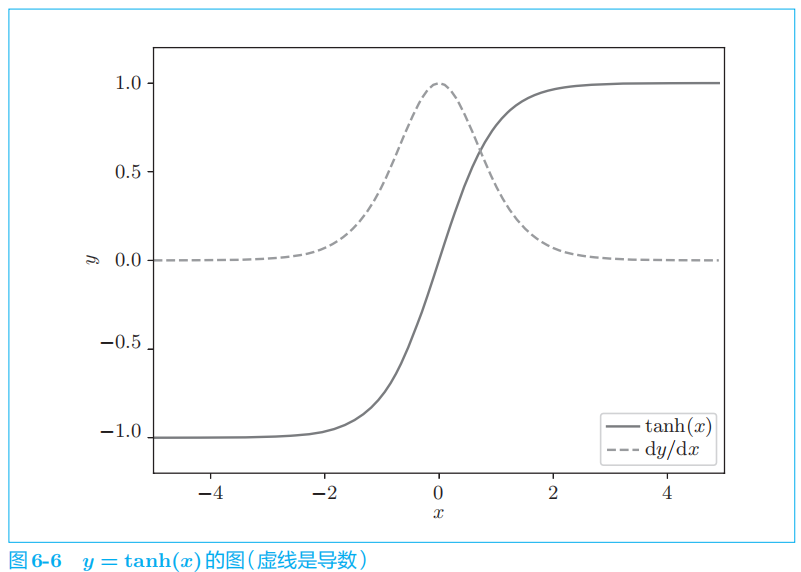

接下来,我们关注
MatMul
(矩阵乘积)节点。


通过举例子验证:

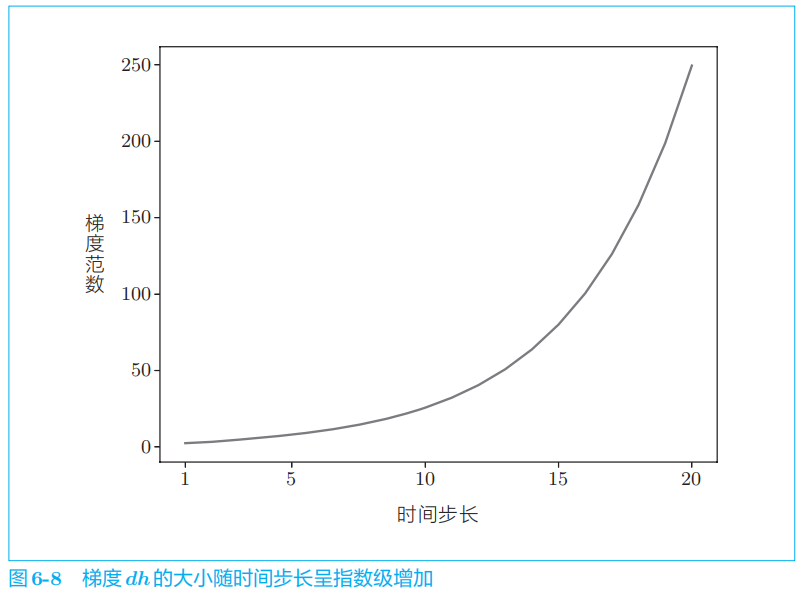


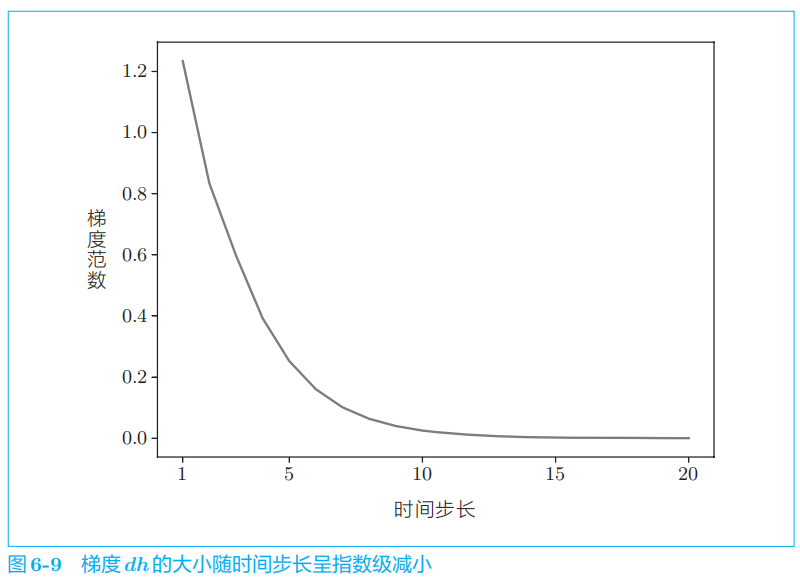

因为矩阵
Wh
被反复乘了
T
次。如果 Wh
是标量,则问题将很简单:当
Wh
大于
1
时,梯度呈指数级增加;当
Wh小于 1
时,梯度呈指数级减小。
1.3 梯度爆炸对策
梯度裁剪:
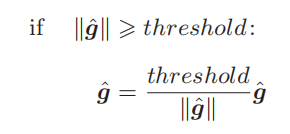



参数
grads
是梯度的列表,
max_norm
是阈值。
2 梯度消失和LSTM
为了解决梯度消失问题,需要从根本上改变 RNN 层的结构,提出Gated RNN
框架,其中包括LSTM。
2.1 LSTM接口
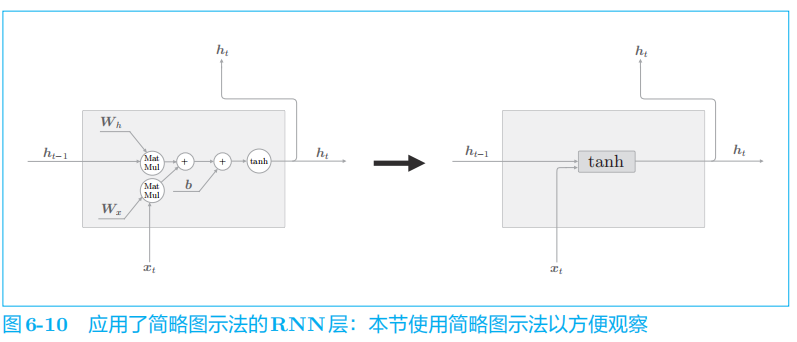
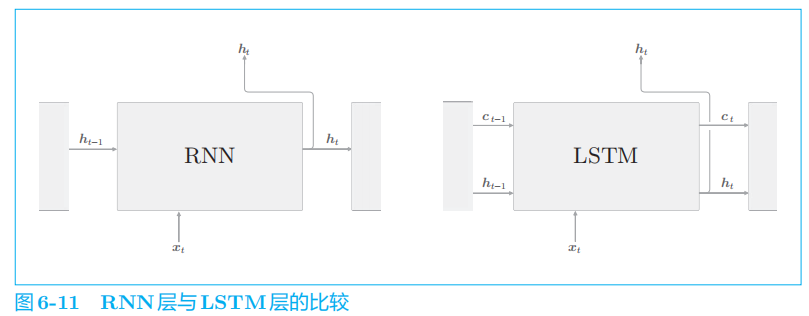
LSTM
还有路径 c
。这个
c
称为记忆单元(或者简称为“单元”),相当于
LSTM 专用的记忆部门。记忆单元的特点是,仅在 LSTM 层内部接收和传递数据。
LSTM
的输出仅有隐藏状态向量
h
。记忆单元 c
对外部不可见。
2.2 LSTM的结构

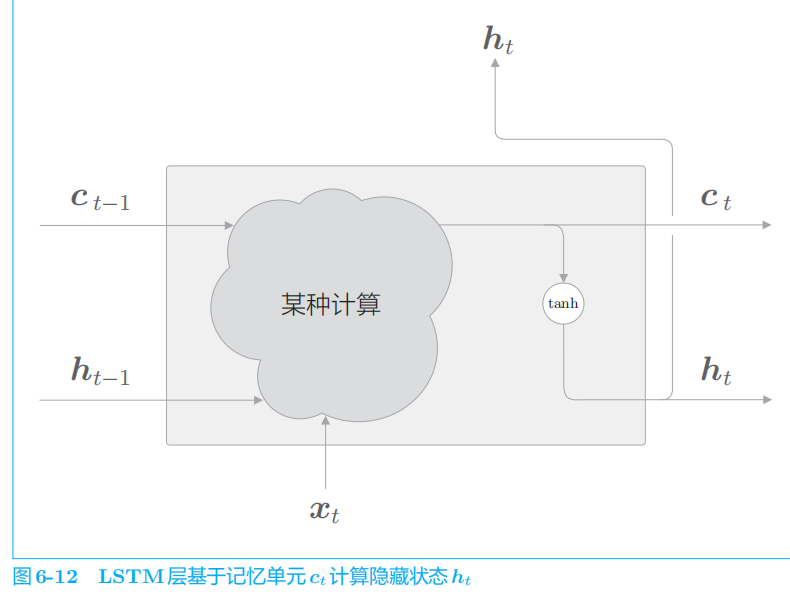

介绍Gate:门

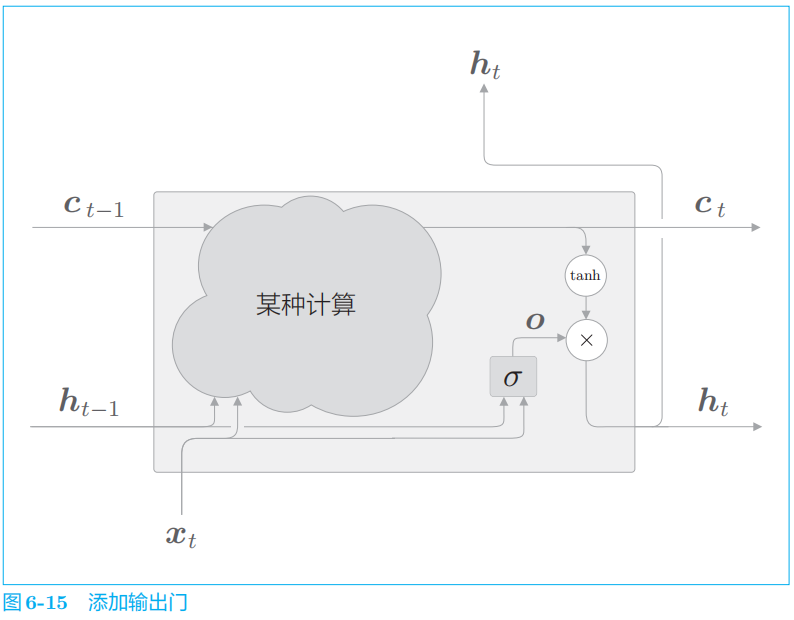
2.3 输出门
针对
tanh(
c
t
)
的各个元素,调整它们作为下一时刻的隐藏状态的重要程度。由于这个门管理下一个隐藏状态 h
t
的输出。
sigmoid
函数用
σ
( )
表示:

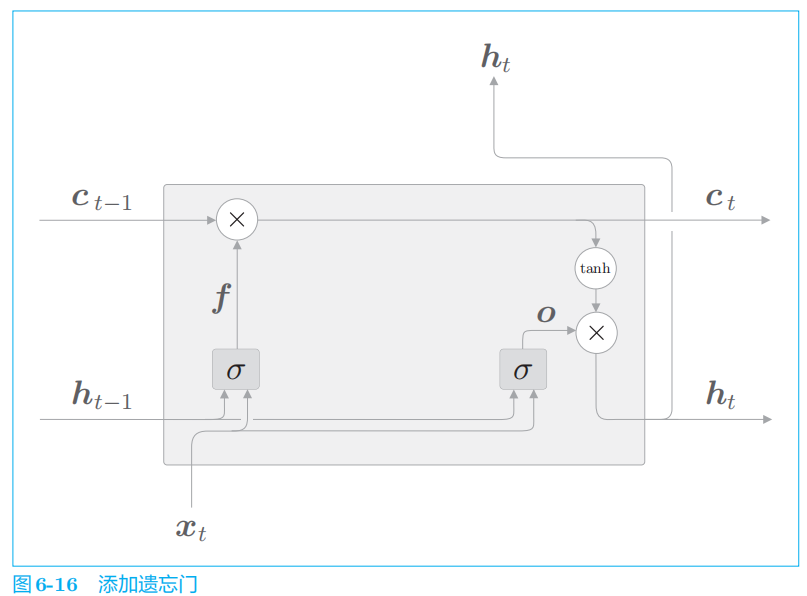
2.4 遗忘门
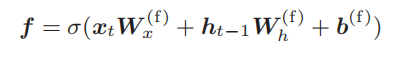
2.5 新的记忆单元
遗忘门从上一时刻的记忆单元中删除了应该忘记的东西,但是这样一来,记忆单元只会忘记信息。现在我们还想向这个记忆单元添加一些应当记住的新信息。
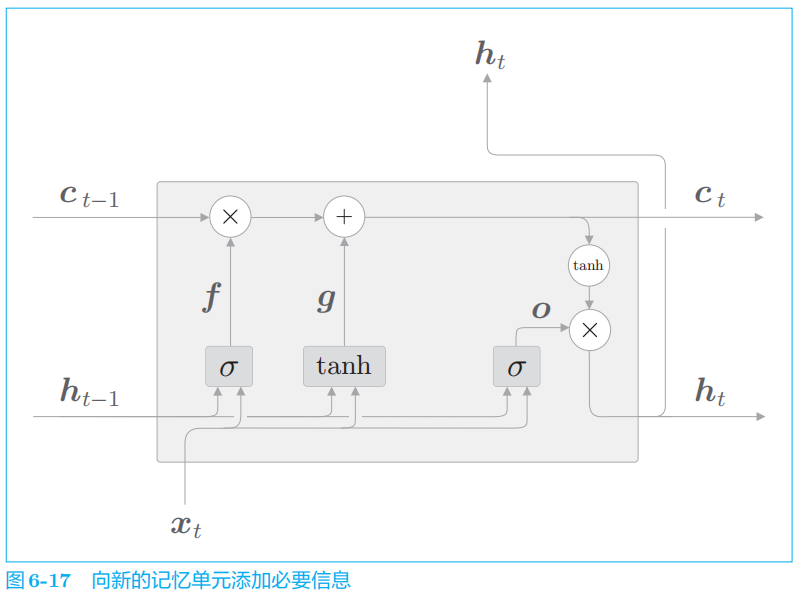
如图
6
-
17
所示,基于
tanh
节点计算出的结果被加到上一时刻的记忆单元 c
t
−
1
上。这样一来,新的信息就被添加到了记忆单元中。
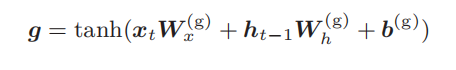
2.6 输入门
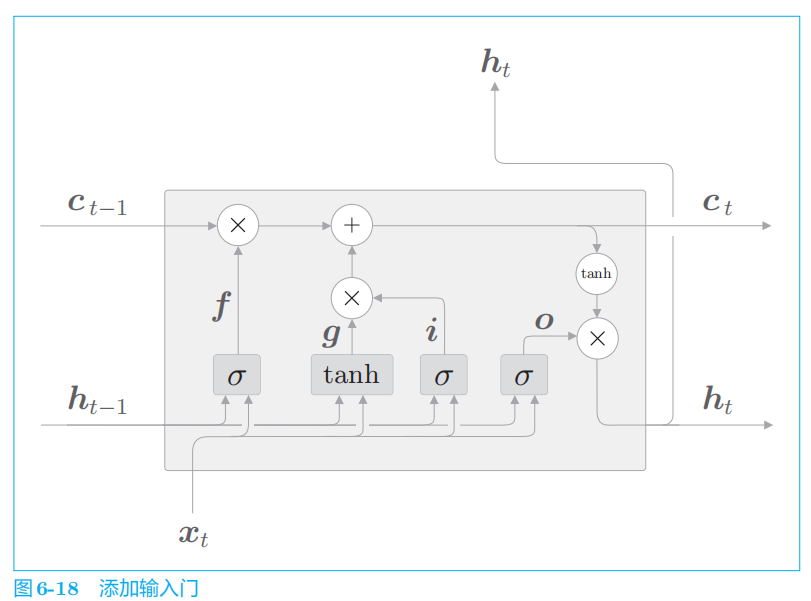
输入门判断新增信息
g
的各个元素的价值有多大。输入门不会不经考虑就添加新信息,而是会对要添加的信息进行取舍。换句话说,输入门会添加加权后的新信息。
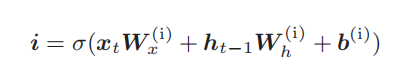
然后,将
i
和
g
的对应元素的乘积添加到记忆单元中。
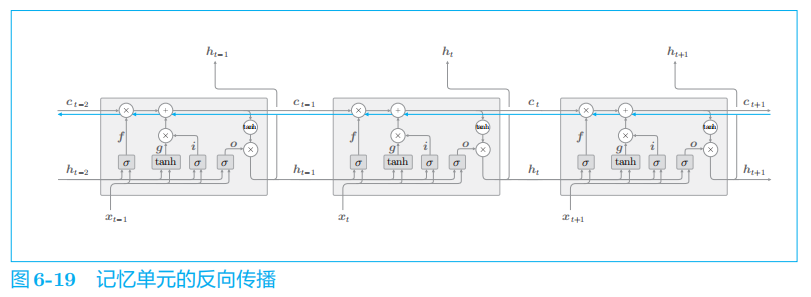
2.7 LSTM的梯度流动


3 LSTM的实现
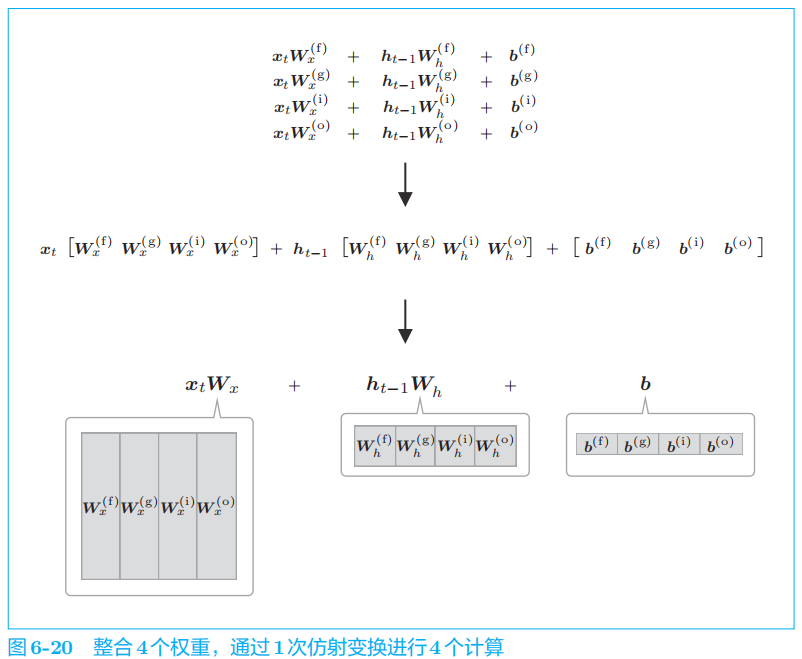
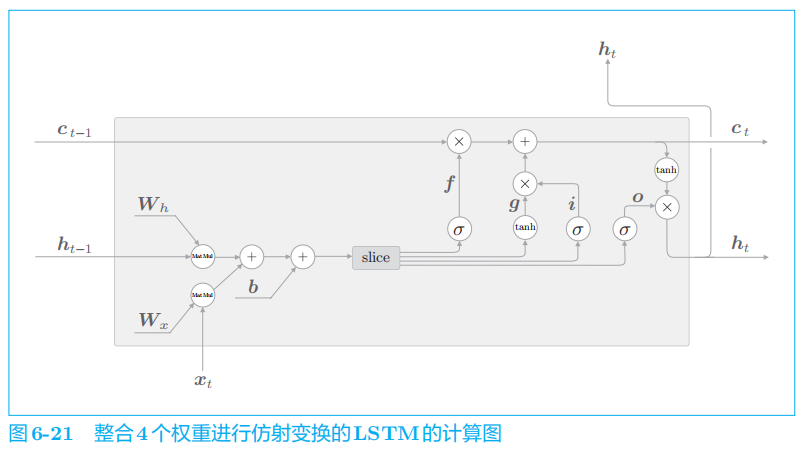
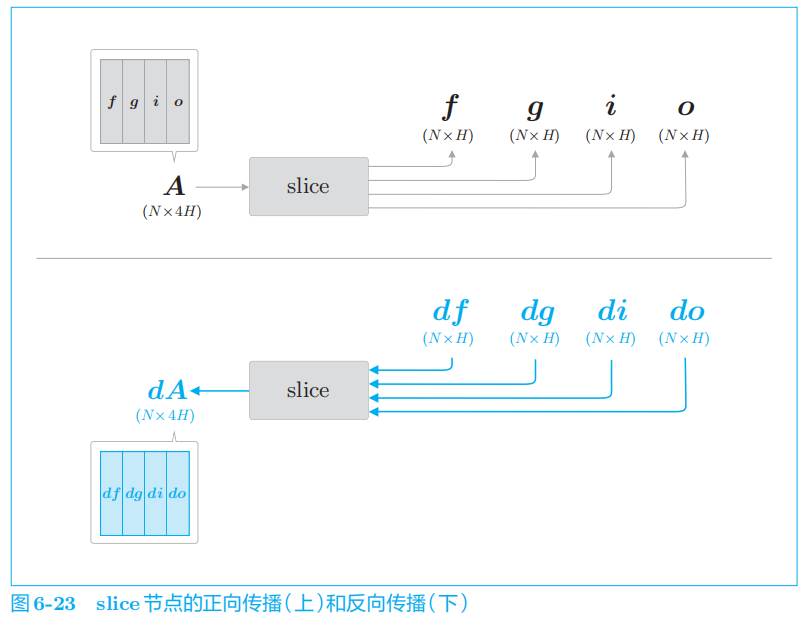
先一起执行
4
个仿射变换。然后,基于
slice
节点,取出 4
个结果。

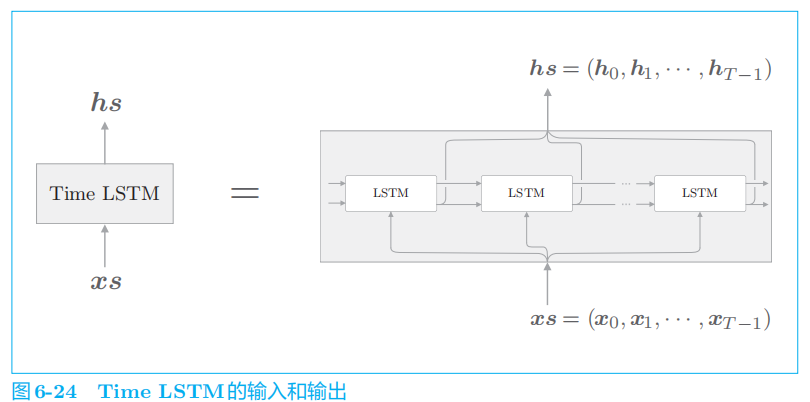
3.1 Time LSTM层的实现
Time LSTM
层是整体处理
T
个时序数据的层,由 T
个
LSTM
层构成。
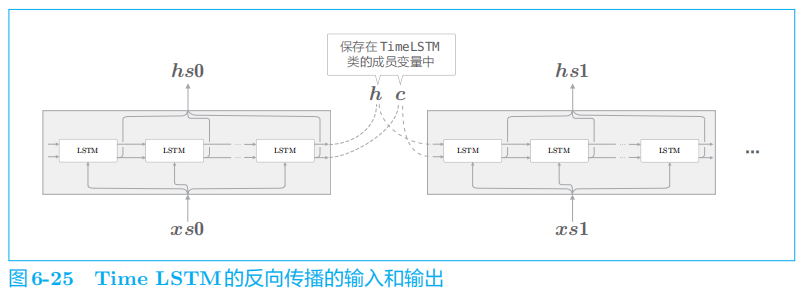
将隐藏状态和记忆单元保存在成员变量中。这样一来,在调用下一个 forward()
函数时,就可以继承上一时刻的隐藏状态(和记忆单元)。
4 使用LSTM的语言模型
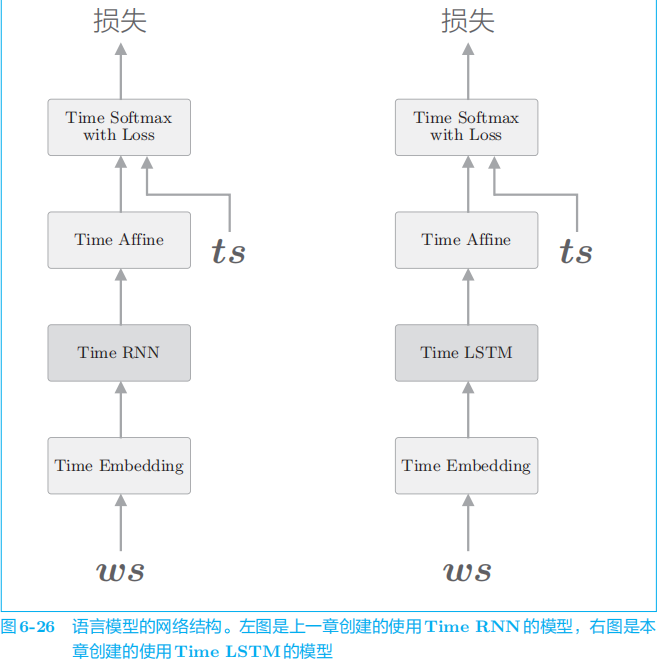
使用
PTB
数据集的所有训练数据进行学习
代码p251
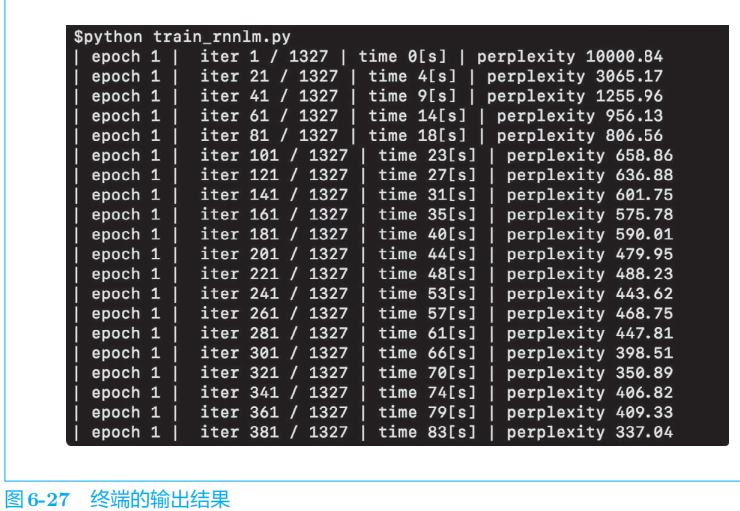

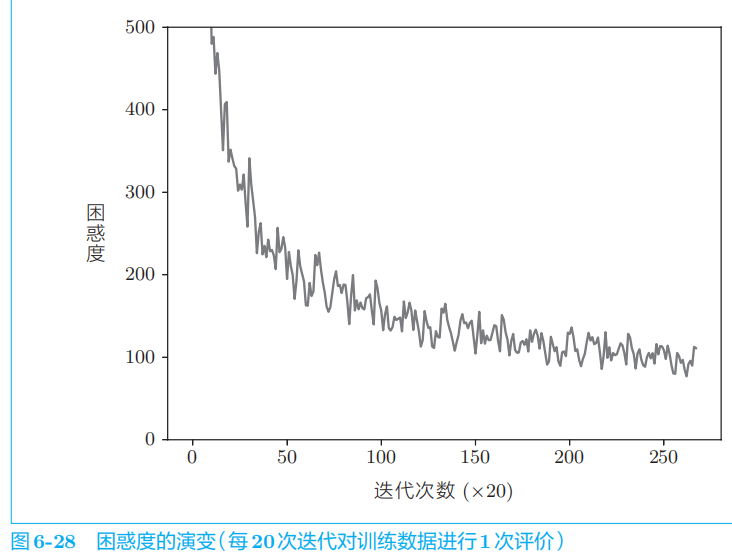

5 进一步改进RNNLM
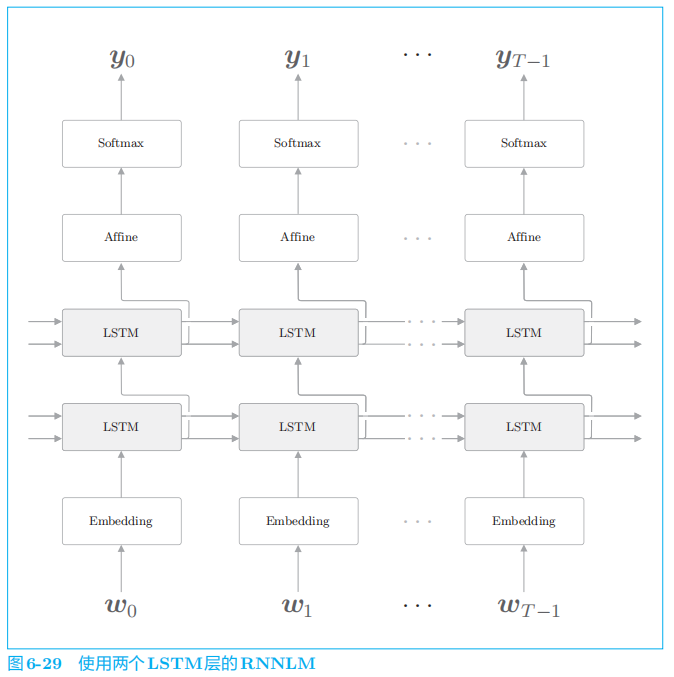
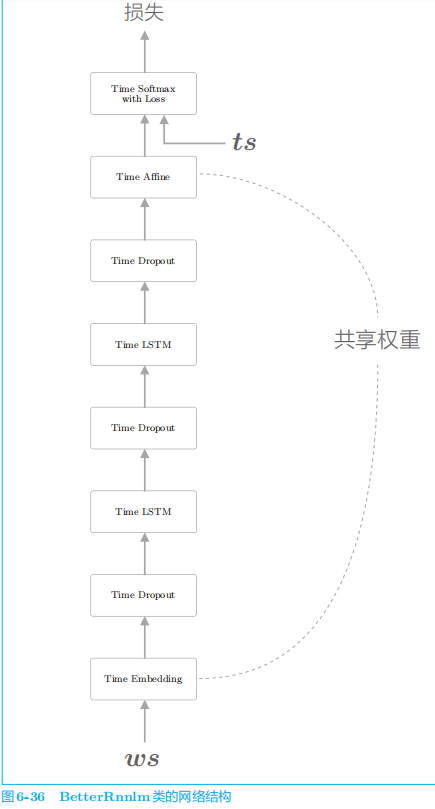
5.1 LSTM层的多层化
在使用
RNNLM
创建高精度模型时,加深
LSTM
层(叠加多个
LSTM层)的方法往往很有效。

5.2 基于Dropout抑制过拟合
过拟合是一种缺乏泛化能力的状态。
像Dropout
这样,在训练时随机忽略层的一部分(比如50%)神经元,也可以被视为一种正则化。
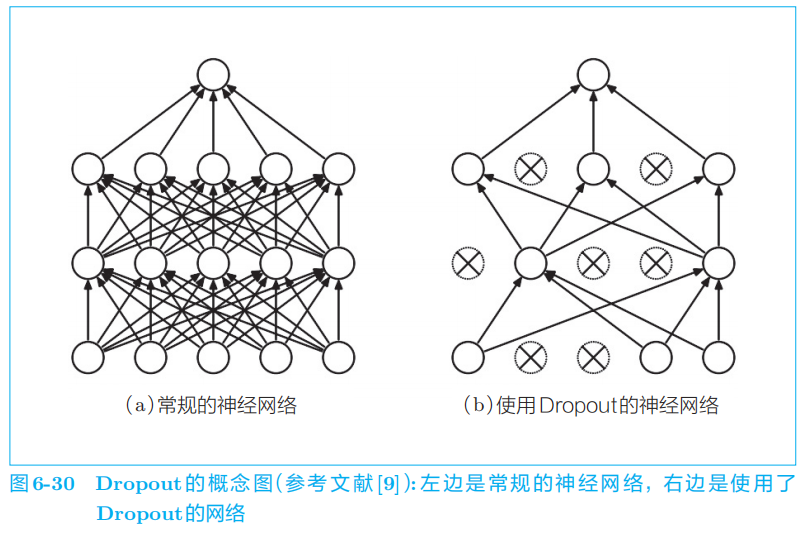
Dropout
随机选择一部分神经元,然后忽略它们,停止向前传递信号。
如果在时序方向上插入
Dropout,那么当模型学习时,随着时间的推移,信息会渐渐丢失。
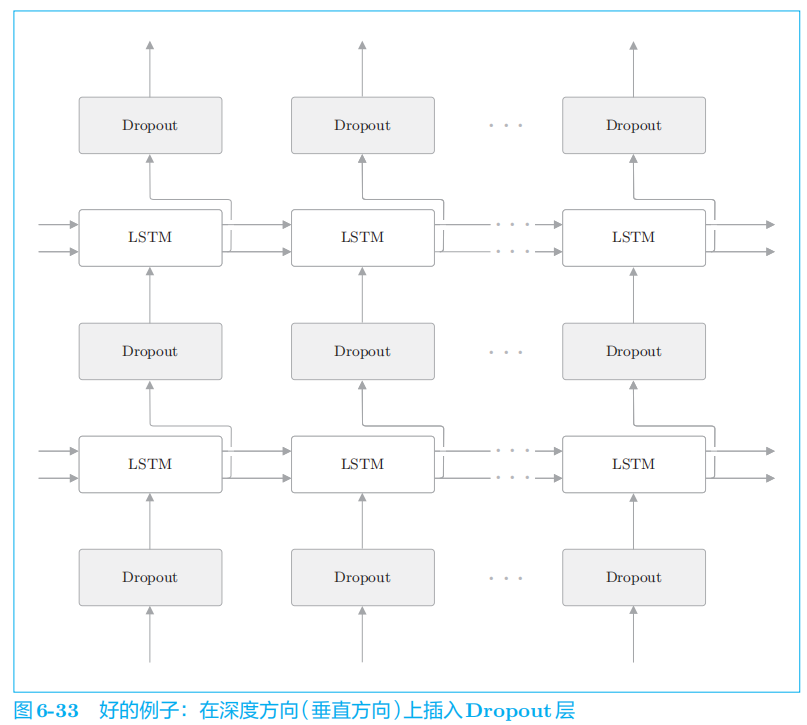

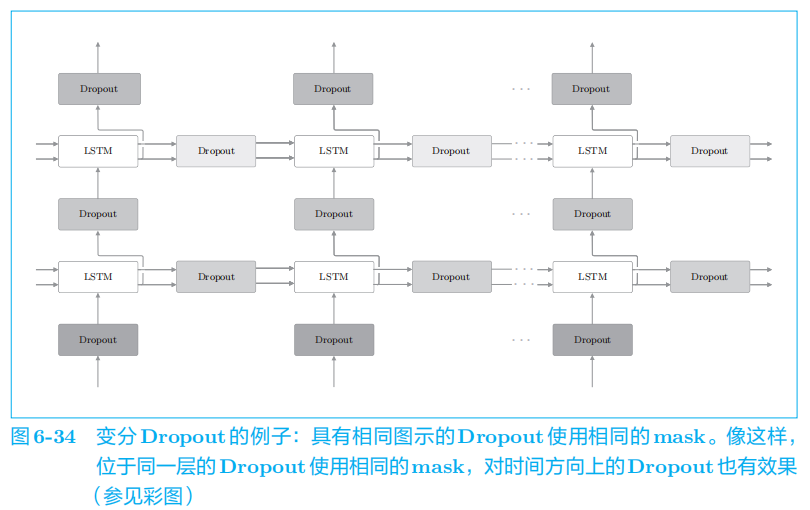


本章没用变分Dropout,用的是常规Dropout。
5.3 权重共享
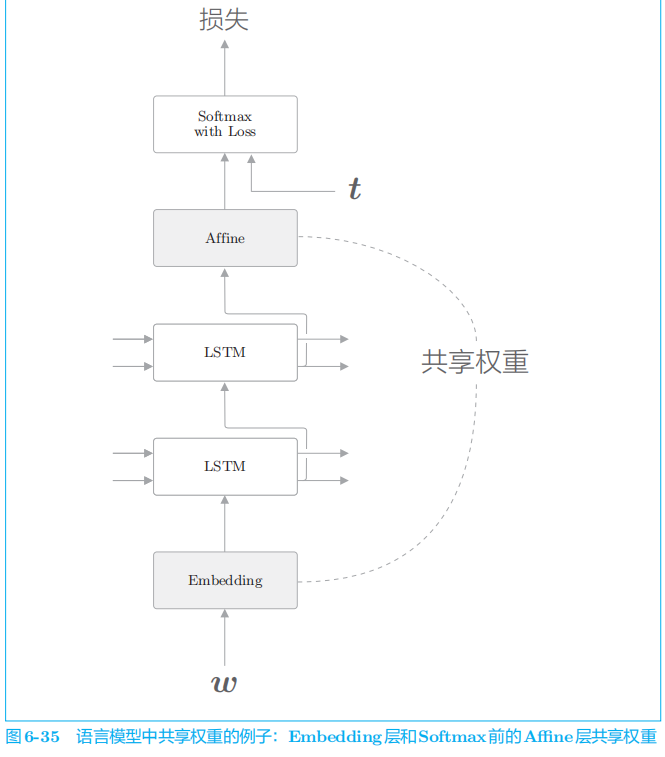

直观上,共享权重可以减少需要学习的参数数量,从而促进学习。另外,参数数量减少,还能收获抑制过拟合的好处。
5.4 更好地RNNLM的实现

针对每个
epoch
使用验证数据评价困惑度,在值变差时,降低学习率。
降低学习率可以提高学习的稳定性。学习率高说明学习快,但会不稳定。
代码p267

6 总结
解决了
RNN
中存在的
梯度消失(或梯度爆炸)问题,提出LSTM并使用PTB数据集进行学习,评价困惑度,以及对此进行改进以提升精度。















 2857
2857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









