






前馈型神网络:指网络的传播方向是单向的,先将输入信号传给下一层(隐藏层),接收到信号的层也同样传给下一层,然后再传给下一层……像这样,信号仅在一个方向上传播。
存在问题:不能很好地处理时间序列数据(以下简称为“时序数据”)即单纯的前馈网络无法充分学习时序数据的性质。
所以需要引入RNN(循环神经网络)
1 概率和语言模型
1.1 概率视角下的word2vec
与之前不同的是,这里我们将上下文限定为左侧窗口。



CBOW
模型的学习旨在找到使式
(5
.
3)
表示的损失函数(确切地说,是整个语料库的损失函数之和)最小的权重参数。
1.2 语言模型
语言模型
(
language model
)给出了单词序列发生的概率。
比如,对于“
you say goodbye
”这一单词序列,语言模型给出高概率(比如 0
.
092
);对于“
you say good die
”这一单词序列,模型则给出低概率(比如 0
.
000 000 000 003 2
)。



1.3 将CBOW模型用作语言模型?
马尔可夫性是指未来的状态仅依存于当前状态。此外,当某个事件的概率仅取决于其前面的 N
个
事件时,称为“
N 阶马尔可夫链”。
若下一个单词仅取决
于前面
2
个单词的模型,称为“
2
阶马尔可夫链”。
CBOW模型存在上下文大小问题以及忽略上下文单词顺序问题。
2 RNN
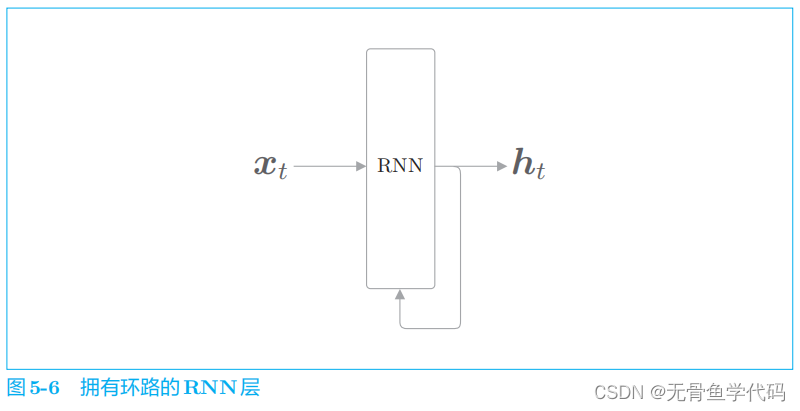
2.1 循环的神经网络
随着数据的循环,信息不断被更新。
通过数据的循环,
RNN
一边记住过去的数据,一边更新到最新
的数据。
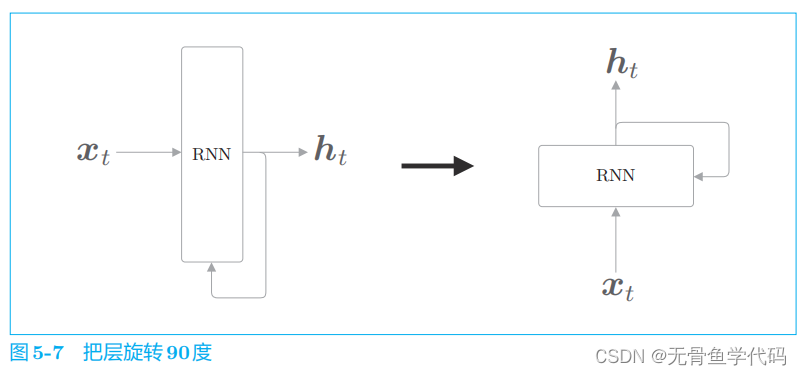
2.2 展开循环
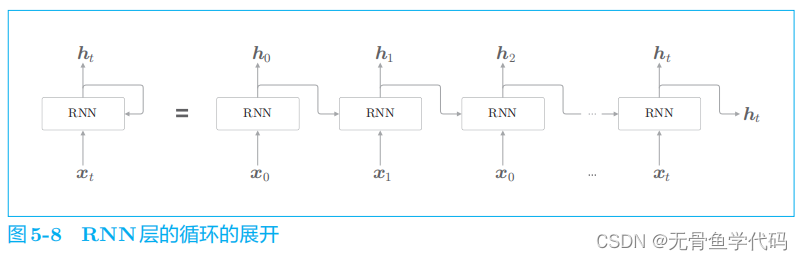


RNN
层是“具有状态的层”或“具有存储(记忆) 的层”
从
RNN
层输出了两个箭头,但是请注意这两个箭头代表的是同一份数据(准确地说,是同一份数据被复制了)。
2.3 Backpropagation Through Time
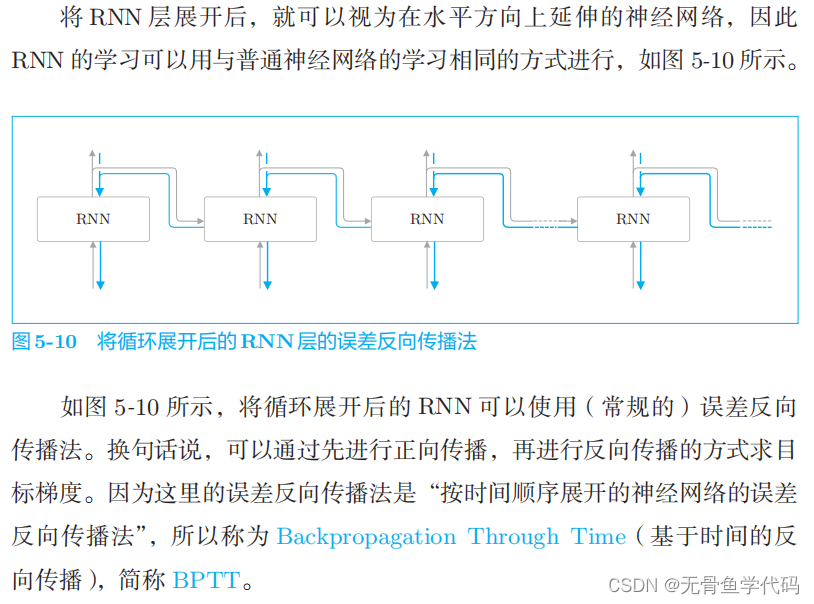
存在问题:

2.4 Truncated BPTT


RNN
执行
Truncated BPTT
时,数据需要按顺序输入。
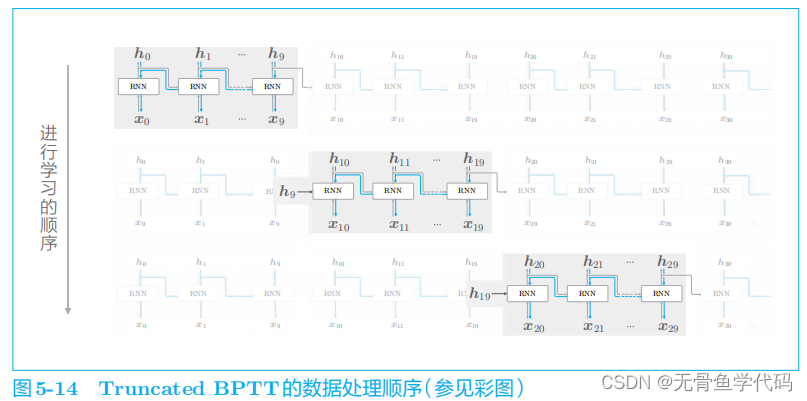
结论:正向传播不会断,误差反向传播按块进行。
2.5 Truncated BPTT的mini-batch学习
在输入数据的开始位置,需要在各个批次中进行“偏移”。

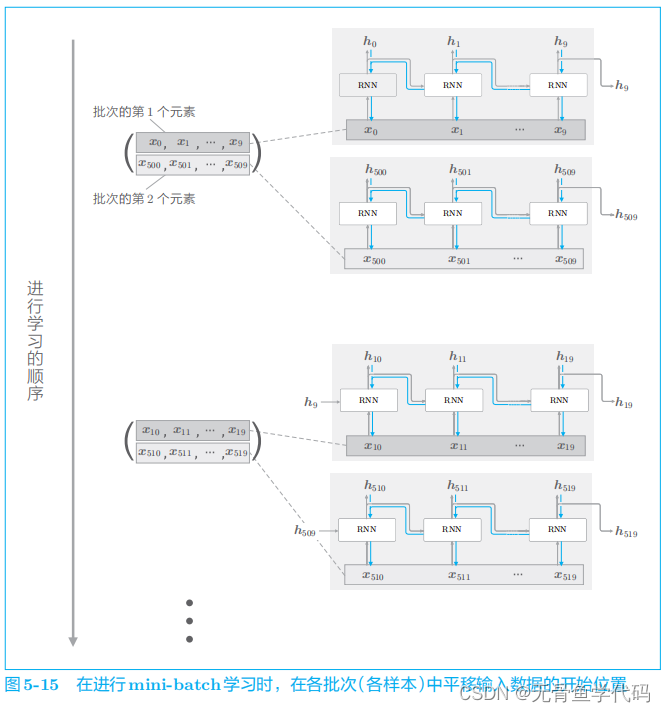
需要注意的是:
一是要按顺序输入数据;二是要平移各批次(各样本)输入数据的开始位置。
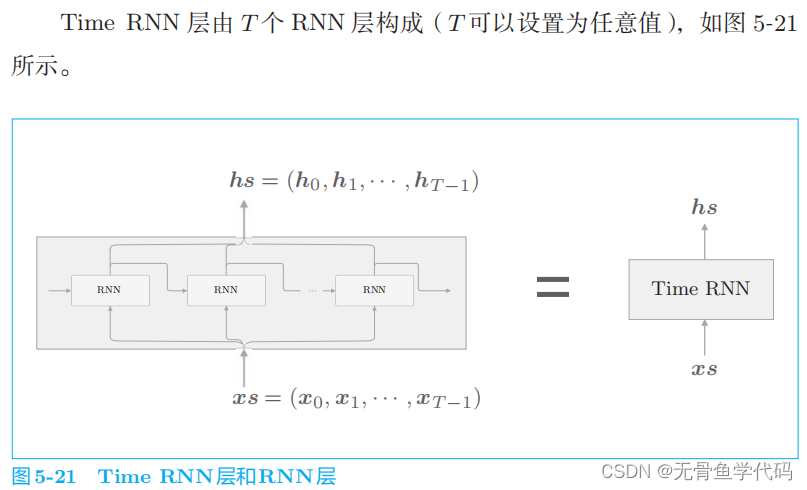
3 RNN的实现
目标神经网络接收长度为
T
的时序数据(
T
为任意值),输出各个时刻的隐藏状态 T
个。


我们接下来进行的实现的流程是:首先,实现进行
RNN
单步处理的
RNN类;然后,利用这个 RNN
类,完成一次进行
T
步处理的
TimeRNN
类。
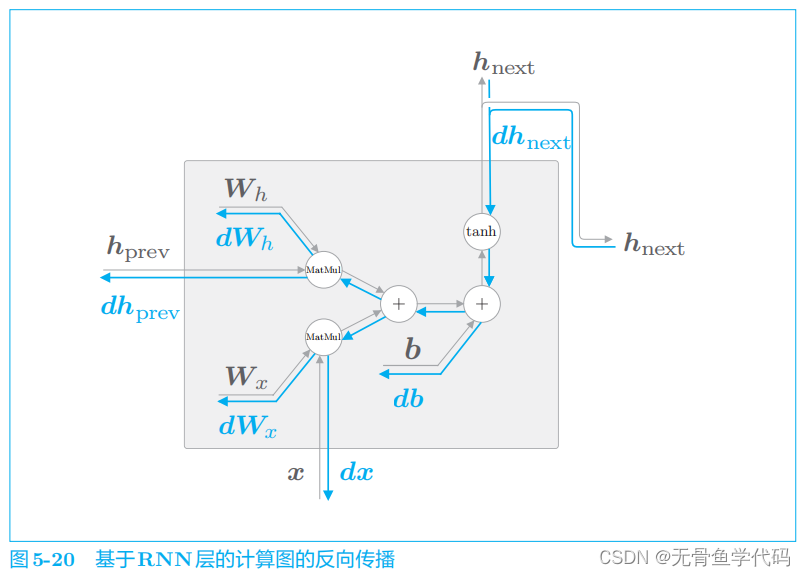
3.1 RNN层的实现
RNN正向传播的数学式:
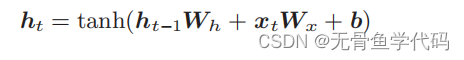







3.2 Time RNN层的实现
这里,
RNN
层的隐藏状态
h
保存在成员变量中。如图 5
-
22
所示,在进行隐藏状态的“继承”时会用到它。
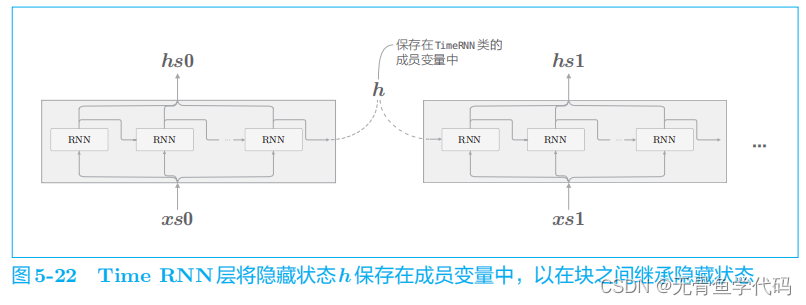
另外,我们可以用
stateful
这个参数来控制是否继承隐藏状态。









这里需要注意的是,
RNN
层的正向传播的输出有两个分叉。在正向传播存在分叉的情况下,在反向传播时各梯度将被求和。因此,在反向传播时,流向 RNN
层的是求和后的梯度。


4 处理时序数据的层的实现
我们将基于
RNN
的语言模型称为
RNNLM
4.1 RNNLM的全貌图
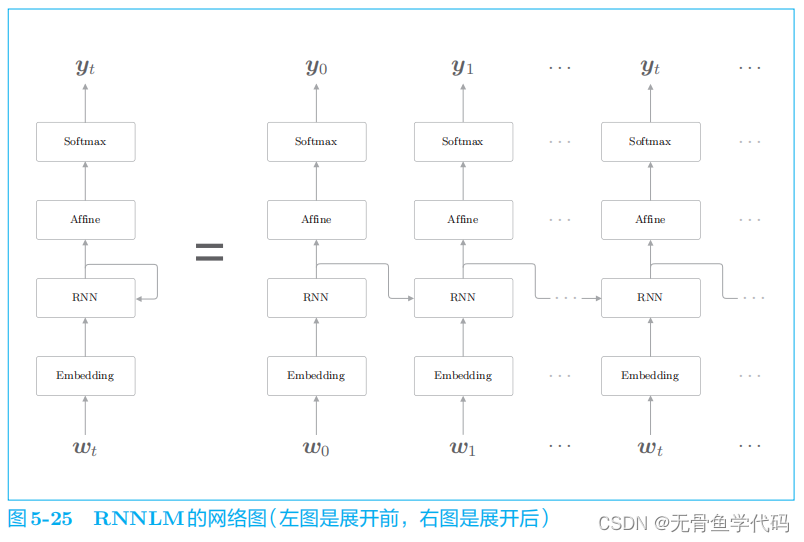

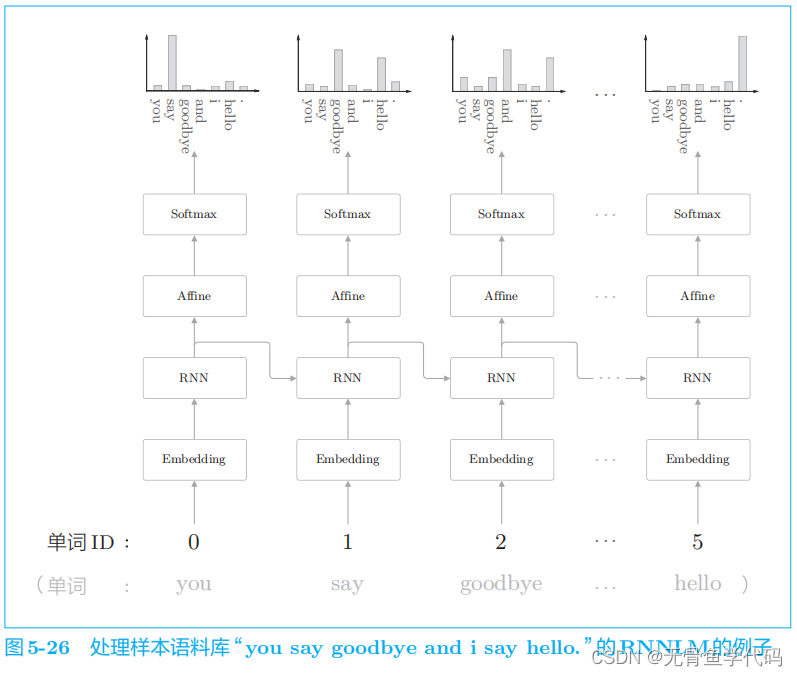

这里需要注意的是,RNN 层“记忆”了“
you say
”这一上下文。更准确地说,
RNN
将“
you say”这一过去的信息保存为了简短的隐藏状态向量。
RNN
层的工作是将这个信息传送到上方的 Affine
层和下一时刻的
RNN
层。
RNNLM 可以“记忆”目前为止输入的单词,并以此为基础预
测接下来会出现的单词。
RNN
层通过从过去到现在继承并传递数据,使得
编码和存储过去的信息成为可能。
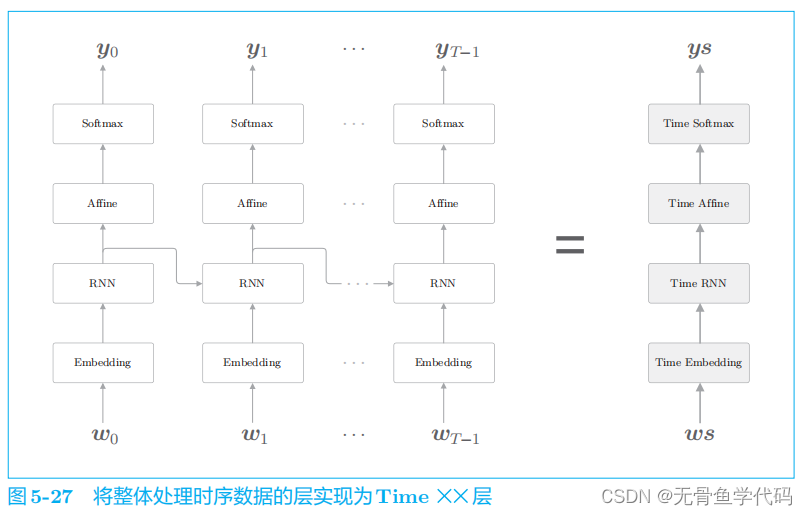
4.2 Time层的实现
之前我们将整体处理时序数据的层实现为了
Time RNN
层,这里也同样使用 Time Embedding
层、
Time Affine
层等来实现整体处理时序数据的层。
Time Affine
层的情况下,
准备
T
个
Affine
层分别处理各个时刻的数据即可。
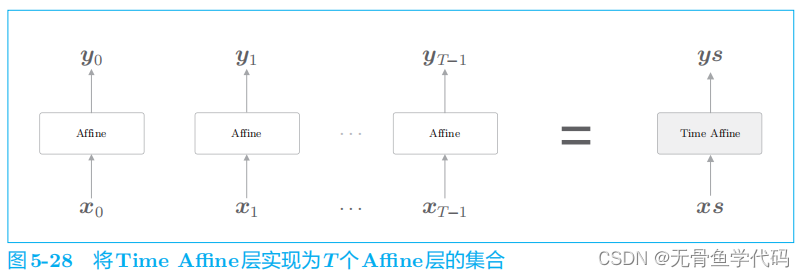
Time Embedding
层也一样,在正向传播时准备
T
个
Embedding
层,由各个 Embedding
层处理各个时刻的数据。
需要注意的是,
Time Affine
层并不是单纯地使用
T
个Affine 层,而是使用矩阵运算实现了高效的整体处理。
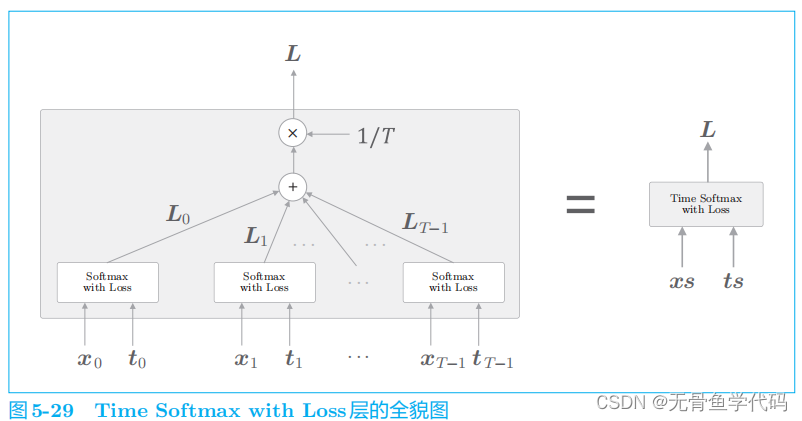
T
个Softmax with Loss 层各自算出损失,然后将它们加在一起取平均。
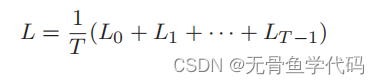
5 RNNLM的学习和评价
5.1 RNNLM的实现
代码p208

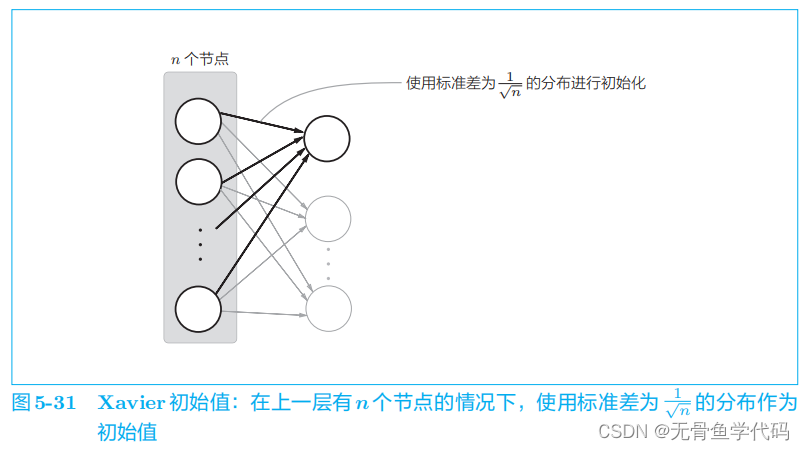
在深度学习中,权重的初始值非常重要。



通过设置好的初始值,学习的进展和最终的精度都会有很大变化。本书此后都将使用 Xavier
初始值作为权重的初始值。
5.2 语言模型的评价
语言模型基于给定的已经出现的单词(信息)输出将要出现的单词的概率分布。
困惑度:概率的倒数
困惑度也可以解释为分叉度,
在刚才的例子中,好的预测模型的分叉度是
1
.
25
,这意味着下
一个要出现的单词的候选个数可以控制在
1
个左右。而在差的模型中,下一个单词的候选个数有 5
个。
困惑度越小,分叉度越小,表明模型越好。
5.3 RNNLM的学习代码
p213
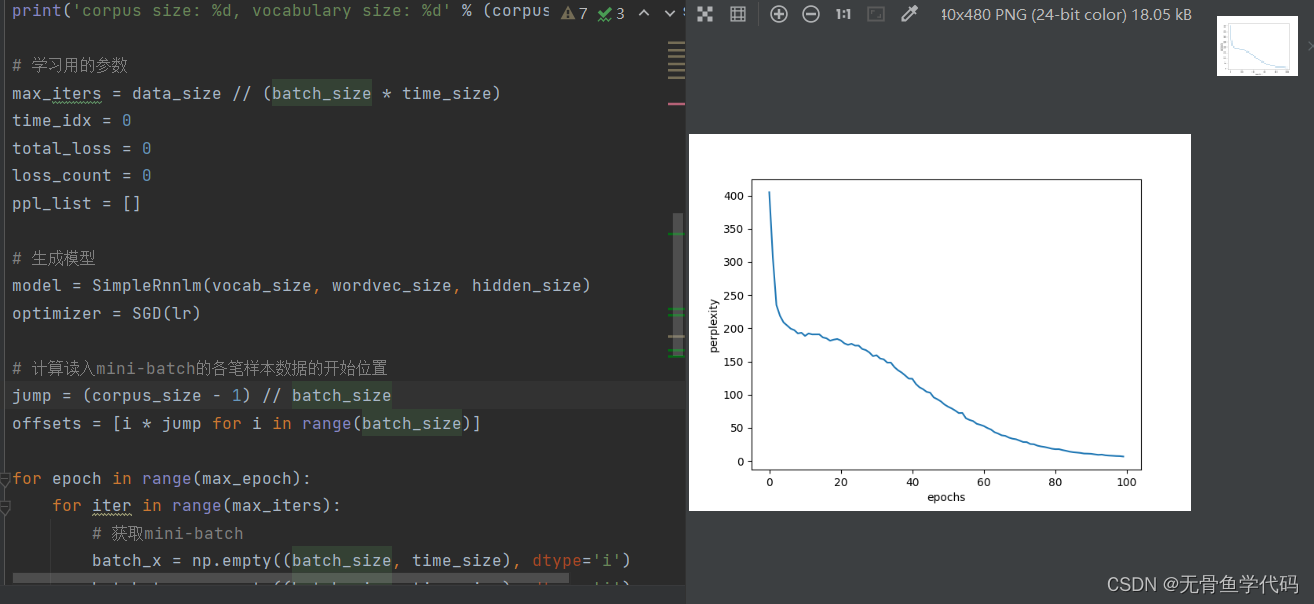
运行效果,困惑度明显下降。
5.4 RNNLM的Trainer类
p216
6 总结
RNN
通过数据的循环,从过去继承数据并传递到现在和未来。如此,RNN
层的内部获得了记忆隐藏状态的能力。















 677
677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









