






1 Attention的结构
基于
Attention
机制,
seq2seq
可以像我们人类一样,将“注意力”集中在必要的信息上。
1.1 seq2seq存在问题
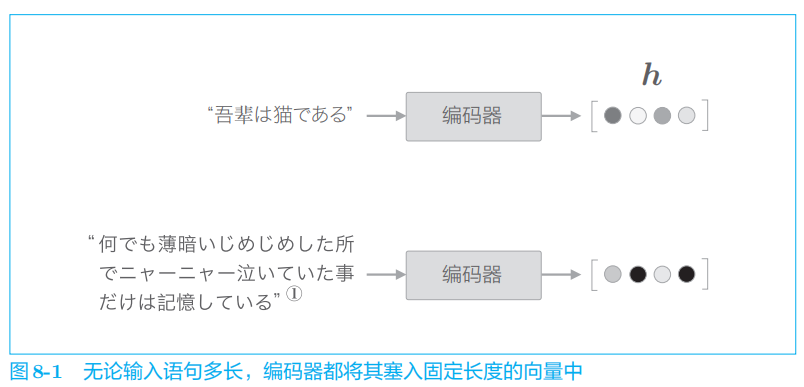

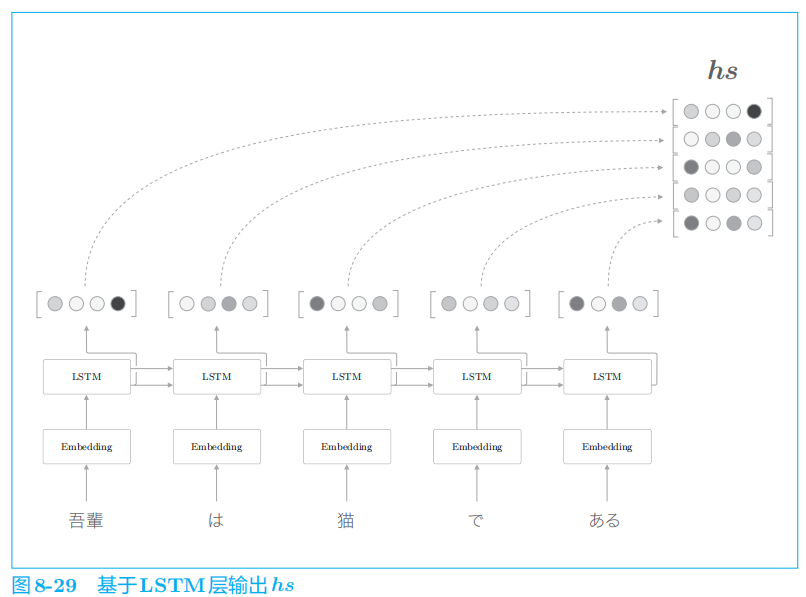
1.2 编码器的改进
编码器的输出的长度应该根据输入文本的长度相应地改变
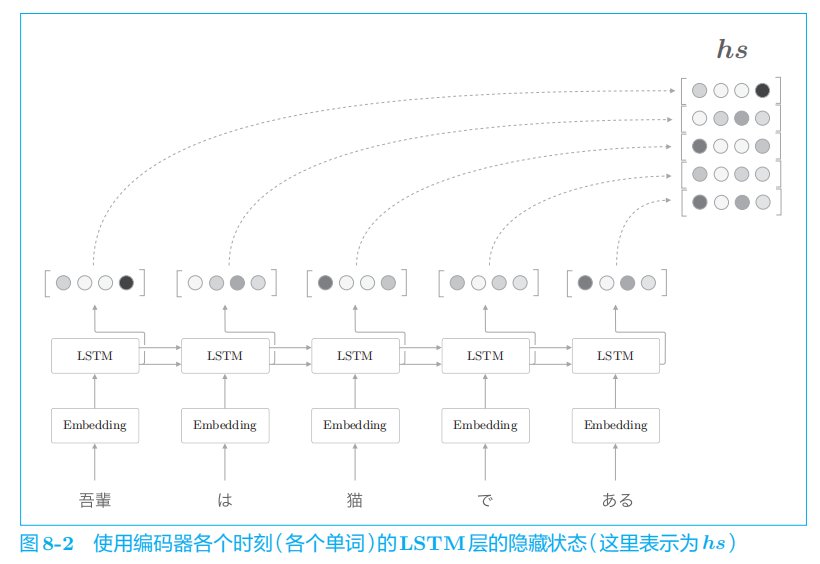
在图
8
-
2
的例子中,输入了
5
个单词,此时编码器输出 5
个向量。
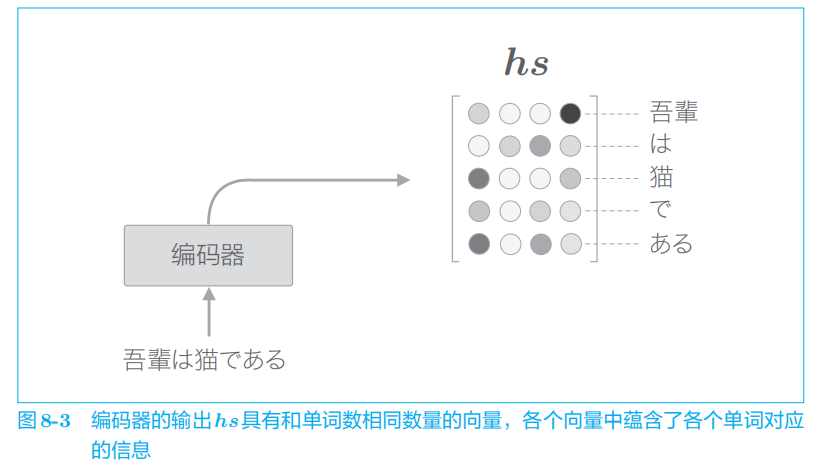
这里我们所做的改进只是将编码器的全部时刻的隐藏状态取出来而已。通过这个小改动,编码器可以根据输入语句的长度,成比例地编码信息。
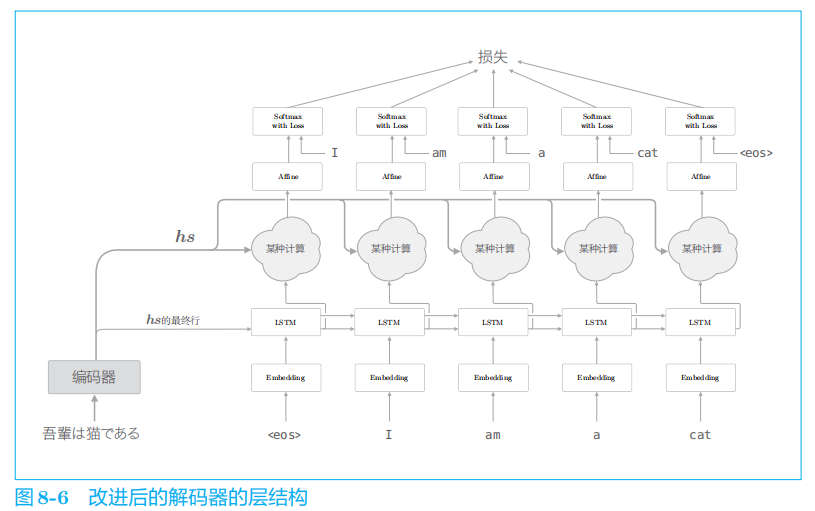
1.3 解码器的改进①
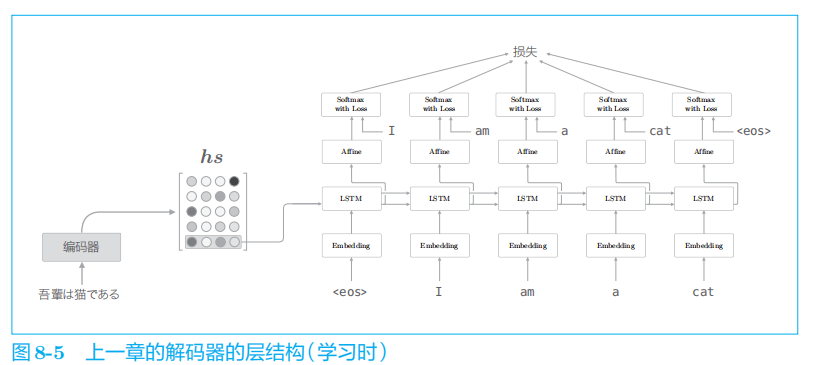
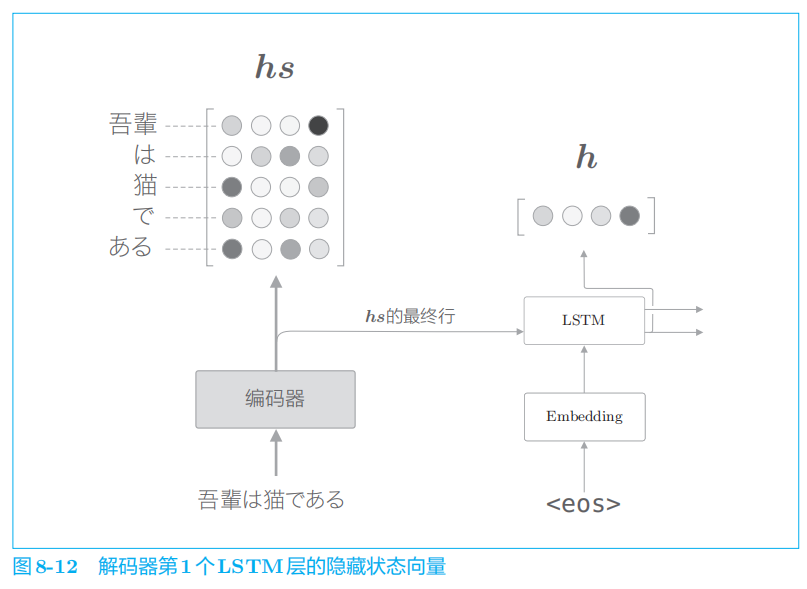
在上一章的最简单的
seq2seq
中,仅将编码器最后的隐藏状态向量传递给了解码器。




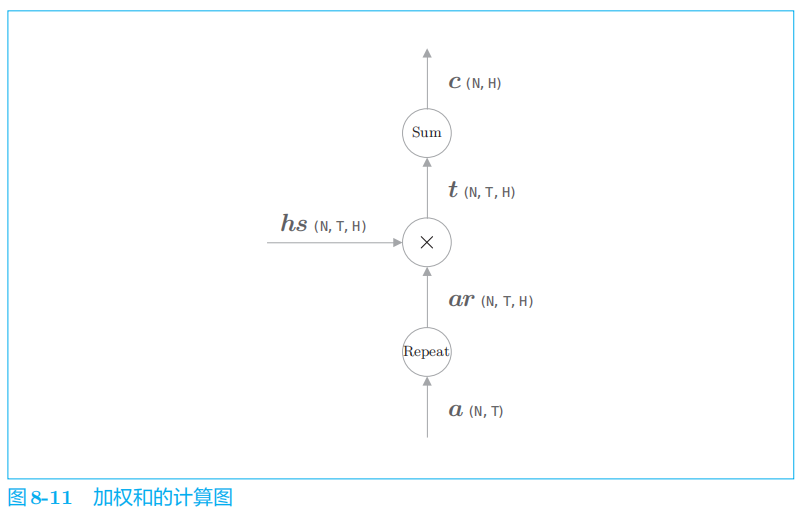
这里重述一下要点:“
Repeat
的反向传播是
Sum
”“
Sum
的反向传播是 Repeat
”。
将图
8
-
11
的计算图实现为层


1.4 解码器的改进②
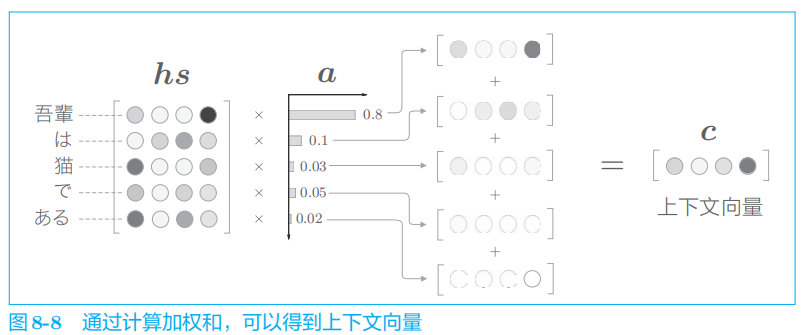
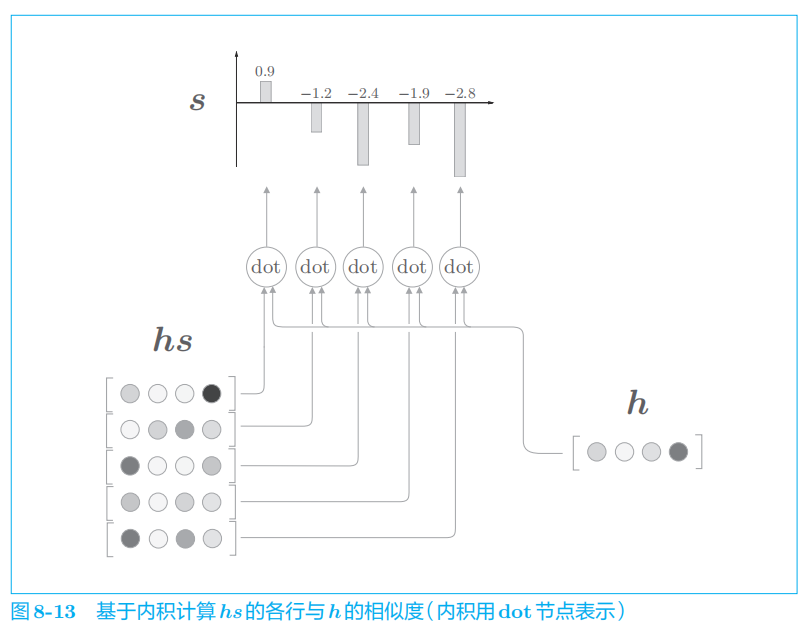
下面我们来看一下各个单词的权重
a
的求解方法。




1.5 解码器的改进③
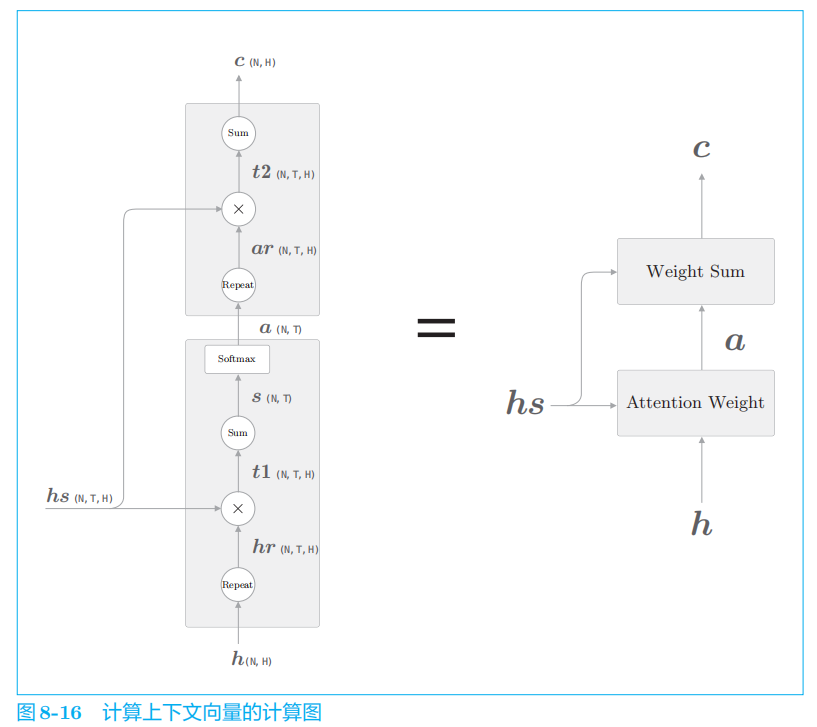
这里进行的计算是:Attention Weight
层关注编码器输出的各个单词向量
hs
,并计算各个单词的权重 a
;然后,
Weight Sum
层计算
a
和
hs
的加权和,并输出上下文向量 c
。我们将进行这一系列计算的层称为
Attention
层。


为了以后可以访问各个单词的权重,这里设定成员变量
attention_weight

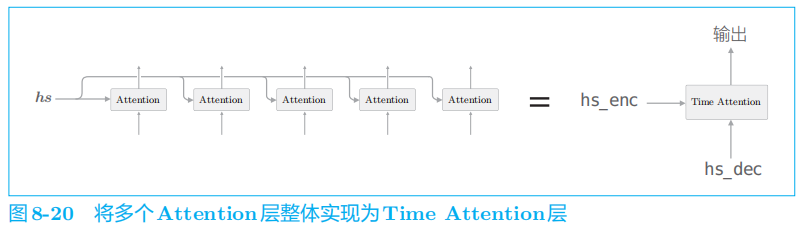


2 带Attention的seq2seq的实现
2.1 编码器的实现
首先实现
AttentionEncoder
类。这个类和上一章实现的
Encoder
类几乎一样,唯一的区别是,Encoder
类的
forward()
方法仅返回
LSTM
层的最后的隐藏状态向量,而AttentionEncoder
类则返回所有的隐藏状态向量。

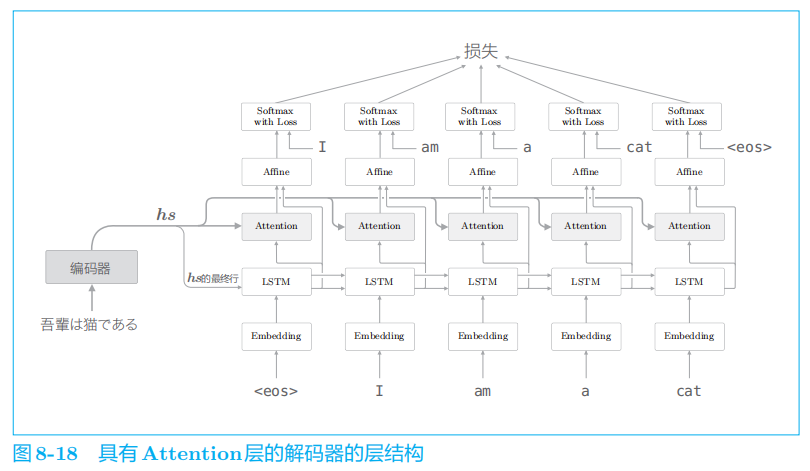
2.2 解码器的实现
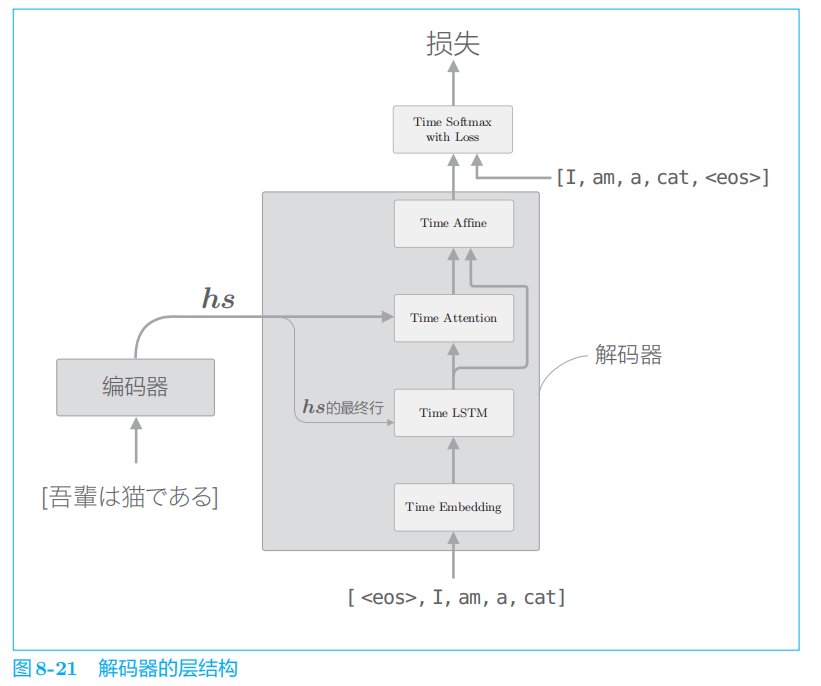
Softmax
层(更确切地说,是 Time Softmax with Loss
层)之前的层都作为解码器。

这里的实现除使用了新的
Time Attention
层之外,和上一章的
Decoder
类没有什么太大的不同。需要注意的是,forward()
方法中拼接了
Time Attention层的输出和 LSTM
层的输出。在上面的代码中,使用
np.concatenate()
方法进行拼接。
2.3 seq2seq的实现

3 Attention的评价
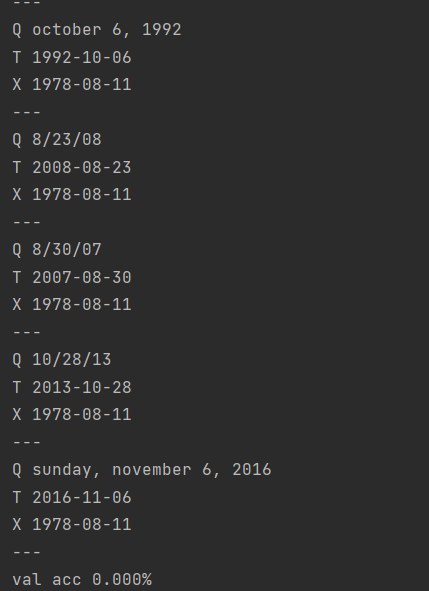
3.1 日期格式转换问题


代码p349



3.2 Attention的可视化
在进行时序转换时,实际观察Attention 在注意哪个元素。
因为在
Attention
层中,各个时刻的
Attention权重均保存到了成员变量中,所以我们可以轻松地进行可视化。



4 关于Attention的其它话题
4.1 双向RNN


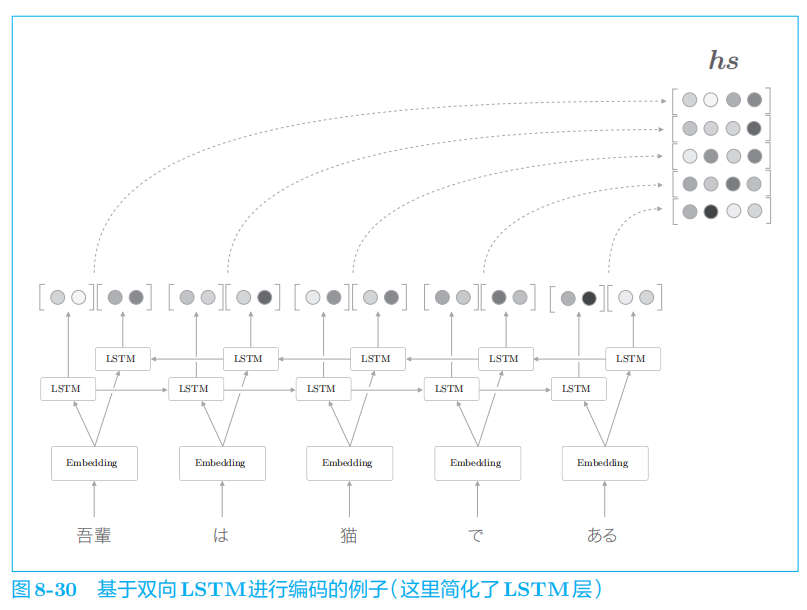

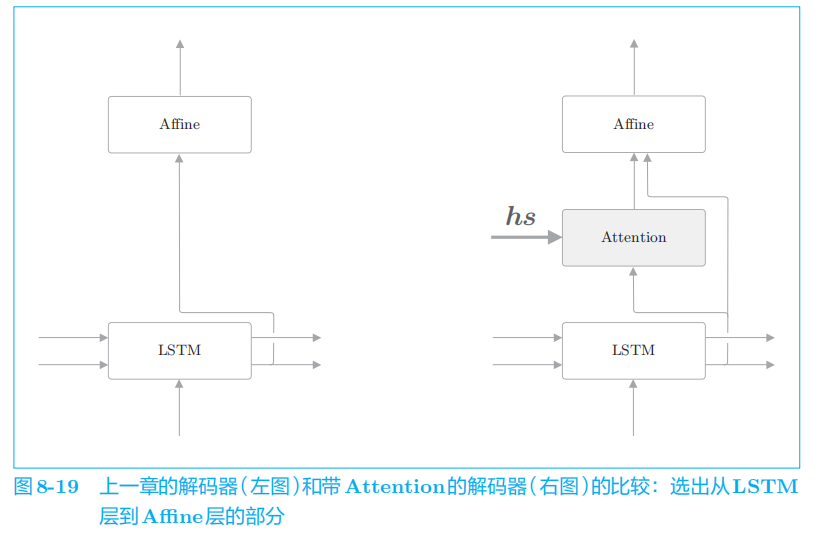
4.2 Attention层的使用方法
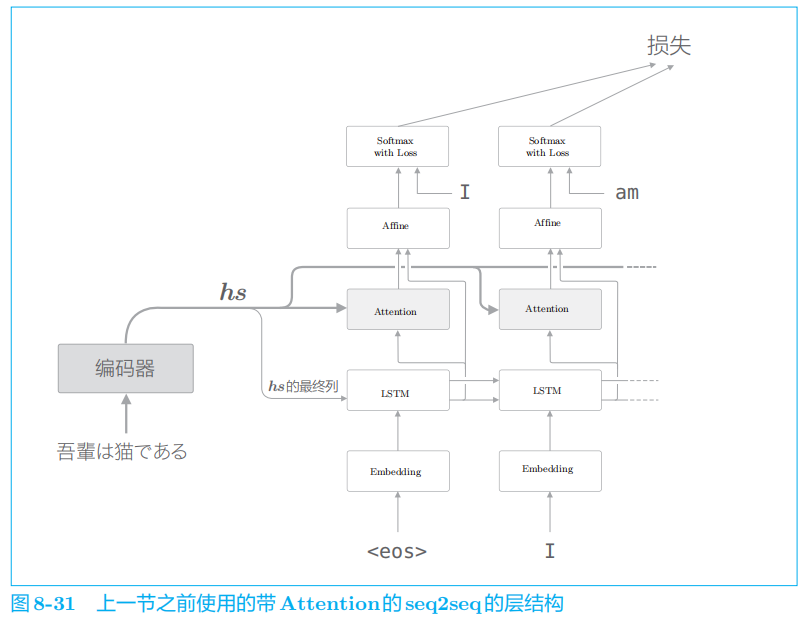

在图
8
-
32
中,
Attention
层的输出(上下文向量)被连接到了下一时刻的 LSTM
层的输入处。通过这种结构,
LSTM
层得以使用上下文向量的信息。相对地,我们实现的模型则是 Affine
层使用了上下文向量。

4.3 seq2seq的深层化和 skip connection
通过加深层,可以创建表现力更强的模型,带 Attention
的
seq2seq
也是如此。
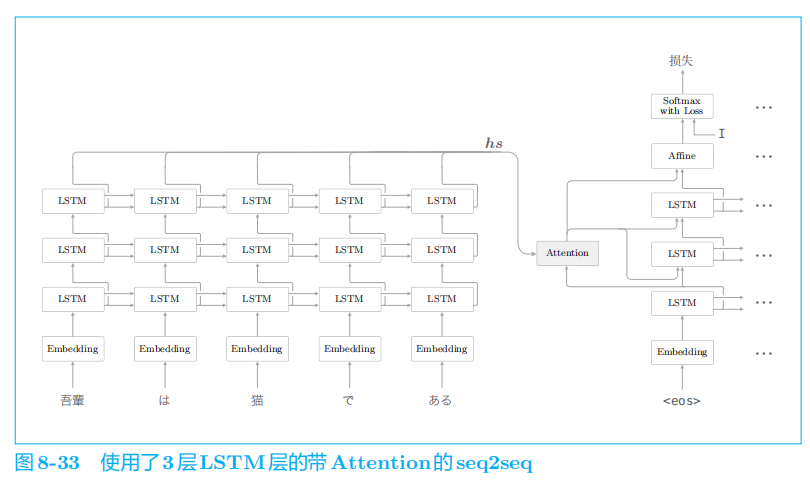
在图
8
-
33
的模型中,编码器和解码器使用了
3
层
LSTM
层。
在加深层时使用到的另一个重要技巧是
残差连接。
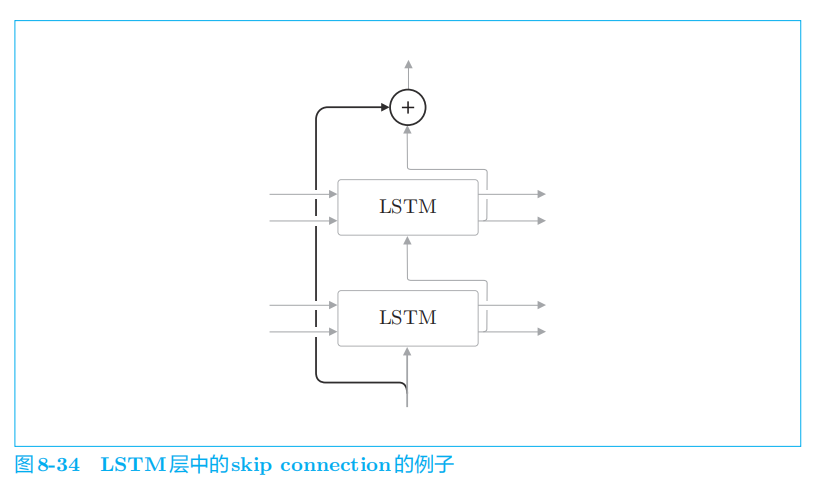
如图
8
-
34
所示,所谓残差连接,就是指“跨层连接”。此时,在残差连接的连接处,有两个输出被相加。
5 Attention的应用
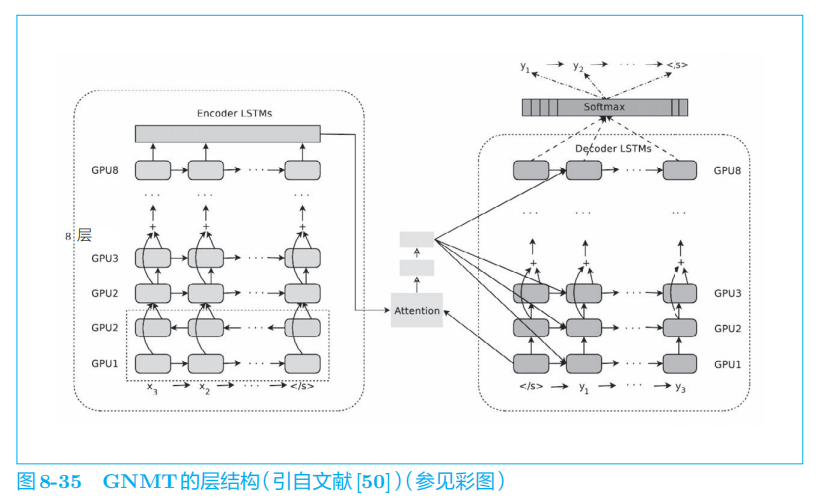
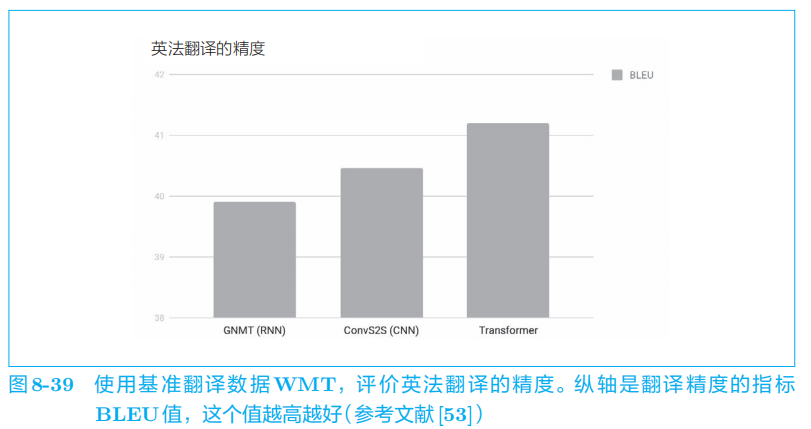
5.1 GNMT
谷歌神经机器翻译系统


5.2 Transformer
RNN
需要基于上一个时刻的计算结果逐步进行计算,因此(基本)不可能在时间方向上并行计算 RNN
。
Transformer
不用
RNN
,而用
Attention
进行处理。

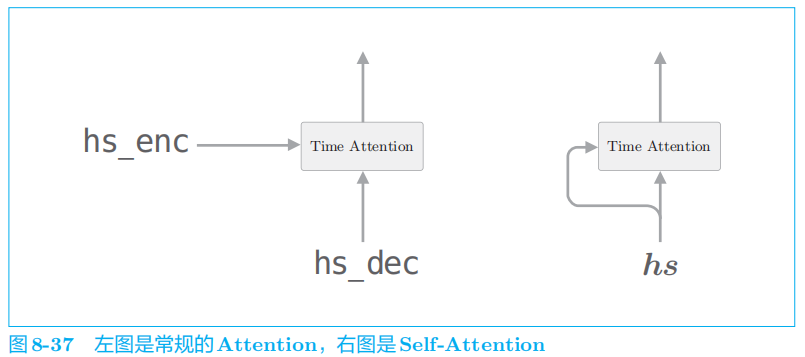
如图
8
-
37
的右图所示,
Self-Attention
的两个输入中输入的是同一个时序数据。像这样,可以求得一个时序数据内各个元素之间的对应关系。
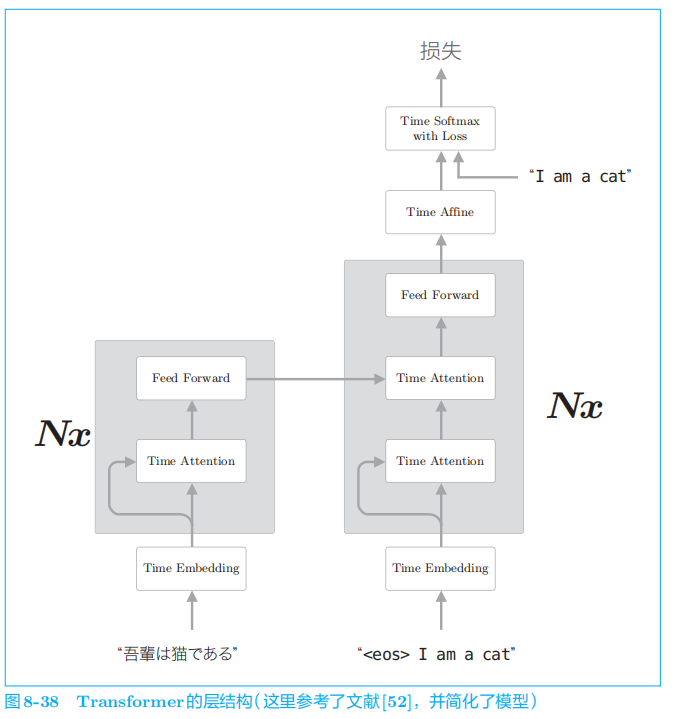
Transformer
中用
Attention
代替了
RNN
。
使用
Transformer
可以控制计算量,充分利用
GPU
并行计算带来的好处。其结果是,与 GNMT
相比,
Transformer
的学习时间得以大幅减少。
5.3 NTM
基于外部存储装置的扩展
在
RNN
的外部配置一个存储信息的存储装置,并使用
Attention向这个存储装置读写必要的信息。



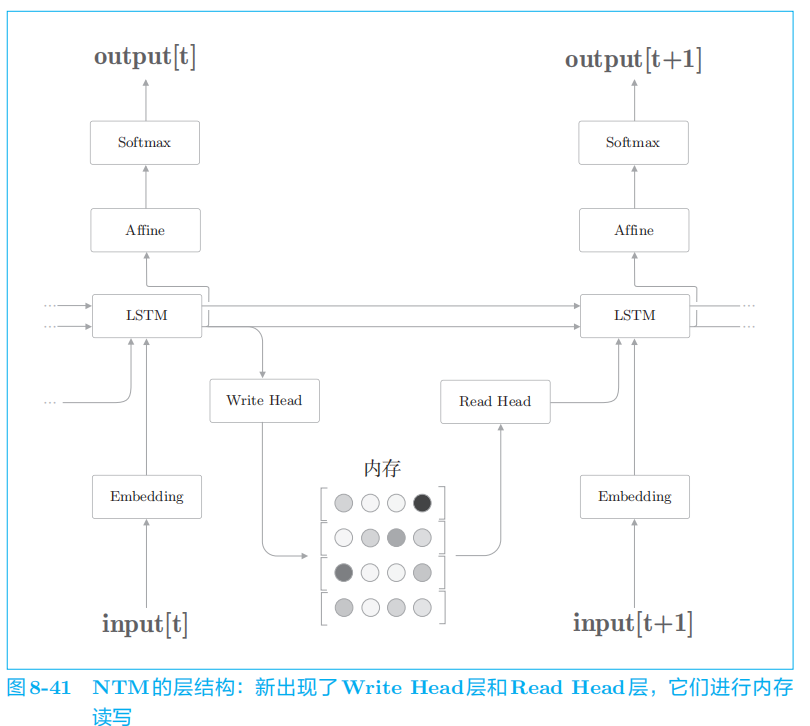
如此,
NTM
借助外部存储装置获得了学习算法的能力,其中
Attention作为一项重要技术而得到了应用。
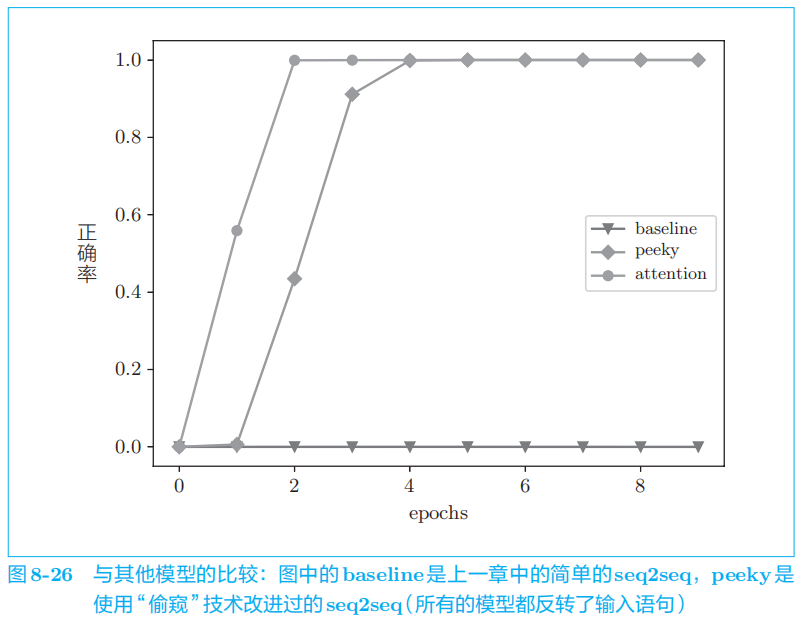
6 总结
使用
Attention
实现了 seq2seq,进行了简单实验,
从结果可知,具有
Attention
的模型以与人类相同的方式将注意力放在了必要的信息上。Attention的应用还有很多,在接下来的学习中还会派上大用场。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









