






word2vec中最大的问题是,随着语料库中处理的词汇量的增加,计算量也随之增加。
对上一章中简单的
word2vec
进行两点改进:引入名为Embedding 层的新层,以及引入名为
Negative Sampling
的新损失函数。
1 word2vec的改进①
假设词汇量有 100 万个,CBOW 模型的中间层神经元有 100 个
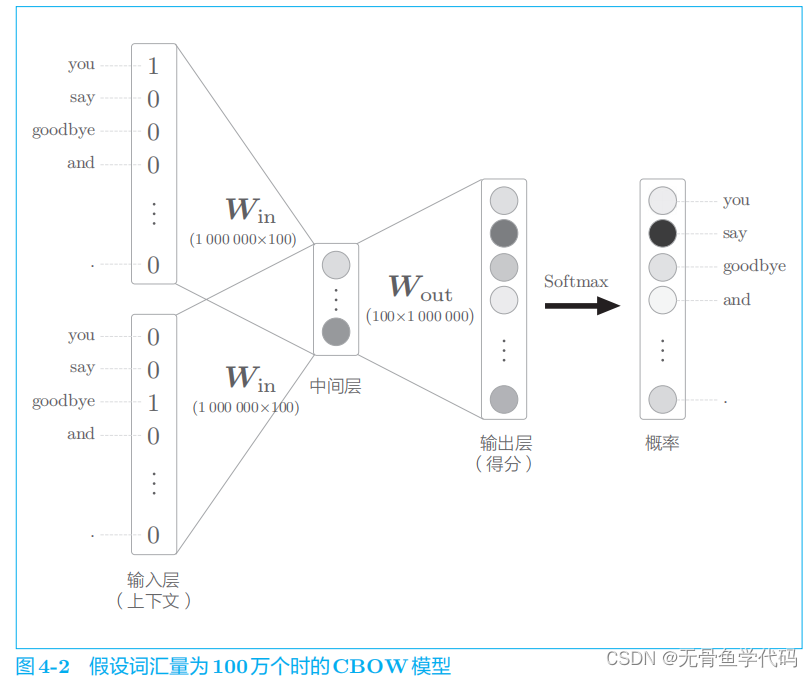
存在问题:



1.1 Embedding层
在上一章的
word2vec
实现中,我们将单词转化为了
one-hot
表示,并将其输入了 MatMul
层,在
MatMul
层中计算了该
one-hot
表示和权重矩阵的乘积。
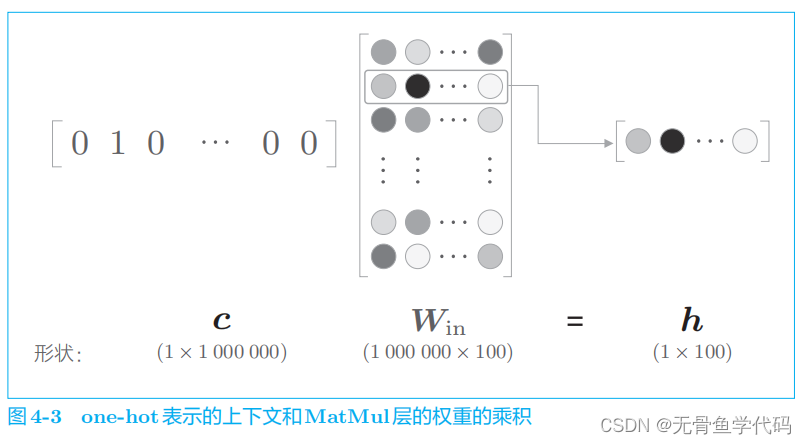
图
4
-
3
中所做的无非是将矩阵的某个特定的行取出来。
现在,我们创建一个从权重参数中抽取“单词
ID
对应行(向量)”的层,这里我们称之为Embedding
层。
1.2 Embedding层的实现
从矩阵中取出某一行的处理是很容易实现的。
例子:


多行里的实现假定用于mini-batch 处理。
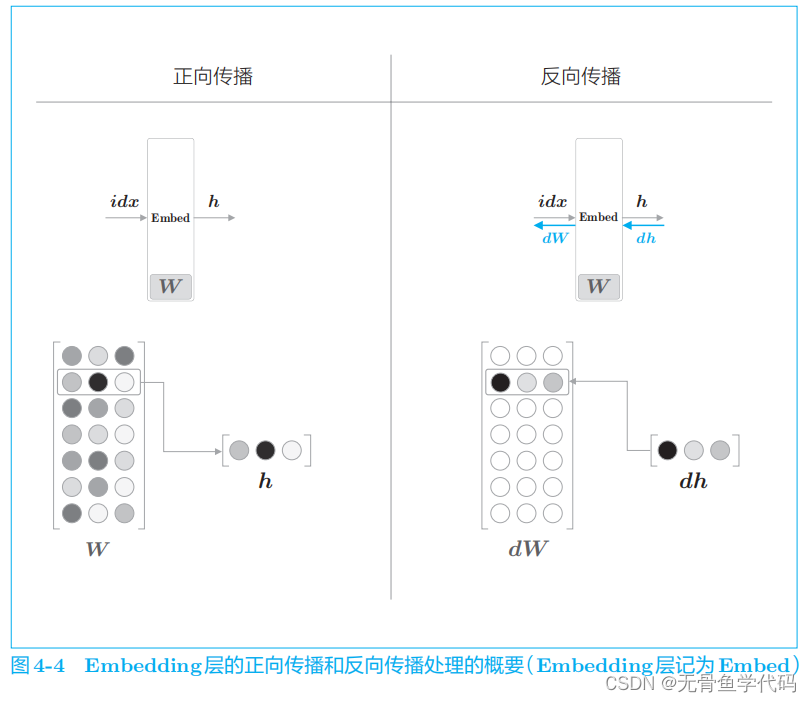
Embedding
层的正向传播只是从权重矩阵 W 中提取特定的行,并将该特定行的神经元原样传给下一层。因此,在反向传播时,从上一层(输出侧的层)传过来的梯度将原样传给下一层(输
入侧的层)。不过,从上一层传来的梯度会被应用到权重梯度
dW
的特定行
(
idx
)

这样处理存在一个问题,这一问题发生在 idx
的元素出现重复时。
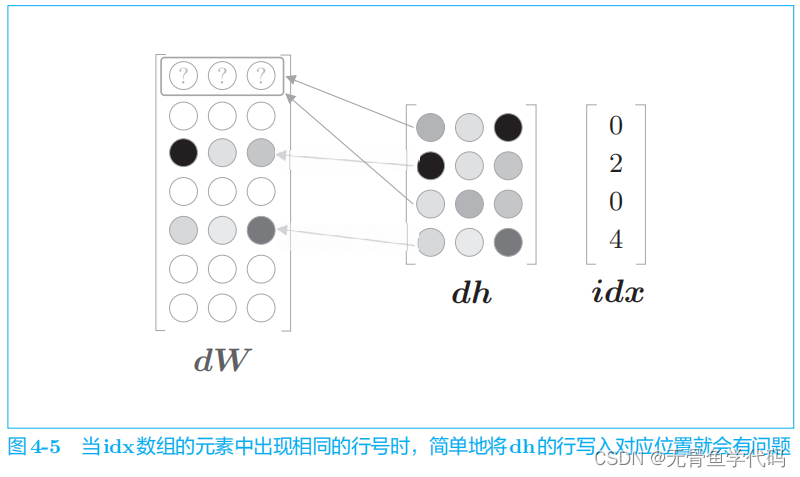
为了解决这个重复问题,需要进行“加法”,而不是“写入”(请读者考虑一下为什么是加法)。也就是说,应该把 dh
各行的值累加到
dW
的对应行中。


现在,我们可以将
word2vec(CBOW
模型)的实现中的输入侧的
MatMul
层换成
Embedding
层。这样一来,既能减少内存使用量,又能避免不必要的计算。
2 word2vec的改进②
word2vec
的另一个瓶颈在于中间层之后的处理,即矩阵乘积和 Softmax 层的计算。



















这里,我们将采用名为
负采样
(
negative sampling
)的方法作为解决方案。使用 Negative Sampling
替代
Softmax
,无论词汇量有多大,都可以使计算量保持较低或恒定。
2.1 中间层之后的计算问题
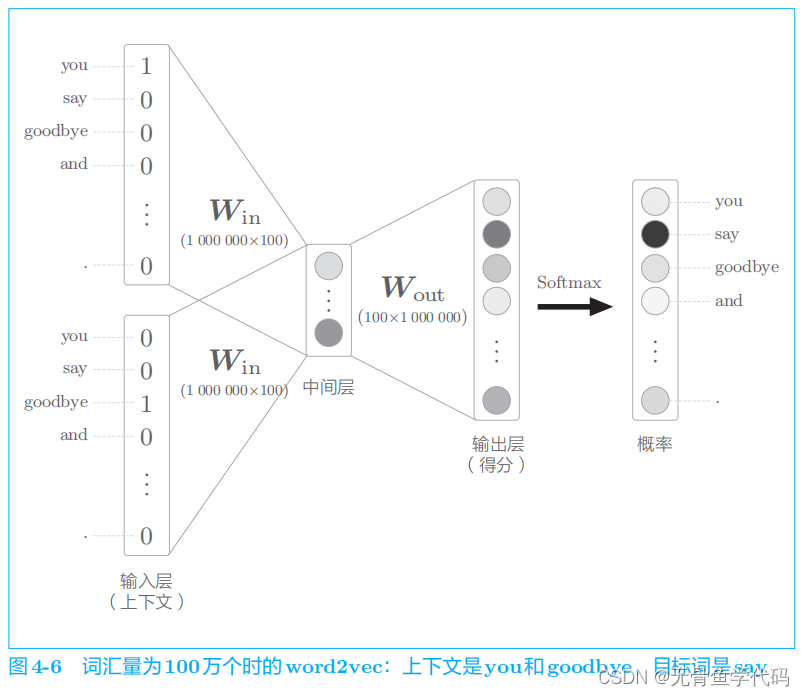
在以下两个地方需要很多计算时间。
2.2 从多分类到二分类
负采样这的关键思想在于二分类。
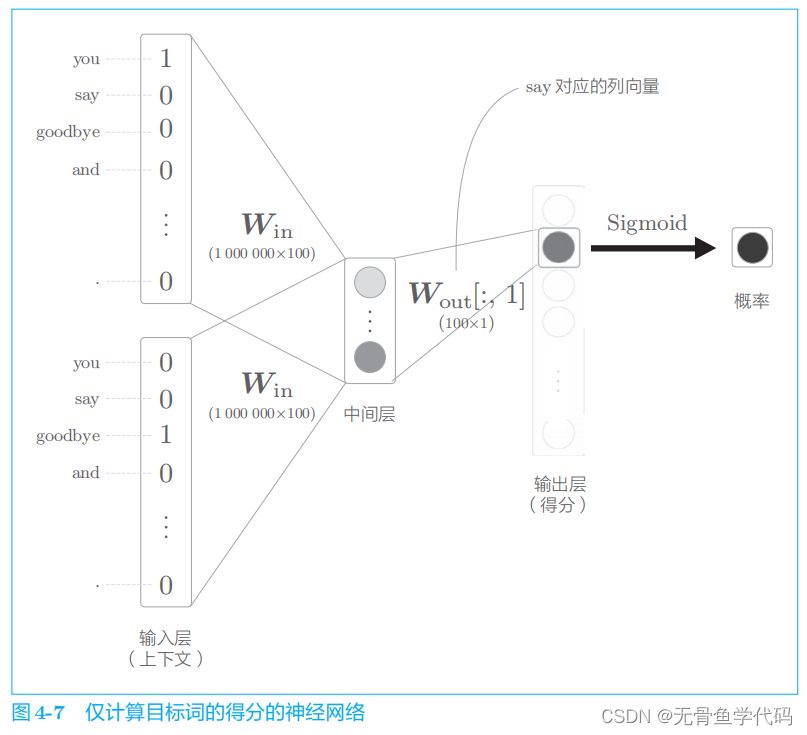
比如,让神经网络来回答“当上下文是 you
和
goodbye
时,目标词是
say
吗?”这个问题,这时输出层只需要一个神经元即可。可以认为输出层的神经元输出的是 say
的得分。
因此,要计算中间层和输出侧的权重矩阵的乘积,只需要提取 say
对应的列(单词向量),并用它与中间层的神经元计算内积即可。
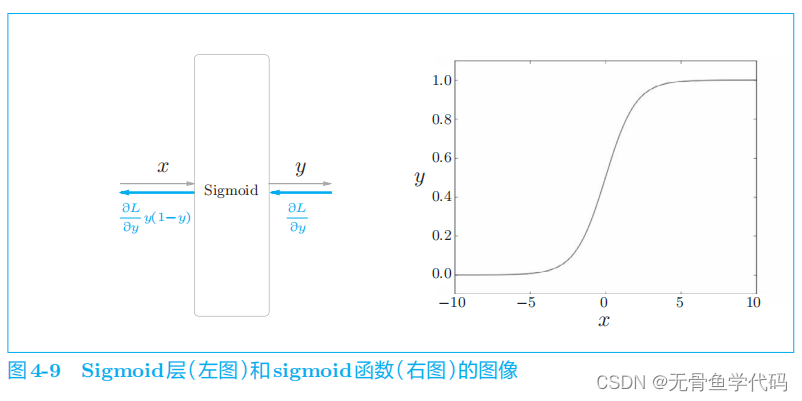
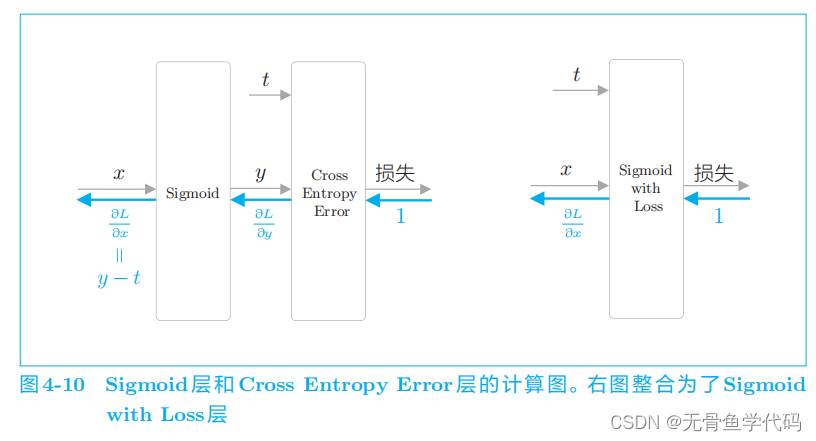
2.3 sigmoid函数和交叉熵误差
要使用神经网络解决二分类问题,需要使用
sigmoid
函数将得分转化为概率。为了求损失,我们使用交叉熵误差作为损失函数。这些都是二分类神经网络的老套路。
2.4 多分类到二分类的实现
把重点放在“层”和“计算”上
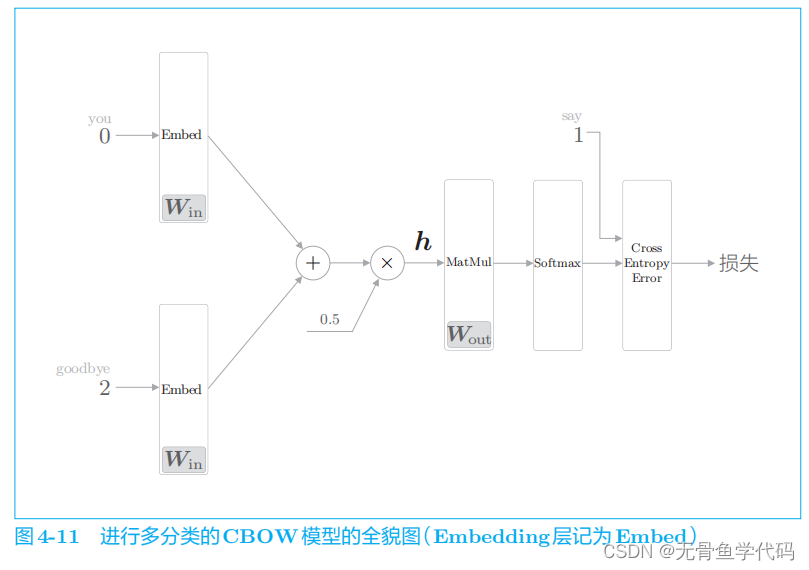
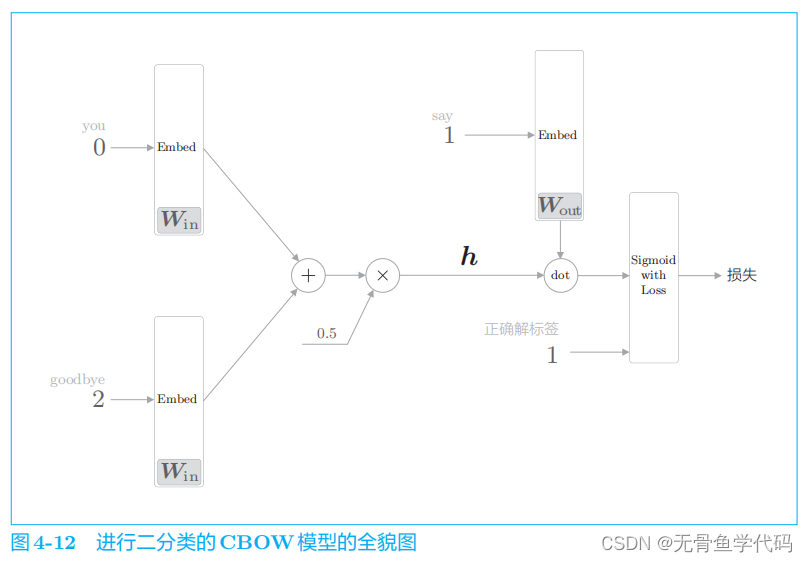
将图
4
-
11
中的神经网络转化成进行二分类的神经网络
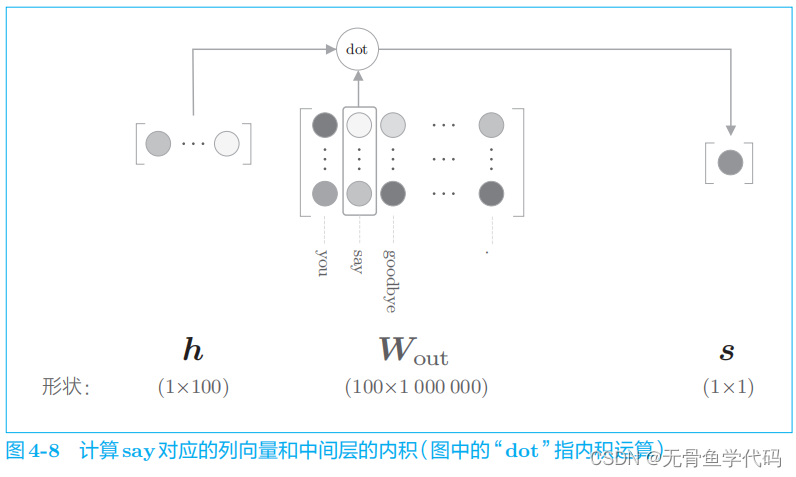
这里,将中间层的神经元记为
h
,并计算它与输出侧权重
W
out
中的单词 say
对应的单词向量的内积。然后,将其输出输入
Sigmoid with Loss
层,得到最终的损失。
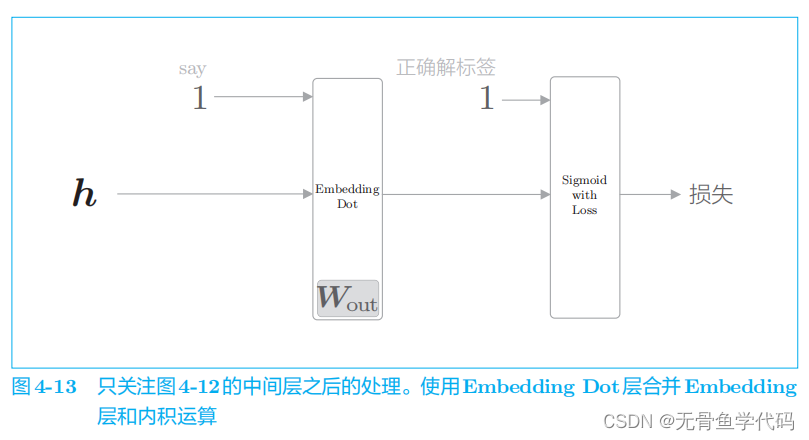
把图
4
-
12 的后半部分进一步简化,引入
Embedding Dot
层。
Embedding Dot
层的实现:
结果逐行(axis=1
)进行求和。
2.5 负采样
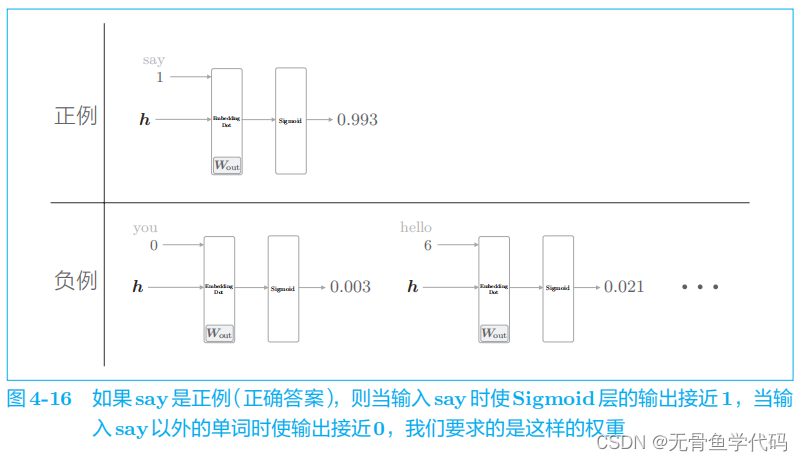
要考虑负例,即不是正解的答案。
我们真正要做的事情是,对于正例(
say
),使
Sigmoid
层的输出接近
1
;对于负例(say
以外的单词),使
Sigmoid
层的输出接近
0
。
但不需要学习所有负例,只需选择若干个即可,这就是负采样的含义。
总而言之,负采样方法既可以求将正例作为目标词时的损失,同时也可以采样(选出)若干个负例,对这些负例求损失。然后,将这些数据(正例和采样出来的负例)的损失加起来,将其结果作为最终的损失。
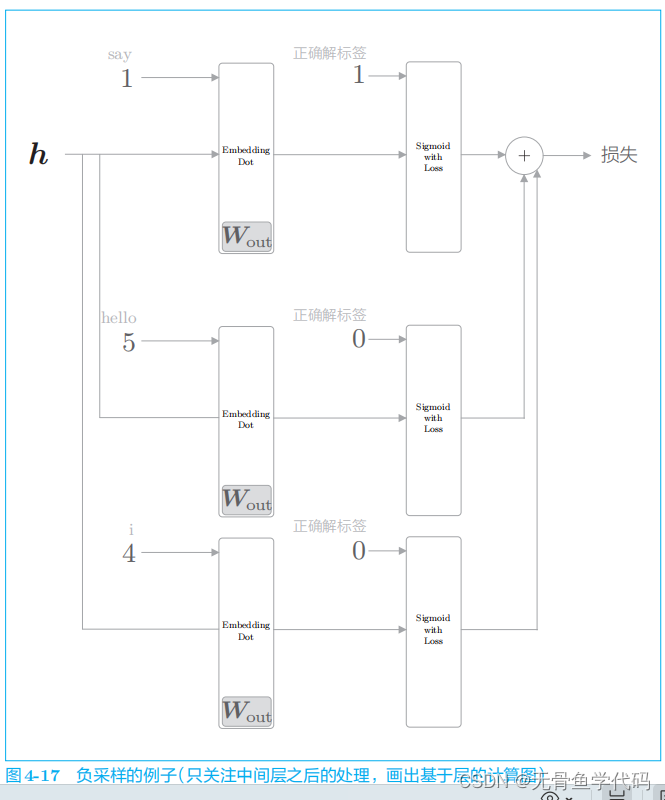
例子:只关注
CBOW
模型的中间层之后的部分
图4
-
17
中需要注意的是对正例和负例的处理。正例(
say
)和之前一样,向 Sigmoid with Loss
层输入正确解标签
1
;而因为负例(
hello
和
i
)是错误答案,所以要向 Sigmoid with Loss
层输入正确解标签
0
。此后,将各个数据的损失相加,作为最终损失输出。
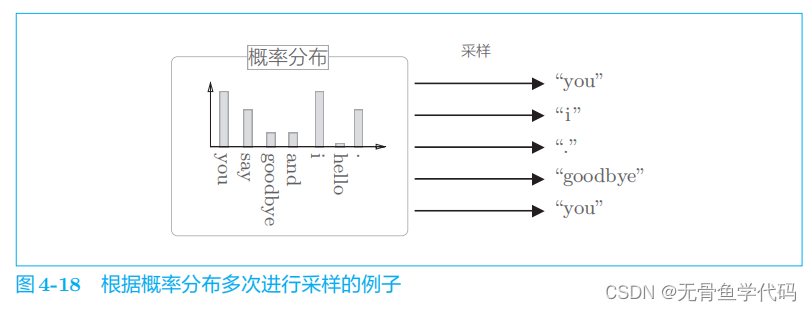
2.6 负采样的采样方法
让语料库中经常出现的单词容易被抽到,让语料库中不经常出现的单词难以被抽到。
可以使用NumPy 的
np.random.choice()
方法。
例:
word2vec 中提出的负采样对刚才的概率分布增加了一个步骤,对原来的概率分布取
0
.
75
次方。

2.7 负采样的实现
p154
3 改进版word2vec的学习
3.1 CBOW模型实现
P156
3.2 CBOW模型学习代码
ch04/train.py 运行这个代码可以获得学习好的参数,用cpu运行时间会很久,建议用GPU运行,需安装Cupy。
3.3 CBOW的评价


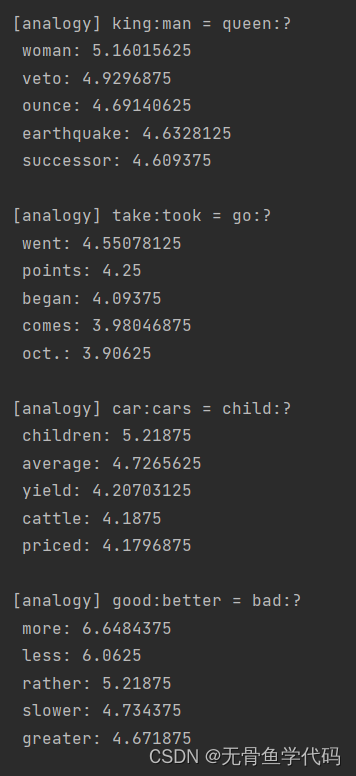
cbow_params.pkl是训练好的数据,这里用来实现例子结果如下:
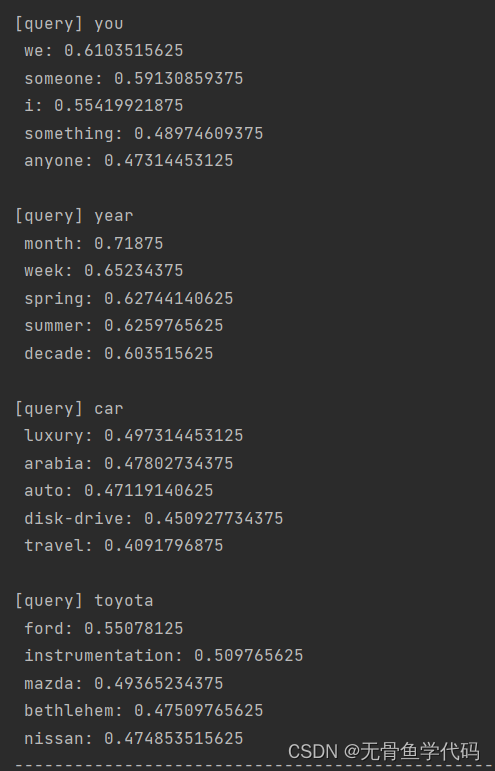
从这些结果可以看出,由CBOW 模型获得的单词的分布式表示具有良好的性质。
此外还可以解决更复杂的模式,例如类推:
使用这个函数,可以用
analogy('man', 'king', 'woman', word_to_id, id_to_word, word_vecs, top=5) 这样
1
行代码来回答刚才的类推问题。
像这样,使用
word2vec
获得的单词的分布式表示,可以通过向量的加减法求解类推问题。不仅限于单词的含义,它也捕获了语法中的模式。
4 word2vec相关话题
在自然语言处理领域,单词的分布式表示之所以重要,原因就在于
迁移学习
(
transfer learning
)。迁移学习是指在某个领域学到的知识可以被应用于其他领域。
单词的分布式表示的优点是可以将单词转化为固定长度的向量。
在第
5
章中说明的循环神经网络,可以以更加优美的方式利用word2vec 的单词的分布式表示来将文档转化为固定长度的向量。
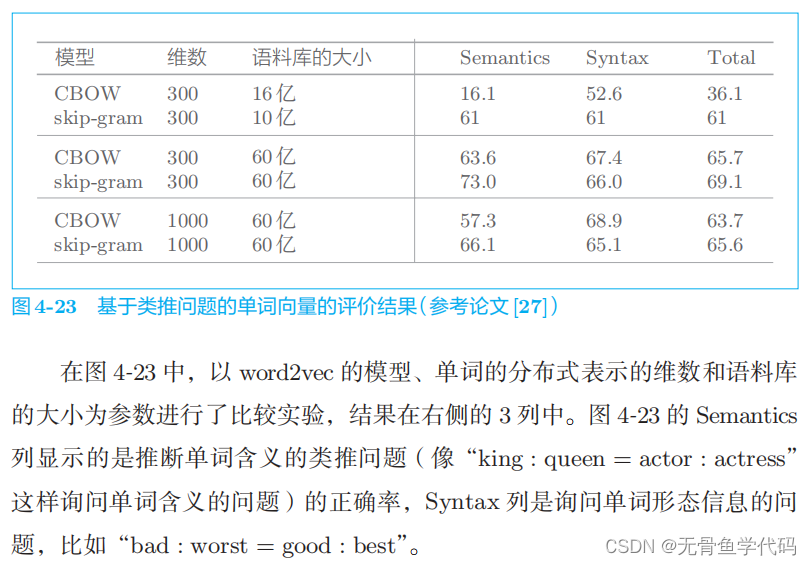
4.1 单词向量的评价方法


5 总结
利用“部分”数据而不是“全部”数据,这是本章的一个重要话题。
仅处理对我们有用的那一小部分数据会有更好的效果。本章我
们仔细研究了基于这一思想的负采样技术。负采样通过仅关注部分单词实现
了计算的高速化。















 3471
3471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









