







基于熵权法对Topsis模型的修正
一、介绍
1、层次分析法的缺点
判断矩阵的确定依赖于专家,如果专家的判断存在主观性的话,会对结果产生很大影响(主观性太强)
2、熵权法原理
指标的变异程度越小,所反映的信息量也越少,其对应的权值也越低。所以熵权法的客观体现在数据本身就可以告诉我们权重大小,那使用熵权法也有一定前提:数据。
3、如何度量信息量大小
1)定性
越有可能发生的事,所包含的信息量越少;越不可能发生的事,所包含的信息量越多,因为他把不可能的事变成可能了,那么概率就可以度量信息量大小。
2)定量
把信息量大小用I表示,概率用p表示,建立函数关系:
I
(
x
)
=
−
l
n
(
p
(
x
)
)
I(x)=-ln(p(x))
I(x)=−ln(p(x))
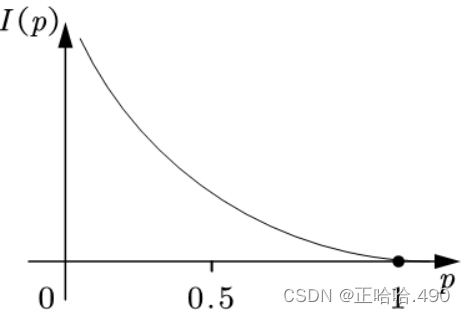
由图可知,当一件事必然发生时能从这件事中获取的信息量为0。
4、信息熵
1)定义
事件X可能发生的情况分别为 x 1 、 x 2 、 x 3 . . . . . x n . x_{1}、x_{2}、x_{3}.....x_{n}. x1、x2、x3.....xn.所以信息熵的定义就是X可能发生的情况的概率和每个情况所代表的信息量的乘积和,具体公式如下: H ( x ) = ∑ i = 1 n [ p ( x i ) I ( x i ) ] = − ∑ i = 1 n [ p ( x i ) l n ( p ( x i ) ) ] H(x)=\sum_{i=1}^{n} [p(x_{i})I(x_{i})]=-\sum_{i=1}^{n}[p(x_{i})ln(p(x_{i}))] H(x)=i=1∑n[p(xi)I(xi)]=−i=1∑n[p(xi)ln(p(xi))]
二、熵权法的计算步骤
1)因为概率是大于等于0的数,所以判断输入的矩阵中是否存在负数,如果有则要重新标准化到非负区间,对于一个已经正向化的矩阵X,对其标准化成Z矩阵,其中
z
i
j
=
x
i
j
/
∑
i
=
1
n
x
i
j
2
z_{ij}=x_{ij}/\sqrt{\sum_{i=1}^{n}x_{ij}^{2} }
zij=xij/i=1∑nxij2
判断Z矩阵中是否存在负数,如果存在需要对X矩阵是用另一种标准化方式
z
i
j
~
=
x
i
j
−
m
i
n
(
x
1
j
,
x
2
j
,
.
.
.
,
x
n
j
)
m
a
x
(
x
1
j
,
x
2
j
,
.
.
.
,
x
n
j
)
−
m
i
n
(
x
1
j
,
x
2
j
,
.
.
.
,
x
n
j
)
\tilde{z_{ij}}= \frac{x_{ij}-min(x_{1j},x_{2j},...,x_{nj})}{max(x_{1j},x_{2j},...,x_{nj})-min(x_{1j},x_{2j},...,x_{nj})}
zij~=max(x1j,x2j,...,xnj)−min(x1j,x2j,...,xnj)xij−min(x1j,x2j,...,xnj)
2)计算第j项指标下第i个样本所占的比重,并将其看作相对熵计算中用到的概率
假设有n个要评价的对象,m个评价指标,且已经经过上一步处理得到的非负矩阵为:
Z
~
=
[
z
11
~
z
12
~
.
.
.
z
1
m
~
z
21
~
z
22
~
.
.
.
z
2
m
~
.
.
.
.
.
.
.
.
.
.
.
.
z
n
1
~
z
n
2
~
.
.
.
z
n
m
~
]
\tilde{Z}= \begin{bmatrix} \tilde{z_{11}} &\tilde{z_{12}} &... &\tilde{z_{1m}} \\ \tilde{z_{21}}&\tilde{z_{22}} &... &\tilde{z_{2m}} \\ ...& ... & ... &... \\ \tilde{z_{n1}} & \tilde{z_{n2}}& ... &\tilde{z_{nm}} \end{bmatrix}
Z~=⎣
⎡z11~z21~...zn1~z12~z22~...zn2~............z1m~z2m~...znm~⎦
⎤
我们计算概率矩阵P其中P的每一个元素Pij的计算公式如下:
p
i
j
=
z
i
j
~
∑
i
=
1
n
z
i
j
~
p_{ij}= \frac{\tilde{z_{ij}}}{\sum_{i=1}^{n}\tilde{z_{ij}} }
pij=∑i=1nzij~zij~
3)计算每个指标的信息熵,并计算信息效用值,并归一化得到每个指标的熵权
对于第j个指标来说,其信息熵的计算公式为:
e
j
=
−
1
ln
n
∑
i
=
1
n
p
i
j
ln
p
i
j
e_{j}=-\frac{1}{\ln_{}{n} } \sum_{i=1}^{n} p_{ij}\ln _{}{p_{ij}}
ej=−lnn1i=1∑npijlnpij
信息效用值的定义:
d
j
=
1
−
e
j
d_{j}=1-e_{j}
dj=1−ej那么信息效用值越大,其对应的信息就越多,将信息效用值进行归一化,我们就能得到每个指标的熵权:
W
j
=
d
j
∑
j
=
1
m
d
j
W_{j}=\frac{d_{j}}{\sum_{j=1}^{m}d_{j} }
Wj=∑j=1mdjdj
三、熵权法的问题
熵权法的另一个问题:因为概率p是位于0‐1之间,因此需要对原始数据进行标准化,我们应该选择哪种方式进行标准化呢?查看知网的文献会发现,并没有约定俗成的标准,每个人的选取可能都不一样。但是不同方式标准化得到的结果可能有很大差异,所以说熵权法也是存在着一定的问题的。
如果大家的论文要发表,别用熵权法如果大家只是用这个方法进行比赛那么可以随便用因为这个方法总比你自己随意定义好














 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









