






在前几周,已经看完了吴恩达的机器学习的一些基础,最近,在看李沐老师的动手学深度学习,跟着李沐老师熟悉代码,并且配合着周志华老师的"西瓜书",不过"西瓜书"并不适合零基础学习的人,里面的数学公式确实有一些难理解,所以我配合着"南瓜书","南瓜书"里面是西瓜书里面重要的公式的详细推导,对于我理解其公式有了很大的帮助。
下面是我这一周的对李沐老师的动手学深度学习的代码的一些整理,李沐老师的代码写的真的很好,我自己刚开始理解也有些难度。
目录
线性回归的从零开始实现
1、引入相关的模块
%matplotlib inline
import random
import torch
from d2l import torch as d2l2、构造个人的数据集
def synthetic_data(w,b,num_examples):
X = torch.normal(0,1,(num_examples,len(w))) # 均值为0,方差为1,样本量,样本长度
y = torch.matmul(X,w)+b # 矩阵乘法
y += torch.normal(0,0.01,y.shape) # 增加噪音
return X,y.reshape((-1,1)) # 列向量返回
true_w = torch.tensor([2,-3.4]) # 自己设定的w值
true_b = 4.2 # 自己设定的b值
features,labels = synthetic_data(true_w,true_b,1000) # 特征和标签3、所以我们的特征有2个,有1000个样本
features.shape # 特征
# torch.Size([1000, 2])
labels.shape # 标签
# torch.Size([1000, 1])4、定义一个data_iter函数,该函数接收批量大小,特征矩阵,标签作为输入,生成大小为batch_size的小批量
def data_iter(batch_size,features,labels):
num_examples = len(features)
indicies = list(range(num_examples))
# 随机读取
random.shuffle(indicies)
for i in range(0,num_examples,batch_size):
batch_indices = torch.tensor(indicies[i:min(i+batch_size,num_examples)])
yield features[batch_indices],labels[batch_indices] # yield迭代
batch_size = 10
for X,y in data_iter(batch_size,features,labels):
print(X,'\n',y)
break
'''
tensor([[ 0.4932, -0.7527],
[ 0.5119, -0.8836],
[ 2.1021, 0.8762],
[-0.5891, 0.0294],
[-0.9463, -0.7159],
[-1.3354, -0.6503],
[-0.1908, 1.3229],
[-0.2472, 2.3124],
[-1.0342, -0.5709],
[-0.7782, 2.5734]])
tensor([[ 7.7466],
[ 8.2369],
[ 5.4165],
[ 2.9225],
[ 4.7335],
[ 3.7457],
[-0.6926],
[-4.1402],
[ 4.0891],
[-6.0984]])
'''5、定义初始化模型参数
w = torch.normal(0,0.01,size=(2,1),requires_grad=True)
b = torch.zeros(1,requires_grad=True)6、定义模型
def linreg(X,w,b):
# 线性回归模型
return torch.matmul(X,w) + b7、定义损失函数
def squared_loss(y_hat,y):
# 均方损失
return (y_hat-y.reshape(y_hat.shape))**2 / 2 # 预测值-真实值8、定义梯度下降优化算法
def sgd(params,lr,batch_size):
# 小批量随机梯度下降
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()9、训练
lr = 0.001 # 学习率
num_epochs = 10 # 训练次数
net = linreg # 线性回归
loss = squared_loss # 均方误差
for epoch in range(num_epochs):
for X,y in data_iter(batch_size,features,labels):
l = loss(net(X,w,b),y)
l.sum().backward()
sgd([w,b],lr,batch_size)
with torch.no_grad():
train_l = loss(net(features,w,b),labels)
print(f'epoch {epoch + 1},loss {float(train_l.mean()):f}')
'''
epoch 1,loss 7.474454
epoch 2,loss 6.077838
epoch 3,loss 4.942935
epoch 4,loss 4.020611
epoch 5,loss 3.270874
epoch 6,loss 2.661391
epoch 7,loss 2.165851
epoch 8,loss 1.762883
epoch 9,loss 1.435153
epoch 10,loss 1.168562
'''10、比较真实参数和通过训练学到的参数来评估训练的成功程度
print(f'w的估计误差:{true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差:{true_b - b}')
'''
w的估计误差:tensor([ 0.6398, -0.8977], grad_fn=<SubBackward0>)
b的估计误差:tensor([1.0361], grad_fn=<RsubBackward1>)
'''线性回归的简洁实现
1、引入相关模块
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l2、设置w,b值,生成特征和标签
true_w = torch.tensor([2,-3.4])
true_b = 4.2
features,labels = d2l.synthetic_data(true_w,true_b,1000) # 此处可以调包,还可以自己生成特征和标签3、定义load_array函数,接收批量大小,通过构造数据迭代器,生成data_iter的一个dataloader对象的实例
def load_array(data_arrays,batch_size,is_train=True):
# 构造一个pytorch数据迭代器
dataset = data.TensorDataset(*data_arrays) # 接受一系列张量作为输入,并将它们打包成数据集。星号表示对元祖解包
# python中 *表示解包操作,他可以将一个包含多个元素的元祖,列表,集合等数据结构解压为多个独立元素
return data.DataLoader(dataset,batch_size,shuffle=is_train) # 批量,打乱数据
batch_size = 10
data_iter = load_array((features,labels),batch_size)
next(iter(data_iter))
'''
[tensor([[ 1.8268, -1.6653],
[ 0.0997, -1.3870],
[-0.3125, 1.4064],
[-1.4359, -1.0062],
[-0.3697, 1.3262],
[ 1.3130, 0.8978],
[ 1.3473, 0.4129],
[ 0.8330, 0.1011],
[ 0.3042, 0.1983],
[-0.1376, 0.1311]]),
tensor([[13.5198],
[ 9.1298],
[-1.1889],
[ 4.7397],
[-1.0332],
[ 3.7711],
[ 5.4895],
[ 5.5379],
[ 4.1317],
[ 3.4804]])]
'''4、构建线性回归,它属于单层神经网络结构
from torch import nn # nn是神经网络的缩写 调包
net = nn.Sequential(nn.Linear(2,1)) # 输入特征维度为2,输出特征维度为1
'''
net为
Sequential(
(0): Linear(in_features=2, out_features=1, bias=True)
)
'''
5、初始化模型参数
net[0].weight.data.normal_(0,0.01) # 初始化权重,使用正态分布替换
net[0].bias.data.fill_(0) # 初始化偏差6、计算均方误差,使用MSELoss类
loss = nn.MSELoss()7、实例化SGD实例,优化
trainer = torch.optim.SGD(net.parameters(),lr=0.01) # 学习率为0.018、训练
num_epochs = 5 # 训练5次
for epoch in range(num_epochs):
for X,y in data_iter:
l = loss(net(X),y) # 损失
trainer.zero_grad() # 梯度归0
l.backward() # 反向传播,计算导数
trainer.step() # 进行模型更新
l = loss(net(features),labels)
print(f'epoch:{epoch + 1},loss:{l:f}')
'''
epoch:0,loss:0.567253
epoch:1,loss:0.009129
epoch:2,loss:0.000251
epoch:3,loss:0.000107
epoch:4,loss:0.000105
'''9、误差估计
print(f'w的误差估计:{true_w-net[0].weight.data.reshpae(true_w.shape)} ')
print(f'b的误差估计:{true_b-net[0].bias.data}')
'''
w的误差估计:tensor([[ 0.0002, -0.0003]])
b的误差估计:tensor([3.9101e-05])
'''图像分类数据集
用于实现softmax回归,需要将图像进行分类,分为训练集和测试集
1、首先引入相关模块
%matplotlib inline
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
d2l.use_svg_display() # 设置 matplotlib 显示图像的格式为 SVG2、通过框架中的内置函数将Fashion-MNIST数据集下载并读取到内存中
# 通过totensor实例讲图像数据从PIL类型变为32位浮点数格式
# 并除以255使得所有像素的数值在0到1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root='data/',train=True,transform=trans,download=True)
mnist_test = torchvision.datasets.FashionMNIST(root='data/',train=False,transform=trans,download=True)
len(mnist_train),len(mnist_test)
'''
(60000, 10000)
mnist_train[0][0].shape # 第一张图片的形状。 通道,黑白,1,长宽28
torch.Size([1, 28, 28])
'''3、数据集包含10个类别,通过以下函数可以用于数字标签以及文本名称之间进行转换
def get_fashion_mnist_labels(labels):
# 返回文本标签
text_labels = ['t-shirt','trouser','pullover','dress','coat','sandal','shirt','sneaker','bag','ankle boot']
return [text_labels[(int(i))] for i in labels]4、创建一个函数可视化这些样本
def show_images(imgs,num_rows,num_cols,titles=None,scale=1.5):
# 绘制图像列表
figsize = (num_cols*scale,num_rows * scale) # 大小
_,axes = d2l.plt.subplots(num_rows,num_cols,figsize=figsize) # 子图数组axes
axes = axes.flatten() # 展平为一维数组
for i,(ax,img) in enumerate(zip(axes,imgs)):
if torch.is_tensor(img): # 判断图像是否为PyTorch张量
# 图片张量
ax.imshow(img.numpy())
else:
# PIL
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False) # 隐藏子图的坐标轴
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i]) # 设置标题
return axes5、训练数据集中前几个样本的图像以及标签
X,y = next(iter(data.DataLoader(mnist_train,batch_size=18)))
show_images(X.reshape(18,28,28),2,9,titles = get_fashion_mnist_labels(y))
6、定义函数,用于获取和读取数据集,这个函数返回训练集和测试集的数据迭代器,接受一个可选参数resize,用来将图像大小调整为另一种形状
def load_data_fashion_mnist(batch_size,resize=None):
# 下载数据集,加载到内存中
trans = [transforms.ToTensor()]
if resize:
trans.insert(0,transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root='data/',train=True,transform=trans)
mnist_test = torchvision.datasets.FashionMNIST(root='data/',train=False,transform=trans)
return (data.DataLoader(mnist_train,batch_size,shuffle=True,num_workers=4),
data.DataLoader(mnist_test,batch_size,shuffle=False,num_workers=4))7、指定resize参数测试函数的图像大小调整功能
train_iter,test_iter = load_data_fashion_mnist(32,resize=64)
for X,y in train_iter:
print(X.shape,X.dtype,y.shape,y.dtype)
break
'''
torch.Size([32, 1, 64, 64]) torch.float32 torch.Size([32]) torch.int64
'''Softmax回归的从零开始实现
上述是将图片进行分类,可以分为训练集和测试集
1、首先引入相关的模块
import torch
from IPython import display
from d2l import torch as d2l2、设置数据迭代器的批量大小为256
batch_size = 256
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size) # 训练集,测试集 迭代器3、初始化模型的参数,原始数据集的每个样本都是28*28的图像,将每个图像展平,看作长度为784的向量,所以输入为784,输出维度为10,权重构成一个784*10的矩阵,偏置构成一个1*10的行向量
num_inputs = 784 # 输入维度
num_outputs = 10 # 输出维度
W = torch.normal(0,0.01,size=(num_inputs,num_outputs),requires_grad=True) # 正态分布初始化权重W
b = torch.zeros(num_outputs,requires_grad=True) # 初始化为04、回顾softmax表达式
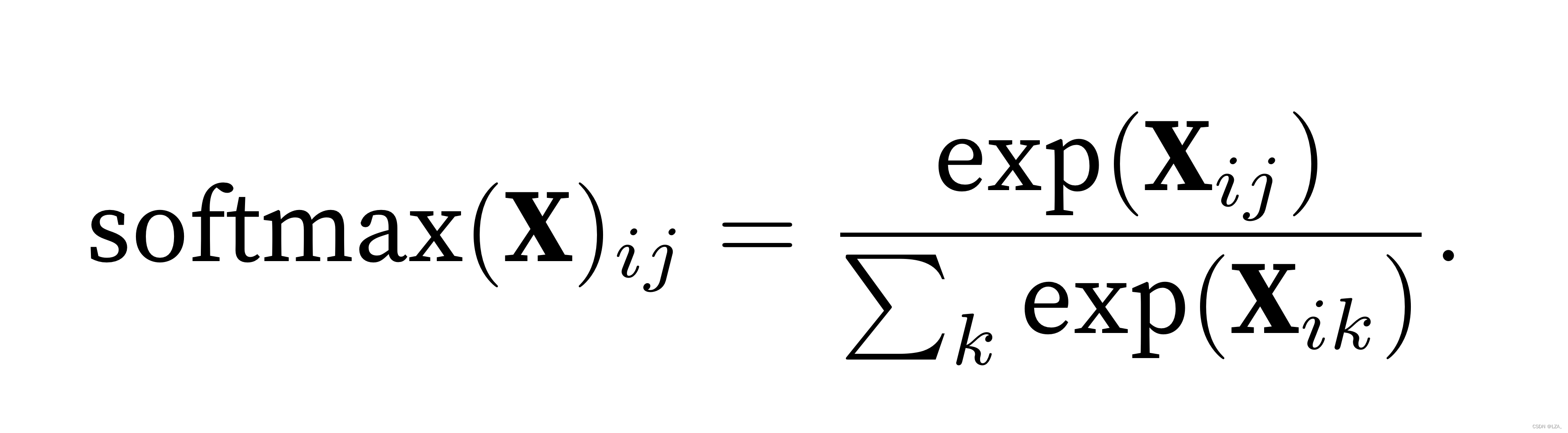
定义softmax函数
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1,keepdim=True) # 其他项按行求和
return X_exp / partition # 广播机制5、定义模型,实现softmax回归
def net(X):
return softmax(torch.matmul(X.reshape((-1,W.shape[0])),W)+b) # 将每张原始图展平为向量6、定义损失函数,交叉熵损失函数
def cross_entropy(y_hat,y):
return -torch.log(y_hat[range(len(y_hat)),y])7、定义分类精度函数
def accuracy(y_hat,y):
# 计算预测正确的数量
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1: # 判断张量是否大于1维,判断张量第二个维度是否大于1
y_hat = y_hat.argmax(axis=1) # 每行中最大元素的索引
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())所以分类精度的计算公式为:
accuracy(y_hat,y) / len(y)8、我们可以评估在任意模型net的准确率
def evaluate_accuracy(net,data_iter):
# 计算在指定数据集上的模型的精度
if isinstance(net,torch.nn.Module):
net.eval() # 评估模式
metric = Accumulator(2) # 正确预测数,预测总数
for X,y in data_iter:
metric.add(accuracy(net(X),y),y.numel())
return metric[0] / metric[1]9、定义了一个Accumulator类,用于多个变量进行累加,上述的实例中创建了2个变量,分别用于存储正确预测的数量和预测的总数量,当我们遍历数据集时,两者随着时间的推移而累加
class Accumulator:
# n个变量上累加
def __init__(self,n):
self.data = [0.0] *n
def add(self,*args):
self.data = [a+float(b) for a,b in zip(self.data,args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self,idx):
return self.data[idx]
10、softmax回归训练
def train_epoch_ch3(net,train_iter,loss,updater):
# 训练模型一个迭代周期
if isinstance(net,torch.nn.Module):
net.train() # 训练模式
metric = Accumulator(3) # 训练损失总和,训练准确度总和,样本数
for X,y in train_iter:
y_hat = net(X)
l = loss(y_hat,y)
if isinstance(updater,torch.optim.Optimizer):
updater.zero_grad()
l.mean().backward()
updater.step()
metric.add(float(l)*len(y),accuracy(y_hat,y),y.size().numel())
else:
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()),accuracy(y_hat,y),y.numel())
return metric[0]/metric[2] , metric[1] / metric[2] # 返回训练损失和训练精度11、定义动画绘制数据,Animator类
class Animator:
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear',yscale='linear',
fmts=('-','m--','g-.','r:'),nrows=1,ncols=1,
figsize=(3.5,2.5)):
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows,ncols,figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes,]
self.config_axes = lambda: d2l.set_axes(self.axes[0],xlabel,ylabel,xlim,ylim,xscale,yscale,legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a,b) in enumerate(zip(x,y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
12、实现一个训练函数
# 总训练函数
def train_ch3(net,train_iter,test_iter,loss,num_epochs,updater):
animator = Animator(xlabel='epoch',xlim=[1,num_epochs],ylim=[0.3,0.9],
legend=['train loss','train acc','test acc']) # 可视化函数
for epoch in range(num_epochs): # 变量num_epochs遍数据
train_metrics = train_epoch_ch3(net,train_iter,loss,updater) # 训练过程相关指标:返回两个值,一个总损失、一个总正确率
test_acc = evaluate_accuracy(net, test_iter) # 测试数据集上评估精度,仅返回一个值,总正确率
animator.add(epoch+1,train_metrics+(test_acc,)) # 可视化:train_metrics+(test_acc,) 仅将两个值的正确率相加,
train_loss, train_acc = train_metrics
13、设置学习率为0.1
# 小批量随即梯度下降来优化模型的损失函数
lr = 0.1
def updater(batch_size):
return d2l.sgd([W,b],lr,batch_size)14、训练10个迭代周期
num_epochs = 10
train_ch3(net,train_iter,test_iter,cross_entropy,num_epochs,updater)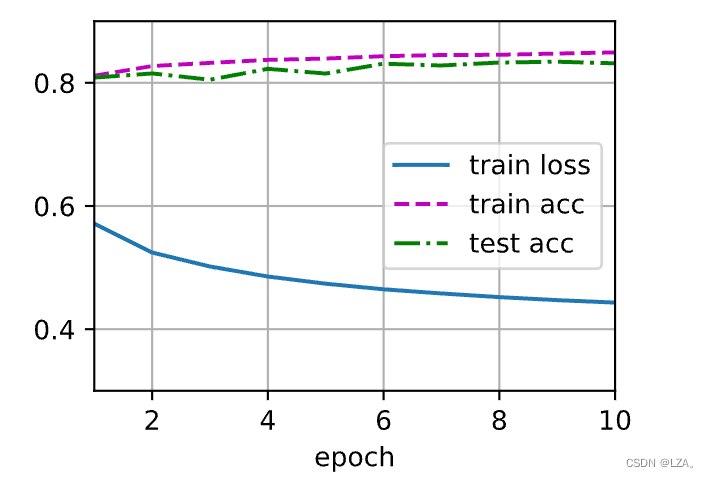
可以看到,随着迭代周期的增加,损失慢慢减少,准确率不断增加。
15、训练已经完成,对图像进行分类预测,比较实际标签和模型预测
def predict_ch3(net,test_iter,n=6):
for X, y in test_iter:
break # 仅拿出一批六个数据
trues = d2l.get_fashion_mnist_labels(y) # 真实label
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1)) # 预测label
titles = [true + '\n' + pred for true, pred in zip(trues,preds)]
d2l.show_images(X[0:n].reshape((n,28,28)),1,n,titles=titles[0:n])
predict_ch3(net,test_iter)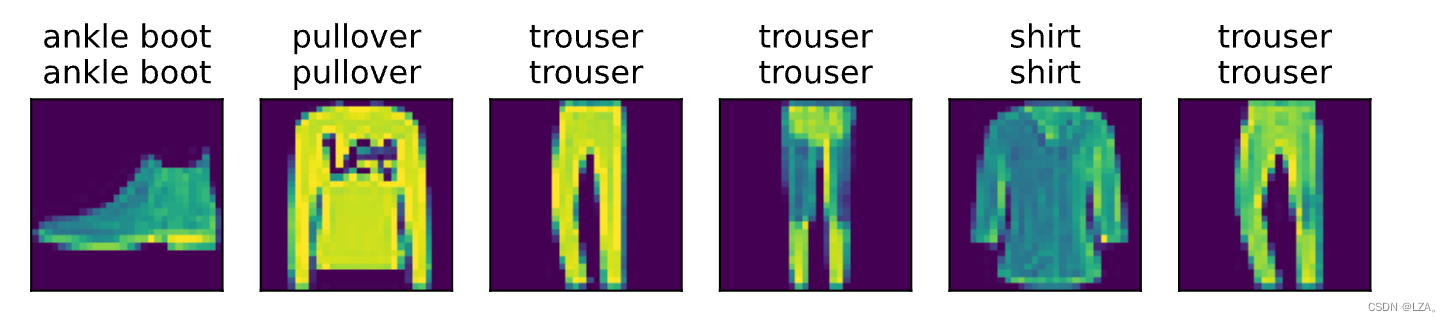
可以看出,在这6个图像中,模型的准确率很高。
Softmax回归的简洁实现
1、首先引入相关模块
import torch
from torch import nn
from d2l import torch as d2l2、依旧设置批量大小为256,设置训练,测试迭代器
batch_size = 256
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)3、初始化模型参数,softmax回归的输出层是一个全连接层,我们在Sequential中添加一个带有10个输出的全连接层
# pytorch不会隐式输入的形状
# 因此,我们定义了展平层(flatten),在线性层前调整网络输出的形状
net = nn.Sequential(nn.Flatten(),nn.Linear(784,10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight,std=0.01) #均值0,标准差为0.01初始化权重
net.apply(init_weights)
'''
Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=10, bias=True)
)
'''4、交叉熵损失函数
loss = nn.CrossEntropyLoss()5、使用学习率为0.1的小批量随机梯度下降作为优化算法
trainer = torch.optim.SGD(net.parameters(),lr=0.1)6、训练模型
num_epochs = 10
d2l.train_ch3(net,train_iter,test_iter,loss,num_epochs,trainer)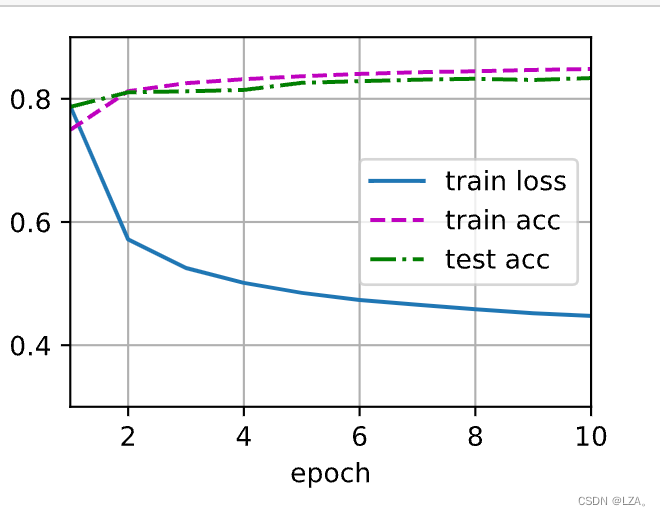
这个算法使结果收敛到一个很高的精度,比之前代码精简许多。
个人总结
这一周,跟着李沐老师熟悉了线性回归以及Softmax回归的基本代码实现,并且跟着"西瓜书"继续深入了解算法原理,以及算法数学公式的推导,之后,也将继续理论与实践相结合,做到熟稔于心!















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









