






在这一周,我主要是通过观看了吴恩达教授的机器学习,以及B站up主小土堆讲解的PyTorch,以下是我在这一周的学习笔记,继续努力,继续学习,继续进步!
目录
机器学习
寻找相关的特征
在上一周学习了协同过滤算法,那么我们在进行观看电影的页面,我们都会发现有相似的电影,我们可能喜欢的电影,或者我们在进行刷短视频的同时,也会有推荐的我们可能喜欢的视频,这些是怎么做的呢,如何知道我们可能会喜欢的项目呢?
我们之前了解到了协同过滤的一部分,学习了每个项目i,每部电影j,以及电影的特征x(i),使用此算法自动学习特征,我们将尝试找到具有特征x(k)的项目k,类似于特征x(i),也就是相似的项目,我们还有可能喜欢的项目。
如下图所示,我们通过欧氏距离计算最小的距离来找到特征x(k),也就是相似项目。

我们也知道协同过滤的局限性,主要有两点,一个是冷启动问题,简单的理解就是有一个新项目,很少有用户评价,或者一个新用户评价的项目很少,对该项目或者用户的协同过滤可能不会很准确,就是初始数据不足;第二个不足就是难以去利用其他的信息进行预测,比如用户的年龄,性别或者项目的属性等信息,如下图所示:

内容过滤算法与协同过滤算法的对比
我们前面了解到协同过滤算法是通过与用户评价相似的用户评分来推荐,我们有一定的数量的用户对某些项目进行评级,算法去推荐新的项目。
而内容过滤算法是采用不同的方法进行推荐,它是根据用户的特征和项目,物品的特征来进行推荐。

对于用户和项目的特征,有以下的例子
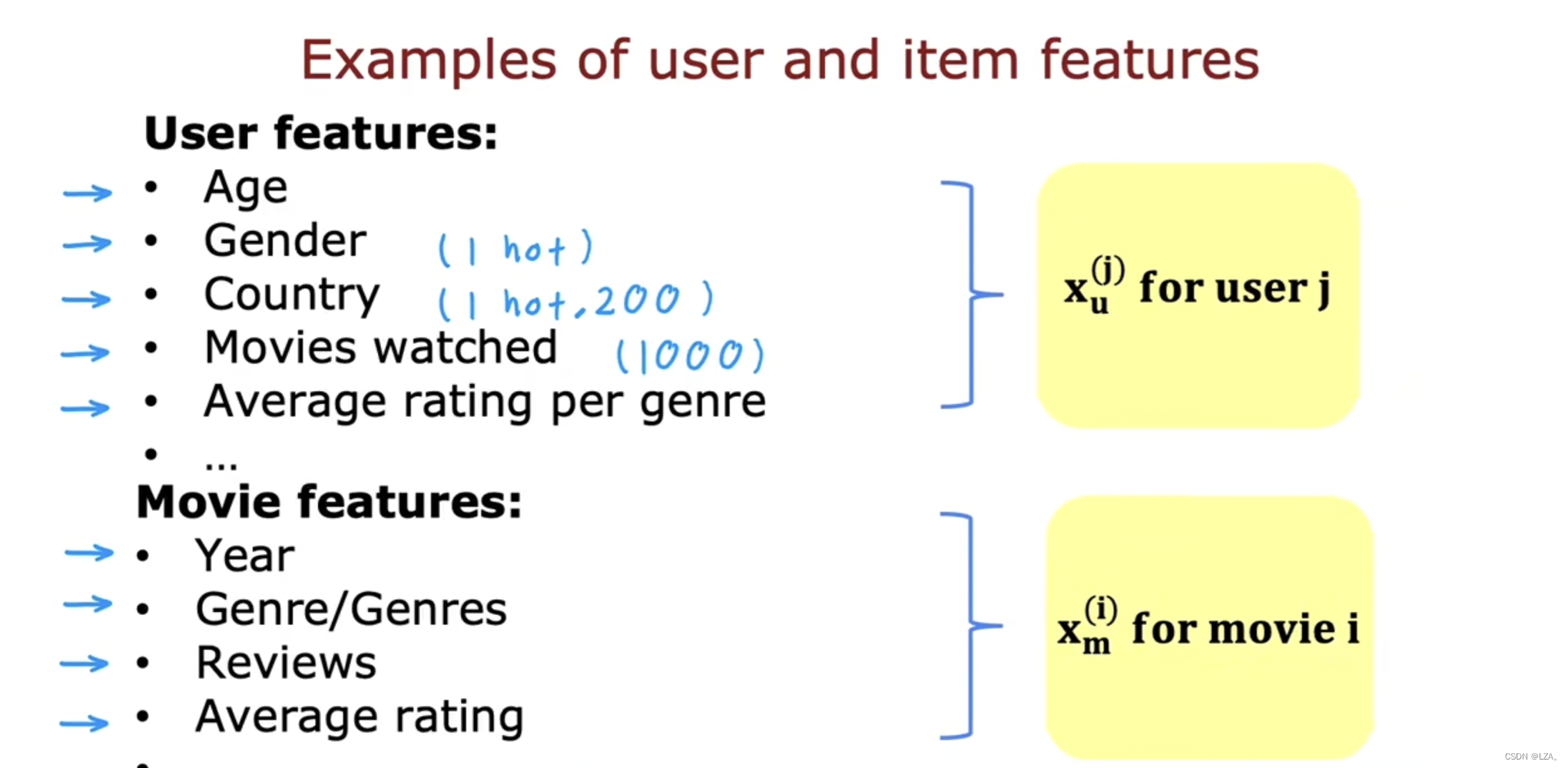
比如用户的年龄,性别,国家等特征,其中性别,国家等特征采用one-hot编码格式,电影的日期,评论等特征,将其各组合为一个向量,我们将试图弄清电影j是否会与用户i很好的匹配,用户特征与电影特征大小可能是不同的。
基于用户的各种特征给出一个评分,再将这个评分与电影评分做比较,越接近越容易推荐。
它是通过点乘的方式计算评分:

vu(j)是一个向量,它是根据用户j的特征计算的数字列表,从特征xu(j)中提取用户的向量;vm(i)也是一个向量,它是根据电影i的特征计算的数字列表,从特征xm(i)中提取电影的向量。
只有相同维度,才可以去计算评分。
基于内容过滤的深度学习方法
我们知道预测用户对电影的评分,就是之前的vu与vm的点积,我们采用神经网络,我们要使用户网络的输出层有32个单元,vu是包含32个数字的列表,最后一层有32个单元;同样,电影网络的输出层也有32个单元,vm包含32个数字的列表。

我们要知道,用户网络,电影网络可以具有不同数量的隐藏层和每个隐藏层有不同的单元,但所有的输出层需要具有相同尺寸的相同维度,也就是输出层都是要一样的,因为这样才可以做点积。
若是二进制标签,可以利用sigmoid来预测y(i,j)为1的概率,训练用户和电影网络的所有参数,构建成了成本函数J。
我们根据vu,vm预测y(i,j)来判断这两个网络,利用成本函数J,使用梯度下降算法或者其他的优化算法来调整神经网络参数,来使成本函数J尽可能的小,可以添加正则项,来保持参数值较小,训练了这个模型后,还可以找到相似的物品或者项目。
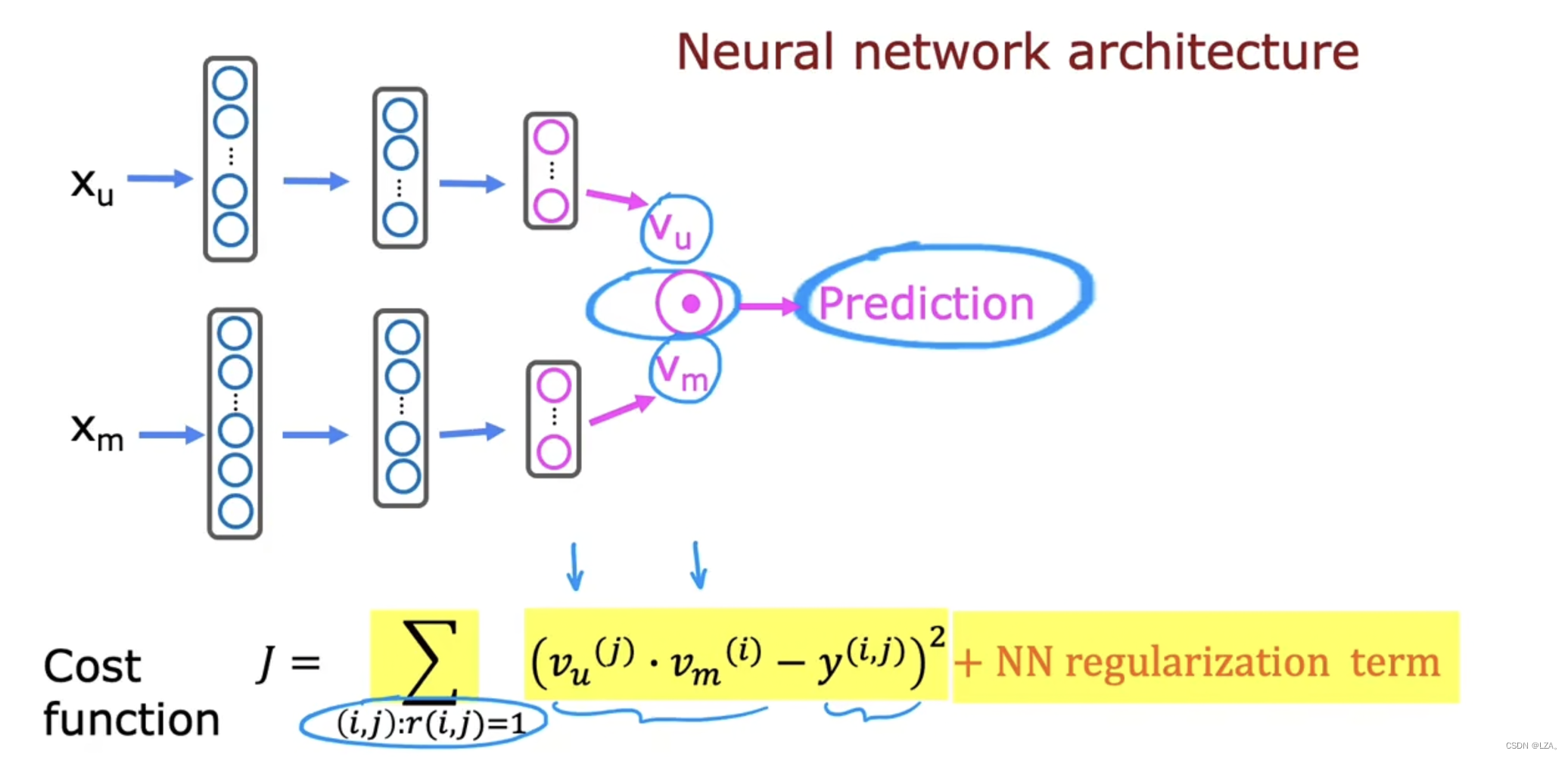
我们训练了这个神经网络结构后,寻找其他的项目k,根据项目k和项目i的向量距离平方距离很小来找到其他相似的项目,类似之前的协同过滤的作用,讨论寻找特征xi相似特征xk的距离

如果我们的电影很多的话,我们的计算成本会很高,下一节会讲解如何从大型项目中去推荐。
从大型目录中推荐
如果我们有数千或者近百万的项目目录的情况下,我们应该如何去推荐呢?

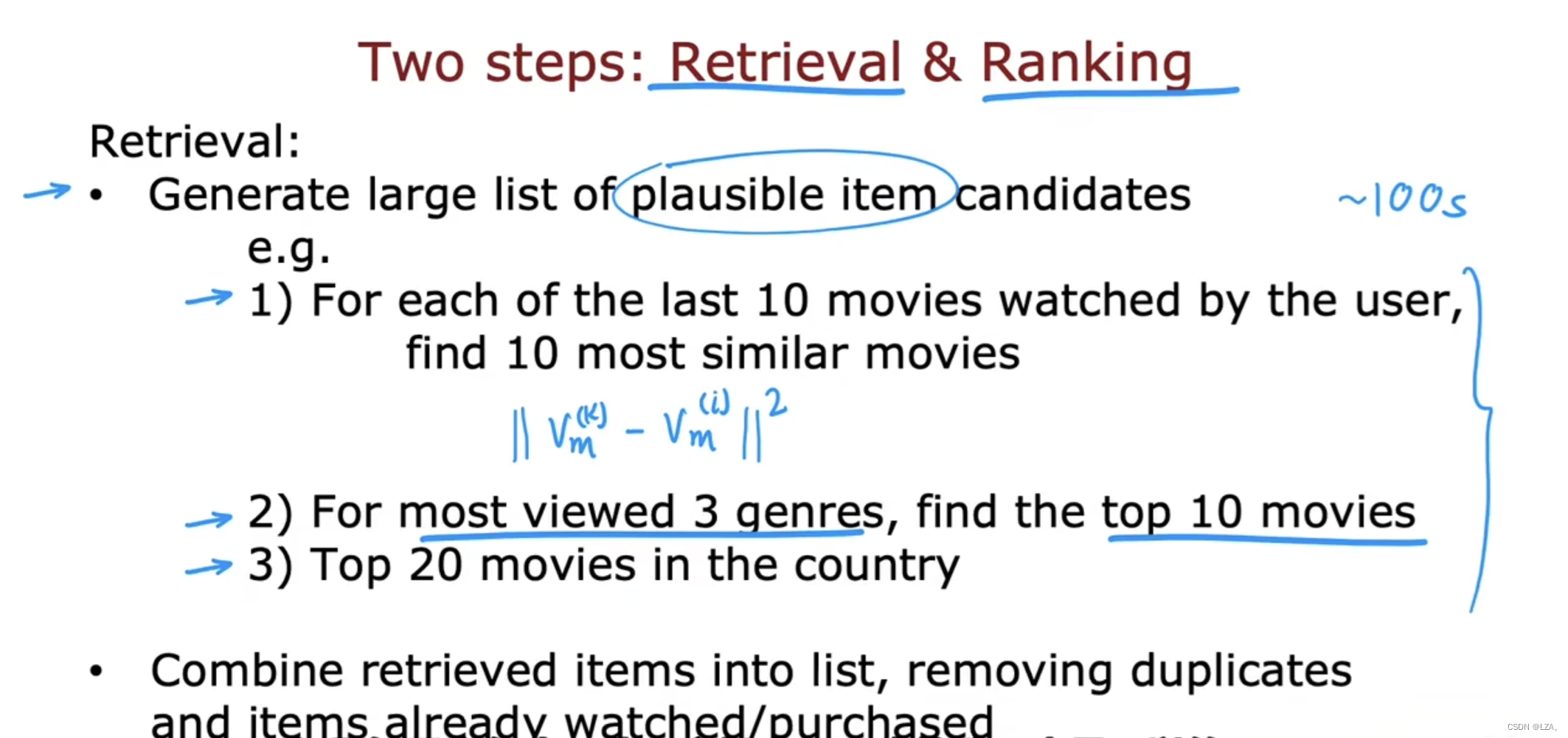
主要有两个步骤,第一个是检索,第二个是排名。
检索步骤就是去生成大量可能项目的候选列表,试图涵盖向用户推荐许多可能的东西,若包含用户可能不太喜欢的项目,那么在排名步骤中微调并选择最好的项目推荐的用户,我们可以根据用户最近观看的几部电影来寻找相似的电影,根据欧式距离来寻找相似电影,或者根据用户喜欢观看电影的类型,来寻找电影,或者根据用户所在的国家来寻找电影,最终包含多部电影,组合成一个列表,删除已经标记,已经观看的重复的项目,检索的目标就是广泛的覆盖范围。
排名的步骤就是通过我们获取的检索列表,使用我们之前的神经网络模型进行屁啊吗,对每个用户电影进行预测评分。
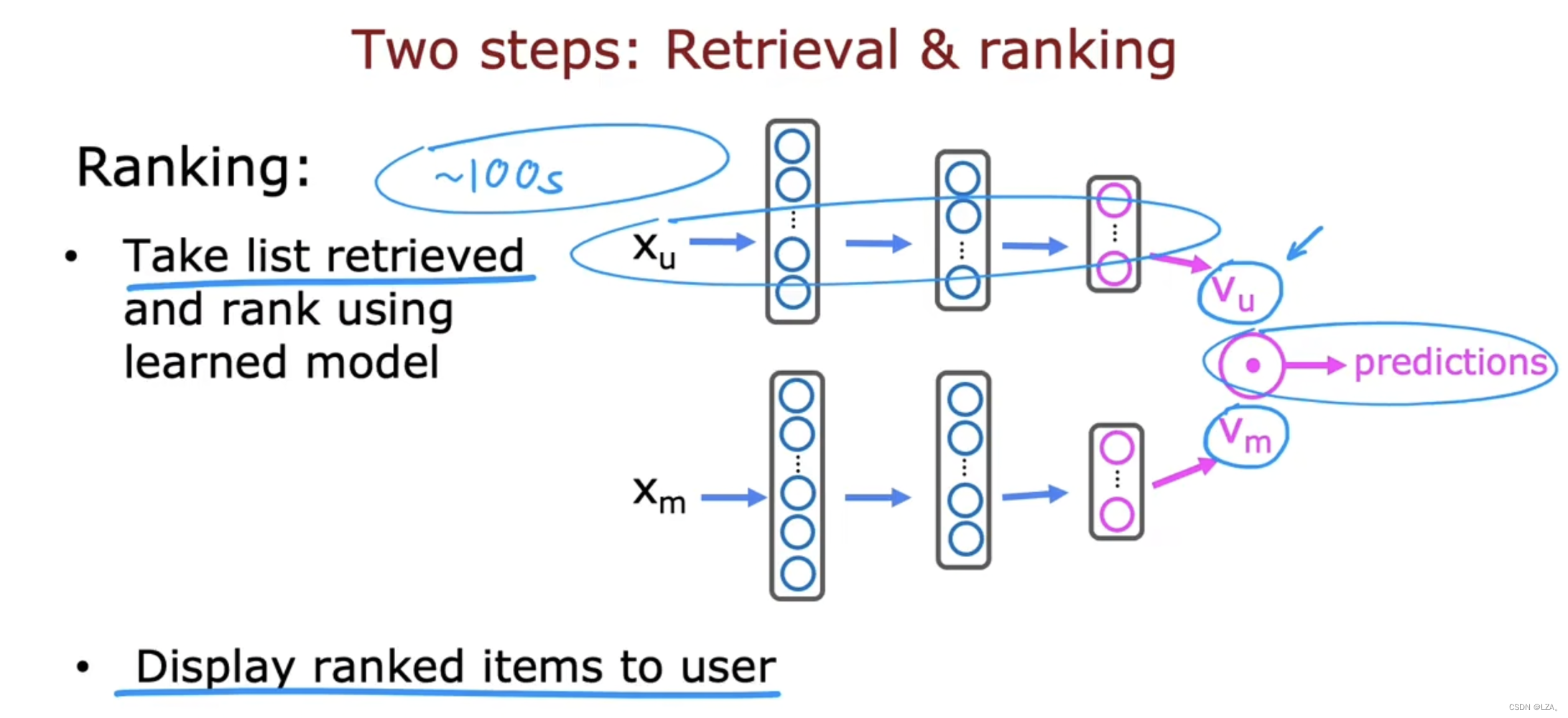
用一个简单的例子总结这两个步骤就是,第一个检索相当于我们选择3个您感兴趣的电影类型,比如选择搞笑,沈腾,火爆,初步确定范围;第二个排名就是将我们之前的向量之间做点积,得到具体的预测电影,比如飞驰人生等等。
降低特征数量
我们在进行数据可视化的一些操作时,如果该数据的特征很庞大,我们进行可视化操作很复杂,我们可以通过降低特征数量的方式来进行可视化操作,那么,我们应该如何进行降低特征数量的操作呢?
PCA算法可以解决我们之前的疑问,它可以获取大量的特征,并将特征数量减少到两个特征或者三个特征,并对其进行绘图和可视化。
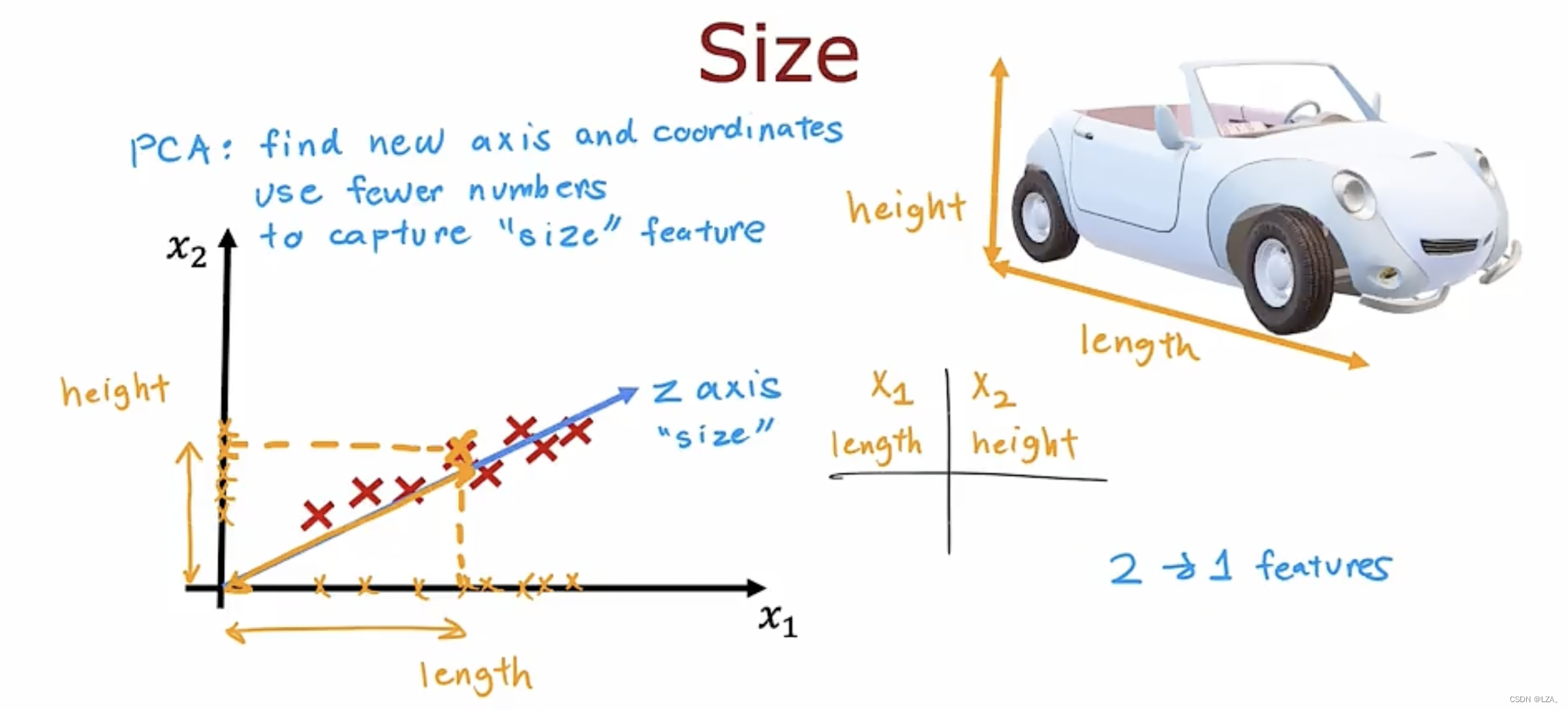
举一个例子,一个汽车有长度和宽度两个特征,我们平时的汽车的宽度不会有太大变化,反而长度每辆汽车都不太一样,所以我们可以减少特征,采用长度特征,因为它变化的很大,宽度的变化不大,两个特征只有一个更具有意义的变化。

PCA算法是找到一个或者多个新轴,例如z轴,这样在新轴测量数据坐标时,获得非常有用的信息,这样的话不需要两个数字去对于x1和x2轴的坐标,只需要一个数字,大致捕捉汽车大小,即z轴上的坐标,比如手机屏幕可以用长,宽表示,还可以用对角线尺寸表示。
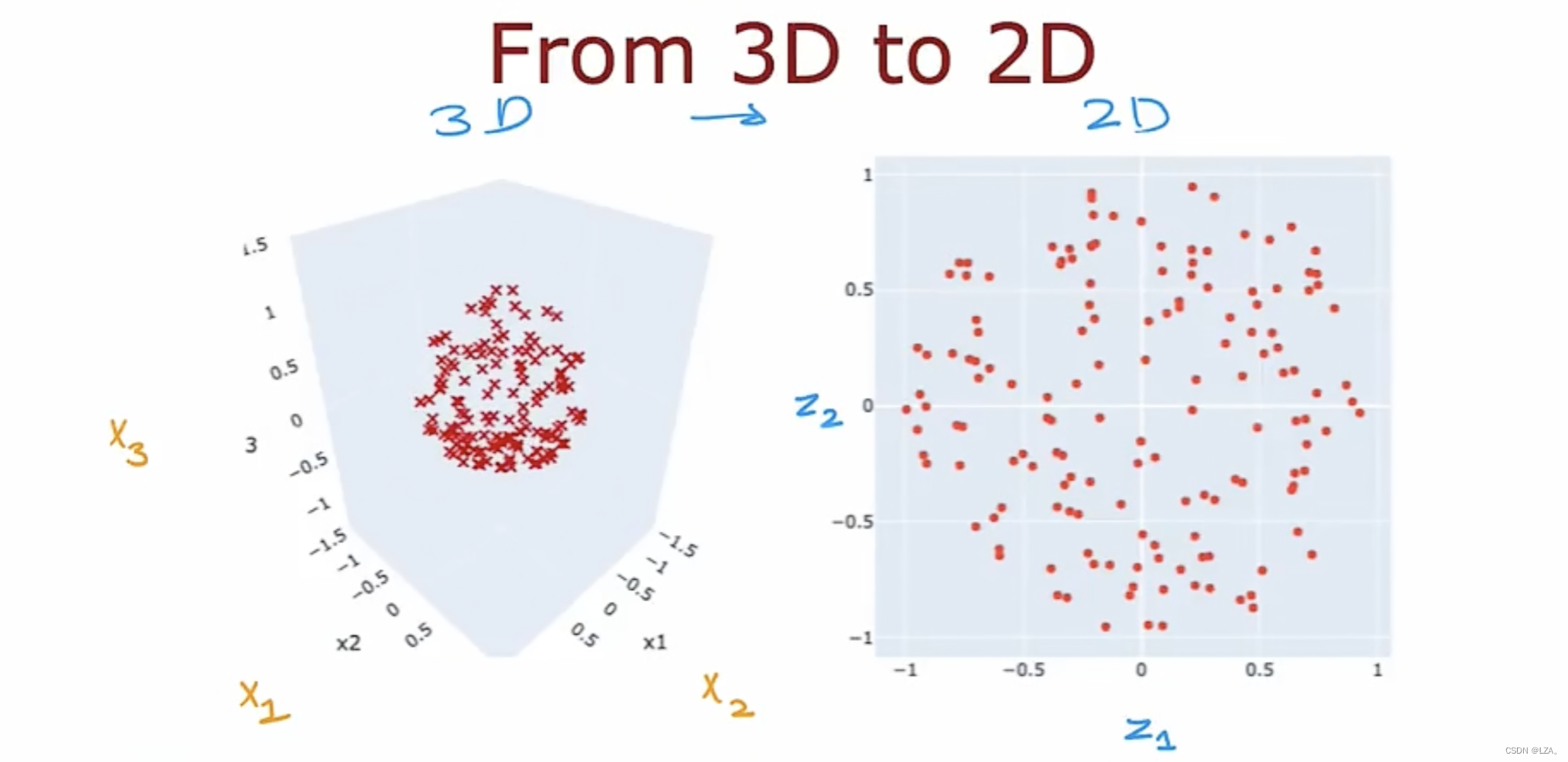
PCA可以用于减少大量特征,从大量特征减少到2个或者3个特征,可以从三维特征压缩为两维特征,可以更直观的观察数据的变化,如下图所示:
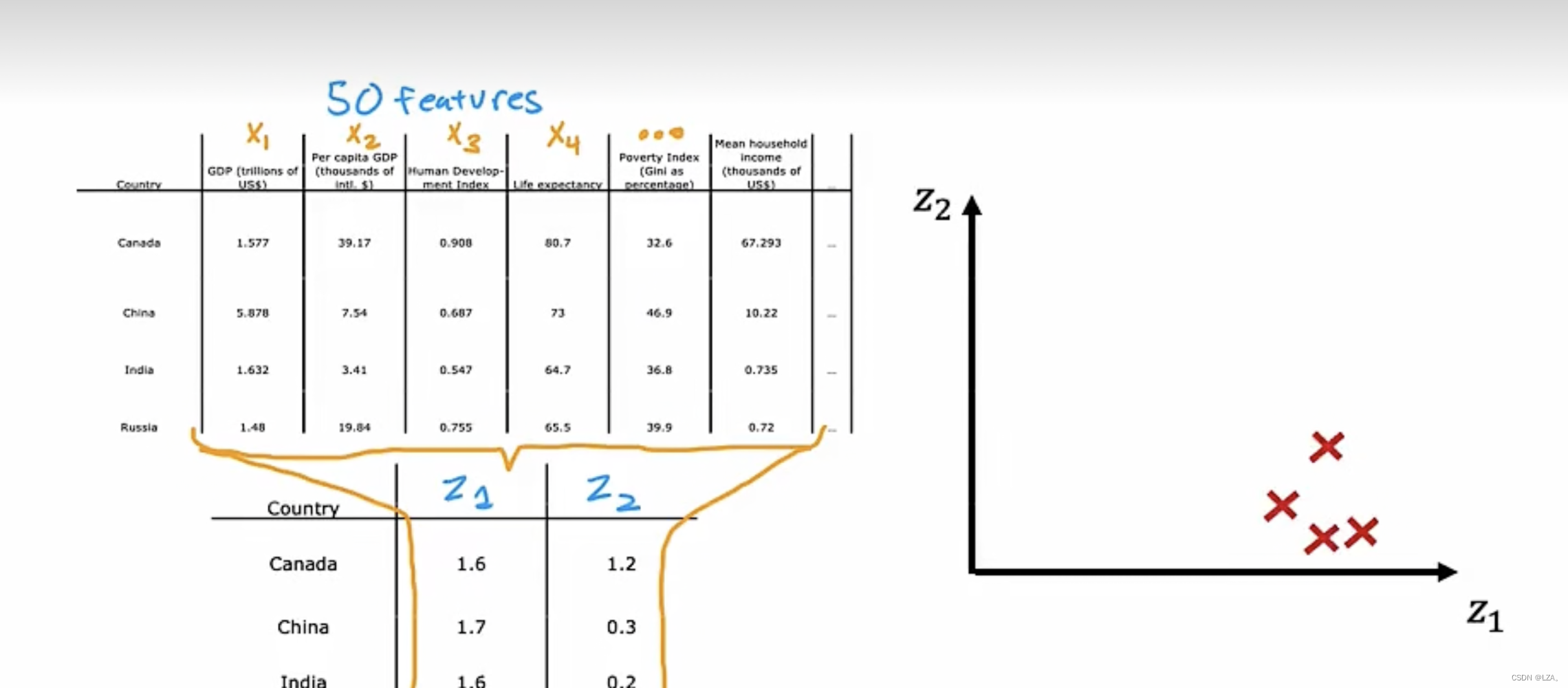
此图为50个特征x1...x50压缩至z1,z2两个特征。
PCA算法
如果我们想用一个功能替换两个功能,实现数据可视化,我们应该如何选择新轴呢?
我们应该先将特征归一化为零均值,若特征采用不同的比例,执行特征缩放,再应用PCA,每个特征减去均值,范围不会相距太大。
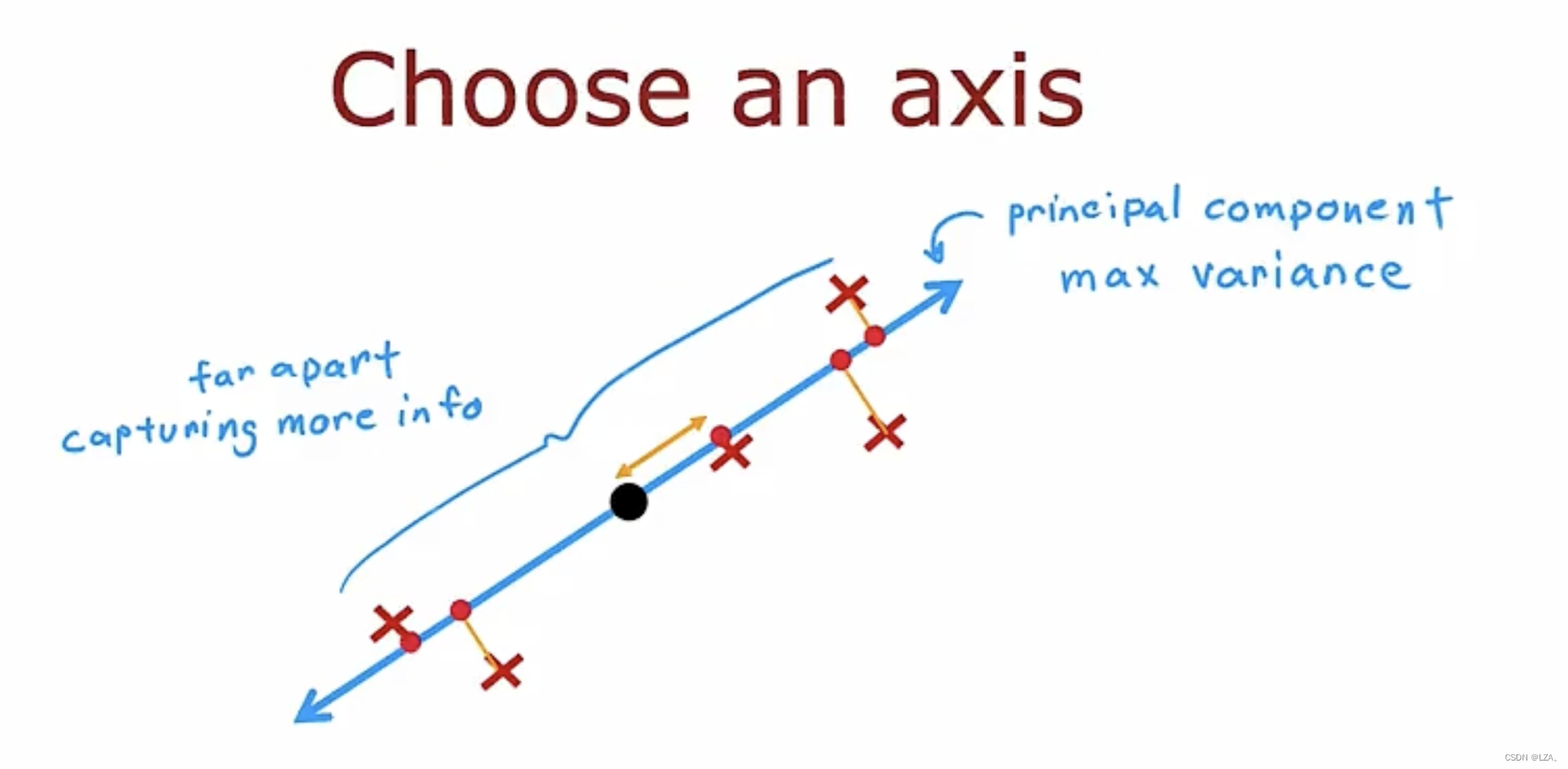
将我们的每一个点投影到我们的新轴,也就是z轴,如果这些点聚集在一起,每个点距离很小,代表在原始数据集中捕获的信息少很多,我们应该去选择投影过后,特征差异大,保证信息差异足够大,这就是我们要找的新轴,称为主成分轴,也就是找到能产生最大方差,保留信息最多的轴。如下图所示:
我们可以将长度为1的向量与当前点的坐标向量做点乘,得到压缩后的特征,也就是该点在新轴的距离,如下图所示:

我们压缩为1个特征可以生成一条新轴,如果我们要压缩为2个特征,要生成两条新轴,第二条新轴与第一条新轴垂直,两个主成分。
同时,我们需要注意,PCA算法不是线性回归算法,可能看起来好像都是在点之间拟合了一条直线,但是他们的目的以及性质完全不同。
首先,PCA算法是没有标签y的,它属于无监督学习,它是使点到轴的距离尽可能的变短,每个特征平均对待,尽可能多的保留原始数据方差,最大化这些投影的传播对应于最小化这些到轴的距离。
而线性回归算法是监督学习,横轴为特征x,纵轴为标签y,预测值尽可能接近真实标签y的。
所以,PCA算法和线性回归算法完全不同。
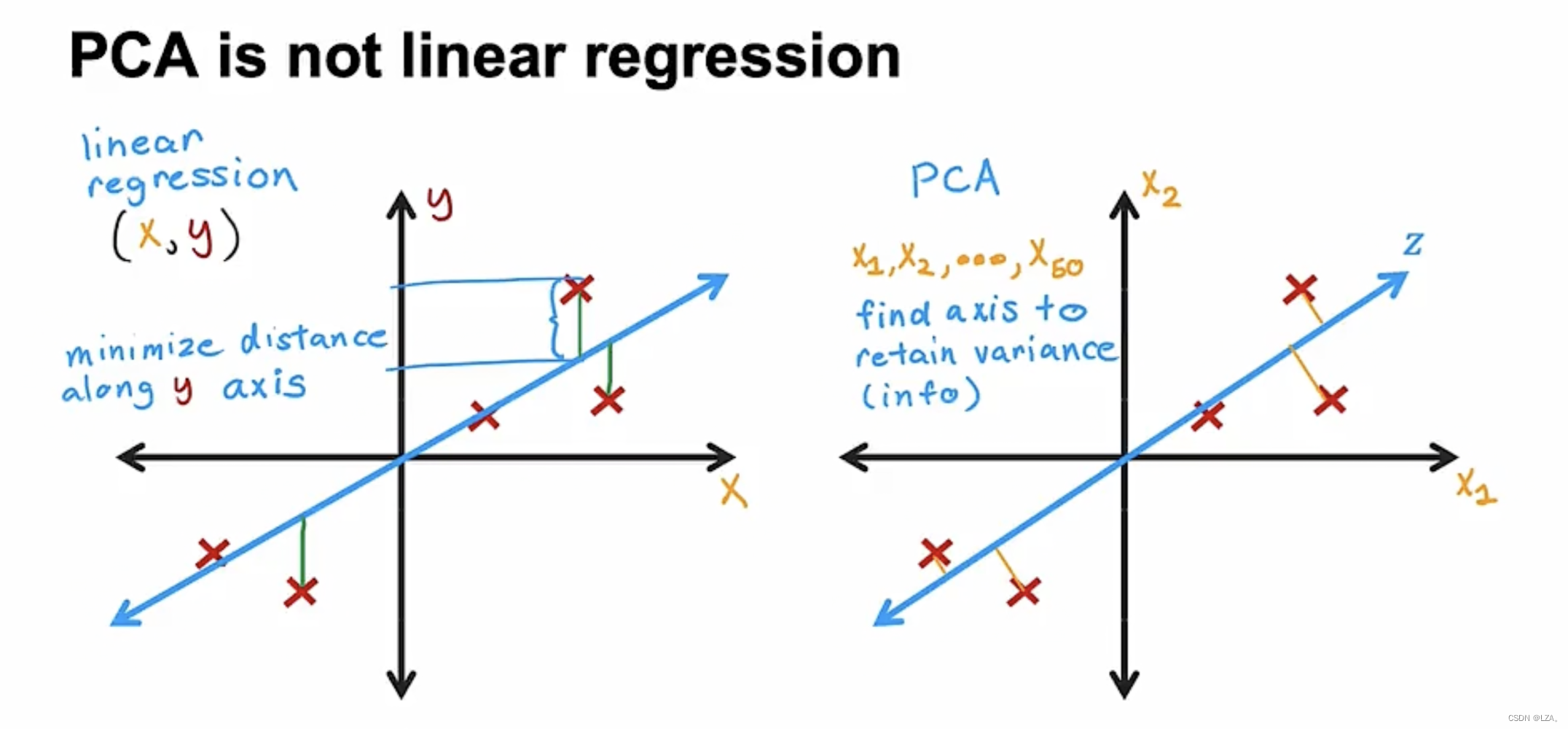
如下图,同样4个点,对于线性回归算法拟合的直线为横轴,它的预测值接近真实标签y,对于PCA算法拟合的直线为纵轴,它的点距离纵轴的距离很短,为主成分。

PCA in scikit-learn
PCA算法中的fit方法将自动进行均值一体化,减去每个特征的均值
相应代码示例如下:

X为特征的点,选择为一条主成分轴,压缩为一个特征,进行拟合,得到捕获原始数据集中99.2%的可变性,最后得到一个数组,为每个点在新轴上的投影到原点的距离。
如果改为两个特征如下:

z1和z2轴互相垂直,PCA将原数据投影,到原点间的一个子空间,使保留信息尽可能的多。
PCA算法最常见的应用为数据的可视化操作,减少维度,将其可视化非常有用。
同时在之前还可以进行数据的压缩和提高监督学习模型训练的速度。

推荐系统代码实战
在这里运用代码实现推荐系统,当用户对一些电影进行评分,如何对该用户去推荐其他的电影呢,并进行推荐电影的排名。
首先,引入相关的模块
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio接下来,加载电影,并将用户对电影的评分赋给Y,用户对电影是否进行了评分赋给R,其中有1682部电影,有943个用户参与了评分
mat = sio.loadmat('ex8_movies.mat')
mat.keys() # Y表示用户对电影的评分,R代表用户对电影是否进行了评分
Y,R=mat['Y'],mat['R'] # 1682个电影,943个用户参与评分
Y.shape,R.shape
# ((1682, 943), (1682, 943))继续引入电影参数的文件,其中包含电影特征X,用户特征Theta,用户个数,电影个数,特征数目
param_mat = sio.loadmat('ex8_movieParams.mat')
param_mat.keys() # 电影特征X,用户特征Theta,用户个数,电影个数,特征数目
X,Theta,nu,nm,nf = param_mat['X'],param_mat['Theta'],param_mat['num_users'],param_mat['num_movies'],param_mat['num_features']
X.shape,Theta.shape,nu,nm,nf
'''
((1682, 10),
(943, 10),
array([[943]], dtype=uint16),
array([[1682]], dtype=uint16),
array([[10]], dtype=uint8))
'''接下来,将用户个数,电影个数,特征数目转为int类型
nu = int(nu)
nm = int(nm)
nf = int(nf)
nu,nm,nf
#(943, 1682, 10)定义序列化参数,将电影特征X和用户特征Theta合并为一维矩阵
def serialize(X,Theta):
return np.append(X.flatten(),Theta.flatten()) # 合并为一维矩阵定义解序列化参数,将参数分解成多维矩阵
def deserialize(params,nm,nu,nf):
X = params[:nm*nf].reshape(nm,nf)
Theta = params[nm*nf:].reshape(nu,nf)
return X,Theta定义代价函数,利用协同过滤代价函数公式
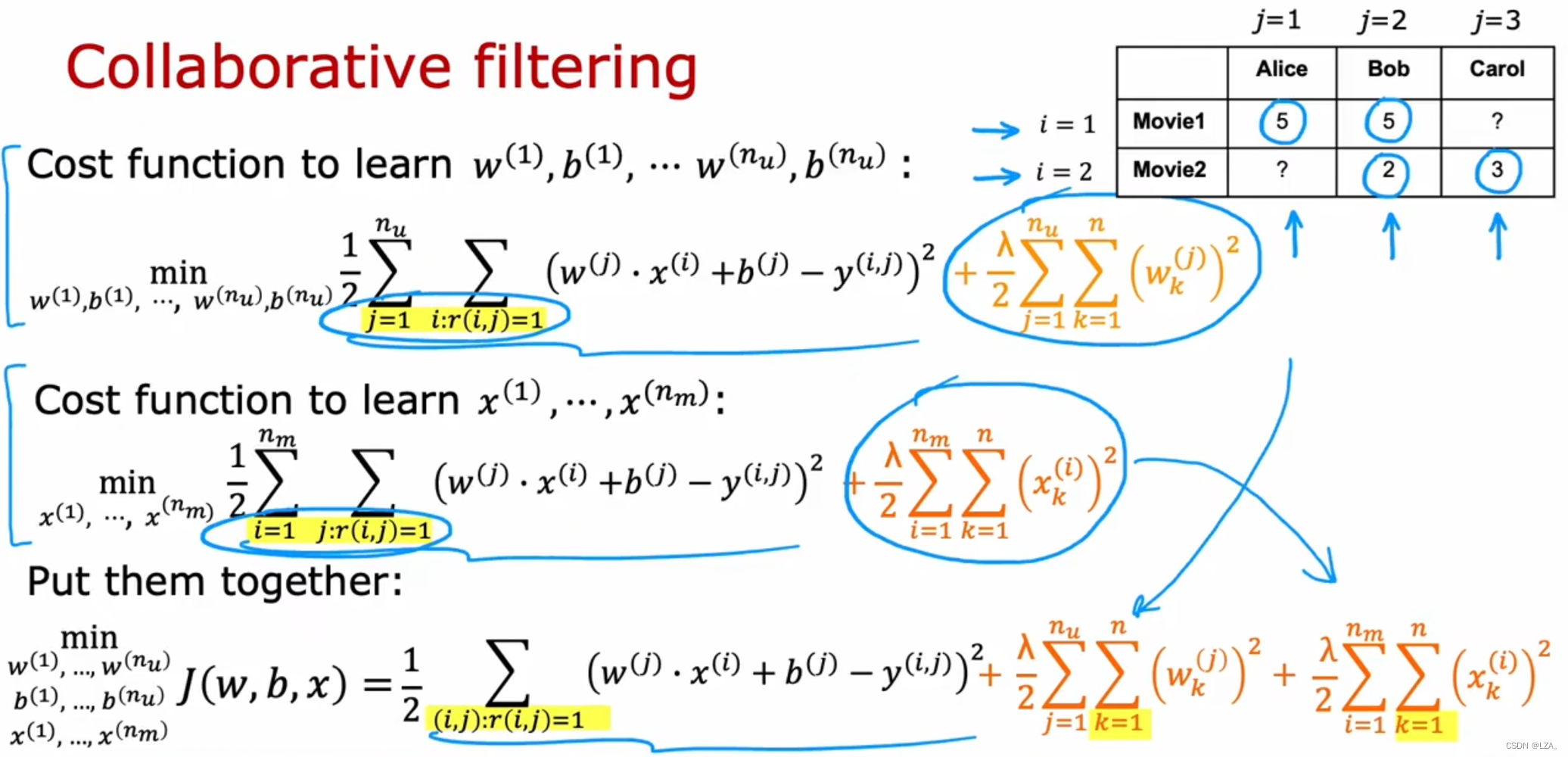
def costFunction(params,Y,R,nm,nu,nf,lamda):
X,Theta = deserialize(params,nm,nu,nf)
error = 0.5*np.square((X@Theta.T-Y)*R).sum()
reg1 = 0.5*lamda*np.square(X).sum()
reg2 = 0.5*lamda*np.square(Theta).sum()
return error+reg1+reg2现在若有用户4名,电影5部,特征有3个,正则参数为0,其代价函数为:
users = 4
movies = 5
features = 3
X_sub = X[:movies,:features]
Theta_sub = Theta[:users,:features]
Y_sub = Y[:movies,:users]
R_sub = R[:movies,:users]
cost1 = costFunction(serialize(X_sub,Theta_sub),Y_sub,R_sub,movies,users,features,lamda=0)
cost1
# 22.224603725685675若正则参数为0.5,代价函数为:
cost2 = costFunction(serialize(X_sub,Theta_sub),Y_sub,R_sub,movies,users,features,lamda=0.5)
cost2
# 25.264421231881858接下来,定义梯度,进行训练最优的参数
def costGradient(params,Y,R,nm,nu,nf,lamda):
X,Theta = deserialize(params,nm,nu,nf)
X_grad = ((X@Theta.T-Y)*R)@Theta + lamda*X
Theta_grad = ((X@Theta.T-Y)*R).T@X + lamda * Theta
return serialize(X_grad,Theta_grad)添加一个新用户,初始化对所有电影评分为0,在随机挑选几个设定评分
my_ratings = np.zeros((nm,1))
my_ratings[9]=5
my_ratings[66]=5
my_ratings[96]=5
my_ratings[121]=4
my_ratings[148]=4
my_ratings[285]=3
my_ratings[490]=4
my_ratings[599]=4
my_ratings[643]=4
my_ratings[958]=5
my_ratings[1117]=3并将Y用户对电影的评分,以及R用户是否对电影进行评分,进行列链接,因为添加了一个用户
Y = np.c_[Y,my_ratings]
R = np.c_[R,my_ratings!=0] # 按列链接两个矩阵所以,此时nm电影个数为此时Y的行数,nu用户个数为此时Y的列数
nm,nu = Y.shape定义均值一体化,若有用户没有对某部电影评分,计算其均值
def normalizeRatings(Y,R):
Y_mean = (Y.sum(axis=1) / R.sum(axis=1)).reshape(-1,1)
Y_norm = (Y-Y_mean)*R
return Y_norm,Y_mean将均值传递给Y_norm和Y_mean参数
Y_norm ,Y_mean = normalizeRatings(Y,R)之后进行参数的初始化
X = np.random.random((nm,nf))
Theta = np.random.random((nu,nf))
params = serialize(X,Theta)
lamda = 10再对模型进行训练,使用Python中的SciPy库来进行最小化优化操作,提供了目标函数的梯度costGradient,设置最大迭代次数为100次
from scipy.optimize import minimize
res = minimize(fun=costFunction,
x0=params,
args=(Y_norm,R,nm,nu,nf,lamda),
method='TNC',
jac=costGradient,
options={'maxiter':100})之后,将通过优化算法得到的最优参数值赋给params_fit
params_fit = res.x
fit_X,fit_Theta = deserialize(params_fit,nm,nu,nf)最后,进行预测
Y_pred = fit_X@fit_Theta.T
y_pred = Y_pred[:,-1] + Y_mean.flatten()
index = np.argsort(-y_pred) #进行降序排列
movies = []
with open('movie_ids.txt','r',encoding='latin 1') as f:
for line in f:
tokens = line.strip().split(' ')
movies.append(''.join(tokens[1:]))
for i in range(10):
print(index[i],movies[index[i]],y_pred[index[i]])推荐的前10部电影以及预测评分为:
1292 StarKid(1997) 5.000000056767229
1652 EntertainingAngels:TheDorothyDayStory(1996) 5.000000014175219
1121 TheyMadeMeaCriminal(1939) 4.999999997054995
813 GreatDayinHarlem,A(1994) 4.999999996494888
1200 MarleneDietrich:ShadowandLight(1996) 4.999999987568511
1535 Aiqingwansui(1994) 4.999999984689212
1598 SomeoneElse'sAmerica(1995) 4.999999984520192
1466 SaintofFortWashington,The(1993) 4.999999959026547
1499 SantawithMuscles(1996) 4.999999956301338
1188 Prefontaine(1997) 4.999999896338637使用PCA进行二维数据的降维度
1、首先引入相关的模块
import numpy as np
import scipy.io as sio
import matplotlib.pyplot as plt2、读取文件,将这些特征赋给X变量
mat = sio.loadmat('ex7data1.mat')
X = mat['X']
3、展示这些二维特征
plt.scatter(X[:,0],X[:,1])
plt.show()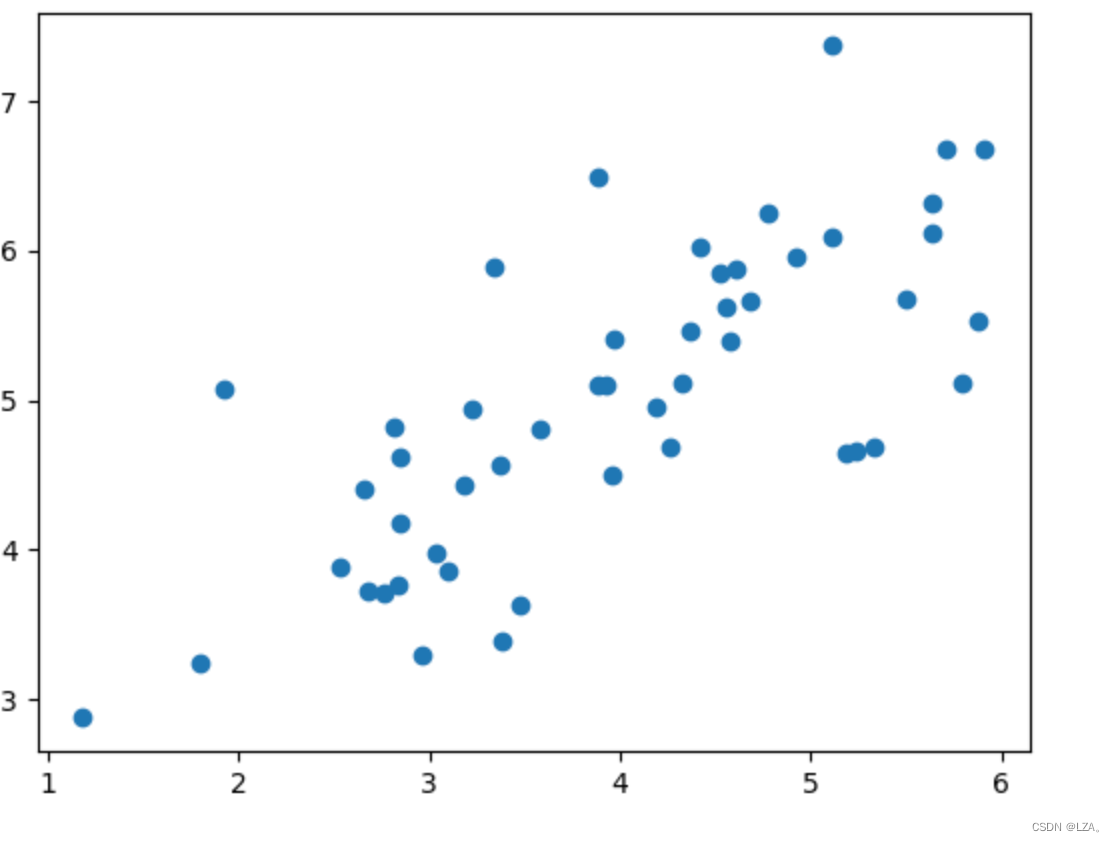
4、接下来对X去均值化处理
X_demean = X - np.mean(X,axis=0)
plt.scatter(X_demean[:,0],X_demean[:,1])
plt.show()5、计算协方差矩阵,其中主对角线是第一个维度的方差和第二个维度的方差
C = X_demean.T@X_demean/len(X)
C #主对角线是第一个维度的方差和第二个维度的方差
6、计算特征值,特征向量
U,S,V = np.linalg.svd(C)
U1 = U[:,0] #第一列 降为一维7、实现降维
X_reduction = X_demean@U1 # 降维之后的数据
plt.figure(figsize=(7,7))
plt.scatter(X_demean[:,0],X_demean[:,1])
plt.plot([0,U[:,0][0]],[0,U[:,0][1]],c='r') #将我们的数据映射到这个维度上
plt.plot([0,U[:,1][0]],[0,U[:,1][1]],c='b')
plt.show()
8、还原数据
X_restore = X_reduction.reshape(50,1)@U1.reshape(1,2) + np.mean(X,axis=0)
plt.scatter(X[:,0],X[:,1])
plt.scatter(X_restore[:,0],X_restore[:,1])
plt.show()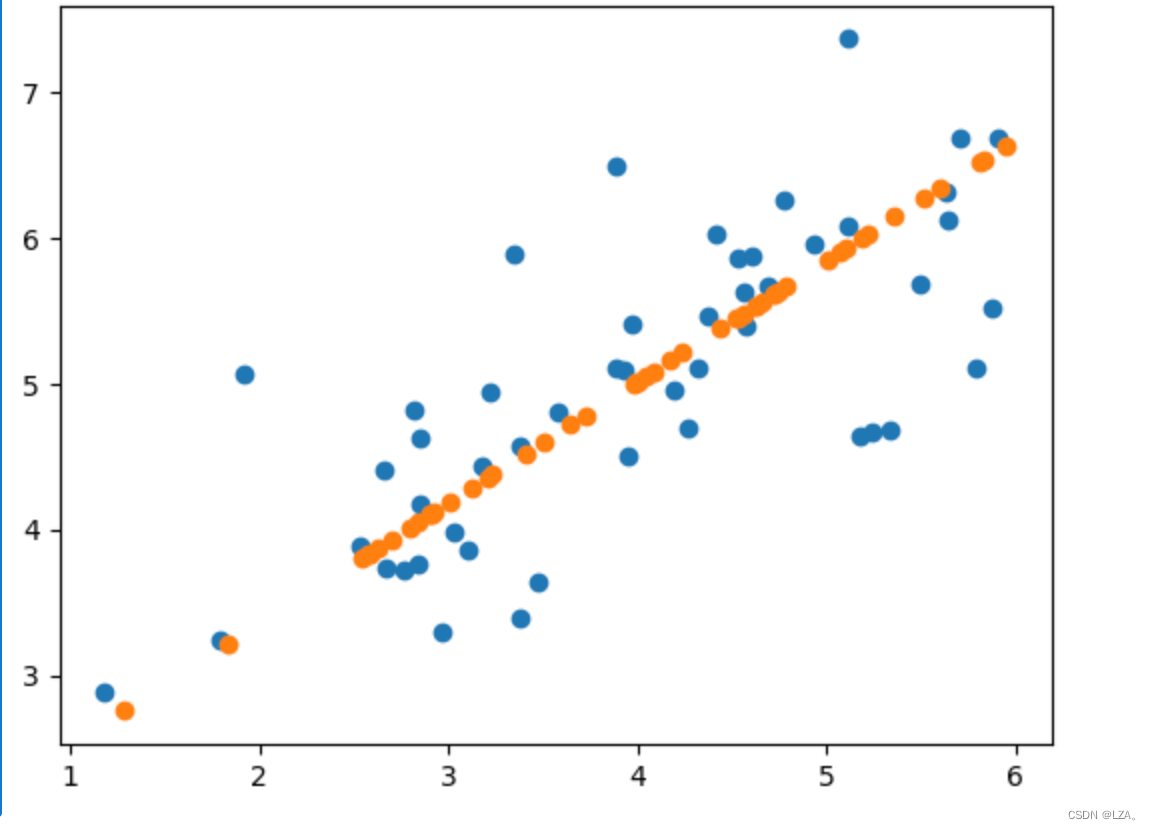
可见该主成分轴可以还原大部分原始数据
使用PCA进行图像的降维
1、引入相关的模块
import numpy as np
import scipy.io as sio
import matplotlib.pyplot as plt2、读取文件,并将特征赋给X,有1024个维度,也就是1024个特征
mat = sio.loadmat('ex7faces.mat')
X = mat['X']
X.shape # 有1024个维度
# (5000,1024)3、将图片输出100张,并显示单通道的灰度图
def plot_100_images(X):
fig,axs = plt.subplots(ncols=10,nrows=10,figsize=(10,10))
for c in range(10):
for r in range(10):
axs[c,r].imshow(X[10*c+r].reshape(32,32).T,cmap='Greys_r') #显示单通道的灰度图
axs[c,r].set_xticks([])
axs[c,r].set_yticks([])4、输出X

5、接下来对X去均值化处理,计算协方差矩阵,并求取特征值,特征向量,取前36列,压缩为36维度
means = np.mean(X,axis=0)
X_demean = X-means
C = X_demean.T@X_demean/len(X)
C.shape #(1024,1024)
U,S,V = np.linalg.svd(C)
U1 = U[:,:36] # 取前36列
X_reduction = X_demean@U1 #被压缩后的特征
6、还原数据
X_recover = X_reduction@U1.T + means
plot_100_images(X_recover)降维为36维度,保留最优的特征

强化学习
强化学习是机器学习的一种思想,比如我们可以使用它去让计算机去自动飞行,如果我们利用监督学习去来控制飞行的话,会导致标签数据制造困难,情况复杂,每一步的动作很难说对错,要整个决策过程才能评价,所以我们采用强化学习。
之前都是学习人类,现在可以说是自己学习。
强化学习的关键输入是一种叫做奖励或者奖励函数,它会告诉机器什么时候做的好或者什么时候做的不好。
比如我们去训练一只狗,当它做的事情是对的时候,我们会奖励它;当它做的事情是错误的时候,我们会惩罚它,如果利用强化学习的话,它自己学习如何做更多好狗的事情,更少去做坏狗的事情。
强化学习是必须要告诉它做什么而不是如何做。

对于奖励函数,如果是无人机的话,它飞行的很不错,我们可以给它的奖励加1;它飞行的很差劲的话,我们可以惩罚它,减去1000。这个将激励它花更多时间去飞行。
对于强化学习的应用,它可以去控制机器,判断最优化的因素,判断经济的趋势等

总结,强化学习的关键思想是不需要告诉算法每个输入的正确输出是什么,而是指定奖励函数,告诉它什么时候做的好,什么时候做的不好。
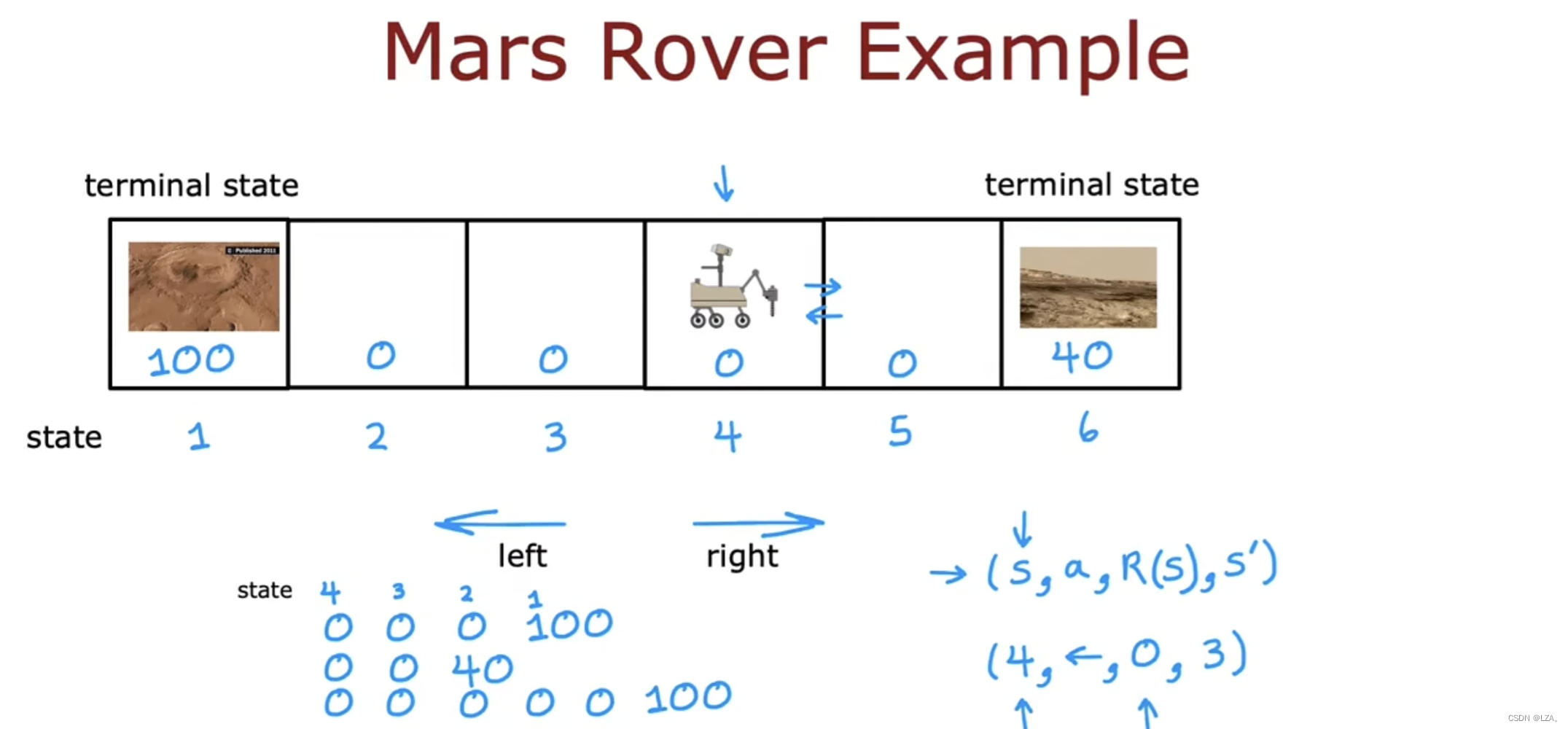
举一个火星探测器的例子
我们在强化学习中,非常关注奖励,因为这是我们知道机器是做的好还是不好。
通常用(s,a,R(s),s')来表示,其中s表示状态,a表示动作,R(s)表示奖励,s'表示下一个状态。
若火星探测器在4号状态,在1号状态和6号状态都有我们想要去观察的地点,但是这两个状态的奖励值均不同,来决定火星探测器去哪一个状态。
假如火星探测器从4号状态往1号状态走,它先经过3号状态,3号状态奖励值为0,表示为(4,⬅️,0,3)
PyTorch
利用GPU训练
之前我们模型的训练是利用的cpu,训练起来很慢,我们可以利用我们的GPU进行训练,训练的速度会快很多。
# 定义训练的设备
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")我们在前面进行定义训练的设备,如果有Nvidia显卡可以选择cuda,在我这里选择mps进行训练
在创建网络模型时利用mps
# 创建网络模型
network = NetWork()
network = network.to(device)在训练集和测试集利用mps
for data in train_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = network.forward(imgs)
loss = loss_fn(outputs, targets)这样我们运行代码会使代码的运行速度快很多。
完整代码如下:
import torch
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from model import *
from torch.utils.tensorboard import SummaryWriter
# 定义训练的设备
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
# 准备数据集
# 训练数据集
train_data = torchvision.datasets.CIFAR10(root='../dataset', train=True, transform=torchvision.transforms.ToTensor())
# 测试数据集
test_data = torchvision.datasets.CIFAR10(root='../dataset', train=False, transform=torchvision.transforms.ToTensor())
train_data_size = len(train_data) # 长度
test_data_size = len(test_data)
print(f'训练数据集的长度为{train_data_size},测试数据集的长度为{test_data_size}') #50000 10000
# print('训练数据集的长度为{},测试数据集的长度为{}'.format(train_data_size, test_data_size))
# 利用dataloader加载数据集
train_dataloader = DataLoader(dataset=train_data, batch_size=64)
test_dataloader = DataLoader(dataset=test_data, batch_size=64)
# 创建网络模型
network = NetWork()
network = network.to(device)
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
learning_rate = 0.01 # 1e-2
optimizer = torch.optim.SGD(network.parameters(),lr=learning_rate) # 随机梯度下降
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 20
# 添加tensorboard
writer = SummaryWriter('../logs')
for i in range(epoch):
print(f'---------第{i+1}轮训练开始---------')
# 训练步骤开始
network.train() #训练状态
for data in train_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = network.forward(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad() # 梯度清0
loss.backward() # 反向传播
optimizer.step() # 参数优化
total_train_step += 1
if total_train_step % 100 == 0:
print(f'训练次数:{total_train_step},loss:{loss.item()}') # item转为真实的数字,tensor取值
writer.add_scalar('train_loss',loss.item(),global_step=total_train_step)
# 测试步骤开始
network.eval() # 评估状态
total_test_loss=0
total_accuracy=0
with torch.no_grad(): # 没有梯度的运算,不需要利用梯度优化
for data in test_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = network.forward(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum() # 正确的个数
total_accuracy = total_accuracy + accuracy # 总的预测正确的个数
print(f'整体测试集上的Loss:{total_test_loss}')
print(f'整体测试集上的正确率:{total_accuracy/test_data_size}')
writer.add_scalar('test_loss',total_test_loss,global_step=total_test_step)
writer.add_scalar('test_accuracy',total_accuracy/test_data_size,global_step=total_test_step)
total_test_step += 1
torch.save(network,f"network_{i+1}.pth")
# torch.save(network.state_dict(),f"network_{i+1}.pth") # 官方推荐
print('模型已保存')
writer.close()
模型验证
我们在前面已经训练好了这个模型,我们现在想要去验证这个模型是否可以预测成功。
我们选择一张狗的图片进行验证,并命名为dog.png

我们利用PIL的Image去加载此图片并将其转化为RGB三通道,默认png可能是四通道
image_path = "../images/dog.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')
print(image)
接下来,我们利用transforms将图片的大小改变,并转换为tensor类型
transfrom = torchvision.transforms.Compose([
torchvision.transforms.Resize(size=(32,32)),
torchvision.transforms.ToTensor()
])
image = transfrom(image)
print(image.shape)
之后,我们去加载之前我们训练好的模型,我们选择最后准确率最高的模型,我们在前面可以多训练几轮,可以使准确率更高,在这里之前的模型训练了20轮,模型准确率达到了65%左右。
network = torch.load("network_20.pth", map_location=torch.device('cpu'))
print(network)因为之前是利用mps训练的,在这里转换为cpu

又因为神经网络的输入需要是四维的,我们进行重塑为四维,进行模型的测试,在没有梯度的情况下进行输入,进行神经网络的前向传播,得到输出output。
image = torch.reshape(image,shape=(1,3,32,32))
network.eval()
with torch.no_grad():
output = network.forward(image)
print(output)
最后,我们取其中的最大值,并查看之前的测试集我们预测的是否正确
print(output.argmax(1))
dataset = torchvision.datasets.CIFAR10(root='../dataset',train=False)
print(dataset.classes)

在我们这个例子中,下标5就是为集合的dog种类,如果不是的话,我们在前面模型的训练可以多进行训练几轮,可以去提高正确率。
完整验证代码如下:
from PIL import Image
import torchvision
from torch import nn
import torch
from model import NetWork
image_path = "../images/dog.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')
print(image)
transfrom = torchvision.transforms.Compose([
torchvision.transforms.Resize(size=(32,32)),
torchvision.transforms.ToTensor()
])
image = transfrom(image)
print(image.shape)
network = torch.load("network_20.pth", map_location=torch.device('cpu'))
print(network)
image = torch.reshape(image,shape=(1,3,32,32))
network.eval()
with torch.no_grad():
output = network.forward(image)
print(output)
print(output.argmax(1))
dataset = torchvision.datasets.CIFAR10(root='../dataset',train=False)
print(dataset.classes)
个人总结
本周主要是学习了机器学习的推荐系统,PCA算法,强化学习的概念,以及推荐系统,PCA算法的一些案例的代码,也掌握了PyTorch框架的基本使用,下一周,将继续学习强化学习,深度学习以及代码实现,继续努力,继续学习,继续进步!















 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









