






在这一周,我主要是通过观看了吴恩达教授的机器学习,以及B站up主小土堆讲解的PyTorch,以下是我在这一周的学习笔记,继续努力,继续学习,继续进步!
目录
机器学习
one-hot 编码
在我们之前所看到的,之前每个特征只能采用两个可能值的一个,拥有可以采用两个及以上离散值的特征,我们可以采用one-hot编码来解决此类特征。
初始特征仍然是分类值特征,但它可以采用多个可能的值,不仅仅是两个可能的值。
one-hot编码可以去处理并采用两个以上值的特征。
比如,我们上周所看到的预测猫的例子,之前我们判断动物的耳朵的形状,将其分为两类,那么我们耳朵的形状有多种类别如何用one-hot编码实现呢?如下图所示:
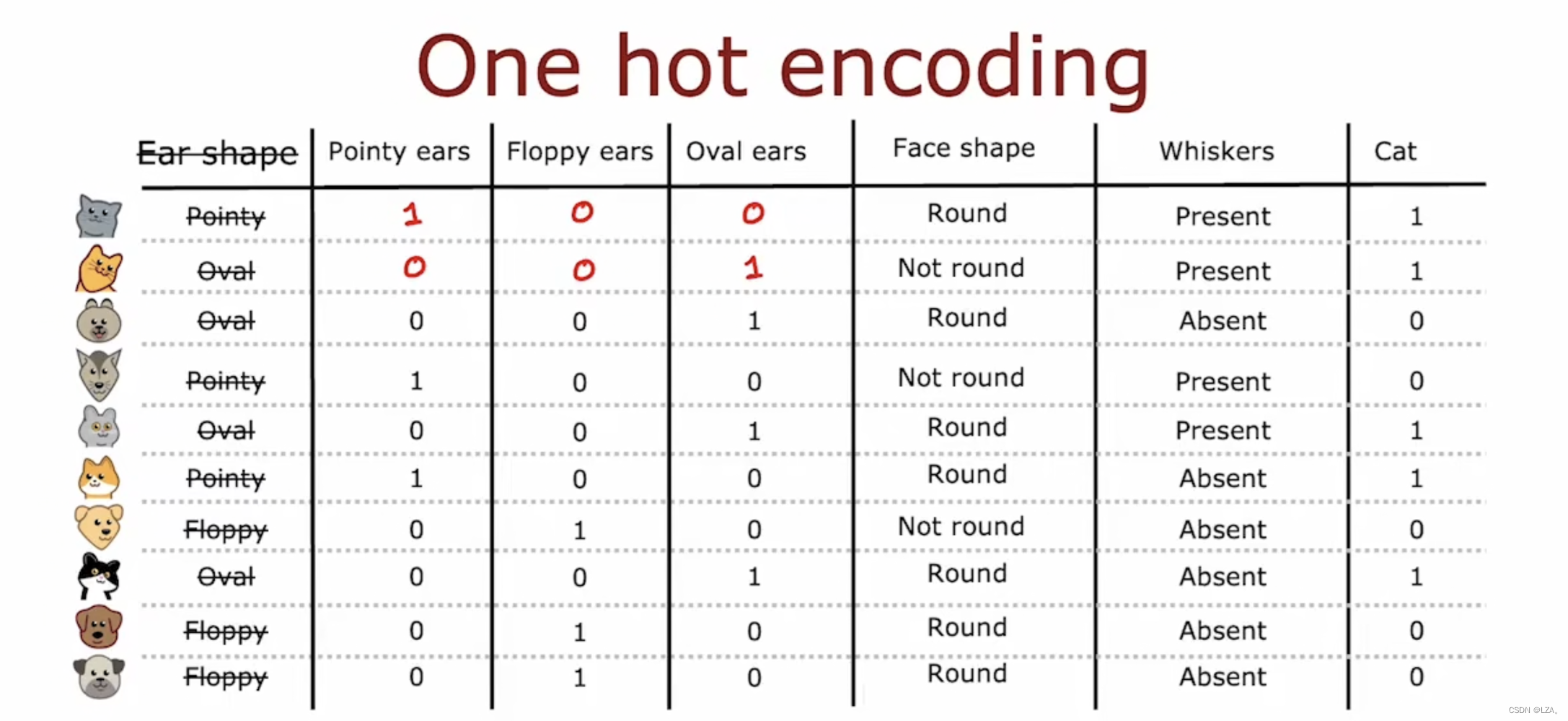
我们可以很清晰的看到,如果这个动物的耳朵是什么形状,则将其置为1,其他则置为0,它构建了三个新的特征,而并不是一个特征采用了三个可能的值,每个特征只能采用两个可能值中的一个,0或者1。
因为其中一个特征始终取值为1,即热特征,故得名one-hot encoding
one-hot也同样适用于训练神经网络
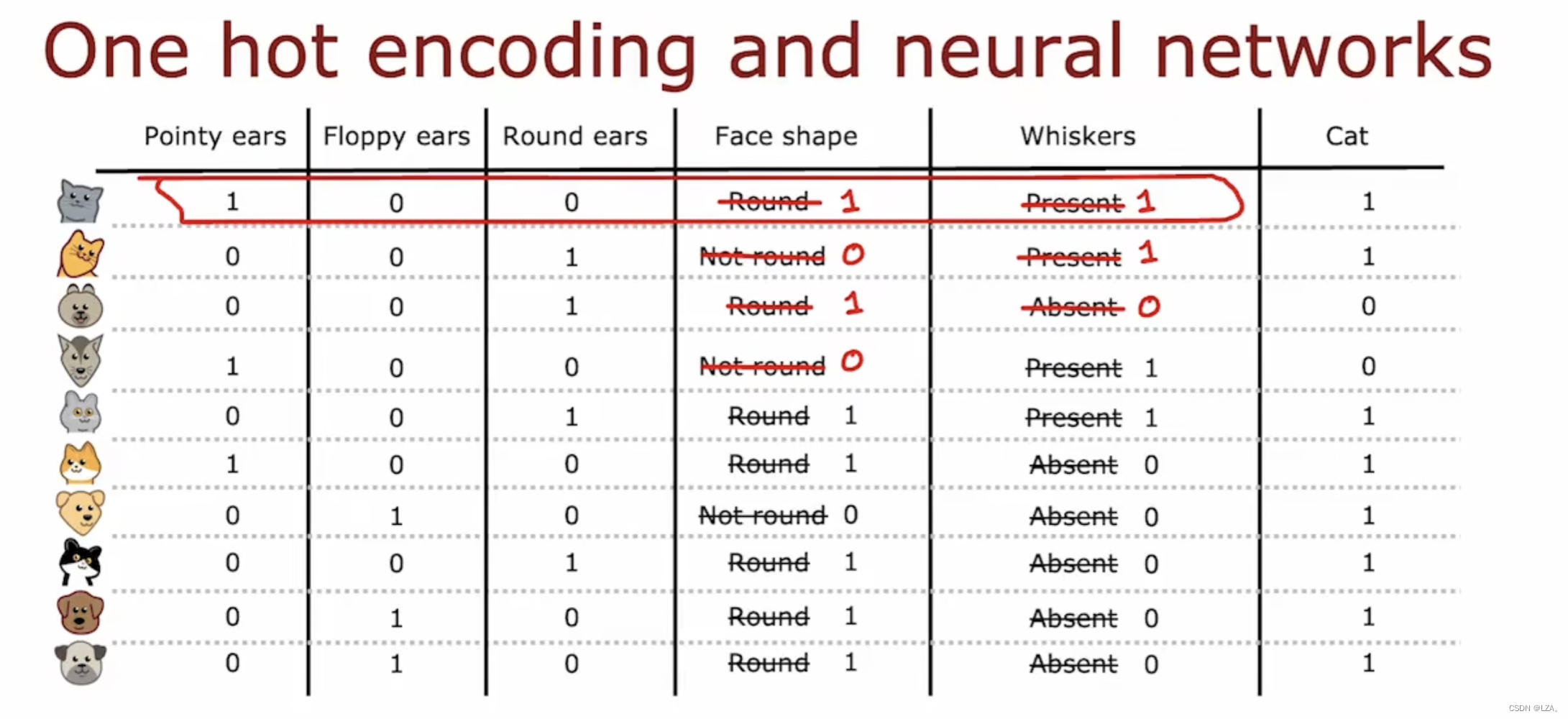
五个特征列表也可以提供给新网络或者逻辑回归以尝试训练分类器,one-hot不仅适用于决策树,可以使用1和0分类特征进行编码,可以作为输入提供给神经网络。
连续有价值的功能
我们除了可以利用一些耳朵形状,面部特征就识别是否是猫,我们还可以通过动物的重量去识别,但是动物的重量这并非像之前的特征一样,具有固定的几个值,动物的重量是一个变化的不定的值,那么我们如何去利用这个变量去判断呢?
权重特征上进行拆分比其他选项提供更好的信息增益。
我们可以像之前如何选择决策树合适的特征那样,我们去选择一个合适的重量范围,我们可以通过计算不同重量区间的信息增益,得出我们应该需要哪个范围,如下图所示:
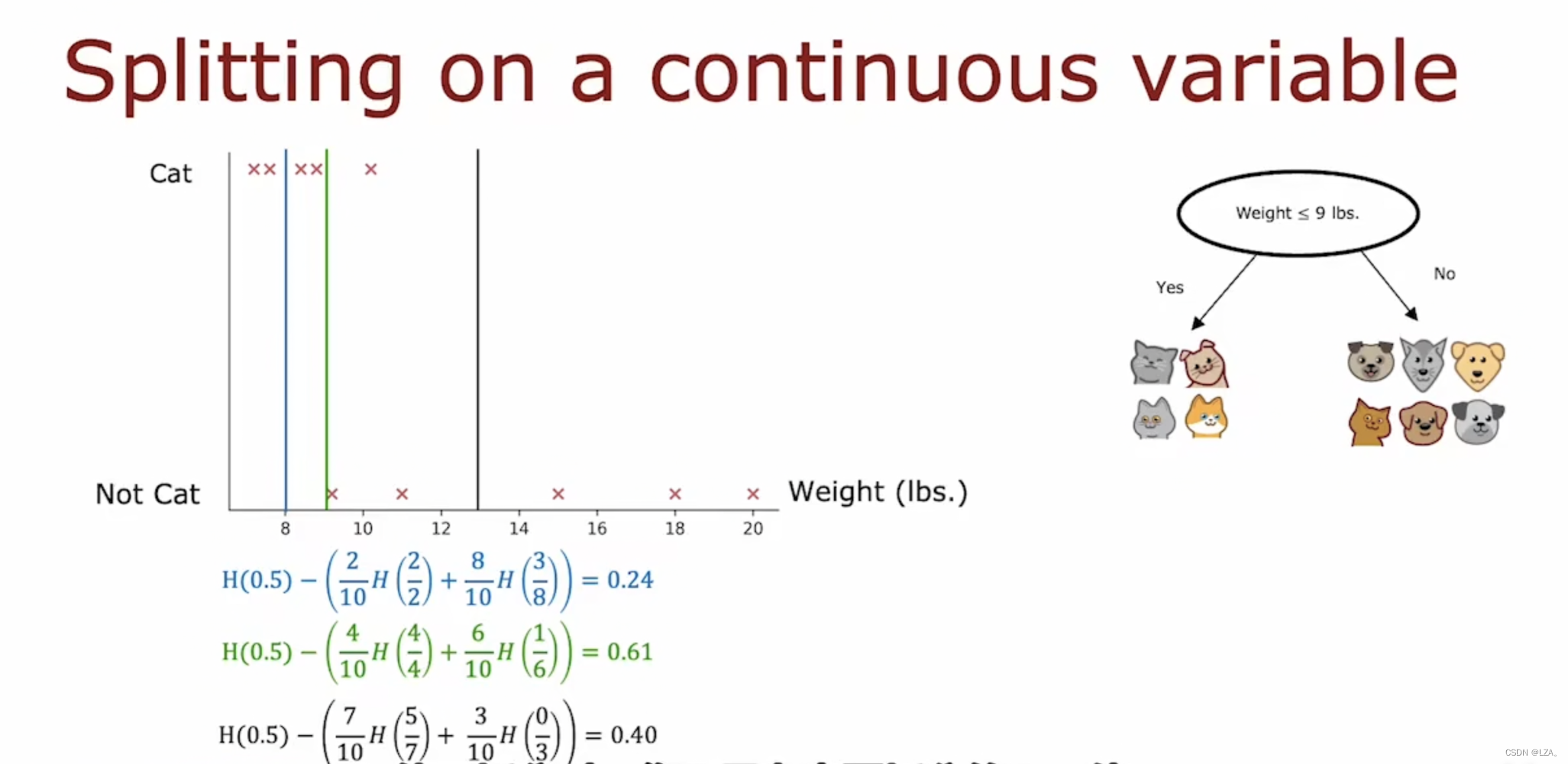
我们可以看到,当我们按重量8来算,它的信息增益为0.24,按重量9来算,它的信息增益为0.61,按重量13来算,它的信息增益为0.40,所以我们应该去选择信息增益大的那个重量范围,选择重量9.
选择不同的值进行信息增益的计算,选择最大的信息增益的那个区间,使用拆分时,只需要考虑要拆分的不同值,执行信息增益的计算,并决定在该连续值特征提供尽可能高的信息增益进行拆分,所以我们尝试不同的阀值,来选择最好的信息增益来进行拆分。
回归树
我们之前只讨论了决策树的分类算法,就是预测这个是否是一个东西,是1还是0,我们在这里将决策树概括为回归算法,简称回归树,我们可以去预测一个数字。
比如我们预测什么形状的猫的重量,通过重要的平均值来计算叶节点处的值,如下图所示:
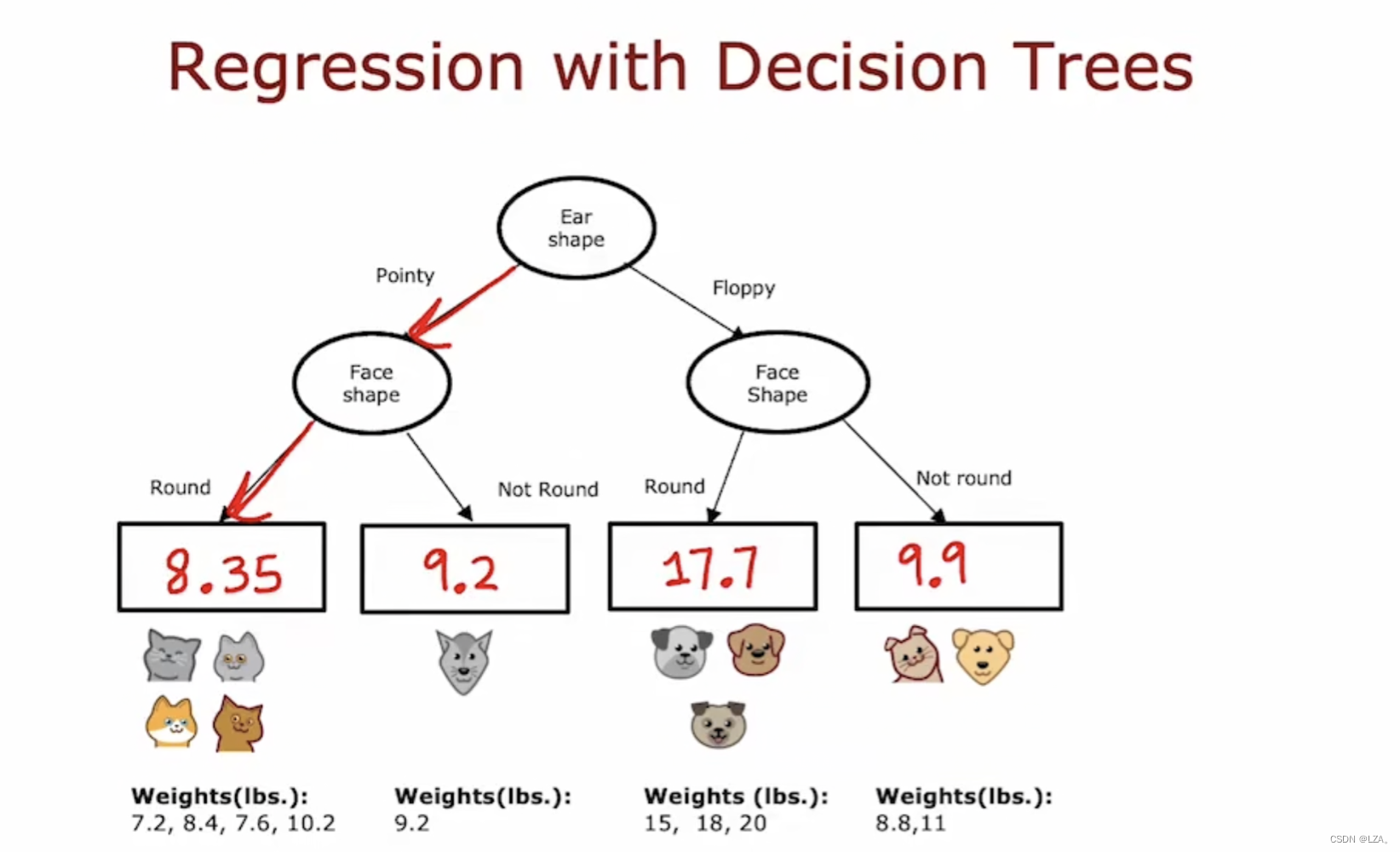
那么前提是我们怎样才能像分类算法的决策树那样去选择一个合适的特征呢,最后计算出预测的重量,若不是分类算法,而是回归算法,如何选择一个可以最好预测动物的体重的特征?
我们构建回归树,不是试图去减少熵(分类问题杂质度量),而是试图减少每个数据子集的值的权重方差。
方差是衡量组内样本的离散程度,加权方差衡量拆分后两个组整体的离散程度,选择拆分的一个好办法是选择最低的加权方差值。
我们可以利用统计学求方差的公式,计算每一个特征分出来的左右分支的方差,在将其方差和数量权重相乘在相加,最后让根结点的方差去减去这个值,相当于分类算法的信息增益,选择最大的那个,因为权重方差减少的快,最大的方差减少,像我们之前选择最大信息增益的那样,我们去选择提供最大的方差减少的那个特征,如下图所示:

通俗的讲,我们计算最开始根结点的方差,在计算加权方差,根结点的方差减去加权方差,哪个值最大,就相当于我们之前的信息增益最大,我们就选择那个特征,比如上图,我们应该选择Ear Shape,也就是耳朵形状这个特征,因为它的最大方差减少的最快。
使用多个决策树
在我们之前的案例中,我们都是使用单个决策树,使用单个决策树的缺点之一是该决策树可能对数据中微小变化高度敏感,所以,我们可以构建很多决策树,也就是树的集成。
如果将其中一种变化,可能得到的特征不同,左右子树中获得的数据子集完全不同,仅仅改变一个训练样本会导致算法在根部产生不同分裂,产生一颗不同的树,这使得算法变得不那么健壮。
我们可以构建很多决策树,在新的示例运行所有的决策树,并让他们投票决定是否为最终预测,不同的树可能会有不同的预测,让他们投票,找预测的多数票。如下图所示:
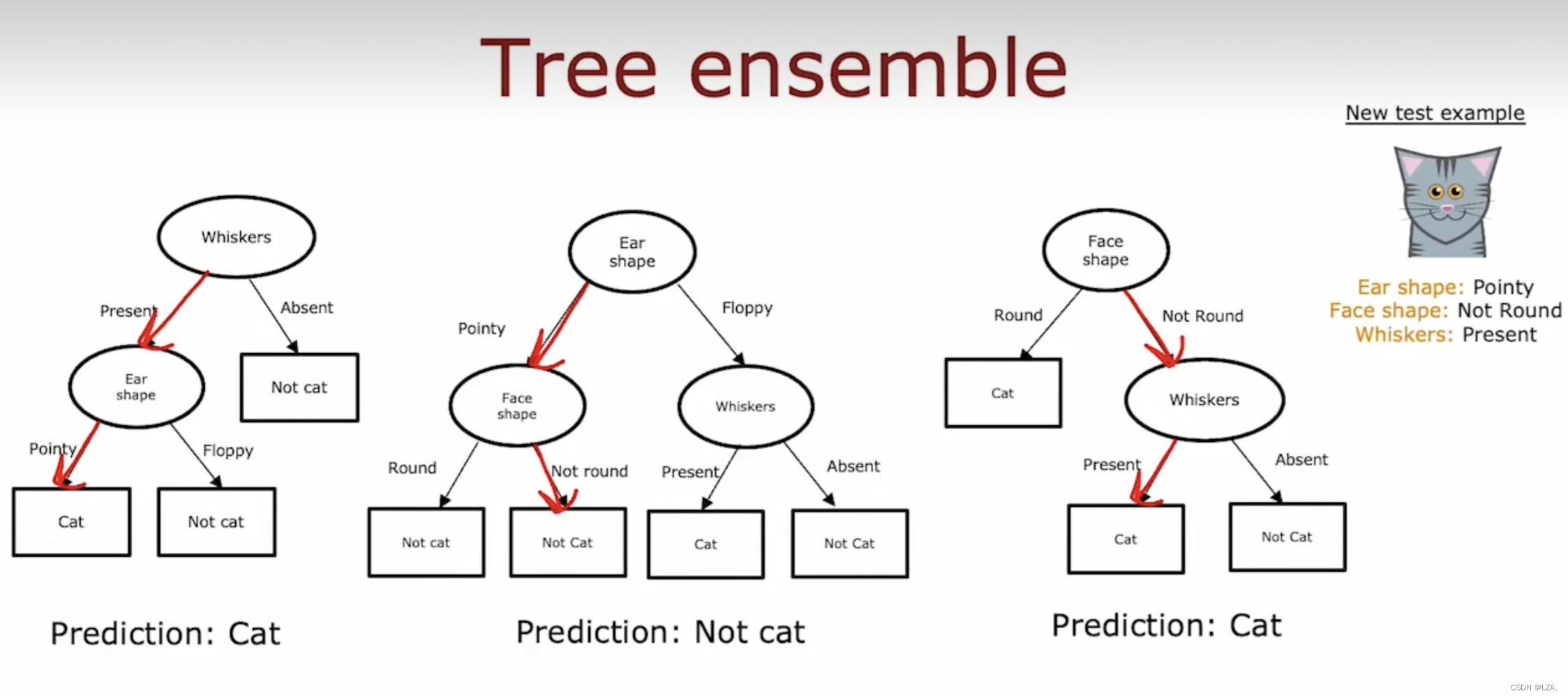
这个图片展示了,有三颗决策树,每一个决策树都不相同,其中有一个新的数据需要预测,在三颗决策树中有两颗预测为猫,另外一颗预测不是猫,根据投票决定,最终这个数据有很大的几率是猫。
有放回抽样
构建树的集成,需要一种有放回的抽样技术,也叫作替换采样。
有放回抽样应用于构建树的集成方式如下;
构建多个随机训练集合,相当于是对原始数据进行有放回抽样,抽样结果为随机森林的训练集合。
有放回抽样可以构建一个新的训练集合,与之前的训练集合有点相似,但是也有可能很大不同。
如下图所示:
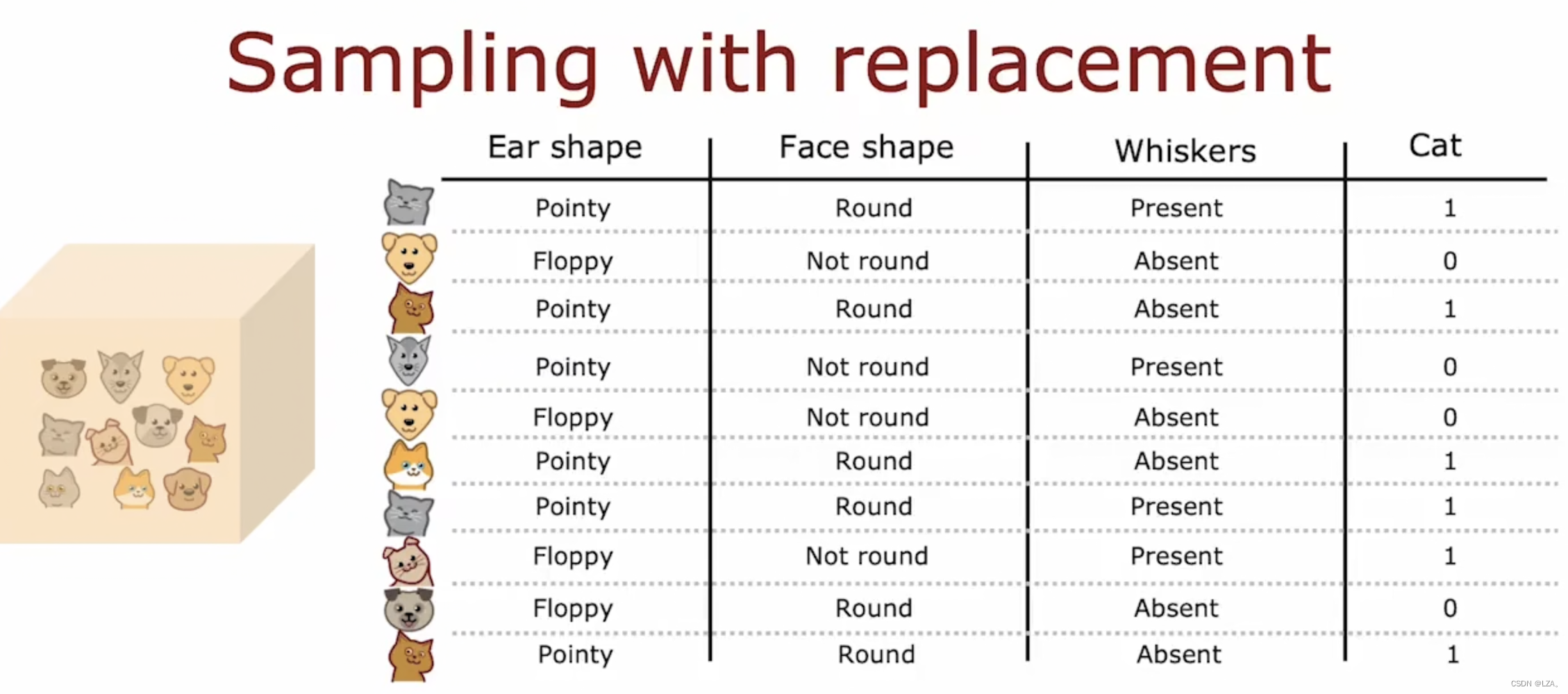
我们可以这样理解有放回抽样,将这些样本想象成不同的球放入一个不透明的箱子里面,我们进行随机的抓取,抓取之后记录是哪一个球,在进行放回箱子,这就是有放回抽样,可能有摸到重复的样本,也有可能是全不一样的,但不可能让它全部一样。
随机森林
随机森林是树的集成算法,比使用单个决策树效果更好,具体实现如下图所示:

我们每次通过有放回抽样,得到一组m个训练样本,可能也会有重复的,并且在这个数据集训练决策树,之后再次进行有放回抽样,得到一组新的数据集,再次训练决策树,以此类推,可以做B次。
至于B的选择,如果决策树的数量是在100左右,那么B的值可以选择在64-228中的任何值,B的值太小会导致欠拟合,太大容易导致过拟合。
那么,我们可以发现,即使使用有放回抽样,可能还是在根结点处会使用相同的拆分,可能会在根结点处使用一模一样的特征进行拆分,碰到这种情况,我们可以选择更小的特征集合,在这个特征子集中选择用来拆分的特征,这样可以提高决策树的多样性。
如下图所示:

k的选择通常是n的平方根。
将参数范围缩小有助于避免过拟合,而且也不用担心某些关键参数没有被选上,因为是随机森林,这个决策树没有选上,还有下一个决策树。
XGBoost
在我们之前的例子中,给定训练集调整大小,重复B次,使用有放回抽样创建大小为M的新训练集合,然后在新数据集上训练决策树。
我们可以进一步的进行优化,可以在构建下一个决策树时,将更多关注我们还没有做好的例子,我们应更多关注示例的子集,比如说我们构建一颗决策树,在构建下一个决策树之前,我们将这个决策树的结果返回到原始的例子,判断预测结果是否正确。
一开始随机森林算法是通过一个基本的训练集合来构成一些随机相同长度的训练子集,但是内容有所不同,去训练好多个决策树,XGBoost算法它的本质是并非通过随机过程构建新训练集,而是更关注之前错的分类数据。
XGBoost内置正则化以防止过拟合。
XGBoost在代码的使用如下:
左方是处理分类算法时应用的,右方是处理回归算法时应用的。

何时去使用决策树
我们之前学过神经网络,现在也学习了决策树,那么我们何时去选择决策树去处理数据,何时去选择神经网络去处理数据呢?
如下图所示:

决策树适合处理结构化的数据,并不推荐使用处理非结构化的数据,比如图片,视频和文本,决策树一般运行会更快一些,而且小的决策树可以让人们更好更直观的了解是如何实现的。
而神经网络可以去处理结构化数据,也可以去处理非结构化数据,通常我们处理非结构化数据都是去使用神经网络,但是神经网络一般情况下可能比决策树慢一些,但是我们通过迁移学习,可能会更容易,构建多个模型一起工作,多个神经网络工作可能会更容易。
因此,哪个算法不能说是最优,或者最差,没有一个最好的算法,只有最适合数据的算法!
决策树以及随机森林案例
泰坦尼克号的生存情况预测:
首先我们利用决策树算法实现对泰坦尼克号的生存情况预测
import numpy as np
import pandas as pd
titan = pd.read_csv("train.csv")
titan.describe()
X = titan[["Pclass","Age"]] #特征数据集
y = titan["Survived"] #目标标签
X["Age"].fillna(value=X["Age"].mean(),inplace=True) #解决缺失值
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25)
from sklearn.feature_extraction import DictVectorizer
X_train = X_train.to_dict(orient="records") #将特征数据集转为字典
X_test = X_test.to_dict(orient="records")
transfer = DictVectorizer()
X_train=transfer.fit_transform(X_train)
X_test = transfer.fit_transform(X_test)
from sklearn.tree import DecisionTreeClassifier
# 将决策树实例化,参数为树的最大深度,叶子最小数目,最小分裂数目
estimator = DecisionTreeClassifier(max_depth=5,min_samples_leaf=2,min_samples_split=2)
estimator.fit(X_train,y_train) #将训练数据集训练
y_pred = estimator.predict(X_test) #预测
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_pred) #准确率
# 0.6636771300448431
接下来我们利用随机森林算法实现对泰坦尼克号生存的预测:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV #用于参数调优和模型选择
estimator = RandomForestClassifier() #将随机森林实例化
param = {"n_estimators":[100,110,120],"max_depth":[3,5,12]} #参数,决策树生成的大小和最大深度
gs = GridSearchCV(estimator=estimator,param_grid=param,cv=3)#传入参数,分类器模型,参数,交叉验证的折数
gs.fit(X_train,y_train) #训练训练集合
y_pred = gs.predict(X_test)
accuracy_score(y_test,y_pred) #准确率
# 0.7219730941704036无监督学习-聚类算法
在我们前面所学的都是监督学习,监督学习就是我们有数据集X和目标标签y,但是在我们现在即将要接触的无监督学习中,我们只有数据集X,没有目标标签y,所以我们无法告诉算法我们想要预测的正确答案y是什么,相反我们要求算法找到有关数据的一些结构。
我们要学习的聚类算法就是查看大量数据点并自动找到彼此相关或者相似的数据点,在数据中寻找一种特定类型的结构。
聚类算法- k-means
k-means算法是我么随机猜测可能要求它找到的两个聚类的中心位置,随机选择两个点,它们有可能是两个不同集群的中心。
k-means会重复做两个不同的事情,第一步是将点分配给簇质心,比如分为红十字和蓝十字,遍历这些点的每一个,查看它更接近哪一个点,把这些点中的每一个分配给它更接近的样本质心,并更改它们的颜色;第二步是移动样本质心,查看所有红点并取它们平均值,将红十字,也就是簇质心移动到红点平均位置,对另一个点也这样做,查看所有蓝点并取平均值,将蓝十字,另一个簇质心,移动到蓝点平均位置。
反复执行上述操作,查看每个点并将其分配给最近的样本质心,然后将每个样本质心移动到所有具有相同颜色的点的平均值,之后发现点的颜色或者样本质心位置没有更多变化,这时意味着k-means聚类算法已经收敛。
如下图所示,该k-means聚类算法已经收敛:
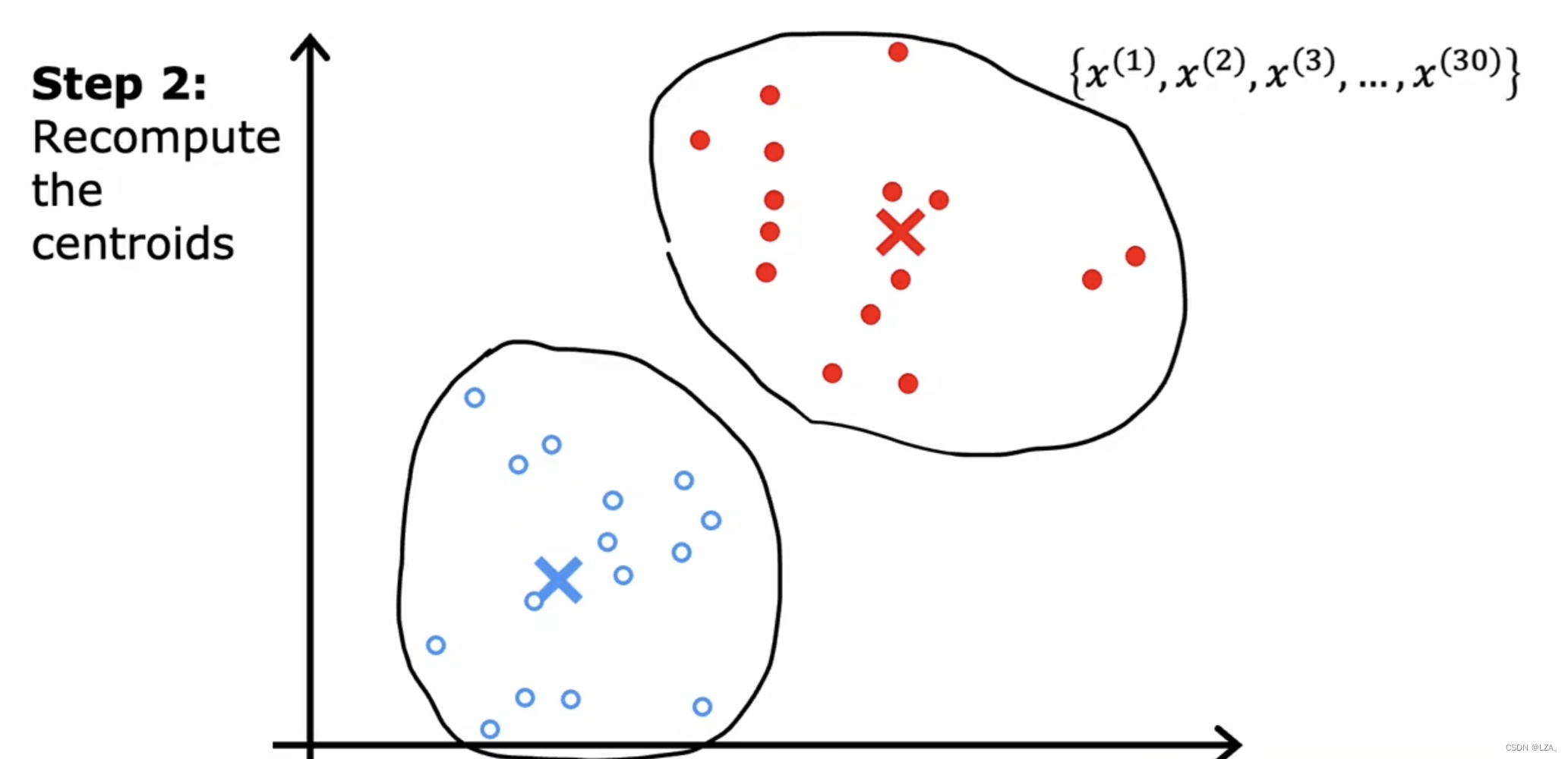
k-means算法的执行步骤如下图所示:

其中下方的x1,x2等,每一个都是包含两个数字的向量。
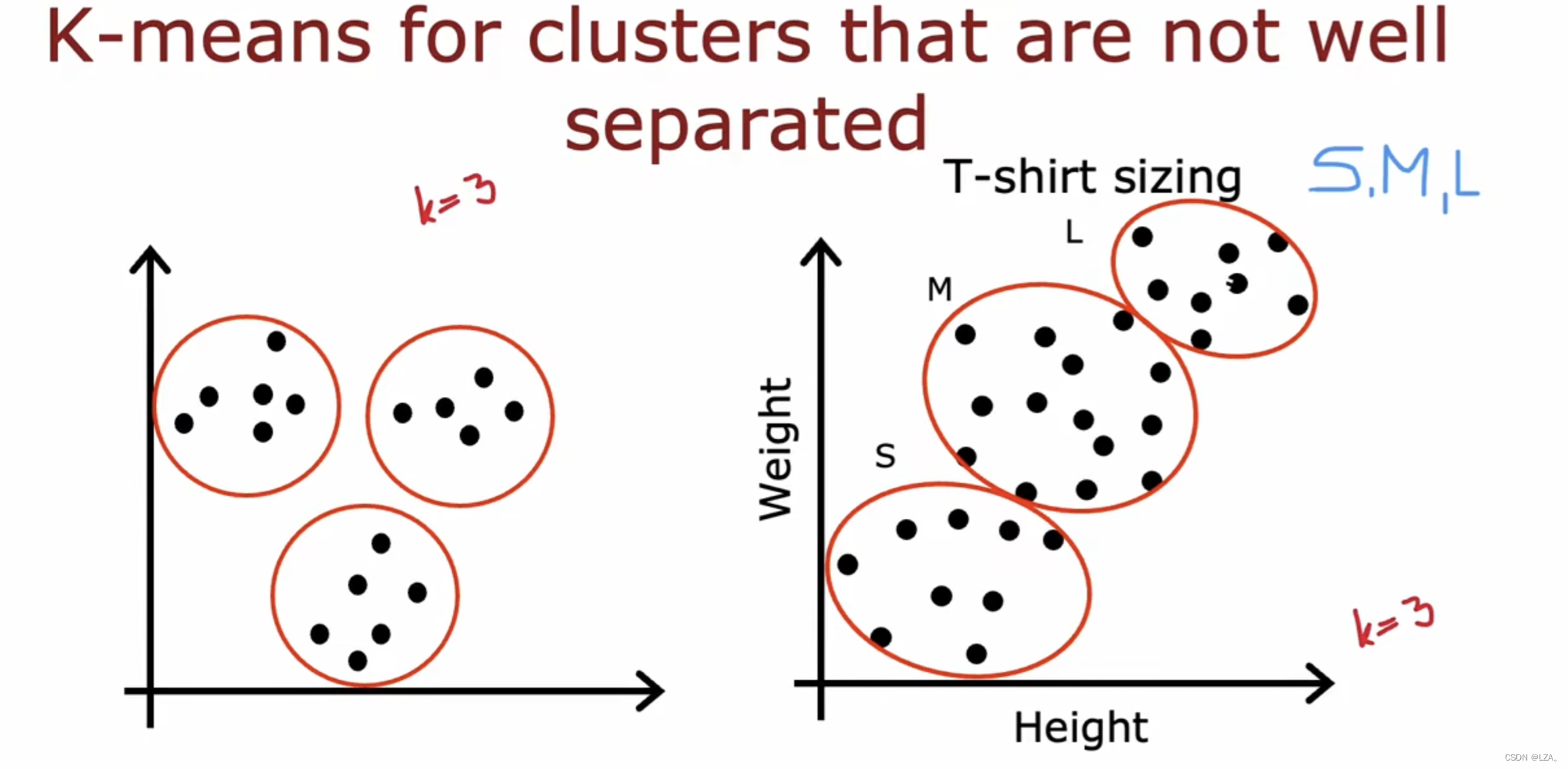
同样,k-means经常应用于集群分离不佳的数据集,如下图所示,我们可以通过每个人的身高和体重,来计算出哪一部分穿S码,哪一部分穿M码,哪一部分穿L码,所以说即使数据不位于分隔良好的组或集群中,k-means仍然工作的很好并且得出有用的结果。
无监督学习-优化目标
前面已经学习到k-means算法是如何实现的,那么我们可以发现,最开始的随机找取K个样本质心,我们如何判断这个算法的好坏的呢?在之前我们学习到的监督学习,我们有成本函数,我们可以利用成本函数来得知算法的好坏,同样在无监督学习的k-means算法,成本函数同样存在,具体公式如下:

其中m是实例的数量,k是分成的集群个数,样本质心,就是要把点分到几个类里面。
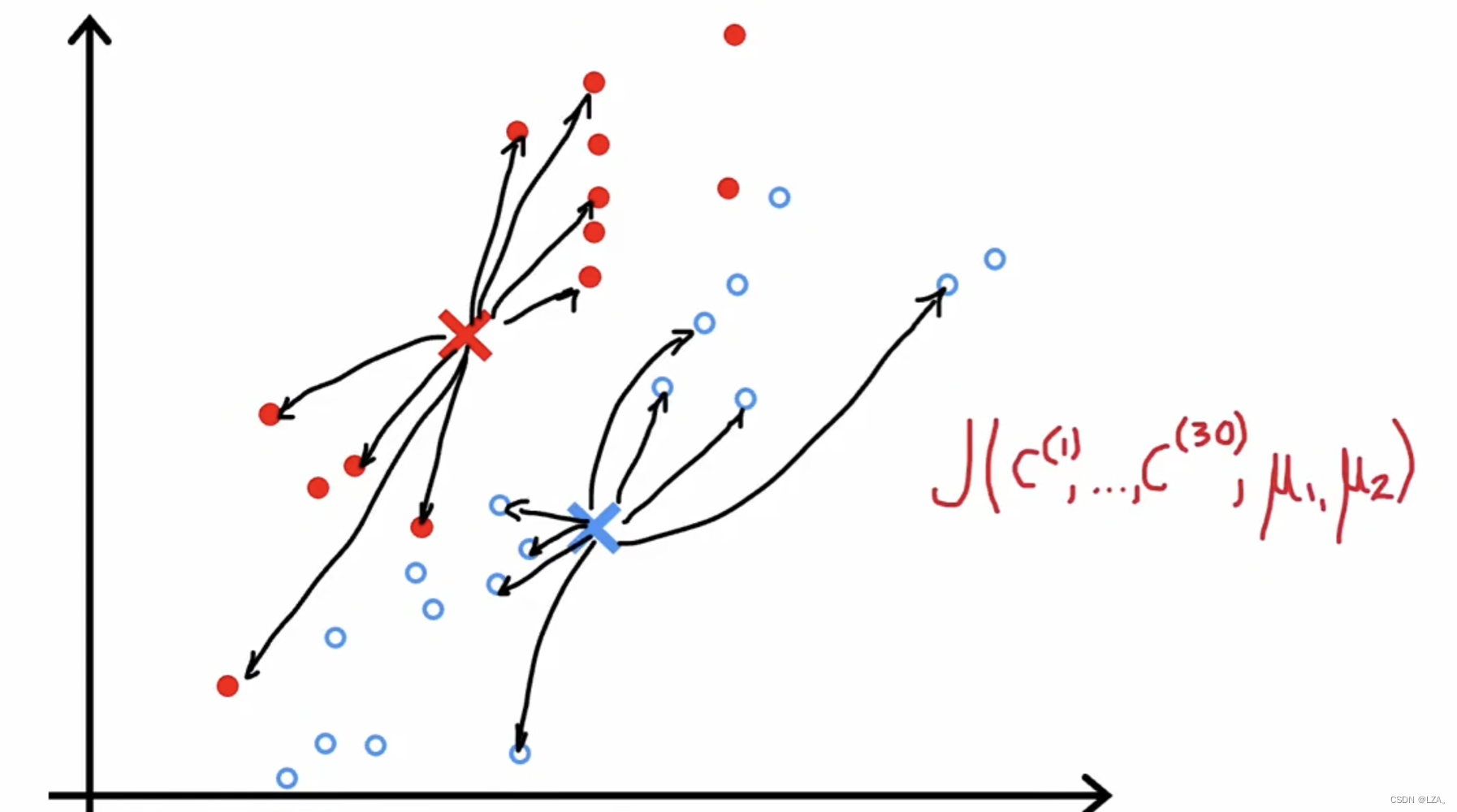
该上图可以很直观的表示,红点和蓝点的所有这些差异的平方的平均值就是成本函数J的值,当然,J越小,代表这个算法越好。
k-means算法的步骤如下:

k-means的每一步都在使成本函数J更小。
初始化k-means
我们知道k-means算法的第一步是选择随机位置作为样本质心,那么如何进行随机位置的猜测呢,使得可以找到更好的集群,也就是说我们如何来实现我们下图的第一步呢?

首先,m是训练示例的个数,k是我们样本质心的个数,当我们进行随机位置作为样本质心时,要保证样本质心的个数K要小于训练示例的个数m,如果,样本质心的个数k大于训练示例的个数m的话,我们将没有足够的训练示例让每个样本质心至少有一个训练示例,如下图所示:

接下来,我们多次运行k- means,尝试找到最佳局部最优值,计算其成本函数J,根据成本函数J的最低值,来选择我们最终样本质心的最佳位置,如下图所示:
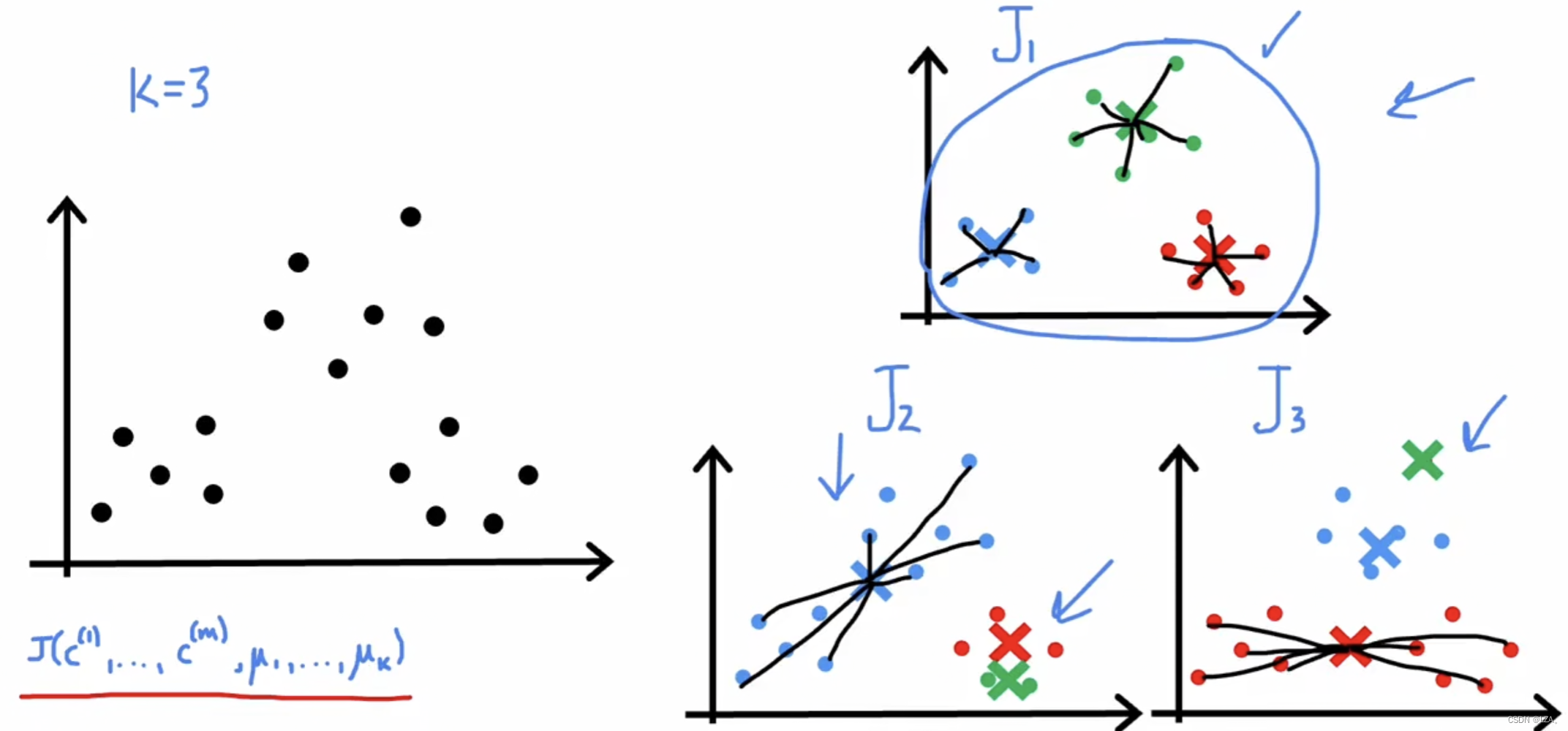
我们从上图中可以很清楚的看到,当我们样本质心的数目为3的时候,样本质心的位置可以影响到成本函数的变化,成本函数越小,算法越好,我们通过样本质心的不同位置来计算成本函数,选择能使成本函数最小的样本质心的位置。

对于这个算法,我们通常的循环次数在50到1000,循环次数过少,会导致找不到更好的位置,循环次数过多,会导致计算压力过大。
在这一节,我们样本质心的数量举的例子为3,它为什么是3,而不是其他数字呢,在下一节,将介绍我们如何去选取样本质心个数。
选择聚类的数量
我们应该如何去选择最适合样本的样本质心个数呢?
聚类是无监督学习,它并不会以特定标签的形式给出饮用正确答案来尝试复制数据本身并不能明确指示有多少集群。
选择我们k值,也就是样本质心的数量的第一种方法称为肘法(elbow method),使用各种k值运行k-means,并将J绘制为数字的函数集群,当集群很少,成本函数J会很高,随着集群数量的增加,成本函数会下降,选择其肘部作为样本质心的个数,如下图所示:
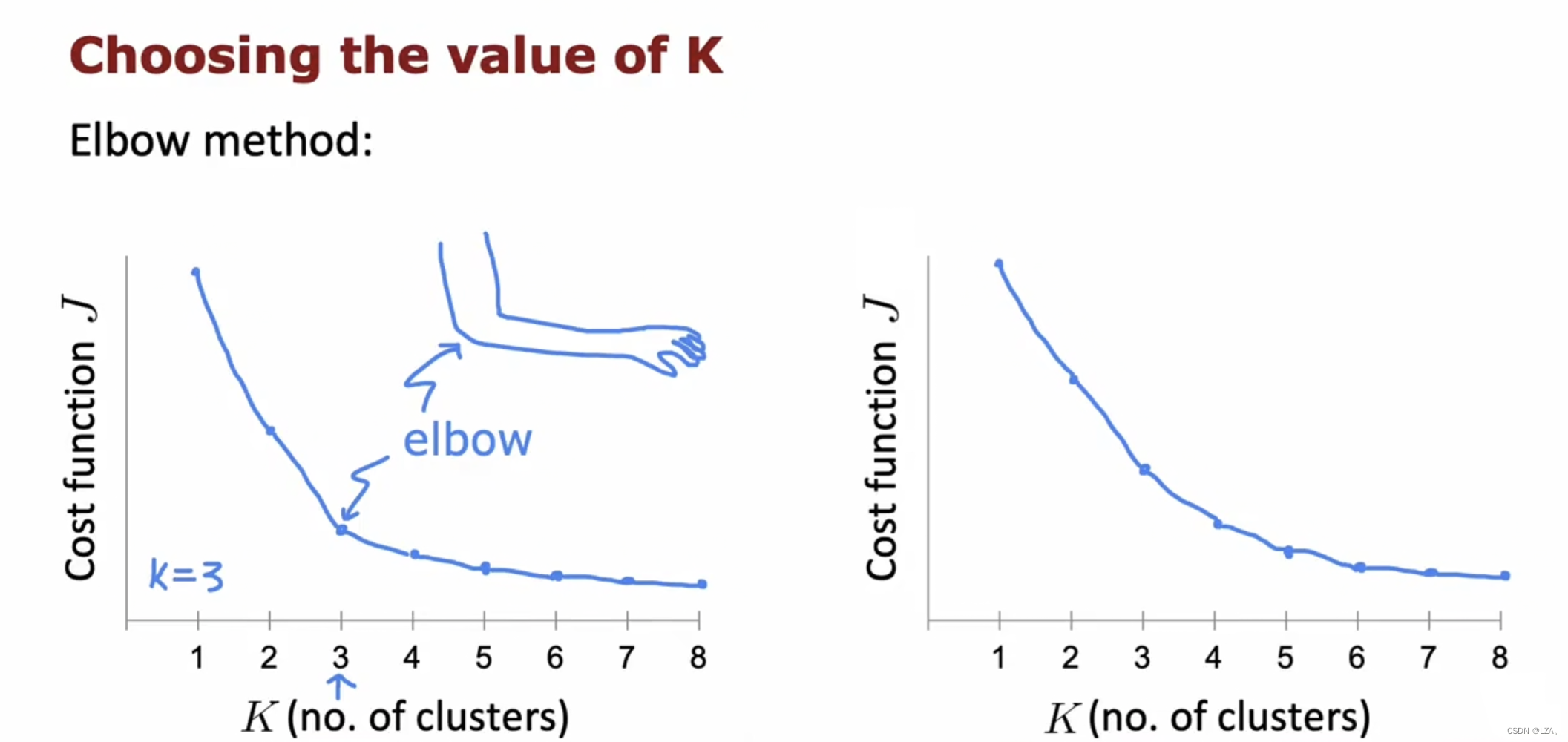
在这个例子中,这是k的数量和成本函数的函数图像,我们选择其肘部,为3,所以在这个算法中,我们选择样本质心的个数为3。
当然,很多成本函数J会平滑的减少,并没有明确的弯头,选择K来最小化J并不是好的方法。
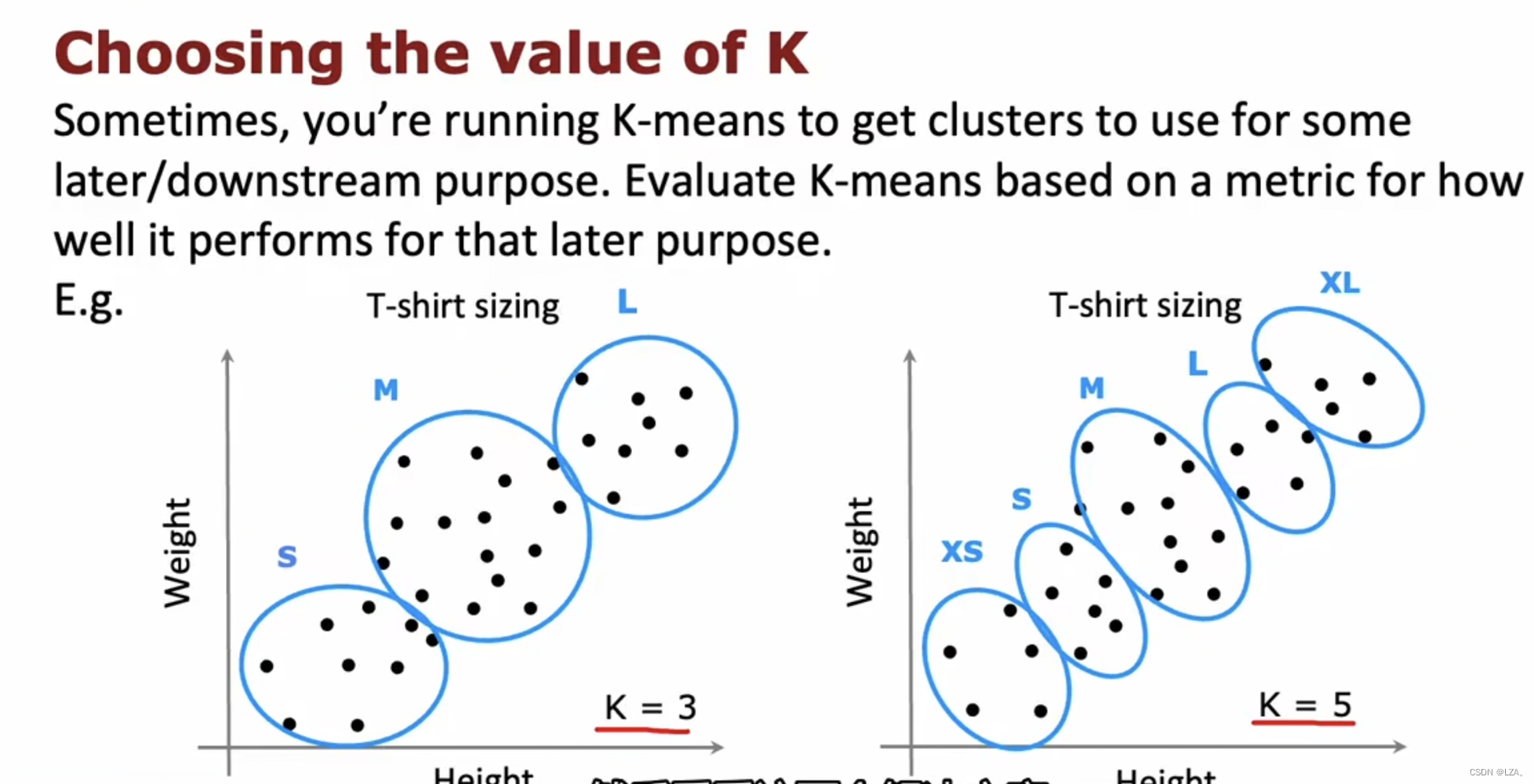
所以,我们应该采用更有意义的内容去来决定样本质心的数量是多少,比如一个无监督学习的样本,有我们的身高和体重,如果我们想制定衣服的尺码为S,M,L,那么我们样本质心的个数就设定为3,如果我们想制定衣服的尺码为XS,S,M,L,XL,那么我们样本质心的个数就设定为5,这是一种主观判断和具体应用相关的。
PyTorch
神经网络-最大池化的使用
池化过程在一般卷积过程后。池化(pooling) 的本质,其实就是采样,选择某种方式对其进行降维压缩,以加快运算速度。
我们采用最多的一组池化过程叫做最大池化(Max Pooling),故名思义,就是寻找卷积输入中,卷积核大小的那个矩阵最大的值,选择最大值输出到下一层。
具体的代码如下:
首先我们先引入相关的模块:
import torch
from torch import nn
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter引入测试数据集,并将其转化为tensor类型
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor())在PyTorch中创建一个数据加载器,每批包含64个样本
dataloader = DataLoader(dataset=dataset, batch_size=64)创建一个卷积神经网络模型类,其中包含一个最大池化层,用于对输入数据进行池化操作。
class NetWork(nn.Module):
def __init__(self):
super(NetWork, self).__init__()
self.maxpool1 = nn.MaxPool2d(kernel_size=3, ceil_mode=False)
# ceil-mode向上取整,如果输入大小无法整除池化窗口大小,那么会向上取整,保证输出大小能够覆盖整个输入
def forward(self, input):
output = self.maxpool1(input)
return output其中最大池化的操作为调用卷积神经网络的MaxPool2d的方法,kernel_size=3指定了池化窗口的大小为3x3。参数ceil_mode=False表示在进行池化时,不使用向上取整的模式。
最后利用forward前向传播,返回output
之后我们将NetWork实例化
network = NetWork() # 创建神经网络最后我们将卷积输入之前的图片和卷积输入之后,进行最大池化操作后的图片输出到tensorboard中,具体代码如下:
writer = SummaryWriter('logs')
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images('input', imgs, global_step=step)
output = network(imgs) # 池化不改变通道数,还是三通道,就能展示
writer.add_images('output', output, global_step=step)
step += 1
writer.close()并且池化不改变通道数,还是三通道,我们就可以在tensorboard中展示。
tensorboard中的展示如下:
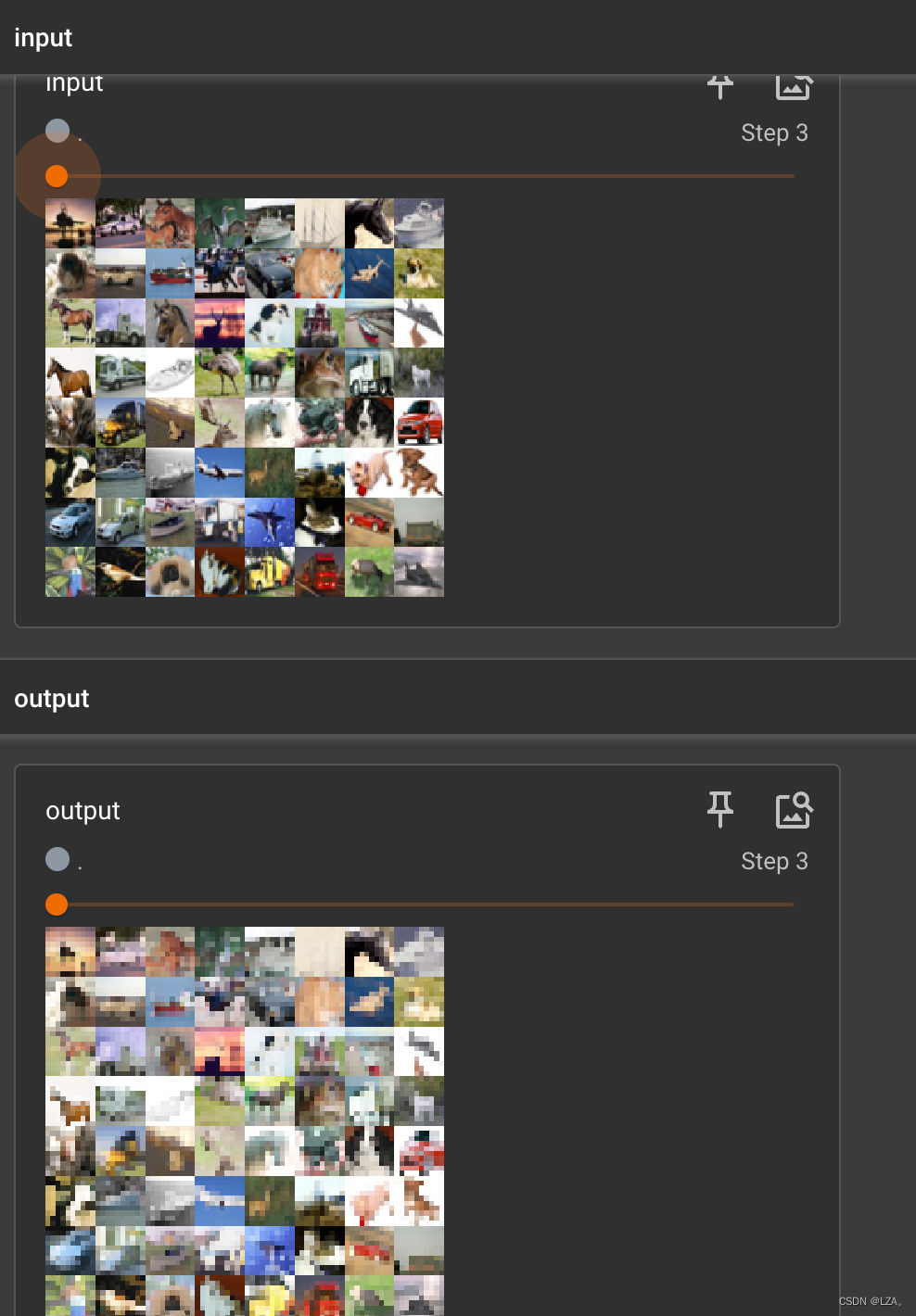
最大池化的优点:数据量变小了,效率更高,更快
卷积的作用是提取特征,池化的作用是降低特征的数据量,剔除冗余的信息,保留数据特征,减少数据量。
神经网络-非线性激活
Relu函数和sigmoid函数都属于非线性激活函数,以下是这两种函数的定义。
首先,ReLu函数是一种简单且广泛使用的非线性激活函数,其定义为 f(x) = max(0, x)。它在输入大于零时返回输入值本身,在输入小于等于零时返回零。这种非线性的特性使得神经网络能够学习复杂的非线性关系。
其次,Sigmoid函数是另外一种常见的非线性激活函数,其定义为 f(x) = 1 / (1 + exp(-x))。它将输入值映射到一个区间在(0, 1)之间的输出,具有将输入压缩到有限范围的特性。Sigmoid函数常用于二分类问题的输出层,以输出0到1之间的概率值。
接下来,我们先用代码去体现Relu函数的作用。
首先,我们先导入相关的模块:
import torch
from torch import nn
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter接下来,我们去创建一个tensor类型的input输入,并将其重塑为一个四维的tensor输入。
input = torch.tensor([[1, -0.5],
[-1, 3]])
input = torch.reshape(input, (-1, 1, 2, 2))接下来,我们去搭建神经网络,应用relu激活函数
class NetWork(nn.Module): # 搭建神经网络
def __init__(self):
super(NetWork, self).__init__()
self.relu = nn.ReLU(inplace=False)
def forward(self, input):
output = self.relu(input)
return output其中这段代码是搭建了一个神经网络,里面的ReLU的参数inplace的意思是
假如input为-1,inplace为True,则经过relu,input变为0,就是与原来的变量做替换;若inplace为false,则经过relu,input不变,还为1,ouput=Relu(input,inplace=False)变为了0
当我们搭建完神经网络后,我们去创建神经网络,去将这个神经网络实例化
network = NetWork()最后,我们将input变量传入神经网络中,输出output。
output = network.forward(input)
print(output)输出结果为:

我们可以发现,将其中输入的小于0的元素,输出全为0,输入大于0的元素,输出不变。
下面,我们用代码去体现sigmoid函数的作用
首先,去引入我们的数据集合,转化为tensor类型,并创建数据加载器,每批展示64个样本。
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset=dataset,batch_size=64)之后,去搭建神经网络,用于sigmoid函数
class NetWork(nn.Module): # 搭建神经网络-sigmoid激活函数
def __init__(self):
super(NetWork, self).__init__()
self.sig = nn.Sigmoid()
def forward(self, input):
output = self.sig(input)
return output在这里我们调用的是神经网络中的sigmoid函数,最后将其输出
创建神经网络,将其实例化
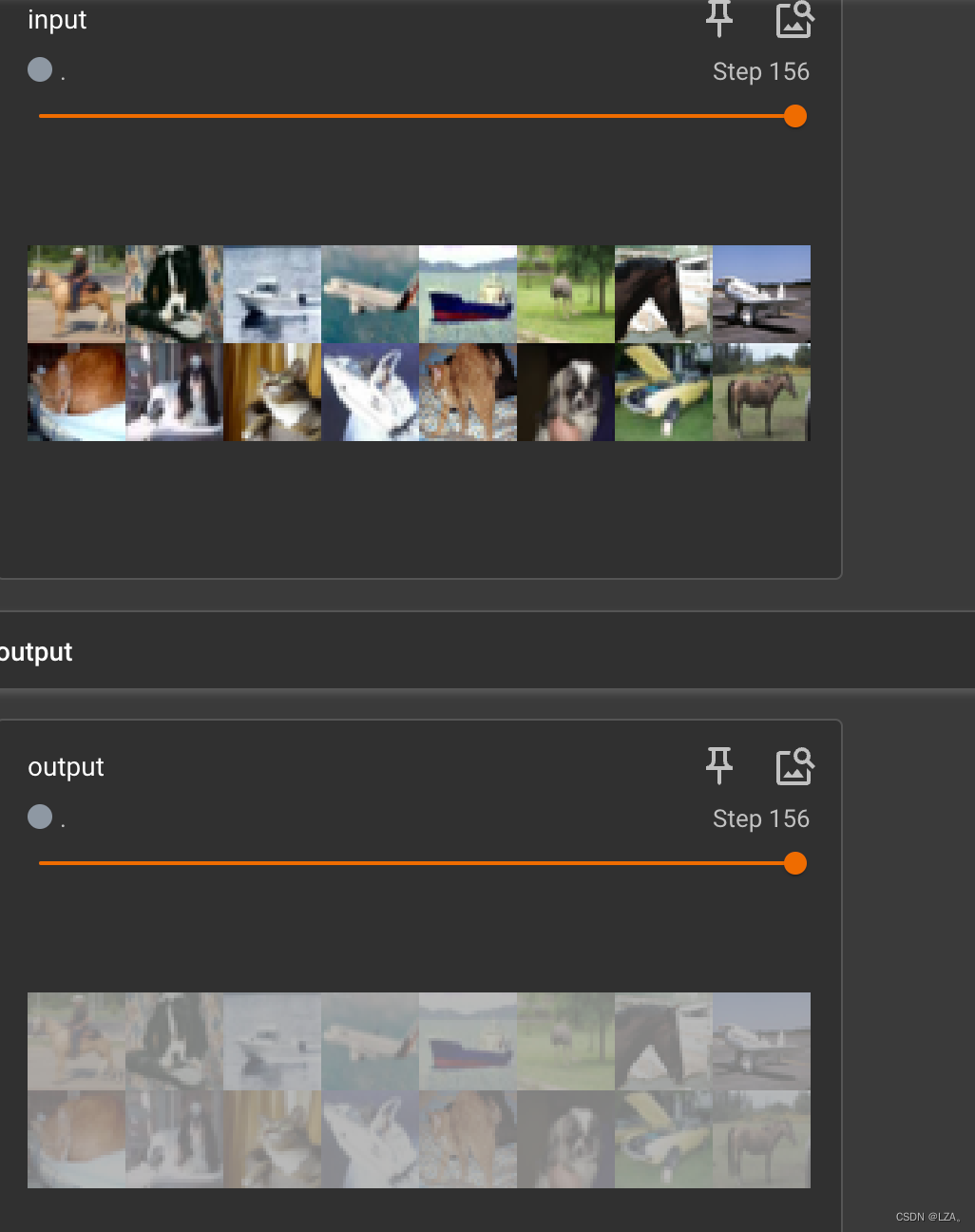
network = NetWork()最后,进行for循环,将其原始照片传入tensorboard,和经过sigmoid函数的神经网络的输出传入tensorboard
writer = SummaryWriter('logs')
step = 0
for data in dataloader:
imgs,targets = data
writer.add_images('input',imgs,global_step=step)
output = network.forward(imgs)
writer.add_images('output',output,global_step=step)
step += 1
writer.close()
print('ok!')在tensorboard中的显示为:
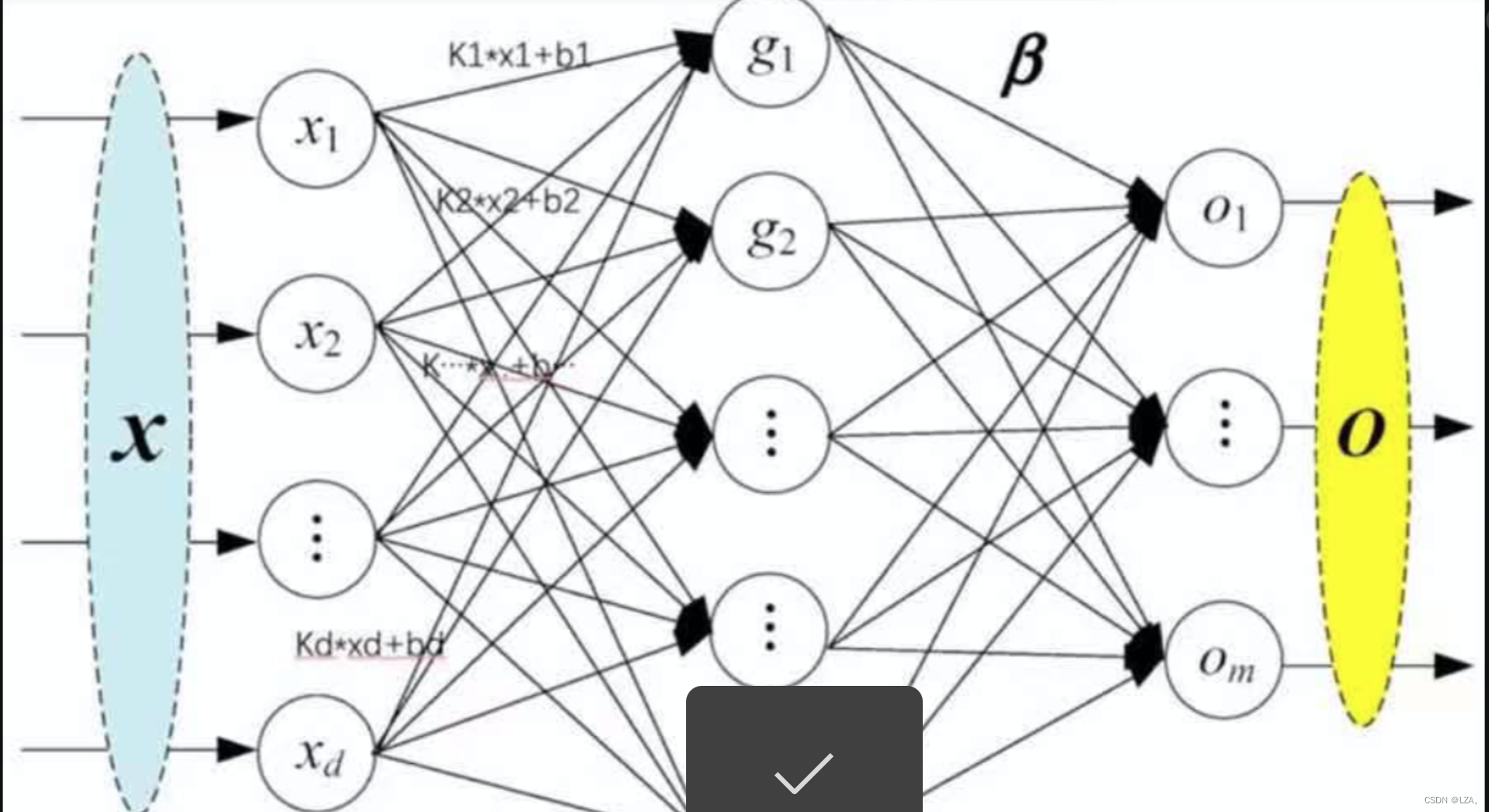
神经网络-线性层
线性层又叫全连接层,其中每个神经元与上一层所有神经元相连,一个简单的线性层如下图所示:
其中利用神经网络线性层的相关代码如下:
首先,引入相关的模块
import torchvision
import torch
from torch.utils.data import DataLoader
from torch import nn
接下来,导入我们所需要的数据集,转化为tensor类型,并创建数据加载器
dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset=dataset, batch_size=64,drop_last=True)之后,创建我们的神经网络,其中nn.Linear后的参数为:
in_features为输入样本特征的大小
out-features为输出样本特征的大小
class NetWork(nn.Module):
def __init__(self):
super(NetWork, self).__init__()
self.linear1 = nn.Linear(in_features=196608, out_features=10)
def forward(self, input):
output = self.linear1(input)
return output将神经网络实例化
network = NetWork()最后,我们输入图片tensor类型,查看效果,我们展平的第一个方法是利用pytorch的重塑,前3位置为1,最后将输入之前图片的形状和通过神经网络输出之后的形状输出为
for data in dataloader:
imgs, targets = data
print(imgs.shape)
output = torch.reshape(imgs, (1, 1, 1, -1)) #展平操作
print(output.shape)
output = network.forward(output)
print(output.shape)
其中第一个数据是输入之前的形状,第二个数据是展平后的形状,第三个数据是展平之后的数据通过神经网络线性层,将特征大小变为10.
我们展平的第二个方式是通过pytorch中的flatten函数,将其展平
output = torch.flatten(imgs) # 展平最后我们的输出为以下图,省略了前3个数字

神经网络-Sequential
Sequential它是一个时序容器。Modules 会以他们传入的顺序被添加到容器中。包含在PyTorch官网中torch.nn模块中的Containers中,在神经网络搭建的过程中如果使用Sequential,代码会更简洁。
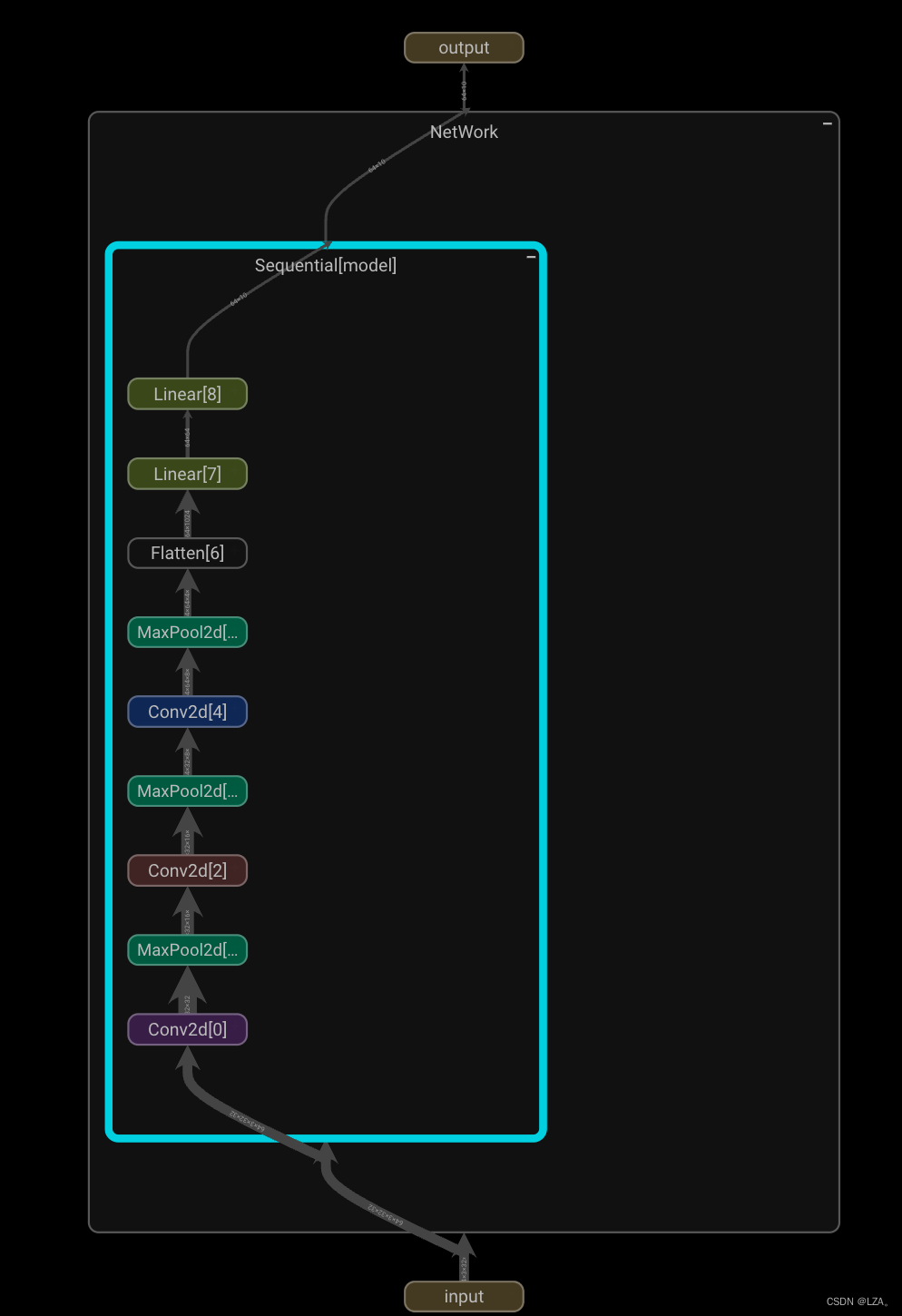
我们现在去搭建一个简单的神经网络,如下图所示,我们的输入图像是3通道32*32,先后经过卷积层(5×5的卷积核)、最大池化层(2×2的池化核)、卷积层(5×5的卷积核)、最大池化层(2×2的池化核)、卷积层(5×5的卷积核)、最大池化层(2×2的池化核)、拉直、全连接层的处理,最后输出的大小为10。
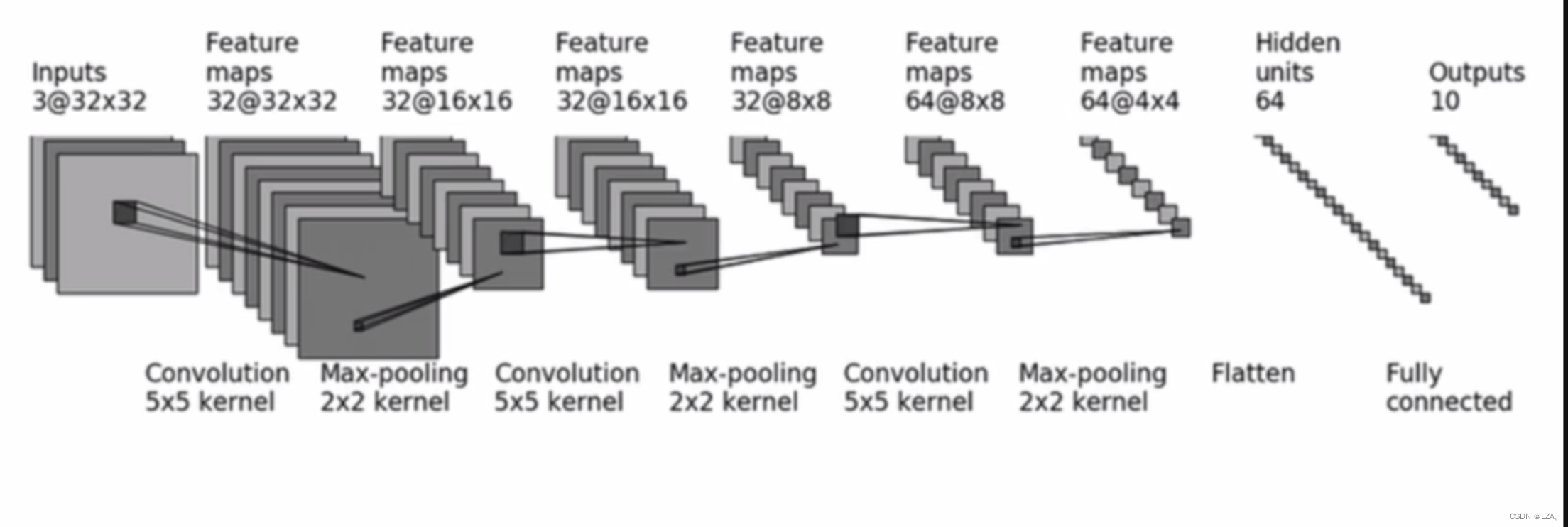
如果不使用Sequential,具体代码如下:
首先引入相关的模块:
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter接下来,搭建神经网络,在其中输入通道和输出通道,卷积核我们自己设定,其中的padding我们可以这样计算(padding=(kernelsize-1)/2),计算出来为2
class NetWork(nn.Module):
def __init__(self):
super(NetWork, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2)
self.maxpool1 = nn.MaxPool2d(kernel_size=2)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2)
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2)
self.maxpool3 = nn.MaxPool2d(kernel_size=2)
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(in_features=1024, out_features=64)
self.linear2 = nn.Linear(in_features=64, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x若使用Sequential,代码如下:
class NetWork(nn.Module):
def __init__(self):
super(NetWork, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(),
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model(x)
return x之后,将这个类实例化:
network = NetWork()输出network为:

创建一个输入,全为1的批量大小为64,通道为3,高和宽都为32的四维张量input,通过神经网络进行输出:
input = torch.ones(size=(64, 3, 32, 32))
output = network.forward(input)
print(output.shape)最后输出的形状为:
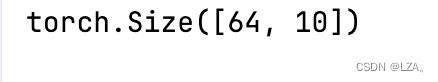
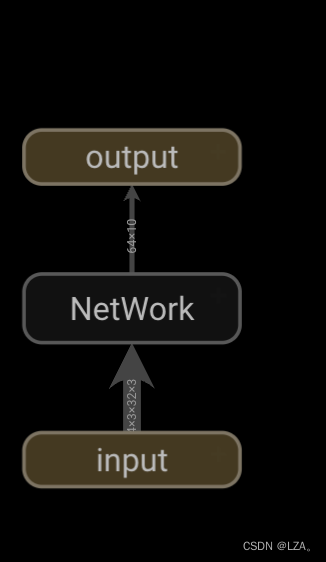
最后,将神经网络对应的计算图结构输出到tensorboard中为:
writer = SummaryWriter('logs')
writer.add_graph(model=network,input_to_model=input)
writer.close()tensorboard中为:
在计算图上点击相应节点,能查看到数据的具体流向和数据细节信息:
个人总结
在这一周中,主要去学习了解了监督学习中的决策树以及随机森林的概念,以及基本的算法实现,并且了解了无监督学习的概念以及其中的K-means算法,学习了深度学习框架PyTorch的一些基本神经网络层的使用,在下一周会继续学习机器学习中的无监督学习的其他算法和PyTorch框架的其他使用。















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









