








导读:YMatrix 最近推出了 5.0 版本,同等条件下 SSB 性能比 ClickHouse 官方数据提升了 24%。本文将介绍新版本使用的性能优化技术,及最终的优化效果。
内容要点:
- 高性能时序数据引擎的技术栈
- 多核并行
- 时序存储引擎 MARS
- 向量化执行器
- 高效编码链
- 观测能力
作者 |YMatrix 性能优化方向负责人 王勇
一、时序分析场景的前景和挑战
时序数据是对实体对象持续观测得到的,带有时间戳的数据序列。例如数据中心的 CPU 利用率,证券交易所记录的股票价格,风电企业采集的风机转速等。
时序数据分析可以提供重要的商业价值。例如,金融时序分析可以及时发现欺诈、洗钱行为,阻止非法交易,挽回巨额损失。电商公司通过分析用户购买偏好和人群画像,实现实时、个性化推荐,大大增加交易额和客户满意度。在工业互联网领域,时序分析可以通过跟踪设备状态,结合订单情况进行产能匹配,优化供应链,提升设备利用率。物联网领域可以实时监测设备状况,及时阻止意外,还可以通过轨迹分析,实现实体追踪和异常行为检测。
如图 1 所示,随着工业互联网的稳步推进及物联网的兴起,联网设备呈指数增长,且远超传统的 IT 和通信设备。

图 1 联网设备增长趋势
时序数据分析在给业务发展带来更大潜能的同时,也给数据平台提出了巨大挑战。时序数据总量可以用:联网设备数量 x 采集频次 x 指标数量 来估算。以新能源车企为例:
-
数据总量巨大。按 100 万辆车、采集周期 1s 、250 个指标进行计算,一天的数据量达 172 TB,一个月达 5.1 PB。数据存储成本、分级管理及数据库系统运维就成为重要问题。
-
快速写入。按上述计算,每秒的写入速度要求达到 2 GB/s。另外还需要处理乱序到达的数据、重复的数据写入,以及后续进行查询时增加的复杂性。
-
高速查询。时序分析一方面要面向众多车主提供高吞吐、低时延的明细查询,另一方面也要提供针对批量数据的异常检测和统计分析。同时还要向数据科学家提供更为复杂的多维数据分析,甚至机器学习的能力。
YMatrix
YMatrix 是主打时序场景的超融合数据库。它融合了 OLTP、OLAP、时空和数据湖的能力,简化了过去用户需要使用维护多套系统的复杂度,增强了数据的流动和整合。YMatrix 源于 Greenplum,而 Greenplum 又是基于 PostgreSQL 的 MPP 型数据库。YMatrix 继承了 Greenplum 及 PostgreSQL 优秀的设计、稳定的基因和丰富的生态,增强了时序、分析方面的能力。但 Greenplum 和 PostgreSQL 基础架构是在较早期 IO、Memory 和 CPU 资源都相对紧张的情况下做出的,YMatrix 着力优化了现代硬件条件下的性能,同时完整地保留它们的功能丰富性和企业级品质。
YMatrix 最新推出的 5.0,针对时序分析场景实现了一系列优化,并和 Clickhouse 这一业界的性能标杆针对 SSB 进行了对比测试。下面将给出结果并解读相关优化技术以及带来的性能提升。
二、SSB 性能结果
SSB(Star Schema Benchmark)是由麻省州立大学基于真实商业应用的数据模型定义的性能评测基准,学术界和工业界普遍用它来评价数据库在分析场景的基础性能。SSB 在 TPC 组织发布的 TPC-H 基准之上,将雪花模型改为更为实用的星型模型,将复杂的 Ad-Hoc 查询简化为更固定的 OLAP 查询。随着 ClickHouse 在 SSB 上展示了亮眼的单表“硬核”计算速度,很多产品也竞相采用 SSB 来验证自身的性能水平。受限于初始的应用场景和技术实现,CK 采用了将 SSB 的多张表扩展成单一宽表的模式(可参考官方文档)。虽然 YMatrix 有优秀的多表 Join 能力,但为了更有比较意义,这里采取和 CK 同样的单表方式来测试。测试采用了和 ClickHouse 相同的 AWS m5.8xlarge 云主机,测试结果为单台主机上的性能。

图 2 YMatrix 和 Clickhouse SSB 性能比较
图2 给出的是 100 倍数据集的性能结果,它的原始数据量约为 200 GB。可以看出 YMatrix 在全部 13 条查询中,有 10 条时间快于 CK,整体快 24%。测试中先进行一次查询预热数据,然后取连续 3 次的平均结果。具体测试过程可以参见:SSB 性能优化结果解读。在 1000 倍的数据集上,YMatrix 有更多的性能提升,由于 Clickhouse 没有披露官方的数据,因此这里不详细展开。
三、高性能时序数据引擎的技术栈
要达到全系统性能的大幅提升,需要全链路、多个模块互相配合才能实现。图 3 从查询的视角给出了实现高性能数据库引擎所需要的技术栈。
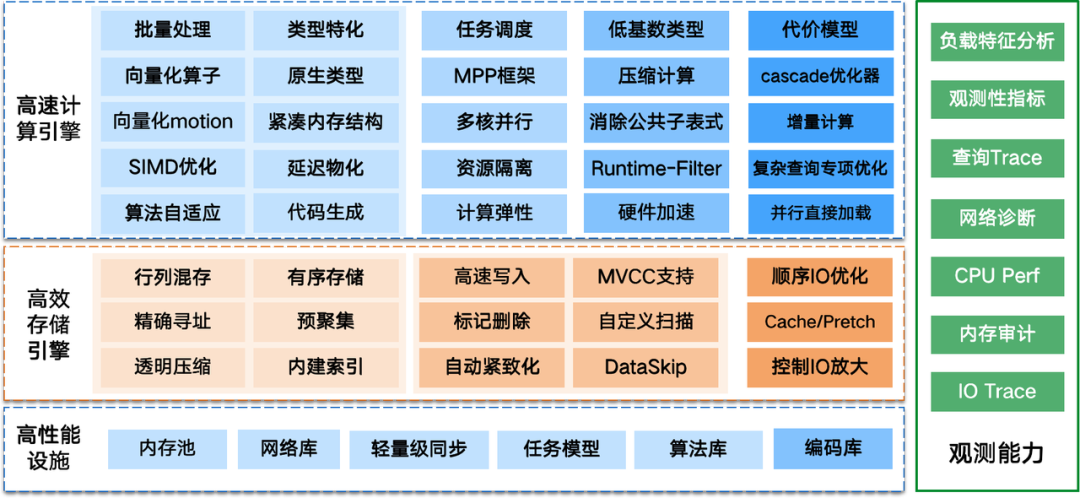
图 3 高性能时序数据库引擎的技术栈
高效的存储引擎。数据库是重数据处理的系统,存储引擎要尽可能精准地准备数据,减少需要处理的数据总量。这主要是靠列存技术和索引技术,分别从列和行的角度减少数据总量。即便在 SSD 大行其道的今天,IO 的代价仍然占很大比重。存储引擎还需要高效地使用 IO 资源,减少 IO 次数和对于存储带宽的占用。对于 HDD 介质,尤其要利用好顺序读吞吐远高于随机读的 IO 特点。精心设计的存储格式和索引策略,再配合 Cache 机制可以使得随机访问大大减少,充分发挥出 HDD 吞吐的能力。另一方面,针对列存,特别是时序场景,可以充分利用数据同质和随时间渐变的规律性,大大减少实际数据的存储量和 IO,同时可以提高缓存命中率,从而提升查询性能。
高速的计算引擎。计算引擎,也就是执行器的性能潜力首先取决于架构,这包括:线程/进程模型,pull/push 模型,算子调度流水线,通信模型,单机并行及资源控制的粒度等。对于分布式查询,架构还包括节点间数据分发和同步模型。对于较复杂的查询,配合精心调整的代价模型,cascade 优化器能选出更优的执行计划。在实际执行阶段,分析查询一般会处理较大的数据量,而向量化成为当下标准的优化技术。它一次处理一批数据,通过减少调用函数次数、提升 cache 效率,生成高质量的 SIMD 指令来提升性能。另外,对于某些特定类型、某些关键算子都可以采用更高效的方式来专门优化,当然需要付出某些维护代价。存储还需要和计算引擎配合,提供更高效的数据处理格式,比如列存。进一步,还可以充分利用硬件特性,如 NVMe SSD 和分布式内存来优化性能,甚至直接使用硬件加速卡。
高性能的基础设施对性能也起到关键作用,尤其是在数据处理已经很快的情况下。这些技术包括内存池化技术、高效的网络库、轻量级的同步机制、全异步、无锁的任务模型、高效的编码库,以及字符串匹配、基本运算、排序等基础库。
全方位的观测能力。例如,能全面呈现查询执行过程各个算子、关键步骤、节点间任务情况的查询 Trace;分析数据集和查询特征,辅助设计表结构和编码方案的工具;以及跟踪 CPU、内存、IO 使用热点及执行序列的工具。这些观测能力可以帮助理解系统与业务,驱动各种资源的饱和使用,同时消除不合理的资源使用,从而实现性能的迭代优化。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 249
249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









