







目录
前言
C语言部分基础知识的回顾和一些笔试题
1.笔试题
1.1 ++a与a++
a++是首先拷贝自己的副本,然后对真值加一
++a是对真值加一,然后使用真值
c语言提供一种特殊的运算符,逗号运算符,优先级别最低,它将两个及其以上的式子联接起来,从左往右逐个计算表达式,整个表达式的值为最后一个表达式的值。如:(3+5,6+8)称为逗号表达式,其求解过程先表达式1,后表达式2,整个表达式值是表达式2的值,如:(3+5,6+8)的值是14;a=(a=3×5,a×4)的值是60,其中(a=3×5,a×4)的值是60, a的值在逗号表达式里一直是15,最后被逗号表达式赋值为60,a的值最终为60。
逗号表达式详解_x=(x++,y++)-CSDN博客![]() https://blog.csdn.net/qq_43539854/article/details/105757536
https://blog.csdn.net/qq_43539854/article/details/105757536
#include<stdio.h>
int main()
{
int a = 0;
int c = 0;
int b = 0;
a = 5;
c = ++a;//c = 6
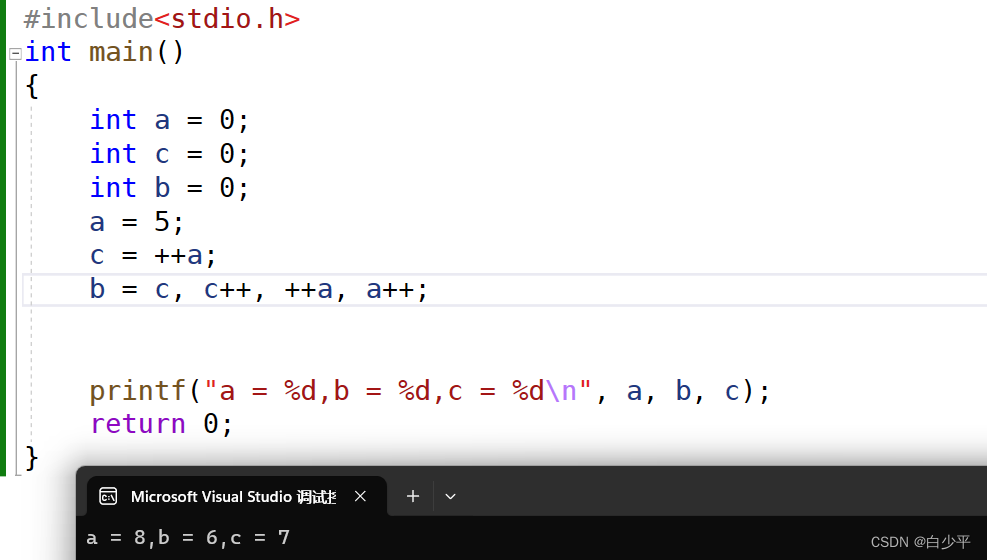
b = ++c, c++, ++a, a++;//b = 7,c = 8,a = 8// b = ++c是一个整体,注意区分逗号表达式
b += a++ + c;//b = 8+8+7 = 23
//b += ++a + c;//b=9+8+7 = 24
printf("a = %d,b = %d,c = %d\n", a, b, c);
return 0;
}注意:b += a++ + c;先计算b = a+c+b再计算a+1

注意:这样就是执行了逗号表达式:
#include<stdio.h>
int main()
{
int a = 0;
int c = 0;
int b = 0;
a = 5;
c = ++a;
b = (c, c++, ++a, a++);
printf("a = %d,b = %d,c = %d\n", a, b, c);
return 0;
}这样b就等于最后表达式的值a,然后a再自增,所以得到如下结果:
a = 8,b = 7,c = 7
去掉括号后,c就会直接被赋值为c,而本来c=6
1.2 二进制0和1
1)统计二进制中1的个数
注意://1000 0000 0000 0000 0000 0000 0000 0001 - 补码
//1111 1111 1111 1111 1111 1111 1111 1110 - 反码
//1111 1111 1111 1111 1111 1111 1111 1111 - 原码
//无符号会被认为是上述1的原码没有符号位
int count_number_1(unsigned int n)//这样写,那我就认为我传过来的是无符号位的
1111 1111 1111 1111 1111 1111 1111 1111
{
int count = 0;
int i = 0;
for (i = 0; i < 32; i++)
{
if (((n >> i) & 1 ) == 1)
{
count++;
}
}
return count;
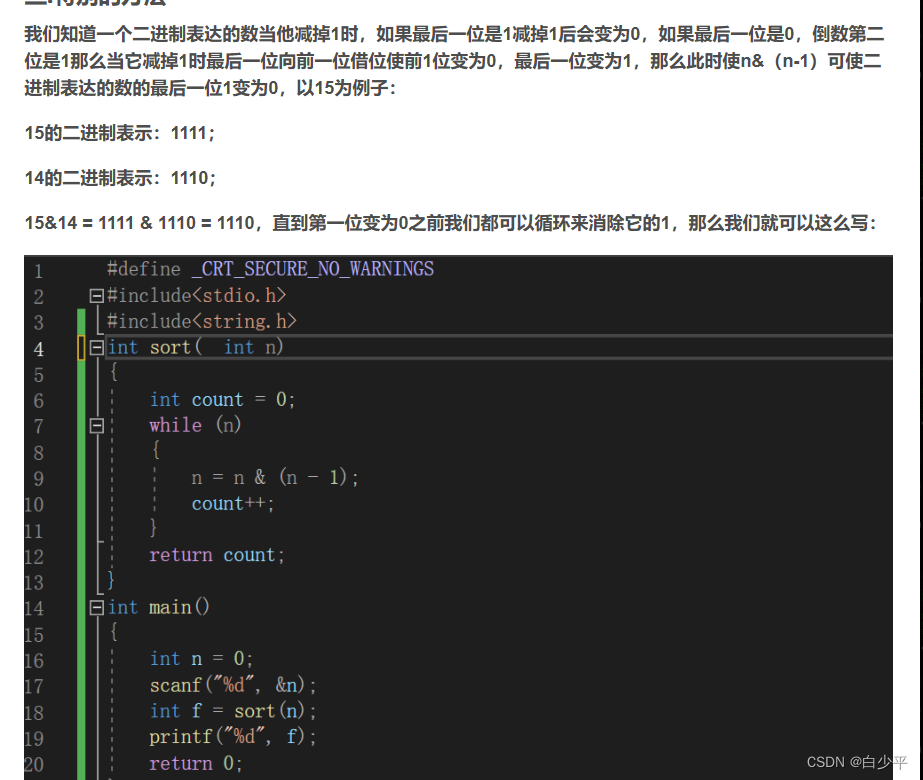
} 异或的方法:相同为0,不同为1
m = m&(m-1)可以得到bit位中1的个数
//001111m
//001110m-1
//001110m'
//001101m'-1
//001100m''
//001011m''-1
//001000m'''
//000111m'''-1
//000000m''''
//进行了4次m&(m-1),4个1
2)求两个数的二进制中不同位的个数
VS常见错误之一:LNK1168无法打开进行写入-CSDN博客![]() https://blog.csdn.net/ymxyld/article/details/125052464
https://blog.csdn.net/ymxyld/article/details/125052464
//异或,相同为0,相异为1
#include<stdio.h>
count_difbit(int a, int b)
{
int count = 0;
int temp = a ^ b;//不同的bit位都是1,找1的个数即可
while(temp)
{
temp = temp & (temp - 1);
count++;
}
return count;
}
int main()
{
int m = 1999;
int n = 2299;
int ret = count_difbit(m, n);
printf("%d\n", ret);
}//15 7
//00000000 00000000 00001111 -15
//正数原码补码反码相同,则15与7不同个数为1
//00000000 00000000 00000111 -7
#include<stdio.h>
int count_difbit(int a, int b)
{
int count = 0;
int i = 0;
for (i = 0; i < 32; i++)
{
if ((a & 1) != (b & 1))
{
count++;
}
a >>= 1;
b >>= 1;
}
return count;
}
//-5
//10000000 00000000 00000101
//11111111 11111111 11111010
//11111111 11111111 11111011
//-1
//10000000 00000000 00000001
//11111111 11111111 11111110
//11111111 11111111 11111111
int main()
{
int m = 0;
int n = 0;
scanf("%d %d", &m, &n);
int ret = 0;
ret = count_difbit(m,n);
printf("%d\n", ret);
return 0;
}1.3 判断元音辅音字母
getchar();的作用:
从标准输入流只读取一个字符(包括空格、回车、tab),读到回车符('\n')时退出,
键盘输入的字符都存到缓冲区内,一旦键入回车,getchar就进入缓冲区读取字符,
一次只返回第一个字符作为getchar函数的值,
如果有循环或足够多的getchar语句,就会依次读出缓冲区内的所有字符直到'\n'.
要理解这一点,之所以你输入的一系列字符被依次读出来,
是因为循环的作用使得反复利用getchar在缓冲区里读取字符,
而不是getchar可以读取多个字符,事实上getchar每次只能读取一个字符.
如果需要取消'\n'的影响,可以用getchar()来清除,
如:while((c=getchar())!='\n'),这里getchar();只是取得了'\n'
但是并没有赋给任何字符变量,所以不会有影响,相当于清除了这个字符。#include<stdio.h>
int main()
{
char v[] = { 'A','a','E','e','I','i','O','o','U','u' };
char ch = 0;
while (EOF != scanf("%c", &ch))
{
getchar();
int i = 0;
for(i = 0;i<10;i++)
{
if (ch == v[i])
{
printf("vov\n");
break;
}
}
if (i == 10)
{
printf("consonat\n");
}
}
return 0;
}注意:这样会错误,如果不用getchar

1.4 以下代码在VS环境下运行结果是?
i和arr是局部变量,放在栈区上,栈区上内存的使用习惯是先使用高地址处的空间,再使用低地址处的空间,(因为栈的特点是后进先出)
数组随着下标的增长,地址是由低到高变化,如果i和arr之间的空间适合的话,就有可能使用的arr数组向后越界就访问到i造成循环变量i的改变,最终死循环
&i:栈区上内存的使用习惯是先使用高地址处的空间,再使用低地址处的空间,i在高地址
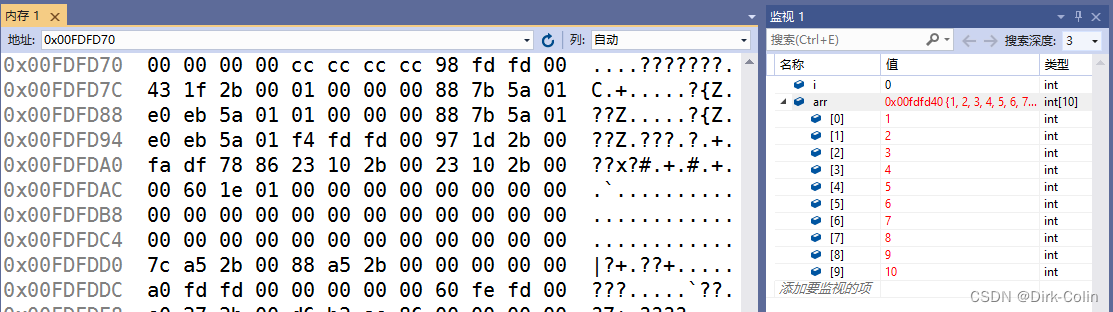
从下图可以看出arr的地址和i的地址。
&arr:数组随着下标的增长,地址是由低到高变化
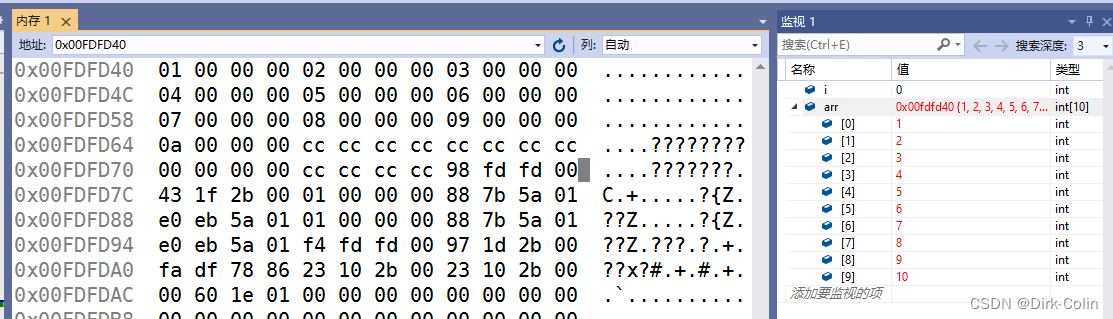
当i>9之后就越界了,出现了arr[10]。
 当i = 12,i++之后i变成了0,因为刚好覆盖了!
当i = 12,i++之后i变成了0,因为刚好覆盖了!
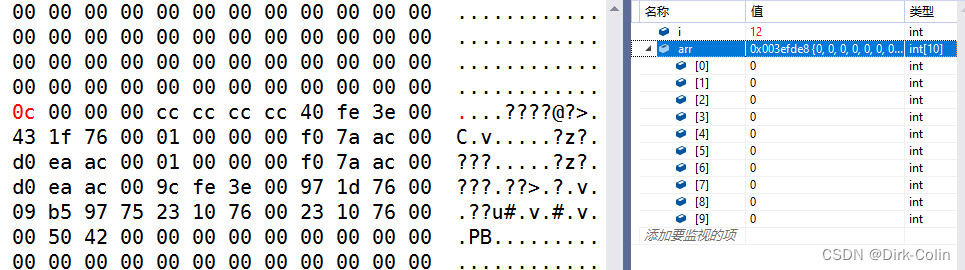

vcc6.0 - i和arr是连续的
gcc - i和arr之间有一个空间
如果将debug变成delease不会报错,他会让i到低地址去,但是这种优化是无差别的
#include<stdio.h>
int main()
{
int i = 0;
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
//for (i = 0; i <= 11; i++)//越界
for (i = 0; i <= 12; i++)//死循环
{
arr[i] = 0;//ctrl+f自动对齐操作快捷键
printf("hehe\n");
}
return 0;
}
1.5 模拟实现strcpy
注意:如何让代码更美观?参考以下代码:
#include<stdio.h>
#include<assert.h>
char* my_strcpy(char* dst,const char* src)
{
assert(dst && src);
char* ret = dst;
while (*dst++ = *src++);
//当src++到\0后,赋值给dst,解引用得到\0,ascii码值就是0,跳出循环
return ret;
}
int main()
{
char arr1[20] = {0};
char arr2[] = "hello";
printf("%s\n", my_strcpy(arr1, arr2));
return 0;
}1.6 1-1在计算机中的计算
1.内存中以补码形式存放 2.只有加法1+(-1)3.把最高位丢了
0000 0000 0000 0000 0000 0000 0000 0001 - 正数的补码反码原码一样 - 1的补码
1000 0000 0000 0000 0000 0000 0000 0001 - -1的原码
1111 1111 1111 1111 1111 1111 1111 1110
1111 1111 1111 1111 1111 1111 1111 1111 - -1的补码
0000 0000 0000 0000 0000 0000 0000 0001 - 1的补码
10000 0000 0000 0000 0000 0000 0000 0000 - 1+(-1),超出了32位,规定超出位丢弃
0000 0000 0000 0000 0000 0000 0000 0000 - 0的补码反码原码一致1.7 大小端字节序
小端模式优点:
内存的低地址处存放低字节,所以在强制转换数据时不需要调整字节的内容(注解:比如把int的4字节强制转换成short的2字节时,就直接把int数据存储的前两个字节给short就行,因为其前两个字节刚好就是最低的两个字节,符合转换逻辑);
大端模式优点:符号位在所表示的数据的内存的第一个字节中,便于快速判断数据的正负和大小
方法一:
以下方法是常见的错误方法,因为这样,已经变化了原本的a,从int变成了char,发生了类型转换。
#include<stdio.h>
int check_smallorbig(int n)
{
char m = (char)n;
return m;
}
int main()
{
int a = 1;//0x 00 00 00 01
//01是低字节,低字节存放在低地址为小端
int ret = check_smallorbig(a);
if (ret == 1)
{
printf("小端\n");
}
else
{
printf("大端\n");
}
return 0;
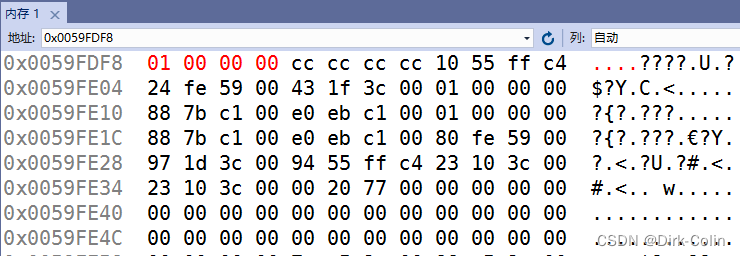
}&a是int*类型,但是这样得到的是4个字节,但是我只想得到一个字节,故强制类型转换成char*,p还是指向的a,p存放的还是a的地址,只是访问的是第一个字节,所以应该用如下的方法才正确。
#include<stdio.h>
int main()
{
int a = 1;
char* p = (char*)&a;//return *((char*)&a);
if (*p == 1)
{
printf("xiaoduan\n");
}
else
{
printf("shabi\n");
}
return 0;
}

方法二:
结构体和共用体的区别在于:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
先看一段代码:
https://blog.csdn.net/m0_57180439/article/details/120417270
#include<stdio.h>
union Un//联合类型的声明,union是联合体关键字
{
char c;//1字节
int i;//4字节
};
int main()
{
union Un u = {0};
printf("%d\n", sizeof(u));
printf("%p\n", &u);
printf("%p\n", &(u.c));//u.c表示联合体的成员c,该引用方法类似结构体
printf("%p\n", &(u.i));
}

由sizeof(u)我们知道这个联合体总计占4个字节,而联合体成员i是int类型的,它占了4个字节,另外一个c是char类型占了1个字节,两个一起占了4个字节。说明c和i必然有一处是共用一块空间的,再者有u本身和它的两个成员是一个地址如上图003EFA80,说明首地址是重合的,简易示图如下:

可以再看这一段C语言共用体(C语言union用法)详解 (biancheng.net)

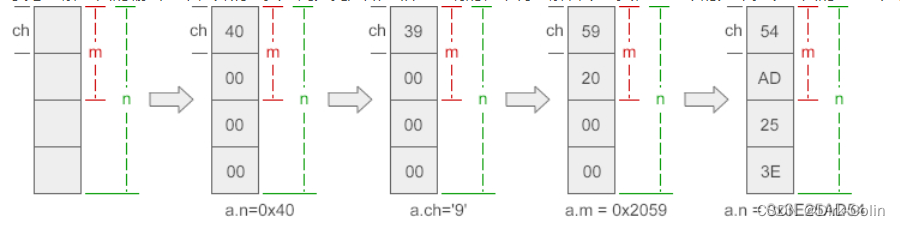
int check_sys()
{
union
{
int i;
char c;
}un;
un.i = 1;
return un.c;
} return un.c就是返回第一个字节,我们知道vs是小端,低字节存放在低地址,那么返回1就说明小端存储模式。
return un.c就是返回第一个字节,我们知道vs是小端,低字节存放在低地址,那么返回1就说明小端存储模式。
1.8 整形提升
1.8.1 整形提升的陷阱
以下代码的运行结果?
#include <stdio.h>
int main()
{
char a = -1;
//1000 0000 0000 0000 0000 0000 0000 0001
//1111 1111 1111 1111 1111 1111 1111 1110
//1111 1111 1111 1111 1111 1111 1111 1111
//1111 1111 - a - 放在内存中
signed char b = -1;
unsigned char c = -1;
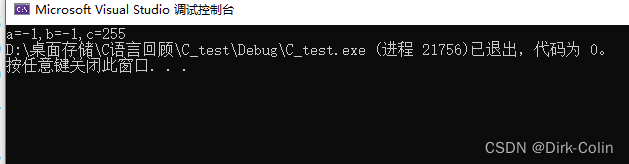
printf("a=%d,b=%d,c=%d", a, b, c);
return 0;
}注意:
打印的时候,计算机存的是补码,但是我们打印出来的是十进制,我们得把补码转成原码,然后将补码转成原码,然后把原码转成十进制数,得到的结果才和打印出来的十进制数一致。
打印的时候才考虑abc的类型
a变成%d打印,char->int, 发生整形提升
1111 1111被认为符号位是1,所以高位补1
1111 1111 1111 1111 1111 1111 1111 1111 - 整形提升后的补码
但是我们打印出来的是十进制,我们得把补码转成原码,
所以将整形提升后的补码转换成原码:
1000 0000 0000 0000 0000 0000 0000 0000 - a=-1的反码
1000 0000 0000 0000 0000 0000 0000 0001 - a=-1的原码
然后把原码转成十进制数,打印出来:-1
signed char 同 char
而对于unsigned char c:
0000 0000 0000 0000 0000 0000 1111 1111 - 无符号,高位补0
原码反码补码相同 - 》然后把原码转成十进制数,打印出来:255
1.8.2 无符号整形打印
a的补码是1000 0000
但是先要进行整形提升变成int类型,这样就需要高位补1,因为现在认为1是符号位,所以补1,变成: 1111 1111 1111 1111 1111 1111 1000 0000
而我们打印又是以%u无符号打印的,所以直接源码反码补码相同,即认为没有符号位了,直接打印出他的十进制数即4294967168
#include <stdio.h>
int main()
{
char a = -128;
printf("%u\n", a);
return 0;
} 1111 1111 1111 1111 1111 1111 1000 0000
1000 0000(a)
内存中存放的样子
要打印,发现a是char类型,是signed char
而打印的类型是unsigned int
故从char 到 int,进行整形提升是补符号位1
因为认为符号位是1,从1000 0000
提升后变成:
1111 1111 1111 1111 1111 1111 1000 0000
上值又被认为是无符号的,所以补码反码原码都是本身
原码再变成二进制:

1.8.3 补码相加原则
#include<stdio.h>
int main()
{
int i = -20;
//10000000 00000000 00000000 00010100
//11111111 11111111 11111111 11101011
//11111111 11111111 11111111 11101100
unsigned int j = 10;
//00000000 00000000 00000000 00001010
printf("%d\n", i + j);
//11111111 11111111 11111111 11110110 - 补码相加
//10000000 00000000 00000000 00001001
//10000000 00000000 00000000 00001010 - -10
return 0;
}1.8.4 死循环--无符号的陷阱
#include<stdio.h>
#include<windows.h>
int main()
{
unsigned int i;
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);
Sleep(1000);
}
return 0;
}1.8.5 无符号字符型数组的长度
a[i]的范围在-128到+127之间,当i=127的时候,a[127] = -128,i继续加1,a[128] 变成127
#include<stdio.h>
int main()
{
char a[1000];
//有符号char
//-128 —— +127
//1111 1111
//1000 0000是无法计算的,直接解析为-128
//当unsigned char为0-255
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));//255
return 0;
}2.结构体
结构体传参传地址
#include<stdio.h>
typedef struct S
{
int arr[1000];
float f;
char ch[100];
}S;
void print(S* ps)
{
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ",ps->arr[i]);
}
printf("\n");
printf("%f\n",ps->f);
printf("%s\n",ps->ch);
}
int main()
{
S s = { {1,2,3,4,5,6,7,8,9,10},5.5f,"hello,world"};
print(&s);
return 0;
}【C语言进阶篇】看完这篇结构体文章,我向数据结构又进了一大步!(结构体进阶详解)-腾讯云开发者社区-腾讯云 (tencent.com) https://cloud.tencent.com/developer/article/2374086
https://cloud.tencent.com/developer/article/2374086
- 函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。
- 如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。
- 所以结构体传参的时候一定要传地址!
🔥 由于函数在传递参数时,如果我们传的是实参,那么形参将是实参的一份临时拷贝。如果我们传过去的结构体很大,那么形参也要开辟相同大小的空间就会照成空间的浪费!
总结
C语言复习















 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









