







官方中文文档: https://mybatis.org/mybatis-3/zh_CN/
1. 快速入门
1.1 导入依赖
<!-- mybatis 依赖 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.14</version>
</dependency>
<!-- mysql驱动 mybatis底层依赖jdbc驱动实现, 本次不需要导入连接池, mybatis自带 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.10.1</version>
<scope>test</scope>
</dependency>
1.2 创建数据库和实体类
实体类 Employee
public class Employee {
private Integer empId;
private String empName;
private Double empSalary;
// getter and setter and toString
}
数据库 mybatis-example
记住创建数据库的时候字符集选择 uft8mb4 排序规则选择 utf8mb4_general_ci 如果要选引擎, 使用 InnoDB 即可

SQL 语句就是
CREATE TABLE `t_emp`{
emp_id INT AUTO_INCREMENT,
emp_name CHAR(100),
emp_salary DOUBLE(10,5),
PRIMARY_KEY(emp_id)
};
INSERT INTO `t_emp` VALUES (1, 'tom', 200.33000);
INSERT INTO `t_emp` VALUES (2, 'jerry', 666.66000);
INSERT INTO `t_emp` VALUES (3, 'andy', 777.77000);
1.3 准备Mapper接口和Mapper.xml文件
Mybatis出现前如何操作数据库的呢?(Spring中讲过)
- xxxDao 接口, 规定方法
- xxxDaoImpl 实现类, 方法的具体实现(数据库的动作, 使用
jdbcTemplate)
Mybatis 如何使用
- xxxMapper 接口, 规定方法
- xxxMapper.xml 写接口对应方法的语句
🐇 解释:xml文件需要放在 resources 目录下, 因为放在 src/main/java 目录下, maven 不会帮忙打包到 target 目录下, 放在 resources 目录下会给打包
mapper 接口:EmployeeMapper
public interface EmployeeMapper {
Employee queryById(Integer id);
int deleteById(Integer id);
}
mapper.xml 文件:EmployeeMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- namespace = mapper对应接口的全限定符 -->
<mapper namespace="com.lh.mapper.EmployeeMapper">
<!-- sql 语句 -->
<select id="queryById" resultType="com.lh.pojo.Employee">
select emp_id empId, emp_name empName, emp_salary empSalary from t_emp where emp_id = #{id}
</select>
<delete id="deleteById">
delete from t_emp where emp_id = #{id}
</delete>
</mapper>
注意点:
-
习惯上 mapper 接口文件与配置文件名称一样(在SpringBoot中默认配置就是这种), EmployeeMapper --> EmployeeMapper.xml, 也可以不一样, 需要在 mapper 配置文件中的
namespace中指定对应接口 -
接口中定义的方法不应该重载, 因为 mybatis 不支持。因为 mybatis 识别方法是通过方法名, 即
id指定, 对于方法名相同, 参数不同的方法, 如如下形式Employee queryById(Integer id); Employee queryById();在
<select id="queryById">中就无法识别到绑定的是哪个方法, 就会报错 -
delete, update, insert 操作的返回类型都为 int 类型, 代表操作成功的行数!
mapper 接口和 mapper.xml 文件仅仅是用来写了 sql 语句, 但目前还没有连接数据库以及还不知道哪些xml文件需要作为数据库操作的文件去被识别等等, 所以还需要一个配置文件
1.4 准备 MyBatis 配置文件
mybatis 框架配置文件:数据库连接信息, 性能配置, mapper.xml 配置等
习惯上命名为 mybatis-config.xml, 不强制嗷。将来整合 Spring 之后, 这个配置文件可以省略, 简单了解即可
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--
environments:配置多个连接数据库的环境
属性:
default:设置默认使用的环境的id,其值为environment中id的某一个
-->
<environments default="development">
<!-- environment 表示配置 mybatis 的一个具体环境 -->
<environment id="development">
<!-- mybatis的内置的事务管理器 -->
<transactionManager type="JDBC"/>
<!-- 配置数据源 -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis-example"/>
<property name="username" value="root"/>
<property name="password" value="mysql"/>
</dataSource>
</environment>
</environments>
<!-- Mapper注册: 指定Mybatis映射文件的具体位置 -->
<mappers>
<!--
mapper标签: 配置一个具体的 mapper 映射文件
resource属性: 指定mapper映射文件的实际存储位置, 需要使用一个类路径根目录为基准的相对路径
对于 maven 工程的目录结构来说, resources 目录下的内容会直接放入类路径, 所以我们可以以 resource 目录为基准
-->
<mapper resource="mappers/EmployeeMapper.xml"/> <!-- 可以写多个 -->
</mappers>
</configuration>
- 此处也可以使用
<properties resource="jdbc.properties"/>来引入properties文件, 这样就可以通过${属性名}方式来访问属性
1.5 测试
配置文件等都创建好了, 但它们也都只是文件, 还没有被使用, 我们需要去使这些文件生效
(这里并没有使用到任何注解, 不结合Spring使用起来会很麻烦, 后续会讲, 这里只需要简单了解即可)
public class MybatisTest {
@Test
public void test_01() throws IOException {
// 1. 读取外部配置文件 (mybatis-config.xml)
InputStream ips = Resources.getResourceAsStream("mybatis-config.xml");
// 2. 根据配置文件创建 sqlSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(ips);
// 3. 根据 sqlSessionFactory 创建 sqlSession (每次业务创建一个, 用完就释放)
SqlSession sqlSession = sqlSessionFactory.openSession();
// 4. 获取接口的代理对象 (代理技术) 调用代理对象的方法, 就会查找 mapper 接口的方法
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
Employee employee = mapper.queryById(1);
System.out.println("employee = " + employee);
// 5. 提交事务(不是查询就要提交, 不提交这里的增删改不会生效)和释放资源
sqlSession.commit(); // 这里是查询, 可以不写提交
sqlSession.close();
}
}
解释:
先读取配置文件, 然后根据文件创建 sqlSessionFactory 会话工厂, 由工厂开启一次会话, 在会话中指定要代理的代理对象, 这样我们使用 mapper. 调用方法时, 调用的是接口中声明的方法(接口不声明就没有), 然后去找 xml 文件中对应的 sql 语句并执行, 找不到会报错, 所以这里mapper接口和mapper.xml文件的对应关系要处理好。最后关闭会话即可, 如果是非查询操作, 需要提交事务后再关闭。
❓ 为什么要手动提交事务?
- 因为可能操作多次, 比如两次删除, 一个修改等, 不知道你什么时候操作完
- 可能需要事务回滚, 这里还没有讲到, 如果发现在多个操作中间某个操作后需要回滚就直接回滚就行, 对数据库没有造成修改, 所以不能默认设置为操作一步就提交一次, 就没办法回滚了, 所以需要手动提交
- 如果不提交, 那么就等于没进行增删改操作, 相当于口头说说, 没有进行真正的执行。
输出结果:employee = Employee{empId=1, empName='tom', empSalary=200.33}
目录结构:
1.6 原理介绍
mybatis 的前身叫 ibatis, 有 1.x, 2.x 版本, 后来对 ibatis 进行升级到 3.x 版本, 并改名为 mybatis, ibatis 和 mybatis 都各自有一套自己的数据库CRUD方法。 mybatis 的数据库CRUD是对ibatis的封装和优化。
先看一下利用 ibatis 如何操作数据库, 假设数据库有 student 表, 有 id 和 name 字段, 并且我们已经创建好了实体类
ibatis 中不用定义 mapper 接口, 直接写 mapper.xml 文件即可
StudentMapper.xml
约束不用变
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
ibatis 方式进行数据库操作
-->
<mapper namespace="two.dog">
<select id="kkk" resultType="com.lh.pojo.Student">
select * from student where s_id = #{id}
</select>
</mapper>
说明:
namespace没有任何要求, 随便声明字符串就可以- 标签中的
id也是随便写就可以, 注意不重复就行
mybatis配置文件
一样的配置, 将 StudentMapper.xml 引入即可
测试
/**
* 使用 ibatis 方式操作数据库
*/
@Test
public void test_02() throws IOException {
// 1. 读取外部配置文件 (mybatis-config.xml)
InputStream ips = Resources.getResourceAsStream("mybatis-config.xml");
// 2. 根据配置文件创建 sqlSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(ips);
// 3. 根据 sqlSessionFactory 创建 sqlSession (每次业务创建一个, 用完就释放)
SqlSession sqlSession = sqlSessionFactory.openSession();
// 4. sqlSession 提供的 crud 方法进行数据库查询
Student student = sqlSession.selectOne("two.dog.kkk", 1);
// 5. 提交事务(不是查询就要提交, 不提交这里的增删改不会生效)和释放资源
sqlSession.commit(); // 这里是查询, 可以不写提交
sqlSession.close();
}
同 mybatis 步骤一样, 只有第四步不同, 因为 ibatis 操作没有使用接口, 所以代理模式使用不上。
方式:select | insert | delete | update
参数1:字符串, 写 sql 标签对应的标识, 直接写 id(kkk) 或者 namespace.id(two.dog.kkk) 即可
参数2:Object 执行sql语句需要传入的参数
整体流程如下:
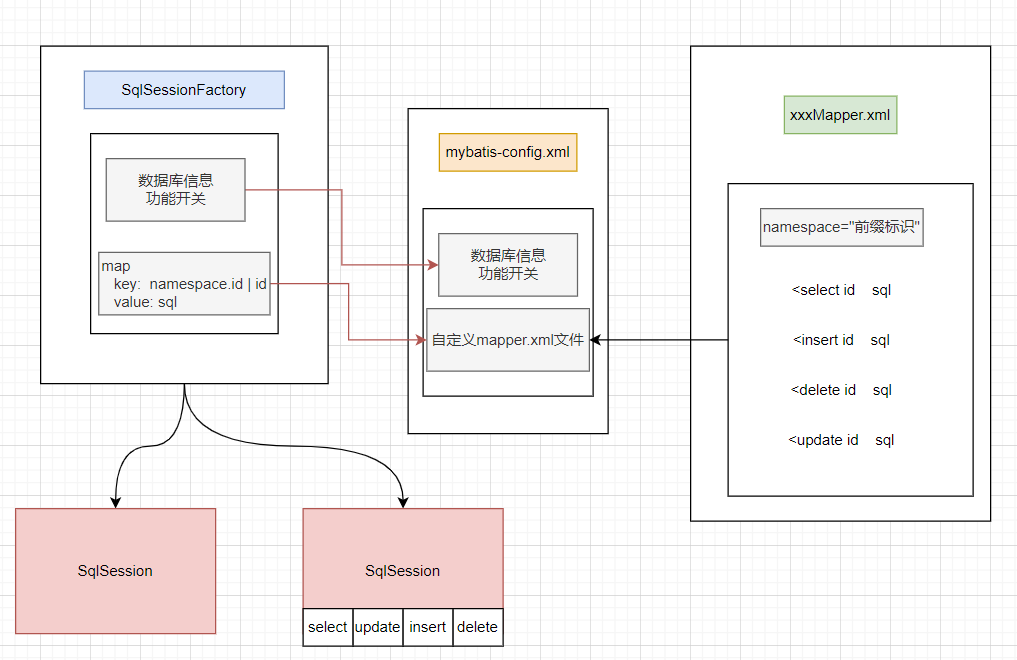
xxxMapper.xml 中写 sql 语句, 并起好标识, 在 mybatis-config.xml 文件中配置好, 并将自定义的 mapper.xml 文件引入, 在根据配置文件创建 SqlSessionFactory 工厂时, 会将配置文件缓存进去, 并将 id 与 sql 语句存入。然后在创建SqlSession 后根据 select | update | insert | delete 方法去 SqlSessionFactory 中查找这个 id, 如果存在则执行 sql 语句并将结果返回。
缺点:
-
sql 语句标签对应的
id和namespace为字符串标识, 容器书写错误 -
参数传递时为 Object 类型, 只能传递一个, 如果是多个参数, 通常使用 Map 整合
-
返回值, 我们在 sql 语句中规定的是 Student, 但实际你写任意类型在此处都不会出现错误提示(运行后也没有)
Employee student = sqlSession.selectOne("two.dog.kkk", 1); Student student = sqlSession.selectOne("two.dog.kkk", 1); // 都不会报错 System.out.println("student = " + student); // 运行结果都为 student = null; 很奇怪
那么 mybatis 优化了什么呢, 为什么要创建接口呢?
我们对比一下 mybatis 和 ibatis, mybatis 多了接口, 并且规定 namespace 为接口名, id 为方法名。
// 4. 获取接口的代理对象 (代理技术) 调用代理对象的方法, 就会查找 mapper 接口的方法
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class); // *
Employee employee = mapper.queryById(1); // **
System.out.println("employee = " + employee);
这里的 getMapper 方法实际上会生成代理对象, 使用的技术就是 jdk动态代理, 这里一共有两个语句
* 语句将为 EmployeeMapper 生成代理对象, 将该类的全类路径获取并获取方法名拼接成一个字符串, 通过 ibatis 调用对应的方法, 这里只是进行生成代理对象和字符串拼接, 和 XML 文件没有关系。
** 是真正要执行的, 当它去执行时, 首先拿到了标识 全类路径+方法名, 然后去 XML 文件中寻找这个标识并执行。
我们据此也可以看出为什么接口中的方法不能重载, 正是因为 ibatis 中 id 不能重复导致的。
2. 基本使用
2.1 向SQL语句传参
2.1.1 mybatis 日志输出配置
这里引入比较简单的控制台输出 STDOUT_LOGGING
在 mybatis-config.xml 中加入
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
2.1.2 #{} 与 ${}
select emp_id empId, emp_name empName, emp_salary empSalary from t_emp where emp_id = #{id} // 假设传入的值为1
#{key}:占位符 + 赋值, 等价于语句先变为 emp_id = ?, 然后进行赋值 1。
${key}:做字符串拼接, 举例, emp_id = 1
这里两个实际上都可以使查询正常运行, 但是运行原理不同。
#{key}--> 实际执行的语句先变为 emp_id = ? 然后传入值

${key}--> 实际执行的语句直接变为 emp_id = 1

🐯 这里推荐使用 #{key}, 因为这样可以防止 注入攻击 的问题。
因为占位符 ? 只能替代值的位置, 只能传入值。而如果使用 ${key}, 会做字符串拼接, 比如我传入 1 or emp_name = 二狗, 拼接后就是 emp_id = 1 or emp_name = 二狗, 那么根据名字就可以查到二狗的信息, 而不仅仅根据 id, 二狗的信息就会暴露。
🐯 ${} 的使用场景 --> 表名, 列名, sql 关键字等是动态的可以使用
因为占位符 ? 只能传递值, 即某个列属性值为多少, 可以用这个, 但是列名如果是动态的, 不能用这个进行传递。
${} 可以做到。比如某个函数 xxx(columnName, columnValue) 查找某个列名为 columnName 且值为 columnValue 的一个函数。sql 语句可以如下
select emp_id empId, emp_name empName, emp_salary empSalary from t_emp where ${cloumnName} = #{columnValue} // 假设传入的值为1
调用时可以写 xxx("emp_id", 1) 进行调用, 当然也有注入攻击的风险。
2.2 数据输入
Mybatis 总体机制是 SQL指令+SQL参数 由Mybatis 组装成完整的语句进行数据库操作然后输出数据。
2.2.1 单个简单类型参数
包括基本数据类型 int, byte, short, double..., 基本数据的包装类型 Integer, Character, Double..., 字符串类型 String
当只有一个简单类型参数时, key 的名字可以随便写, 因为找参数直接就确定是这一个, 不会根据名字去找了。但是推荐按使用参数名。
比如定义了两个接口方法:
int deleteById(Integer id);
List<Employee> queryBySalary(Double salary);
XML 定义SQL语句
<delete id="deleteById">
delete from t_emp where emp_id = #{id}
</delete>
<select id="queryBySalary" resultType="com.lh.pojo.Employee">
select emp_id empId, emp_name empName, emp_salary empSalary
from t_emp where emp_salary = #{二狗子}
</select>
delete语句不用写 resultType, 因为它固定为int类型,updateinsert也是嗷!!select语句也可以正常执行, 程序执行不会报错。不过不推荐写二狗子, 推荐写与参数名相同的 salary。
2.2.2 单个实体对象传入
员工属性有 emp_id, emp_name, emp_salary。
演示插入员工
int insertEmp(Employee employee);
SQL语句, key = 属性名 即可, 不要写 employee.empName 这种。
<insert id="insertEmp">
insert into t_emp (emp_name, emp_salary) values (#{empName}, #{empSalary})
</insert>
那究竟是怎么根据 key 来找的呢?
我们试一下, 就写 employee.empName 试试
insert into t_emp (emp_name, emp_salary) values (#{employee.empName}, #{empSalary})
看看报错就知道了, There is no getter for property named ‘employee’ in ‘class com.lh.pojo.Employee’
- 我们写的是
employee.empName, 他说没找到employee, 说明什么?它在找的时候, 如果遇到., 就会将之后的内容忽略掉。 - 它是通过
get方法来获取属性值, 而不是属性名来获取!!!注意嗷 (但是一般我们的 get, set 方法定义都是固定的, 只要不自己改就没问题), 你比如empName的 get 方法名改为getEmpN, 那么我读取属性应该写#{empN}。
2.2.3 多个简单类型传入
场景:根据员工名字和工资查询员工
List<Employee> queryByNameAndSalary(String name, Double salary);
SQL 语句
<select id="queryByNameAndSalary" resultType="com.lh.pojo.Employee">
select emp_id empId, emp_name empName, emp_salary empSalary
from t_emp where emp_name = #{name} and emp_salary = #{salary}
</select>
试一下对不对
Parameter ‘name’ not found. Available parameters are [arg1, arg0, param1, param2]
!!单个简单类型参数的时候, 名字随便起都可以, 多个简单类型参数的时候, key = 参数名 都不对
🐇 解决方案1:使用 arg0, arg1 或 param1, param2
这是 mybatis 提供的默认机制, 即按照参数顺序排的, arg 和 param 没什么区别, 只是 arg 从 0 开始, param 从 1 开始。
where emp_name = #{arg0} and emp_salary = #{arg1}
where emp_name = #{param1} and emp_salary = #{param2}
where emp_name = #{arg0} and emp_salary = #{param2}
arg 和 param 混着用也是可以的
🐇 解决方案2:在接口参数上使用 @Param 注解
// @Param(名称) 名称可以任意指定, abc 什么都可以, 但一般习惯和参数名相同
List<Employee> queryByNameAndSalary(@Param("name") String name,@Param("salary") Double salary);
这个时候, 我们再使用这个语句就没有问题了
<select id="queryByNameAndSalary" resultType="com.lh.pojo.Employee">
select emp_id empId, emp_name empName, emp_salary empSalary
from t_emp where emp_name = #{name} and emp_salary = #{salary}
</select>
小细节:谁使用了 @Param , 谁的 arg 就不能用了, 但是它的 param 还能用。
比如这里面两个参数, 我只给 name 使用了 @Param, salary 没用注解, 那我的 name 可以使用 [name, param1] 这两种, 而 salary 可以使用 [arg1, param2]。
2.2.4 Map 类型参数
接口方法定义
List<Employee> queryEmpByMap(Map<String, Object> data);
SQL语句:key 的值 = map 中的 key 值
<select id="queryEmpByMap" resultType="com.lh.pojo.Employee">
select emp_id empId, emp_name empName, emp_salary empSalary
from t_emp where emp_name = #{name} and emp_salary = #{salary}
</select>
测试程序
HashMap<String, Object> map = new HashMap<>();
map.put("name", "二狗子");
map.put("salary", 222.22);
List<Employee> employees = mapper.queryEmpByMap(map);
可以成功查询嗷!
🐯 那么有一个小问题, 如果指定的 key 值在 map 中没有呢?
比如我修改 SQL 语句为 where emp_name = #{n} and emp_salary = #{salary}, 测试程序还是不变。
结果还是可以正常执行!!

查不到 map 中的 name, 就设置为 null。。。。。注意点嗷
2.3 数据输出
数据输出(即 resultType) 整体上有两种形式
- 增删改操作返回受影响的行数:直接使用 int 或 long 类型接收即可
- 查询操作需要指定查询的输出数据类型, 并且某些场景下, 需要实现主键数据回显 (插入成功后返回主键)
2.3.1 单个简单类型
对于 增删改操作在接口定义时, 返回值设为 int 或 long, 在 XML 配置时, 不用指定返回值 (因为根本就没提供 resultType 属性), 下面主要对查询操作进行演示
接口方法定义:
String queryNameById(Integer id);
Double querySalaryById(Integer id);
SQL语句:
<select id="queryNameById" resultType="java.lang.String">
select emp_name empName from t_emp where emp_id = #{id}
</select>
<select id="querySalaryById" resultType="_double">
select emp_salary empSalary from t_emp where emp_id = #{id}
</select>
解释:
resultType 可以有两种形式的写法 1. 类的全限定符号 2. 别名简称
resultType可以使用全限定符号, 所以写java.lang.String- 使用别名简称, 如
java.lang.Double可以简写为double,_double
mybatis 提供了72种默认的别名, 大致规则如下, 在顶部官方链接中可以看
基本数据类型 int, double -> _int, _double
包装数据类型 Integer, Double -> int|integer, double
集合容器类型 Map, List, HashMap -> map, list, hashmap
另外返回值类型为 double 或 Double 时, 由于 Java 的自动拆箱和封箱机制, 所以 double, _double 也不会出错。
如上面的代码中, 返回值类型是 Double, 但是我 resultType = "_double", 即基本类型的别名, 也不会出错。
2.3.2 别名
在 mybatis-config.xml 中可以定义别名规则来自定义别名
如原来的XML配置中, 返回类型需要写全限定符号, 比较长, 我们就可以定义别名
<select id="queryById" resultType="com.lh.pojo.Employee">
...
</select>
在 mybatis-config.xml 配置文件中定义别名
<typeAliases>
<typeAlias type="com.lh.pojo.Employee" alias="dog"/>
</typeAliases>
如此, 我们在写返回类型的时候就可以写
<select id="queryById" resultType="dog">
...
</select>
不过使用 typeAliases 中的 typeAlias 的缺点是一次只能为一个类定义一个别名, 当需要定义的很多时, 就会很麻烦
所以可以使用另外一种设置方式, 批量将包下的类设置别名, 别名就是类的首字母改为小写后的形式, 如 com.lh.pojo.Employee 别名就是 employee
<typeAliases>
<package name="com.lh.pojo"/>
</typeAliases>
那么需求又来了, 我给这一整个包都起了别名, 其中一个我不想用这个别名, 我想单独对这一个特殊照顾一下, 起别名该怎么设置?
其实有两种方式, 一种是
<typeAliases>
<typeAlias type="com.lh.pojo.Employee" alias="dog"/>
<package name="com.lh.pojo"/>
</typeAliases>
这种方式下, 我返回类型写 employee 或者 dog 都不会错
另一种是在类上加上 @Alias 注解
@Alias("dog")
public class Employee {}
此时配置文件还是
<typeAliases>
<package name="com.lh.pojo"/>
</typeAliases>
这种情况下和第一种就不一样了, 这个时候返回类型只能写 dog, 写 employee 会报错, 说找不到 employee 这种类。
官网只介绍了第二种形式, 第一种是我自己试出来的😃
2.3.3 单个实体类型
在别名中已经包含了 resultType 如何设置 , 此处不介绍了
不过还有一个需要介绍的, 即数据库列名与实体类属性名的映射问题
前面在查询时我们都是这么写的
<select id="queryById" resultType="employee">
select emp_id empId, emp_name empName, emp_salary empSalary
from t_emp where emp_id = #{id}
</select>
要为列名起一个别名, 这个别名就会映射到 Java 的实体属性名, 实际上不是根据属性名, 而是通过调用 set 方法来, 比如这里我为 emp_name 设置的别名是 empName, 我的 Java 实体属性名实际是 empN, 而我的 set 方法为 setEmpName, 由于别名和 setEmpName 可以对应上, 所以 empN 属性可以被成功赋值, 而当我的 set 方法为 setEmpN 时, 由于不对应并不能成功赋值。
| 属性名 | set 方法名 | 别名 | 能否成功赋值 |
|---|---|---|---|
| empN | setEmpN | empN | 能 |
| empN | setEmpN | empName | 不能 |
| empN | setEmpName | empN | 不能 |
| empN | setEmpName | empName | 能 |
花里胡哨的没啥用, 不过知道是通过 set 方法来赋值的就行。
另外, 如此指定会很麻烦, 因为数据库命名规则是 emp_id, 而 Java 是 empId, 手动指定会很麻烦, 所以可以开启自动映射(不过还是要求数据库列名命名和Java实体类属性名仅仅是命名规则不同, 你不能列名是 emp_id, 属性名变为 id了, 这它不会帮你映射)。
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
开启后, 我们的SQL语句就不用这么麻烦了
<select id="queryById" resultType="employee">
select emp_id, emp_name, emp_salary
from t_emp where emp_id = #{id}
</select>
🅰️ 注意:上面所说的使用 get, set 获取和设置值等注意事项实际上都归结于没有规范操作, 如果我们都规范命名(实际开发中一定是这样), 很多细节是不需要注意到的, 比如我们可以认为是在 get 时写属性名即可, 不用注意需要根据 get 的命名来获取值, 在起别名时要根据 set 方法名来设置值等等, 我们直接简化操作, 开启自动映射就可以了。
2.3.4 map 数据类型
当没有实体类可以被用来接值的时候, 我们可以使用 map 来存放数据。
场景:查询公司中工资最高的员工及公司员工的平均工资
Map<String, Object> selectEmpNameAndMaxSalary();
SQL语句
<select id="selectEmpNameAndMaxSalary" resultType="map">
select emp_name 员工姓名,
emp_salary 员工工资,
(select avg(emp_salary) from t_emp) 部门平均工资
from t_emp where emp_salary = (select max(emp_salary) from t_emp)
</select>
输出
Map<String, Object> employee = mapper.selectEmpNameAndMaxSalary();
System.out.println("employee = " + employee);
// employee = {部门平均工资=417.84, 员工姓名=andy, 员工工资=777.77}
还有一种使用方法是指定 Map 的关键字, 如用员工的 id 作为关键字, 将查询对象作为值, 举例:查询所有员工, 接口方法定义, 由 List<Employee> --> Map<Integer, Object>
@MapKey("empId") // Employee 实体类的哪个属性作为 key
Map<Integer, Object> queryList();
mapper.xml
<!-- 返回类型不变 -->
<select id="queryList" resultType="employee">
select * from t_emp
</select>
查询结果:
{"1":{"empId":1,"empName":"二狗蛋","empSalary":200.33},"2":{"empId":2,"empName":"jerry","empSalary":666.66},"3":{"empId":3,"empName":"andy","empSalary":777.77},"4":{"empId":4,"empName":"二狗子","empSalary":222.22},"5":{"empId":5,"empName":"二狗子","empSalary":222.22},"6":{"empId":6,"empName":"二狗蛋","empSalary":222.0}}
2.3.5 list 数据类型
当查询数据为多条时, 只能使用集合, 否则抛出异常
场景:查询所有员工的姓名
List<String> queryNames();
SQL语句
<select id="queryNames" resultType="string">
select emp_name from t_emp;
</select>
当返回值是集合时, resultType 不需要指定集合类型, 只要指定里面的泛型即可!!
我们发现如下两种形式的定义它的的 resultType 都写 string
String queryNameById(Integer id);
List<String> queryNames();
解释:当查询到的数据是多条时, 会被封装到 List 中。
其实我们知道底层是 ibatis 实现的, 它是如何做的呢?ibatis 有两个查询方法, 一个是 selectOne, 一个是 selectList, 但是 selectOne 实际上还是调用的 selectList, 如果集合大小大于1会抛出异常。
@Override
public <T> T selectOne(String statement, Object parameter) {
// Popular vote was to return null on 0 results and throw exception on too many.
List<T> list = this.selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
}
if (list.size() > 1) {
throw new TooManyResultsException(
"Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
所以无论查一个数据还是多个数据, 底层都是会将数据封装到 list, 所以不需要我们指定类型为 list, 直接写泛型类型即可。
2.4 返回主键值
2.4.1 自增长主键回显
场景:当插入一条数据后, 由于主键是自增长类型, 插入后我想获取该数据的主键, 如何操作?
int insertEmp(Employee employee);
SQL语句
<insert id="insertEmp" useGeneratedKeys="true" keyColumn="emp_id" keyProperty="empId">
insert into t_emp (emp_name, emp_salary) values(#{empName}, #{empSalary})
</insert>
useGeneratedKeys = "true"开启获取自动增长的主键值keyColumn="emp_id"主键列的列名keyProperty="empId"接收主键列值的属性名
测试程序
InputStream resource = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resource);
// openSession(boolean autoCommit) 开启自动提交事务, 这样就不用在增删改操作后进行 sqlSession.commit();
SqlSession sqlSession = sqlSessionFactory.openSession(true);
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
// 要插入的对象
Employee employee = new Employee();
employee.setEmpName("二狗蛋");
employee.setEmpSalary(222d);
int rows = mapper.insertEmp(employee);
System.out.println("employee = " + employee);
// employee = Employee{empId=6, empName='二狗蛋', empSalary=222.0}
sqlSession.close();
这里要解释的地方有两个:
- 我们可以在
sqlSessionFactory.openSession()时传入一个参数true, 代表开启自动提交事务, 这样就不需要自己进行sqlSession.commit()手动提交事务 - 主键回显是什么?当我们插入后, 主键是在数据库中生成的, 而当我们插入后又想要这个主键值进行后续操作时, 我们就可以在 mapper.xml 中的
insert标签中配置需要主键回显, 如此, 我们传入的参数employee没有主键值, 但是当我们成功插入后, 它会帮我们把我们传入的employee的主键值进行赋值, 即将自增主键的值设置到实体类对象中, 如上, 设置为了6。
2.4.2 非自增长主键回显
已常见的 UUID 举例, UUID 在数据库中以64位字符串存放, 所以不能自增长, 下面先演示Java代码如何维护UUID
TeacherMapper 接口定义
public interface TeacherMapper {
int insertTeacher(Teacher teacher); // 插入
}
Teacher 实体类定义
public class Teacher {
private String tId;
private String tName;
// get, set and toString
}
TeacherMapper.xml
<insert id="insertTeacher">
insert into teacher (t_id, t_name) values(#{tId}, #{tName})
</insert>
测试
TeacherMapper mapper = sqlSession.getMapper(TeacherMapper.class);
// java.util 的 UUID 类
String uuid = UUID.randomUUID().toString().replace("-", "");
Teacher teacher = new Teacher();
teacher.settName("二狗子");
teacher.settId(uuid);
System.out.println(teacher);
int rows = mapper.insertTeacher(teacher);
UUID.randomUUID().toString() 生成UUID字符串, 中间有 - 分割, 改为 ""。
UUID是自己生成的, 想交给 mybatis 操作, 可以这么写 TeacherMapper.xml
<insert id="insertTeacher">
<selectKey order="BEFORE" resultType="string" keyProperty="tId">
select replace(UUID(),'-','');
</selectKey>
insert into teacher (t_id, t_name) values(#{tId}, #{tName})
</insert>
解释
selectKey用来在插入语句之前或之后生效order属性用来设置插入之前生效还是之后生效, 此处肯定是之前resultType用于生成返回值类型, 此处UUID是字符串keyProperty用来选择将哪个对象属性设置为该值select replace(UUID(),'-','');是SQL语法, 生成UUID并进行字符串替换
该语句会先运行 selectKey 中的语句, 并设置好 tId, 然后再执行插入语句, 如下图, 两次执行SQL语句
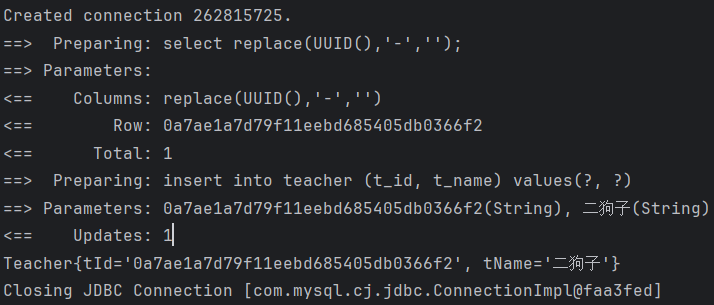
这样就实现了数据库自动生成主键类似的行为, 同时保持了 Java 代码的简洁。
🐇如果主键不止一个, 也是有办法的, 不过可能不常用, 去官网查吧。
测试
TeacherMapper mapper = sqlSession.getMapper(TeacherMapper.class);
Teacher teacher = new Teacher();
teacher.settName("二狗子");
int rows = mapper.insertTeacher(teacher);
System.out.println(teacher);
// Teacher{tId='0a7ae1a7d79f11eebd685405db0366f2', tName='二狗子'}
2.5 实体类属性和数据库字段的对应关系
实体类属性和数据库字段的对应我们已经学过两种了
我们还是用 teacher 这个例子, 数据库的字段为 t_id, t_name, 实体类的属性名为 tId, tName
如何进行对应, 这里提供三种方案。
方案1:在 select 语句中定义别名
<select id="queryById" resultType="teacher">
select t_id tId, t_name tName from teacher where t_id = #{id}
</select>
方案2:开启驼峰映射, 会自动映射
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<select id="queryById" resultType="teacher">
select t_id, t_name from teacher where t_id = #{id}
</select>
方案3:自定义映射规则 resultMap
<!--
id: 标识
type: 返回类型, 全限定符或别名, 集合只写泛型即可
-->
<resultMap id="teacherMap" type="teacher">
<!--
<id /> 主键映射关系
<result /> 普通列的映射关系
-->
<id column="t_id" property="tId" />
<result column="t_name" property="tName" />
</resultMap>
<!-- resultMap 引用 id -->
<select id="queryById" resultMap="teacherMap">
select t_id, t_name from teacher where t_id = #{id}
</select>
resultMap和resultType只能选择一个使用resultMap用来自定义映射关系, 上述只是用于单表, 当进行多表查询时,resultType将无法进行映射了, 这个时候resultMap就得用起来了, 比如我订单里面包含商品信息, 这种查询时需要多表之间进行关联的。
3. 多表映射
3.1 多表实体类存储设计
多表映射可以简化为两种, 一对一和一对多
一对一:指一个实体A拥有一个实体B(一个订单只属于一个客户)
一对多:指一个实体A拥有多个实体B(一个客户可以有多个订单)
数据库设计:
t_customer 表有 customer_id, customer_name 两个属性
t_order 表有 order_id, order_name, customer_id 三个属性
实体类设计
@Data
public class Order {
private Integer orderId;
private String orderName;
private Integer customerId;
}
@Data
public class Customer {
private Integer customerId;
private String customerName;
}
3.2 一对一
在查询订单时, 关联的客户信息也查出来, 这个时候就要修改实体类, 加入客户, 用来存放客户信息 (注意:当我们没有这个需求时, 这个字段不进行赋值, 为空即可)
@Data
public class Order {
private Integer orderId;
private String orderName;
private Integer customerId;
// 查询的客户信息
private Customer customer;
}
SQL语句:两个表联查, 可以使用 INNER JOIN
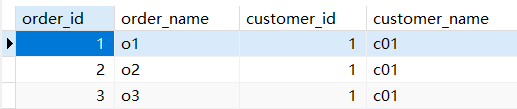
SELECT order_id, order_name, t_order.customer_id customer_id, customer_name FROM t_order INNER JOIN t_customer ON t_order.customer_id = t_customer.customer_id where order_id = #{id}
查询结果如图所示:共有三个订单
现在 Order 实体类中有四个属性 order_id, order_name, customer_id, customer, 按照原来的方法我们只能成功赋值前三个属性, 而第四个作为自定义对象, mybatis 并不知道如何赋值, 因为 customer_name 列会去找 customerName 属性, 但是找不到, 所以需要我们自定义映射关系。
<!-- type 返回值类型 -->
<resultMap id="orderMap" type="order">
<!-- 第一层映射 -->
<id column="order_id" property="orderId"/>
<result column="order_name" property="orderName"/>
<result column="customer_id" property="customerId"/>
<!--
第二层映射, 使用 association 标签
property: 实体属性名
javaType: 实体类型, 全限定符或别名
-->
<association property="customer" javaType="customer">
<!-- column 指定列名, property 指定 Customer类中的实体属性名 -->
<id column="customer_id" property="customerId"/>
<result column="customer_name" property="customerName"/>
</association>
</resultMap>
<select id="queryOrderById" resultMap="orderMap">
SELECT order_id, order_name, t_order.customer_id customer_id, customer_name FROM t_order
INNER JOIN t_customer ON t_order.customer_id = t_customer.customer_id where order_id = #{id}
</select>
- 里面的
column都是根据SQL语句中select后面from之前的那些字段, 我们可以定义别名并使用
SELECT order_id, order_name, t_order.customer_id customer_id, customer_name FROM - 主要是
association和javaType两种字段来实现一对一
3.3 一对多
场景:查询所有客户信息, 包括客户的订单信息, 客户实体类需要添加字段来存储订单信息。
@Data
public class Customer {
private Integer customerId;
private String customerName;
// 订单信息
private List<Order> orderList;
}
SQL语句及查询结果如下
SELECT t_customer.customer_id customer_id, customer_name, order_id, order_name FROM t_customer INNER JOIN t_order

只有一个用户但是它有三个订单
XML文件
<resultMap id="customerMap" type="customer">
<id column="customer_id" property="customerId"/>
<result column="customer_name" property="customerName"/>
<!--
给集合属性赋值
property: 集合属性名
ofType: 集合的泛型类型
-->
<collection property="orderList" ofType="order">
<id column="order_id" property="orderId"/>
<result column="order_name" property="orderName"/>
<result column="customer_id" property="customerId"/>
</collection>
</resultMap>
<select id="queryList" resultMap="customer">
SELECT t_customer.customer_id customer_id, customer_name, order_id, order_name
FROM t_customer INNER JOIN t_order
</select>
如此配置即可
- 主要是
collection和ofType两种字段来实现一对多
注意:order 类中的 customer 在此处并没有进行赋值, 为什么?
- 需求是查询客户及客户订单信息, 并不需要订单对应的客户信息
- 如果加上会一直陷入死循环查询, 订单中有客户信息, 客户中有订单信息…
3.4 多表映射优化
之前我们使用 resultType 时是有自动映射的, 只要列名和属性名相同(比如都为 orderId)就可以自动映射, 如果开启驼峰映射, 那么 order_id 与 orderId 就可以自动映射。那么 resultMap 可以吗?
在 setting 中有一个字段 autoMappingBehavior

由于默认值是 PARTIAL, 所以只能映射一层嵌套。
而且这里还很特殊, 它所说的嵌套一层是指当 resultMap 中没有 collection 或 association 时才帮忙嵌套一层
<resultMap id="customerMap" type="customer">
</resultMap>
会自动嵌套 customer_id, customer_name, 而 orderList 为空
<resultMap id="customerMap" type="customer">
<id column="customer_id" property="customerId"/>
<collection property="orderList" ofType="order">
</collection>
</resultMap>
都不嵌套, customer_id, customer_name, orderList 都为空
设置 autoMappingBehavior 为 FULL 后
<resultMap id="customerMap" type="customer">
<id column="customer_id" property="customerId"/>
<collection property="orderList" ofType="order">
<id column="order_id" property="orderId"/>
</collection>
</resultMap>
会帮我们映射 customer_id, customer_name, orderList
视频中讲的说 id 和属性手动映射一下, 其他可以交给自动映射, 没有说具体原因, 我试了一下, 如果不指定 id, 查询结果有些情况下会和我们实际要的结果不一致, 所以 id 尽量都不要省啦。
4. 动态语句
4.1 where + if
本章使用的实体类
@Data
public class Employee {
private Integer empId;
private String empName;
private Double empSalary;
}
接口方法定义
List<Employee> query(@Param("name") String name, @Param("salary") Double salary);
实际开发中存在一种常见, 比如我想根据员工的姓名或工资查询, 这两个参数传入的值都可以为空, 即传入的可以是姓名和工资, 只有姓名或只有工资, 或者两个都没有(查询所有员工), 那么SQL语句该怎么写, 按照原来的方法
SELECT * from t_emp where emp_name = #{name} and emp_salary = #{salary}
如果我只传入了工资, 那么 name 将为 null, 最终执行的SQL语句将是 SELECT * from t_emp where emp_name = null and emp_salary = ? 这样将查不到任何员工, 因为不存在没有名字的员工。
所以出现了 if 来实现动态拼接语句
<select id="query" resultType="employee">
select emp_id, emp_name, emp_salary from t_emp where
<!-- test为判断条件 -->
<if test="name != null">
emp_name = #{name}
</if>
<if test="salary != null and salary > 10">
and emp_salary = #{salary}
</if>
</select>
如此我们实现了动态拼接, 当名字为空, 就不加上这个列属性的判断了, 同理工资也是
注意:> 是 > 符号, 在XML文件中不要写 > < 符号, 因为容易被识别为标签开始结束符, 所以使用 > < 代替
该语句四种情况下的语句如下表格
| 姓名 | 工资 | SQL语句 | 是否正确 |
|---|---|---|---|
| 空 | 空 | select emp_id, emp_name, emp_salary from t_emp where | 否 |
| 空 | 不空 | select emp_id, emp_name, emp_salary from t_emp where and emp_salary = ? | 否 |
| 不空 | 空 | select emp_id, emp_name, emp_salary from t_emp where emp_name = ? | 是 |
| 不空 | 不空 | select emp_id, emp_name, emp_salary from t_emp where where emp_name = ? and emp_salary = ? | 是 |
实际拼接会有两种情况下报错的, SQL 语句不正确, 所以通常要结合 where, where 标签有两个作用
- 自动添加 where 关键字, 如果
where内部有任何一个 if 满足, 自动添加 where 关键字, 不满足则不添加 - 自动去掉多余的 and 和 or 关键字
<select id="query" resultType="employee">
select emp_id, emp_name, emp_salary from t_emp
<where>
<if test="name != null">
emp_name = #{name}
</if>
<if test="salary != null and salary > 10">
and emp_salary = #{salary}
</if>
</where>
</select>
这种书写形式下, 四种情况都是正确的
注意:要把 and 和 or 关键字放在前面才能识别到, 如果多余会自动去除, 放到后面识别不到, 语句仍然错误
<where>
<if test="name != null">
emp_name = #{name} and <!-- 不要这么写 -->
</if>
<if test="salary != null and salary > 10">
emp_salary = #{salary}
</if>
</where>
4.2 set
update t_emp set emp_name = #{empName}, emp_salary = #{empSalary} where emp_id = #{empId}
场景:更新的时候也有可能某些字段为空, 那我们不能把数据库的那些值设置为空
接口函数定义
int update(Employee employee);
SQL语句编写
<update id="update">
update t_emp set
<if test="empName != null">
emp_name = #{empName},
</if>
<if test="empSalary != null">
emp_salary = #{empSalary}
</if>
where emp_id = #{empId}
</update>
问题和前面的一样, 当我第二个条件不满足, 第一个满足时 update t_emp set emp_name = ?, where emp_id = ? 会多一个逗号, 当都不满足时 update t_emp set where emp_id = ? 会多一个 set
所以引入 set, 作用有两个
- 自动去掉多余的逗号(逗号放在前面后面都可以, 但是
andor关键字只能放在前面) - 自动添加 set 关键字
<update id="update">
update t_emp
<set>
<if test="empName != null">
emp_name = #{empName},
</if>
<if test="empSalary != null">
emp_salary = #{empSalary}
</if>
</set>
where emp_id = #{empId}
</update>
测试如下:right
int rows = mapper.update(new Employee(1, "二狗蛋", null));
4.3 trim
了解即可
<!--
trim:代替了where的作用,使用prefix
若标签中有内容时
prefix|suffix:将trim标签中内容前面或后面添加指定内容
suffixOverrides|prefixOverrides:将trim标签中内容前面或后面去掉指定内容 连接完成后语句最前面后者最后面的内容
若标签中没有内容时,trim标签也没有任何效果 也就没有了where
-->
<select id="queryTrim" resultType="employee">
select emp_id, emp_name, emp_salary from t_emp
<!-- | 分割可能的多个值 -->
<trim prefix = "where" suffixOverrides = "and | or">
<if test = "name != null and name != ''">
emp_name = #{name} and
</if>
<if test = "salary !=null and salary > > 10">
emp_salary = #{salary}
</if>
</trim>
</select>
trim 可以代替 where, 还可以代替 set
4.4 choose/when/otherwise
相当于 Java 中的 switch-case-default, 在多个分支条件中, 仅执行一个
从上到下执行, 遇到第一个满足条件的分支会被采纳, 后面的都不被考虑, 如果所有的 when 都不满足, 那么就执行 otherwise 分支
场景:如果给了员工姓名就根据姓名查, 没给姓名给了工资就根据工资查, 都没给就查询全部
<select id="queryChoose" resultType="employee">
select emp_id, emp_name, emp_salary from t_emp
where
<choose>
<when test="name != null">
emp_name = #{name}
</when>
<when test="salary != null and salary > 10">
emp_salary > #{salary}
</when>
<otherwise>1=1</otherwise>
</choose>
</select>
4.5 foreach
foreach 标签中的属性有如下几种
collection:设置需要循环的数组或集合 该属性是必须指定的,而且在不同情况下,该属性的值是不一样的。主要有以下3种情况:
1. 如果传入的是单参数且参数类型是一个数组或者 List 的时候,collection 属性值分别为 array 和 list。当然使用 `@Param` 进行指定名字更好一点。
1. 如果传入的参数是多个的时候,就需要把它们封装成一个 Map 了,当然单参数也可以封装成 Map 集合,这时候collection 属性值就为 Map 的键。
1. 如果传入的参数是 POJO 包装类的时候,collection 属性值就为该包装类中需要进行遍历的数组或集合的属性名
item:表示数组或集合中的每一个数据
separator:循环体之间的分隔符
open:foreach 标签中所循环的所有内容的开始符
close:foreach 标签所循环的所有内容的结束符
index:配置的是当前元素在集合的位置下标,如果需要可以使用
下面演示增删改查四种操作下的 foreach 该如何使用
接口方法定义
List<Employee> queryBatch(@Param("ids") List<Integer> ids);
int deleteBatch(@Param("ids") List<Integer> ids);
int insertBatch(@Param("ids") List<Employee> employees);
int updateBatch(@Param("employees") List<Employee> employees);
XML文件:插入
<insert id="insertBatch">
insert into t_emp(emp_name, emp_salary) values
<foreach collection="employees" separator="," item="emp">
(#{emp.empName}, #{emp.empSalary})
</foreach>
</insert>
- 通过
对象.属性名访问内部属性值
对应的SQL语句为
insert into t_emp(emp_name, emp_salary) values (?, ?) , (?, ?) , (?, ?)
XML文件:查询
<sql id="employeeProperties">
emp_id, emp_name, emp_salary
</sql>
<select id="queryBatch" resultType="employee">
select <include refid="employeeProperties"/> from t_emp
where emp_id in
<foreach collection="ids" open="(" separator="," close=")" item="id">
#{id}
</foreach>
</select>
这里的使用了 SQL 片段, 就是为了避免重复写, 你可以在 <sql id="标识"></sql> 里面声明任意的SQL片段, 然后使用 <include refid="标识" /> 进行引用即可。
对应的SQL语句为
select emp_id, emp_name, emp_salary from t_emp where emp_id in ( ? , ? , ? )
XML 文件:更新
<update id="updateBatch">
<foreach collection="employees" item="emp">
update t_emp set emp_name = #{emp.empName}, emp_salary = #{emp.empSalary}
where emp_id = #{emp.empId};
</foreach>
</update>
对应的SQL语句为
update t_emp set emp_name = ?, emp_salary = ? where emp_id = ?; update t_emp set emp_name = ?, emp_salary = ? where emp_id = ?; update t_emp set emp_name = ?, emp_salary = ? where emp_id = ?;
-
删除操作是
delete from t_emp where emp_id in (...)形式, 一条语句可以完成, 插入也是 -
这里不同于前面, 因为更新比较特殊, 更新的时候是一条语句更新一个内容, 没有公共的部分, 因为更新的时候是根据集合中的一个元素去更新数据库的一条数据, 所以需要一个语句更新一条数据库信息。这里就造成了多语句的情况, 数据库默认情况下是不支持的, 会报错, 这里就需要我们在连接数据库的时候进行设置, 允许多语句查询, 加入
allowMultiQueries=true<dataSource type="POOLED"> <property name="driver" value="com.mysql.cj.jdbc.Driver"/> <property name="url" value="jdbc:mysql://localhost:3306/mybatis-example?allowMultiQueries=true"/> <property name="username" value="root"/> <property name="password" value="mysql"/> </dataSource>
XML文件:删除
<delete id="deleteBatch">
delete from t_emp where
<foreach collection="ids" separator="or" item="id">
emp_id = #{id}
</foreach>
</delete>
对应的SQL语句
delete from t_emp where emp_id = ? or emp_id = ? or emp_id = ?
- 也可以使用像查询一样的方式
delete from t_emp where emp_id in (?, ?, ?)
4.6 模糊查询
/**
* 根据用户名模糊查询用户信息
*/
List<User> getUserByLike(@Param("username")String username);
三种方法,最后一种更常用
<select id="getUserByLike" resultType="User">
select * from t_user where username like '%${username}%'
select * from t_user where username like concat('%',#{username},'%')
select * from t_user where username like "%"#{username}"%"
</select>
5. 高级扩展
5.1 mapper 包批量扫描
在 mapper 扫描时, 我们原来的方式是逐个写入, 每写一个就添加一个
<mappers>
<mapper resource="mappers/OrderMapper.xml"/>
<mapper resource="mappers/CustomerMapper.xml"/>
</mappers>
这种方式比较麻烦, 也有更快捷的方式, 使用包批量扫描, 指定位置
<mappers>
<package name="com.lh.mapper"/>
</mappers>
不过如此情况下, 就有两点要求
- mapper.xml 文件与 mapper 接口命名一致
- 二者所在文件目录必须相同, 如此处都为
com.lh.mapper, 这样编译打包后, EmployeeMapper.java 和 EmployeeMapper.xml 才是在同一个文件夹目录下。
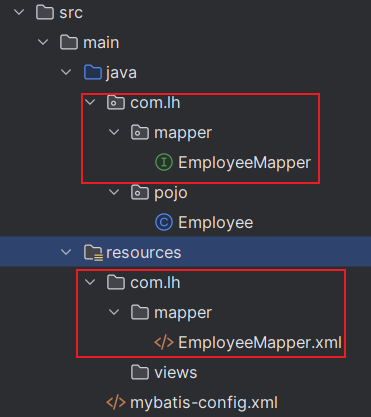
5.2 分页插件
一个比较好的分页插件 pagehelper, 但使用该插件要注意在写SQL语句时不要加 ; 结尾, 因为分页插件底层是使用的 AOP, 帮我们在尾部拼接上 limit (x,y) 的方式进行分页查询。
select * from t_emp ; # 分号不要嗷!!!
POM 依赖
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>6.1.0</version>
</dependency>
mybatis-config.xml 配置分页插件
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<property name="helperDialect" value="mysql"/>
</plugin>
</plugins>
helperDialect 属性用于指定数据库类型 (支持多种数据库)
测试, query() 是查询所有员工
EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class);
// 调用之前设置分页数据(当前是第几页, 每页显示多少个)
PageHelper.startPage(1, 2); // 第一页, 两个数据
List<Employee> list = mapper.query();
// List<Employee> list = mapper.query(); 不能将两条查询语句写到一个分页区中
// 即 PageHelper.startPage(pageNum, pageSize) 与 PageInfo 中间只能有一个查询语句, 否则分页失效
// 将查询数据封装到一个 PageInfo的分页实体类
PageInfo<Employee> pageInfo = new PageInfo<>(list);
System.out.println("pageInfo = " + pageInfo);
在 pageInfo 中有很多信息可以使用
pageInfo = PageInfo{
pageNum=1, // 当前页
pageSize=2, // 每页的数量
size=2, // 当前页的数据的数量
startRow=1, // 当前页中第一个数据在数据库中的行号, 不常用
endRow=2, // 当前页中最后一个数据在数据库中的行号, 不常用
total=6, // 所有页面总数据量
pages=3, // 总页数
// mapper.query() 查询后的返回值, 返回类型不是我们规定的 List<Employee> 啦, 而是变成了 Paeg<Object>
list=Page{
count=true,
pageNum=1, // 页码
pageSize=2, // 页面大小
startRow=0, // 起始行
endRow=2, // 末行
total=6, // 总数据量
pages=3, // 总页数
reasonable=false,
pageSizeZero=false
}[Employee(empId=1, empName=二狗蛋, empSalary=200.33), Employee(empId=2, empName=jerry, empSalary=666.66)],
// mapper.query() 结果结束位置
prePage=0, // 前一页页码
nextPage=2, // 后一页页码
isFirstPage=true, // 是否为第一页
isLastPage=false, // 是否为最后一页
hasPreviousPage=false, // 是否有前一页
hasNextPage=true, // 是否有下一页
navigatePages=8, // 导航页码数, 默认给 8 个 (超过8个也只给8个)
navigateFirstPage=1, // 导航条上的第一页页码
navigateLastPage=3, // 导航条上的最后一页页码
navigatepageNums=[1, 2, 3] // 所有导航页
}
5.3 逆向工程
现阶段就不学了嗷
6. 实用技巧
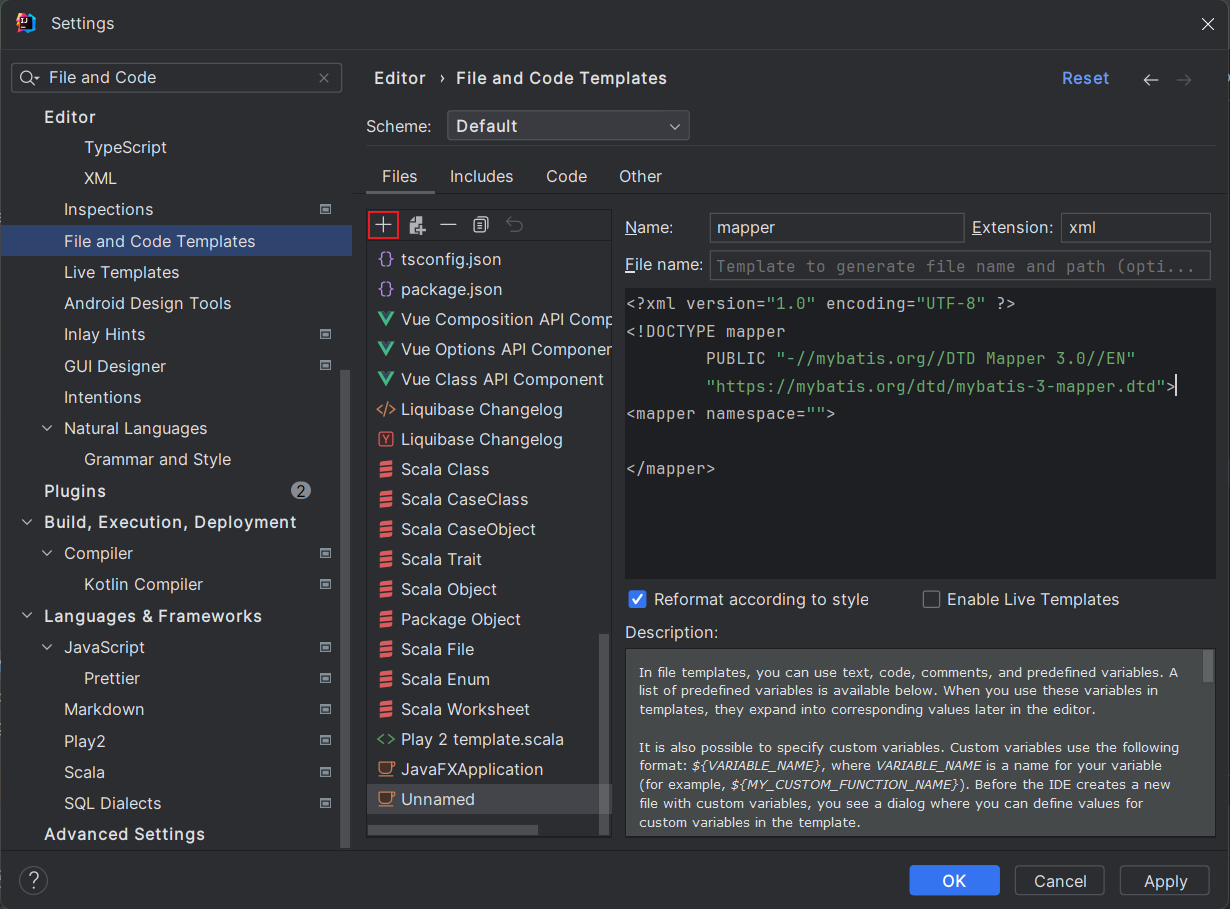
6.1 创建模板
每次创建 mapper.xml 文件不方便, 可以使用这种方式创建模板, 这样在创建文件时, 右键选择该模板即可。
6.2 目录创建
在 src/main/java 下创建多级目录, 我们使用 com.lh.pojo 的方式, 通过 . 来分割
在 resources 资源目录下创建多级目录, 我们使用 views/jsp 的方式, 通过 / 来分割, . 不行, 如果用 . 会生成 名为 view.jsp 这一个目录, views 无子目录。
7. 常见问题
JDK问题导致的某些函数无法调用, 如 List.of 是 JDK9之后的, JDK8无法调用, 需要修改多个地方
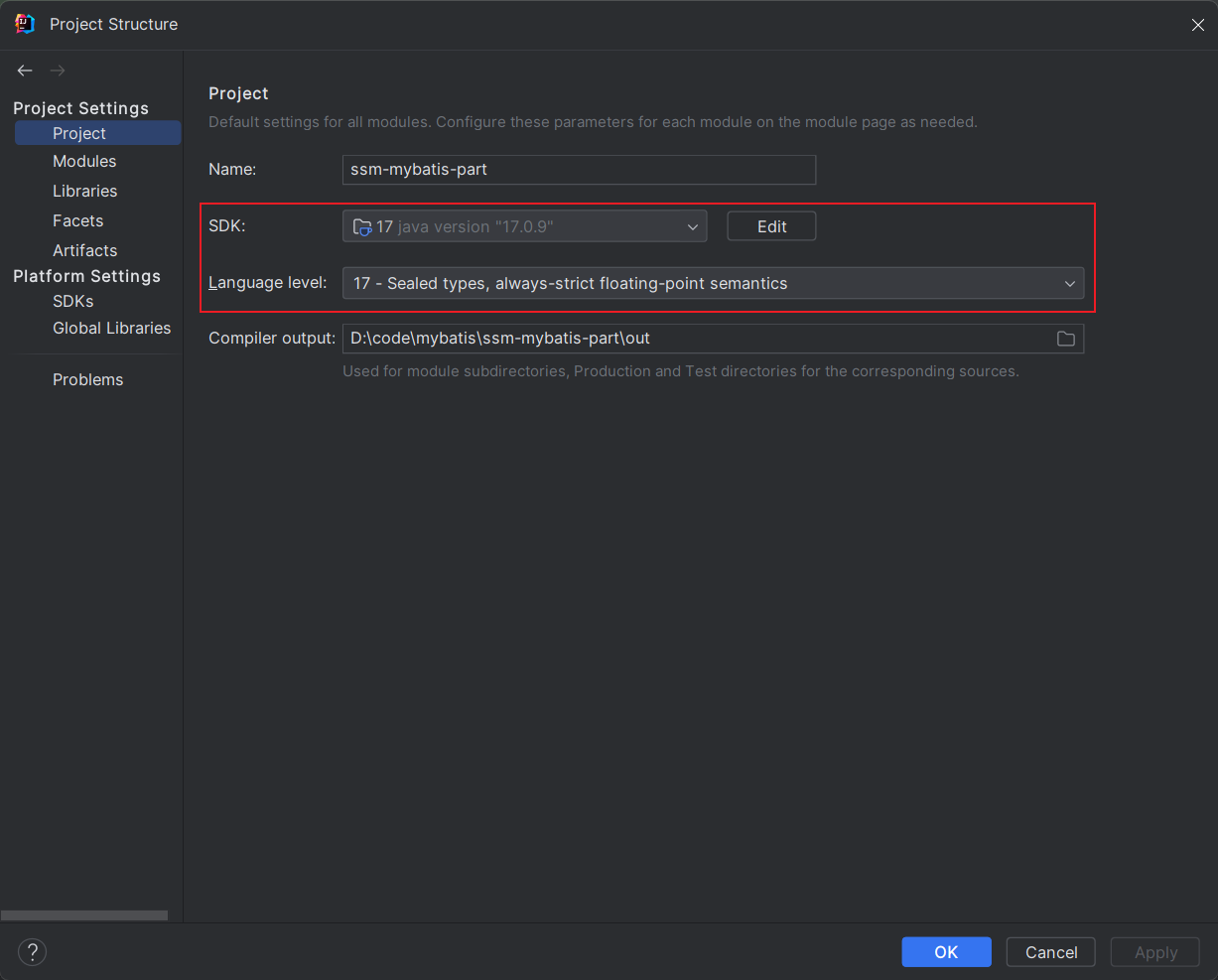
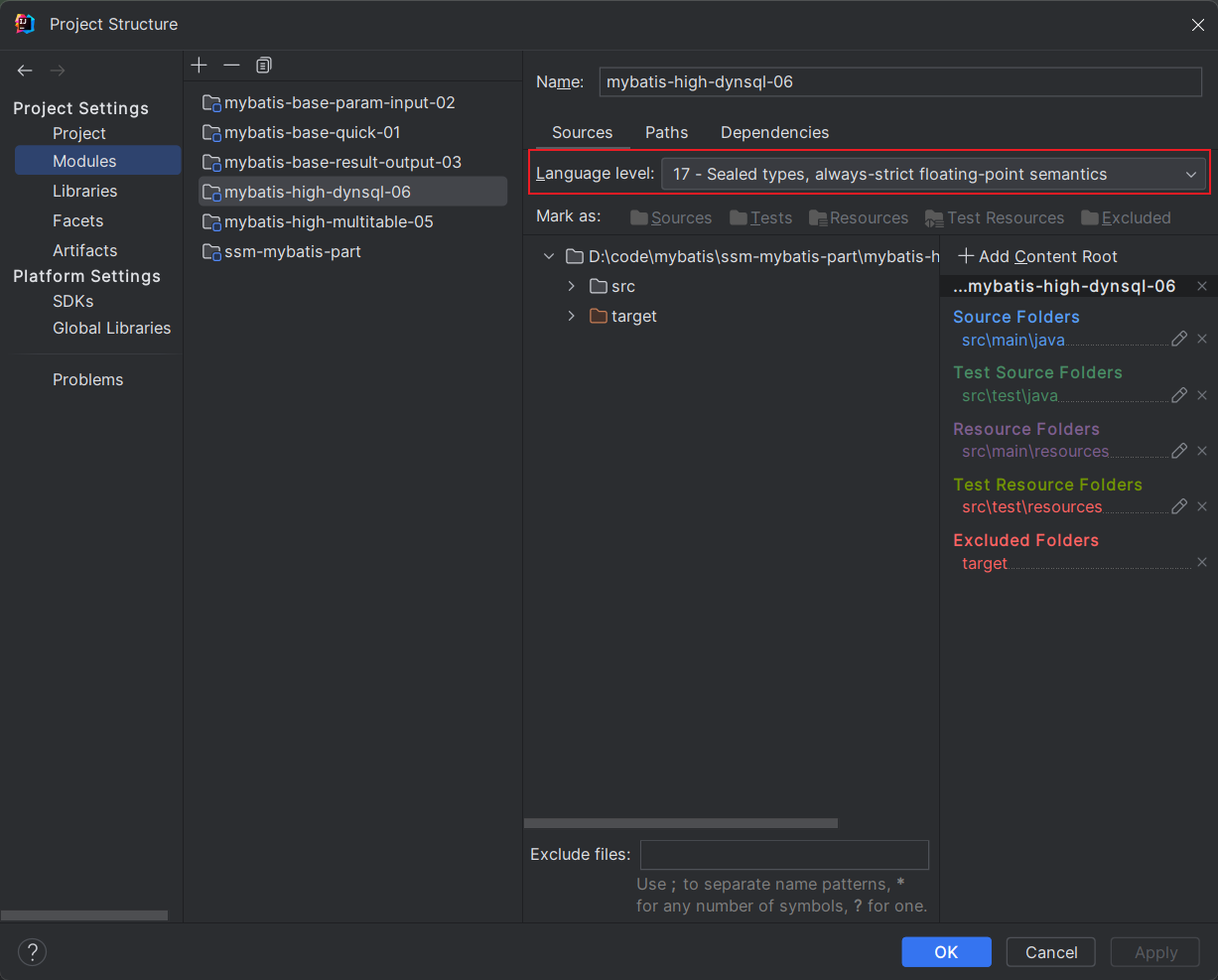
这个地方改完之后, 就可以调用函数了, 它是语言层面上的, 不会爆红了。
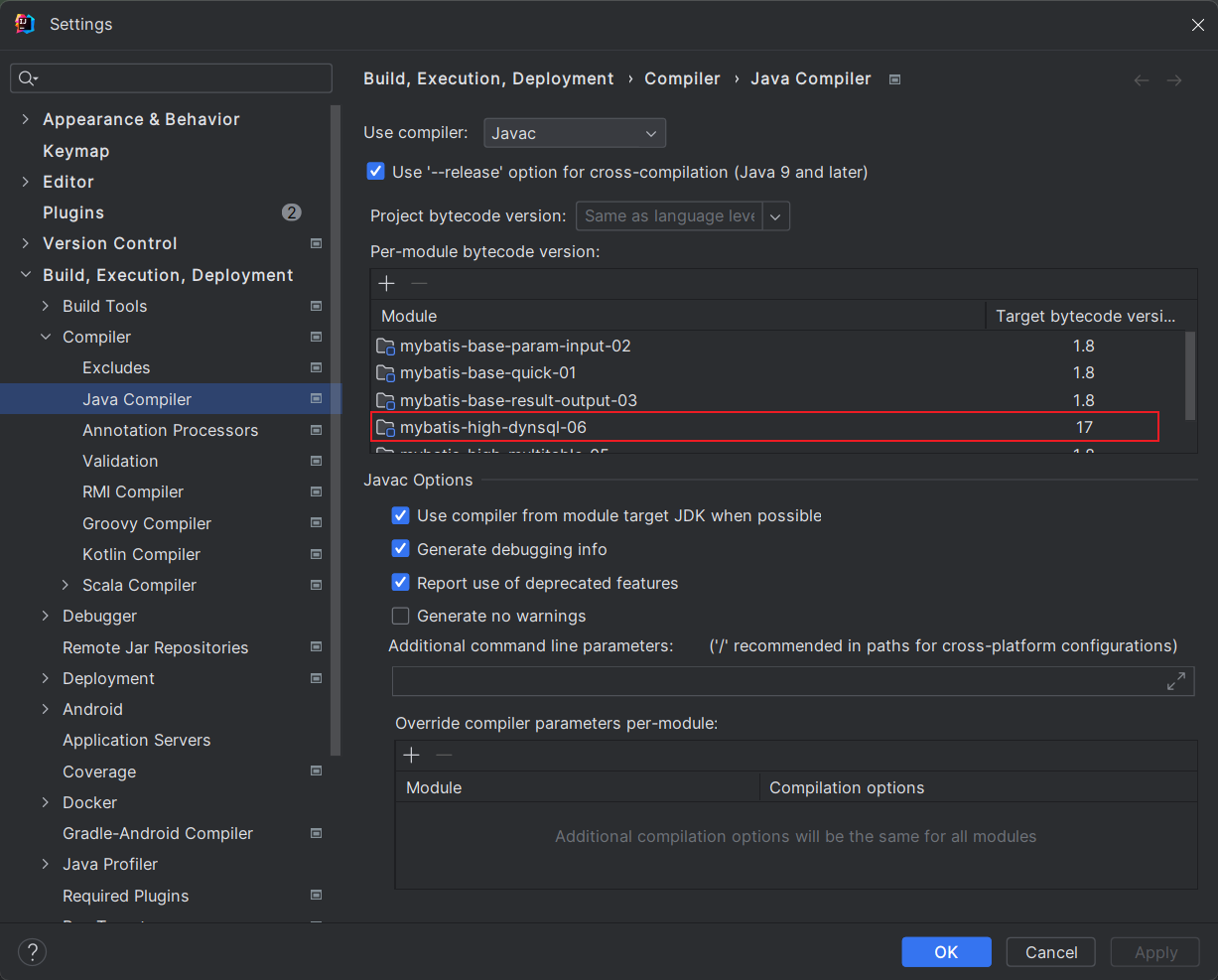
不会爆红是Java编辑器通过了, 但是进行编译的时候还要指定JDK
这几个都一样就行了















 159
159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









