







- 系统变量和环境变量
https://www.cfan.com.cn/2021/0106/134717.shtml
-
show.signif.stars ??
-
Boolean vector(布尔向量)
Bolean value==logical value布尔向量就是充满着逻辑值的逻辑向量。
-
read.table 和 data.frame区别
1)read.table——读取矩形表格
2)data.frame——创建数据框函数 -
levels?——因子中字符型变量所特有的还是?
-
对象结构在形成数据框之后无法更改
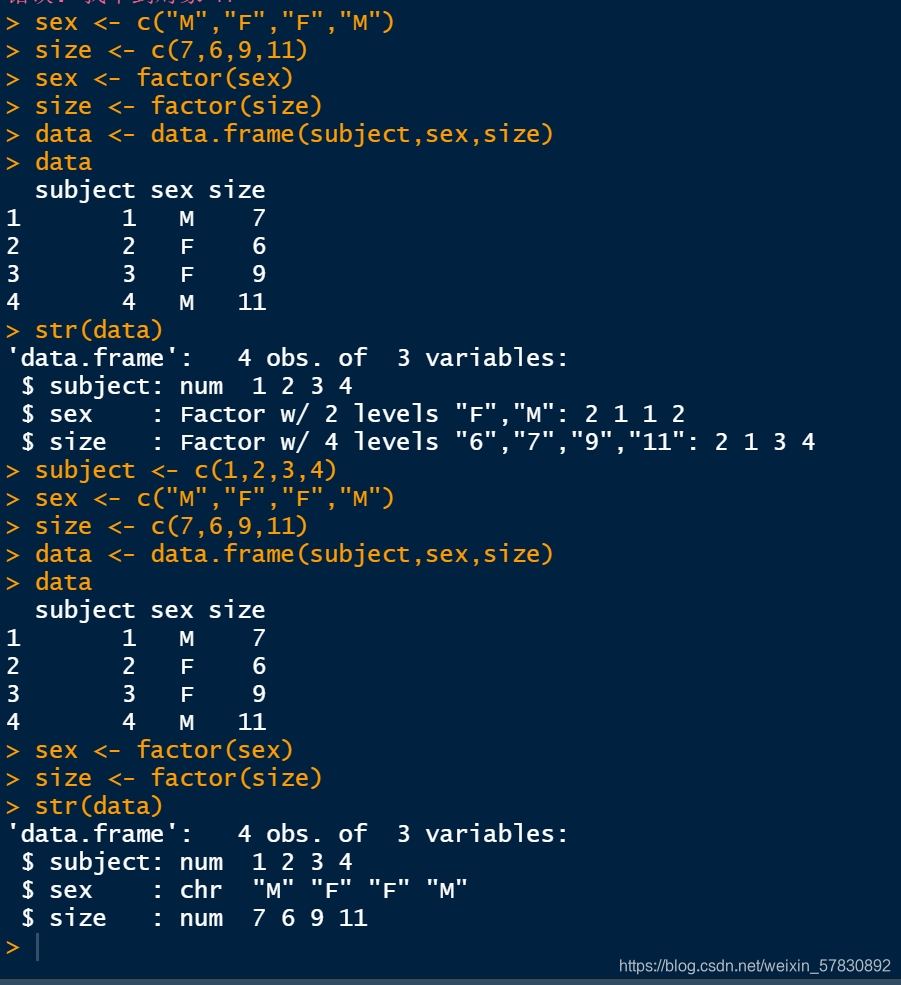
-
?length()
(1)length() 用来返回字符数量的
(2)向量索引中用到的length
v
[1] 1 4 4 3 2 2 3`
length(v)
[1] 7
v[-length(v)] ## Drop just the last element
[1] 1 4 4 3 2 2
v[-length(v)] ##可以看作索引v时 drop向量中第7个变量,即最后一个元素
[1] 1 4 4 3 2 2
(3)数据框索引中用到的length
data
subject sex size
1 1 M 7
2 2 F 6
3 3 F 9
4 4 M 11
data[-length(data)]
subject sex
1 1 M
2 2 F
3 3 F
4 4 M
data[,-length(data)]
subject sex
1 1 M
2 2 F
3 3 F
4 4 M
data[-length(data),]
subject sex size
1 1 M 7
2 2 F 6
4 4 M 11
##综合来看,-length(data)就是 -3(data这个数据框的变量数)
(4)数据框中用length()
> df
n let
1 1 A
2 2 B
3 3 C
4 4 D
> length(df)
[1] 2
(5)nchar()与 length()
-
nchar函数:主要使用来返回向量中每个字符长度
-
而length函数:则是用来返回向量中总共的字符数量
-
v[]与subset()
v[v<3] <- 9
subset(v, v<3) <- 9
#> Error in subset(v, v < 3) <- 9: could not find function "subset<-"
```##我认为是因为v是一个数据集名称,所以可以赋值,而subset是函数,不能被赋值。
-
数据框索引的几种情况
1)data[x,y]——数据框第x行,第y列
2) data[x](无逗号)——数据框第x列——我理解的就是提取数据框中
第x个变量及其赋值,所以第x列对应的变量。 -
rep()
rep(1, 40*(1-.8)) # length 7 on most platforms #因为返回结果为浮点数,这里返回的结果会比8小
rep(1, 40*(1-.8)+1e-7) # better #40*(1-.8)+1e-7=40X0.2+10^(-7),这样返回的浮点数最后得到的结果就是8
x <- rep(1, 40*(1-.8)+1e-7)
> x
[1] 1 1 1 1 1 1 1 1
> length(x)
[1] 8
>
11.整数(integer)和浮点数(float)
https://blog.csdn.net/weixin_30732487/article/details/98061444
-
explicit testing??
-
NaN、NA、NULL、Inf
1)NaN——无意义的值(0/0),但R实际上是把NaN视作一个数的
> z <- NaN
> z>5
[1] NA #这里是NA,我认为是因为NaN虽然没有值(即无意义的值),但是有位置的
> is.na(z)
[1] TRUE #R中把NaN视作NA
在分析中排除NaN时:
> vz <- c(1,2,3,NaN,5)
> sum(vz)
[1] NaN
> sum(vz,**na.rm=T**)
[1] 11
> sum(vz,**nan.rm=T**)
[1] NaN
> sum(vz,**NaN.rm=T**)
[1] NaN
2)NA——有位置,没有值
- NA(logical)
- NA_real_(double)
- NA_integer_(integer)
- NA_character_(character)
3)NULL——没有位置,也没有值
PS:
(1)如何区分NULL和NA?很简单,前者的logical length是0,后者的logical length是1,意思是假如用is.logical判断NA的逻辑值,得到的结果是TRUE。NA可以为正无穷或负无穷,但NULL永远代表的是没有这个值,一个空集的概念。(https://www.cnblogs.com/postmodernist/p/4235211.html)
(2)logical(0)—— no value to be checked
(ps: logical (1)—true;logical (0)—false)
4)Inf——无穷大
link
Note that NULL is different from the other two. NULL means that there is no value, while NA and NaN mean that there is some value, although one that is perhaps not usable.
14.floor() , ceiling(), round( )
取整数
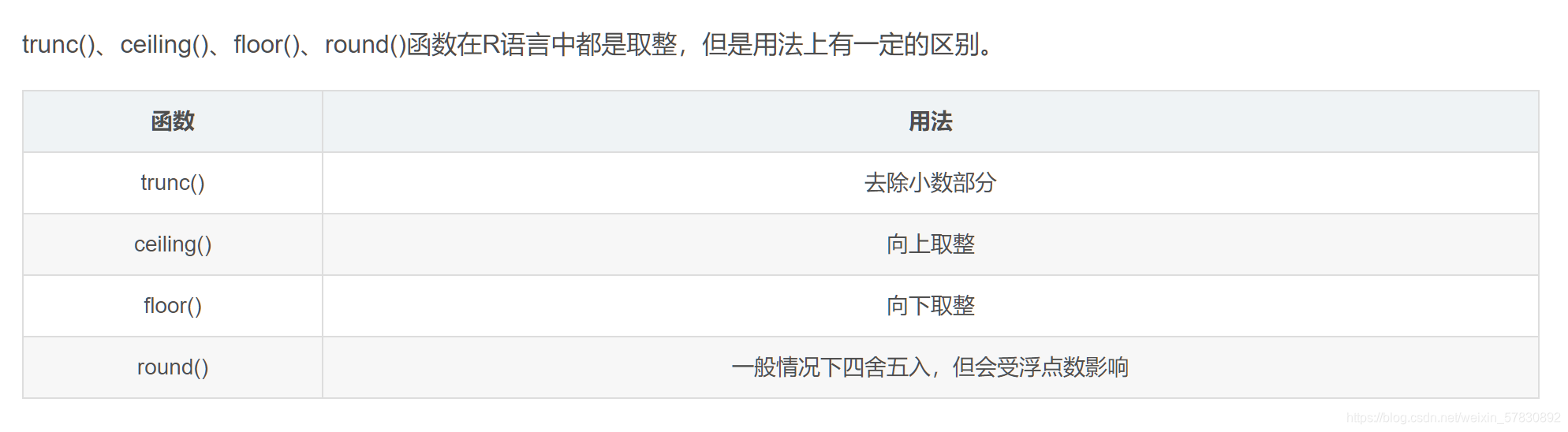
[注:round()会受浮点数影响,在.5时无法确定是舍还是入,可以在后面+0.000001或者-0.0001来确保不会出现bug]
15.replace=F replace=T
16.grep()函数用法
https://www.jianshu.com/p/11bbfa8e98c5
17.substr()substring()
x <- c(“12345678”,“abcdefg”,“hijklmn”,“opqrst”)
x
[1] “12345678” “abcdefg” “hijklmn” “opqrst”
substring(x,c(2,4),c(4,5,8))
[1] “234” “de” “ijklmn” “r”#这里"r"的字符串起始位置组合为4-4,所以只有r
> DNA <- paste(sample(bases,12,replace=T),collapse = "")
> DNA
[1] "ATACTGTTGATA"#sample()中字符串排列是随机的
- regexpr、gregexpr和regexec
(1)共同点:这三个函数返回的结果包含了匹配的具体位置和字符串长度信息,可以用于字符串的提取操作。
(2)不同点:
> DNA <- paste(sample(bases,12,replace=T),collapse = "")
> DNA
[1] "ATACTGTTGATA"
> regexpr("ATA",DNA)
[1] 1
attr(,"match.length")
[1] 3
attr(,"index.type")
[1] "chars"
attr(,"useBytes")
[1] TRUE
> regexpr("A",DNA)
[1] 1
attr(,"match.length")
[1] 1
attr(,"index.type")
[1] "chars"
attr(,"useBytes")
[1] TRUE
> gregexpr("A",DNA)
[[1]]
[1] 1 3 10 12
attr(,"match.length")
[1] 1 1 1 1
attr(,"index.type")
[1] "chars"
attr(,"useBytes")
[1] TRUE
> gregexpr("ATA",DNA)
[[1]]
[1] 1 10
attr(,"match.length")
[1] 3 3
attr(,"index.type")
[1] "chars"
attr(,"useBytes")
[1] TRUE
> regexec("A",DNA)
[[1]]
[1] 1
attr(,"match.length")
[1] 1
attr(,"index.type")
[1] "chars"
attr(,"useBytes")
[1] TRUE
> regexec("ATA",DNA)
[[1]]
[1] 1
attr(,"match.length")
[1] 3
attr(,"index.type")
[1] "chars"
attr(,"useBytes")
[1] TRUE
19.正则表达式与字符串,及字符串的处理
https://blog.csdn.net/duqi_yc/article/details/9817243
20.paste(…, sep = " ", collapse = NULL, recycle0 = F)
| sep | a character string to separate the terms(多个变量之间对应连接的字符串) |
|---|---|
| collapse | an optional character string to separate the results(向量最后返还结果之间连接的字符串) |
> a <- "apple"
> d <- c("fig","grapefruit","honeydew")
> paste(a,d,sep="-",collapse = ",")
[1] "apple-fig,apple-grapefruit,apple-honeydew"
21.??environment
as.formula("y ~ x1 + x2") #> y ~ x1 + x2 #> <environment: 0x3361710>
https://site.douban.com/182577/widget/notes/10567181/note/319376663/
其实没懂!!
22.在向量中使用seq()
> y <- c(1:20,seq(1,12,3))
> y
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13
[14] 14 15 16 17 18 19 20 1 4 7 10
``#这里是相当于y向量由1:20 和 seq(1,12,3)这两个组件组成
#seq(1,12,3)表示一组from1,to12,差为3的等差数列`在这里插入代码片`
> x <- matrix(c(1:20,seq(1,12,3)),3,3)
> x
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
#这里矩阵所需数据少于20,所以没有seq(1,12,3)函数的变量
cf:
> x <- matrix(c(1:20,seq(1,12,3)),6,4)
> x
[,1] [,2] [,3] [,4]
[1,] 1 7 13 19
[2,] 2 8 14 20
[3,] 3 9 15 1
[4,] 4 10 16 4
[5,] 5 11 17 7
[6,] 6 12 18 10
#**注:**在数据长度不是矩阵行数&列数整数倍的时候会报错。
24.读入文本失败时的解决方案
> read.table("input.csv")
Error in file(file, "rt") : 无法打开链结
此外: Warning message:
In file(file, "rt") : 无法打开文件'input.csv': No such file or directory
> read.table("input.txt")
Error in file(file, "rt") : 无法打开链结
此外: Warning message:
In file(file, "rt") : 无法打开文件'input.txt': No such file or directory
> **setwd("D:/R/Rdata/RData-training")**##这里要将需要导入的文件的文件夹路径设置当前工作目录,才能读取这个文件。
> read.table("input.csv")
V1 V2
1 ,"mpg","cyl","disp","hp","drat","wt","qsec","vs","am","gear","carb"
2 Mazda RX4 ,21,6,160,110,3.9,2.62,16.46,0,1,4,4
3 Mazda RX4 Wag ,21,6,160,110,3.9,2.875,17.02,0,1,4,4
4 Datsun 710 ,22.8,4,108,93,3.85,2.32,18.61,1,1,4,1
5 Hornet 4 Drive ,21.4,6,258,110,3.08,3.215,19.44,1,0,3,1
6 Hornet Sportabout ,18.7,8,360,175,3.15,3.44,17.02,0,0,3,2
7 Valiant ,18.1,6,225,105,2.76,3.46,20.22,1,0,3,1
8 Duster 360 ,14.3,8,360,245,3.21,3.57,15.84,0,0,3,4
9 Merc 240D ,24.4,4,146.7,62,3.69,3.19,20,1,0,4,2
10 Merc 230 ,22.8,4,140.8,95,3.92,3.15,22.9,1,0,4,2
11 Merc 280 ,19.2,6,167.6,123,3.92,3.44,18.3,1,0,4,4
12 Merc 280C ,17.8,6,167.6,123,3.92,3.44,18.9,1,0,4,4
13 Merc 450SE ,16.4,8,275.8,180,3.07,4.07,17.4,0,0,3,3
14 Merc 450SL ,17.3,8,275.8,180,3.07,3.73,17.6,0,0,3,3
15 Merc 450SLC ,15.2,8,275.8,180,3.07,3.78,18,0,0,3,3
16 Cadillac Fleetwood ,10.4,8,472,205,2.93,5.25,17.98,0,0,3,4
17 Lincoln Continental ,10.4,8,460,215,3,5.424,17.82,0,0,3,4
18 Chrysler Imperial ,14.7,8,440,230,3.23,5.345,17.42,0,0,3,4
19 Fiat 128 ,32.4,4,78.7,66,4.08,2.2,19.47,1,1,4,1
20 Honda Civic ,30.4,4,75.7,52,4.93,1.615,18.52,1,1,4,2
21 Toyota Corolla ,33.9,4,71.1,65,4.22,1.835,19.9,1,1,4,1
22 Toyota Corona ,21.5,4,120.1,97,3.7,2.465,20.01,1,0,3,1
23 Dodge Challenger ,15.5,8,318,150,2.76,3.52,16.87,0,0,3,2
24 AMC Javelin ,15.2,8,304,150,3.15,3.435,17.3,0,0,3,2
25 Camaro Z28 ,13.3,8,350,245,3.73,3.84,15.41,0,0,3,4
26 Pontiac Firebird ,19.2,8,400,175,3.08,3.845,17.05,0,0,3,2
27 Fiat X1-9 ,27.3,4,79,66,4.08,1.935,18.9,1,1,4,1
28 Porsche 914-2 ,26,4,120.3,91,4.43,2.14,16.7,0,1,5,2
29 Lotus Europa ,30.4,4,95.1,113,3.77,1.513,16.9,1,1,5,2
30 Ford Pantera L ,15.8,8,351,264,4.22,3.17,14.5,0,1,5,4
31 Ferrari Dino ,19.7,6,145,175,3.62,2.77,15.5,0,1,5,6
32 Maserati Bora ,15,8,301,335,3.54,3.57,14.6,0,1,5,8
33 Volvo 142E ,21.4,4,121,109,4.11,2.78,18.6,1,1,4,2
25.read.table(“file”,header=T,skip=…)
input 1文本内容
前五行有注释
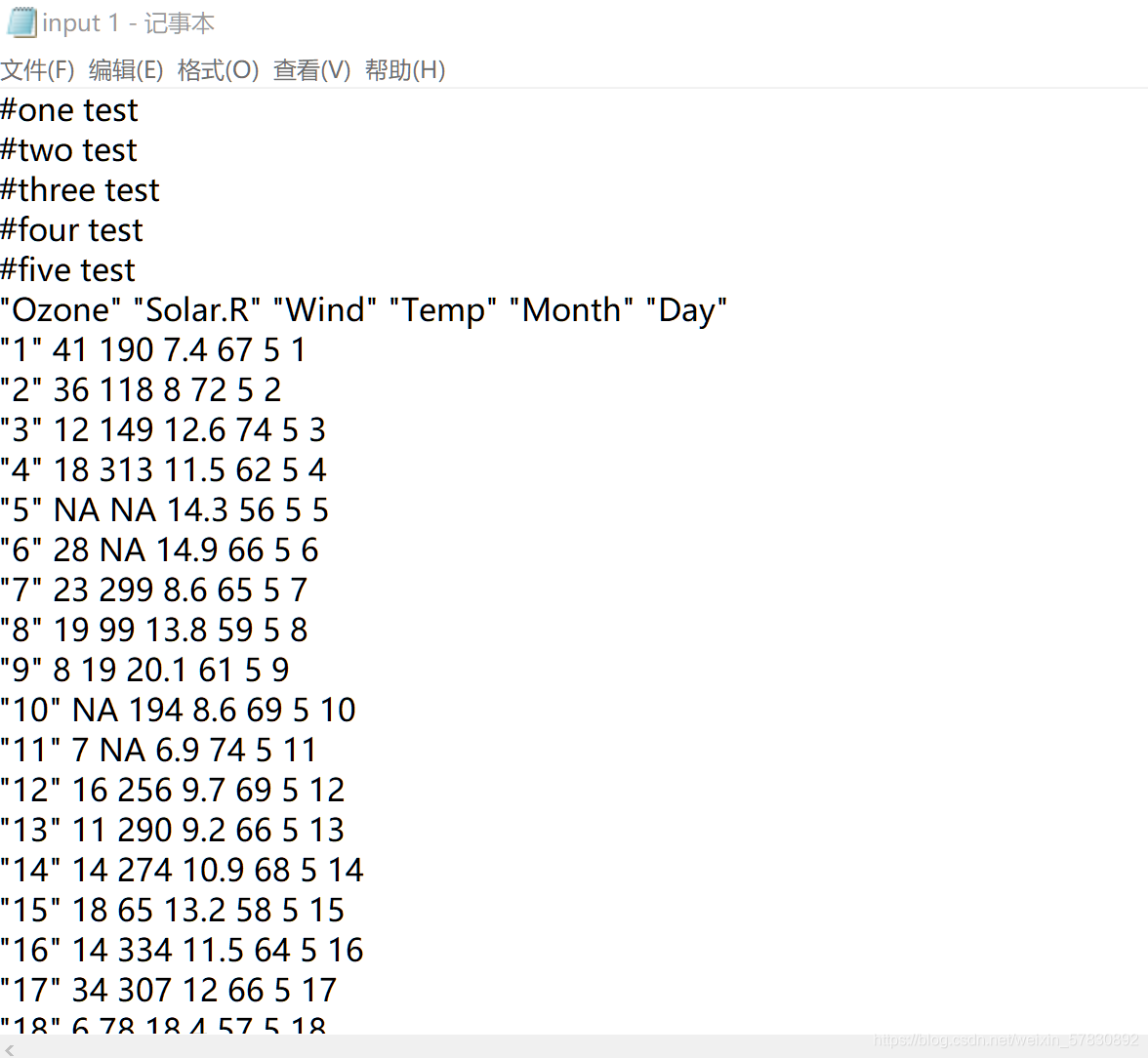
1)标明skip前五行
> read.table("input 1.txt",header=T,skip = 5)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
8 19 99 13.8 59 5 8
9 8 19 20.1 61 5 9
10 NA 194 8.6 69 5 10
11 7 NA 6.9 74 5 11
12 16 256 9.7 69 5 12
13 11 290 9.2 66 5 13
14 14 274 10.9 68 5 14
15 18 65 13.2 58 5 15
16 14 334 11.5 64 5 16
17 34 307 12.0 66 5 17
2)未标明skip前五行
> read.table("input 1.txt",header=T)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
8 19 99 13.8 59 5 8
#同样也跳过了前五行,因为input 1.txt文本中的前五行前面加了#,表示前五行为注释,所以导入R中时,被自动识别,读取进来也不运行。
26.R读取其他统计软件或者格式的文件
1)有一个通用方法是将其转换成csv格式文件,再用read.table(“file”,…)读取
2)利用R自带包"foreign",其中包含很多种函数读取对应软件的文件
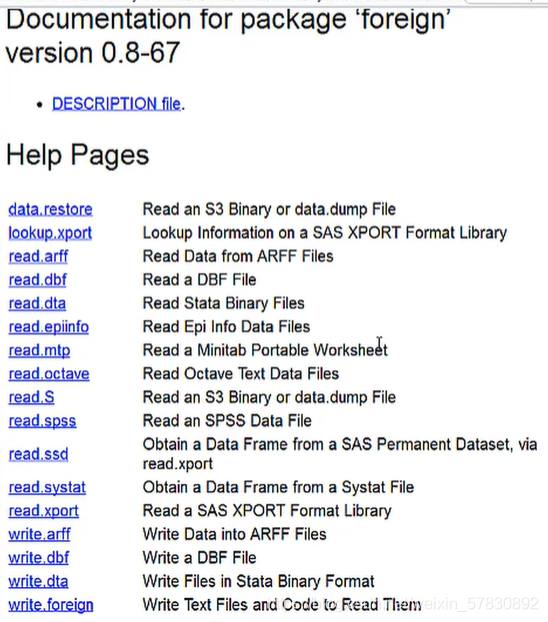
3)如果"foreign"包中没有可读取的函数,则先寻找R中对应的包
> RSiteSearch("Matlab")#跳转到对应的R网页,找到可读取Matlab格式的文件的函数在包"R.Matlab"中
27.file.choose() 打开文件的文件选择器
data <- read.csv(file.choose())
#打开的文件为之前设置的当前工作目录
28.导入excel数据
3.1Q:
1)指数
> N <- 2.1e23
> N
[1] 2.1e+23#??
exp() 函数返回 e的x次方
30.数据框索引的区别
-1.
mydata$V1,mydata[, 1]索引的返回值是向量
-因为R的缺省规则是返回一个维数尽可能低的值
- 可通过选项drop() 修改
> r[,3,drop=F]#设置drop=F
Wind
1 7.4
2 8.0
3 12.6
4 11.5
5 14.3
6 14.9
7 8.6
8 13.8
9 20.1
10 8.6
> r[,3]#未设置drop
[1] 7.4 8.0 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6
- mydata[2,]返回值是数据框
> mydata[2,]
x2 sumx meanx x3 NULL. x4 x5
2 5 6 3 2 2 9 9
- mydata[“V1”]返回值是数据框
> q["X"]#得到的是数据框
X
1 Mazda RX4
2 Mazda RX4 Wag
3 Datsun 710
4 Hornet 4 Drive
5 Hornet Sportabout
6 Valiant
7 Duster 360
8 Merc 240D
9 Merc 230
> q[,1]#得到的是向量
[1] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710" "Hornet 4 Drive"
[5] "Hornet Sportabout" "Valiant" "Duster 360" "Merc 240D"
[9] "Merc 230" "Merc 280" "Merc 280C" "Merc 450SE"
> r <- e[1:10,1:6]#得到的是数据框
> r
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3
4 18 313 11.5 62 5 4
5 NA NA 14.3 56 5 5
6 28 NA 14.9 66 5 6
7 23 299 8.6 65 5 7
8 19 99 13.8 59 5 8
9 8 19 20.1 61 5 9
10 NA 194 8.6 69 5 10
31.文件读取数据
| read.table | 读取表格形式数据的主要方法 |
|---|---|
| scan | 区别于read.table;1)可以创建不同的数据类型 2)指定对象类型 |
| read.fwf | 读取文件中一些固定宽度格式的数据 |
32.写入数据
| write.table | |
|---|---|
| write(x,file) |
33.警告
-
问题:
Warning message:
In readLines(file, n = thisblock) : 读’data.csv’时最后一行未遂 -
解决方法:
在程序段或原文件中最后一行加一个回车
34.expand.grid()生成规则序列
- 定义:生成数据框,并将参数各水平完全匹配
- 规律:类似三层嵌套循环结构
> expand.grid(h=c(60,80),w=c(100,300),sex=c("Male","Female"))
h w sex
1 60 100 Male
2 80 100 Male
3 60 300 Male
4 80 300 Male
5 60 100 Female
6 80 100 Female
7 60 300 Female
8 80 300 Female
#第1列: 两个值依次循环
#第2列:每个值重复一遍再往下推进
#第3列:平均分配得到每个值得重复次数,重复次数结束后再往下推进
35.泊松分布
https://blog.csdn.net/ccnt_2012/article/details/81114920
36.Lamba函数
- 即匿名函数
- 相比函数,lamba 表达式具有以下 2 个优势:
对于单行函数,使用 lambda 表达式可以省去定义函数的过程,让代码更加简洁;
对于不需要多次复用的函数,使用 lambda 表达式可以在用完之后立即释放,提高程序执行的性能。
【详见:https://www.zhihu.com/question/20125256】
37.泊松分布
rpois()
x <- ts(matrix(rpois(36,5),12,3),start = c(1961,1),frequency = 12)
> x
Series 1 Series 2 Series 3
Jan 1961 1 4 3
Feb 1961 6 5 4
Mar 1961 7 8 6
Apr 1961 10 11 7
May 1961 6 6 6
Jun 1961 7 8 3
Jul 1961 3 4 8
Aug 1961 4 3 4
Sep 1961 2 5 5
Oct 1961 9 7 7
Nov 1961 5 13 4
Dec 1961 5 5 6
rpois(36,5)#生成36个符合泊松分布的均值为5的随机值
38.对象类型转换规律

39.数学,比较,逻辑运算 运算符
y%%x y除以x求余数
y%/%x y除以x求商
40.《R for Beginner》 P25
数值型因子转换成数值型变量需要先转换成字符型再转换成数值型??
> fac3 <- factor(c(3,2,1))
> fac3
[1] 3 2 1
Levels: 1 2 3
> as.numeric(fac3)
[1] 3 2 1
> levels(fac3)
[1] "1" "2" "3"#直接转换水平值好像也没变呀??
> as.numeric(as.character(fac))#先转变成字符型,再转变成数值型,水平值也没变?
[1] 1 10
> levels(fac)
[1] "1" "10"
41.精度计算
- all.equal()
> all.equal(0.9, 1.1 - 0.2)
[1] TRUE
> all.equal(0.9, 1.1 - 0.2, tolerance = 1e-16)#此处R中得到的1.1-0.2得到的不是0.9,而是无限接近0.9的值,误差为10^-16
[1] "Mean relative difference: 1.233581e-16"#1.233581e-16大于1e-16,所以返回差异值
numeric ≥ 0. Differences smaller than tolerance are not reported. The default value is close to 1.5e-8.
2. == 返回T ; F
#返回值为T
> 0.9==1-0.1
[1] TRUE
> 2.2==(3.2-1)
[1] TRUE
> 2==(3.2-1.2)
[1] TRUE
> 2==(3-1)
[1] TRUE
> 2.0==(3-1)
[1] TRUE
> 2.0==(3.0-1.0)
[1] TRUE
#返回值为F
> 0.9==(3-2.1)
[1] FALSE
> 0.9==(1.1-0.2)
[1] FALSE
#??
> 0.9==1-0.1
[1] TRUE
> 0.9==3-2.1
[1] FALSE
42.逻辑型下标索引方式
> x <- rpois(40,lambda = 5)
> x
[1] 8 4 6 4 8 4 2 5 11 3 6 11 7 4 5 5 3 5 7 5 6 4 2 4 5 3 7 0 4
[30] 5 2 6 6 8 4 4 5 4 6 3
> x[x%%2==0]
[1] 8 4 6 4 8 4 2 6 4 6 4 2 4 0 4 2 6 6 8 4 4 4 6
#此处索引逻辑是:
x%%2==0
返回 T/F
若为T,则x[T] 返回此处的值
若为F,则x[F] 不返回此处的值
> x <- 1:40
> s <- c(F,T)
> x[s]
[1] 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40
#此处索引逻辑是:
x[s]=x[F,T,F,T...]
F不返回此处值
T返回此处值
44.数据运算函数

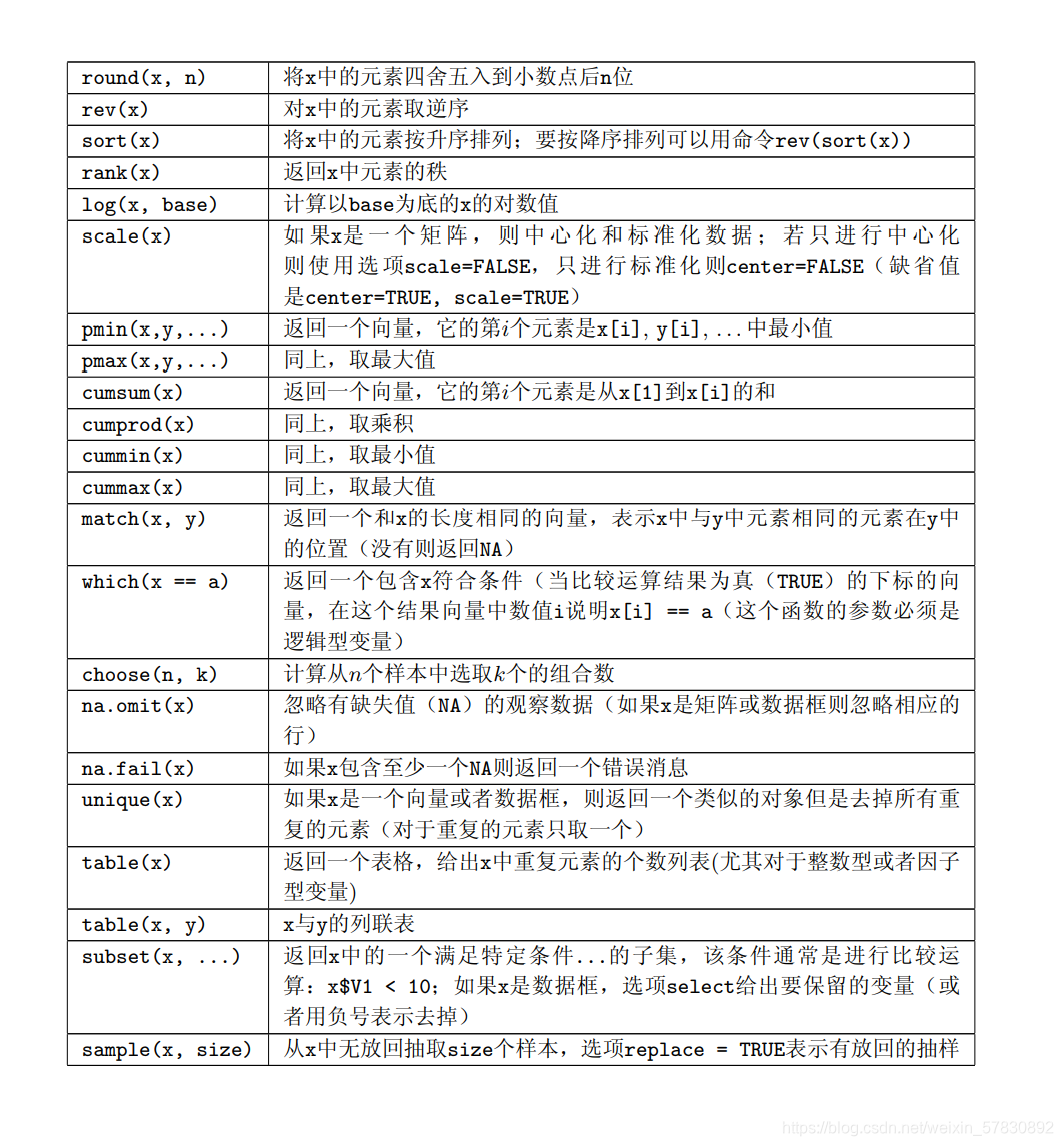
45.R Graph 报错
In doTryCatch(return(expr), name, parentenv, handler) :
invalid graphics state
没有设置plot(x,y)
46.给数据添加随机噪音?
噪声是一个测量变量中的随机错误或偏差,包括错误值或偏离期望的孤立点值。在R中可以通过调用outliers软件包中的outlier函数寻找噪声数据,该函数通过寻找数据集中与其他观测值及均值差距最大的点作为异常值。
例如在POS-bp算法中增加噪声,优点:使输出更光滑从而提升网络的推理能力,提升泛化能力。添加样本噪声,使线条更光滑。
dat<-data.frame(xvar=1:20+rnorm(20,sd=3),yvar=rnorm(20,sd=3),zvar=1:20+rnorm(20,sd=3))#+rnorm(20,sd=3);...增加随机噪音
46.包的新接口??














 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









