









1. Nueral Networks(NN)
Performing LinReg with a complex set of data with many features is very unwieldly.
100 features quadratic, 5050 resulting new features
50*50 image, n=2500, n^2/2=3125000 new features
so neural networks is applied with many features
1.1 Model Representation I
[x0x1x2] -> [a1a2a3a4 ] -> h(x)
intermediate or hidden layer nodes
ai(j) = ‘activation’ of unit i in layer j

1.2 Model Representation II
zi(j) = theta10 x0 + theta21 x1 + theta22 x2
ai(j) = g( zi(j) )
x = [x0 x1 … xn]’
z(j) = [z1(j) z2(j) … zn(j)]’ = Theta(j-1) * a(j-1)
a(j) = g( z(j) )
h(x) = a (j+1) = g( z(j+1) )

1.3 multiclass classification
change the last h(x) to h(x)1, h(x2)2, …
1.4 cost function of NN
L = total number of layers
si =number of units (not counting bias unit) in layer i
K = number of ouput units/classes
too complicated to write
1.5 backpropagation algorithm
- Gradient computation forward propagation vs. backpropagation

- backpropagation algorithm

- backpropagation intuition

1.6 implementation note: unrolling
#s1 = 10, s2=10, s3=10, s4=1
#Theta1 10*11, Theta1 10*11, Theta3 1*11
thetaVec = [Theta1(:); Theta2(:); Theta3(:)];
Theta1 = reshape(thetaVec(1:110), 10, 11);
Theta2 = reshape(thetaVec(111:220), 10, 11);
Theta3 = reshape(thetaVec(221:231), 1, 11);
1.7 Gradient Checking
in order to assure backprop. works as intended
epsilon = 1e-4;
for i = 1:n,
thetaPlus = theta;
thetaPlus(i) += epsilon;
thetaMinus = theta;
thetaMinus(i) -= epsilon;
gradApprox(i) = (J(theatPlus) - J(thetaMinus)) / (2*epsilon)
end;
#then compare gradApprox = deltaVector
1.8 Random Initialization
Initializing all theta weights to 0 does not work with NN, because backprop. will get the same value.
#s1 = 10, s2=10, s3=10, s4=1
#Theta1 10*11, Theta1 10*11, Theta3 1*11
thetaVec = [Theta1(:); Theta2(:); Theta3(:)];
Theta1 = rand(10,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
Theta2 = rand(10,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
Theta3 = rand(1,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
1.9 Putting it together
First pick a network architecture; choose the layout of your neural network, including how many hidden units in each layer and how many layers total.
Number of input units = dimension of features x(i)
Number of output units = number of classes
Number of hidden units per layer = usually more the better
If more than 1 hidden layer, then the same number of units in every hidden layer.
Training a Neural Network
- Randomly initialize the weights
- Implement forward propagation to get h(x)
- Implement the cost function
- Implement backpropagation to compute partial derivatives
- Use gradient checking to confirm that your backpropagation works. Then disable gradient checking.
- Use gradient descent or a built-in optimization function to minimize the cost function with the weights in theta.
perform forward and back propagation, loop on every training example
for i = 1:m;
Perform forward/backward prop. on every example (x(i), y(i))
Get activations a(1) and delta terms d(1) for l = 2,..., L
2 ex3
2.1 lrCostFunction
temp = theta;
temp(1) = 0;
Z = X * theta ; %here theta consist of theta0, theta1,..., thetan, total number n+1, and X shanp m * (n+1)
H = sigmoid(Z);
J = ( -y'*log(H) - (1-y)'*log(1-H)) /m + temp' * temp * lambda / m /2 ; %use temp not theta here, because theta0 does not regularize
grad = ( X'*(H-y) + temp * lambda )/m ; %again use temp to exclude theta0

2.2 oneVsAll
initial_theta = zeros(n+1, 1);
for c=1:num_labels,
options = optimset('GradObj', 'on', 'MaxIter', 50);
[theta]=...
fmincg(@(t)(lrCostFunction(t, X, (y == c), lambda)), ...
initial_theta, options);
all_theta(c, :) = theta';
end;

For some unknown reasons, my octave is stucked at this step. I reinstalled octave, but it doesn’t work. The enviroment is ubuntu20.04 on Virtualbox. Then I copied the files to my centos7 on another VM, the plot is not supported(?), but the training can go on, so that the code is OK.
At last, I downloaded ex3-octave.zip again, and unzip to ex3, it worked finally!
2.3 predictOneVsAll
[p_value, p] = max(X * all_theta',[], 2);

2.4 predict (ex3_nn)
X = [ones(m,1) X];
z2 = X * Theta1';
a2 = sigmoid(z2);
a2 = [ones(m,1) a2];
z3 = a2 * Theta2';
a3 = sigmoid(z3);
[p_value, p] = max( a3, [], 2);
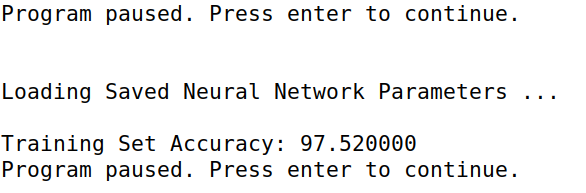
2.5 submit

3 ex4
After reinstall virtualbox ubuntu20 and Octave, the perplexing problem disappeared finally. Export Appliance as ubt20.ova.
3.1 Feddforward function with regularization
X = [ones(m,1) X];
% add x0=1 in the input layer, X: m*(input_layer_size + 1)
Z2 = X * Theta1';
% compute Z in the hidden layer
% Theta1: (hidden_layer_size)*(input_layer_size+1), Z2: m*(hidden_layer_size + 1)
A2 = sigmoid(Z2); % compute A2
A2 = [ones(m,1) A2]; % add a20=1 in the hidden layer, A2: m*(hidden_layer_size + 1)
Z3 = A2 * Theta2'; %compute Z in the output layer
% Theta2: (output_layer_size)*(hidden_layer_size + 1), Z3: m*(output_layer_size)
% output_layer_size==num_labels
H = sigmoid(Z3);
% change y to Y
Y = zeros(m, num_labels);
for i=1:m
Y(i, y(i)) = 1;
end
%
J = sum( sum( -Y .* log(H) - (1-Y) .* log(1-H)) ) /m;
Theta1_temp = Theta1;
Theta1_temp(:,1) = 0; //exclude theta0
Theta2_temp = Theta2;
Theta2_temp(:,1) = 0; //exclude theta0
Theta1_sum = Theta1_temp .* Theta1_temp;
Theta2_sum = Theta2_temp .* Theta2_temp;
Theta_sum = (sum(Theta1_sum(:)) + sum(Theta2_sum(:))) * lambda / m /2
J = J + Theta_sum;
3.2 Backpropagation
for t = 1:m,
a1 = X(t, :); % a1-> 1*(N1+1), since x0 has been added in the feeforward part
% a1 = [1; a1]; % a1-> 1*(N1+1)
z2 = a1 * Theta1'; % z2-> 1*N2
a2 = sigmoid(z2); % a2-> 1*N2
a2 = [1, a2]; % a2->1*(N2+1)
z3 = a2 * Theta2'; % z3->1*N3
a3 = sigmoid(z3); % a3->1*N3
%step1
delta3 = a3 - Y(t, :); % delta3->1*N3
%step2
delta2 = delta3 * Theta2; % delta2->1*(N2+1)
delta2 = delta2(2:end); %delta2->1*N2
%setp3
delta2 = delta2 .* sigmoidGradient(z2);
%step4
Theta1_grad += delta2' * a1 ; % N2*(N1+1)
Theta2_grad += delta3' * a2 ; % N3*(N2+1)
end
Theta1_grad = Theta1_grad / m + (lambda/m) * Theta1_temp;
% exclude j=0, use the parameters in the feeforward part
Theta2_grad = Theta2_grad / m + (lambda/m) * Theta2_temp;
% exclude j=0, use the parameters in the feeforward part
3.3 submit
















 690
690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









