









1. assignment 4
1.1 data cleaning
import pandas as pd
import numpy as np
import re
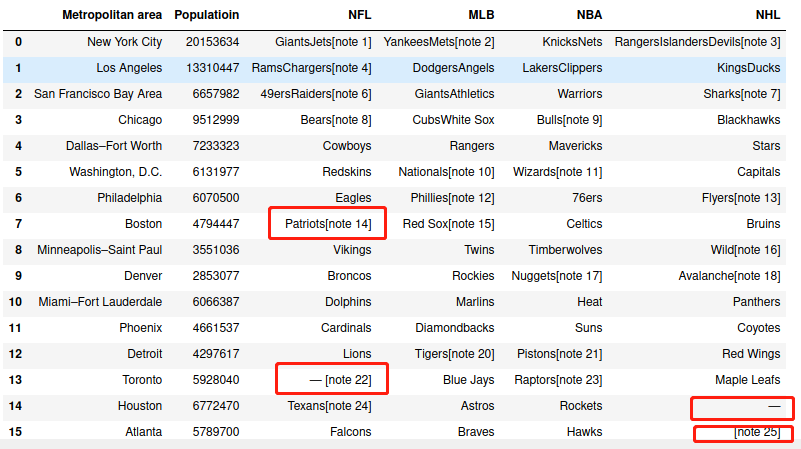
cities=pd.read_html("assets/wikipedia_data.html")[1]
cities=cities.iloc[:-1,[0,3,5,6,7,8]]
cities = cities.rename(columns = {'Population (2016 est.)[8]':'Populatioin'})
def str_clean(str_series):
if re.search('\—.*', str_series):
str_series = np.NaN #replace('—', np.NaN) seems not work well
elif re.search('\[.*]', str_series):
pos = re.search('\[.*]', str_series).start()
if pos == 0:
str_series = np.NaN
else:
str_series = str_series[:pos]
return str_series
for team in {'NFL','MLB','NBA','NHL'}:
cities[team] = new_cities[team].apply(str_clean)

another method to replace ‘abc 123[def 345]’ with ‘abc 123’
pat = "(?P<name>\w*)(?P<cmt>\[\w.*])"
repl = lambda m: m.group('name')
str_series = str_series.str.replace(pat, repl, regex=True)
1.2 NHL correlation
1.2.1 read data
nhl_df=pd.read_csv("assets/nhl.csv")
cities=pd.read_html("assets/wikipedia_data.html")[1]
cities=cities.iloc[:-1,[0,3,5,6,7,8]]

cities = cities.rename(columns = {'Population (2016 est.)[8]':'Populatioin'})
1.2.2 clean the string
def str_clean(str_series):
if re.search('\—.*', str_series):
str_series = np.NaN #replace '—' with NaN
elif re.search('\[.*]', str_series):
pos = re.search('\[.*]', str_series).start()
if pos == 0:
str_series = np.NaN #some cell is like '[kkk]'
else:
str_series = str_series[:pos] #truncate '['and the right string
return str_series
clr_cities = cities
for team in {'NFL','MLB','NBA','NHL'}:
clr_cities[team] = clr_cities[team].apply(str_clean)

1.2.3 clean nhl and other dataframe string
two dataframes have differnt expression, so …
nhl_cities = clr_cities
nhl_cities['NHL_com']=nhl_cities['NHL'].str.replace('.*\s','')

adjust nhl_df
nhl_df['team']=nhl_df['team'].str.strip('*') #some nhl.df['team'] cell has '*'
nhl_df = nhl_df[nhl_df['year']== 2018]
nhl_df['team']=nhl_df['team'].str.replace('.*\s','') #keep only the last name
nfl_df['team']=nfl_df['team'].str.strip('*+')
nba_df['team']=nba_df['team'].str.replace(r'\*.*','')
nba_df['team']=nba_df['team'].str.replace(r'\xa0.*','')
print(nhl_df.sort_values(by='team')[['team','W','L']])

1.2.4 join together
last_cities = nhl_cities.set_index('NHL_com').join(nhl_df.set_index('team'))
last_cities['W'] = last_cities['W'].replace(np.nan, 0, regex=True) #before computing the ratio
last_cities['L'] = last_cities['L'].replace(np.nan, 0, regex=True) #before computing the ratio
last_cities['W/L ratio'] = last_cities['W'].astype(int)/last_cities['L'].astype(int)
last_cities.at['KingsDucks','W/L ratio'] = 1.648148 #compute manualy and replace
last_cities.at['RangersIslandersDevils','W/L ratio'] = 1.076191 #compute manualy and replace
last_cities = last_cities[['Metropolitan area','Populatioin','W/L ratio']].dropna().sort_values(by='Metropolitan area')
print(last_cities)

1.2.5 output to a plot
last_cities.to_csv('cities.csv') #the current directory of jupyter
output csv file, draw a plot in excel
















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









