







目录
LESSON 1 线性模型
代码说明:1、函数forward()中,有一个变量w。这个变量最终的值是从for循环中传入的。
2、for循环中,使用了np.arange。
3、python中zip()函数的用法
import numpy as np
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
def forward(x):
return x*w
def loss(x,y):
y_pred = forward(x)
return (y_pred-y) **2
w_list=[]
mse_list=[]
for w in np.arange(0.0,4.1,0.1):
w_list.append(w)
l_sum = 0
for x,y in zip(x_data,y_data):
y_pre = forward(x)
loss_val=loss(x,y)
l_sum += loss_val
mse_list.append(l_sum/3)
plt.plot(w_list,mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()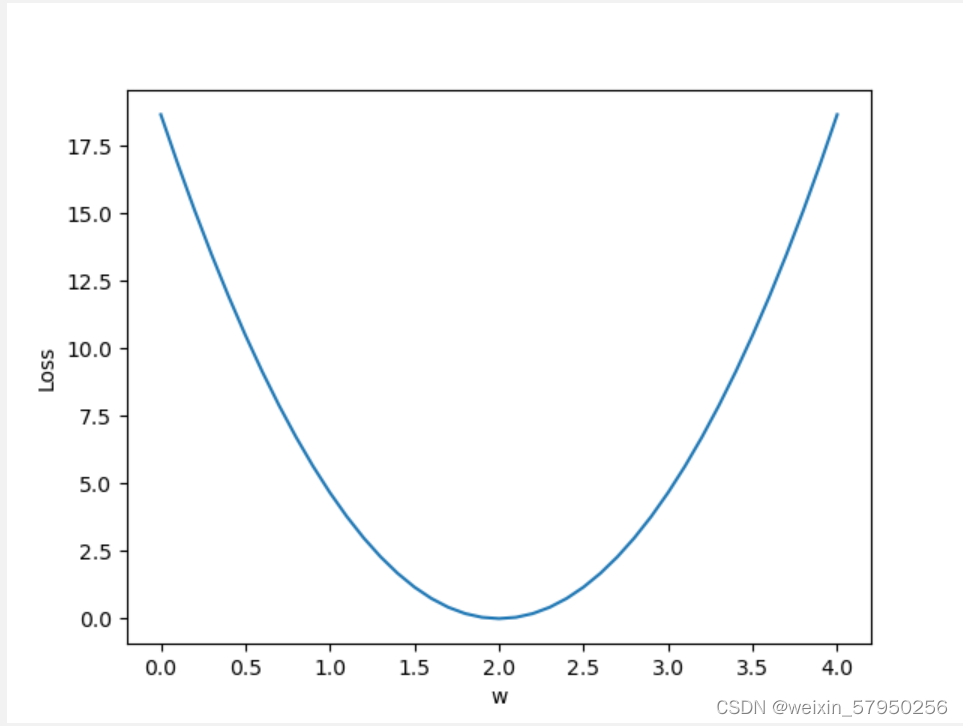
作业:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
# y = x*2.5-1 构造训练数据
x_data = [1.0, 2.0, 3.0]
y_data = [1.5, 4.0, 6.5]
W, B = np.arange(0.0, 4.1, 0.1), np.arange(-2.0, 2.1, 0.1) # 规定 W,B 的区间
w, b = np.meshgrid(W, B, indexing='ij') # 构建矩阵坐标
def forward(x):
return x * w + b
def loss(y_pred, y):
return (y_pred - y) * (y_pred - y)
# Make data.
mse_lst = []
l_sum = 0.
for x_val, y_val in zip(x_data, y_data):
y_pred_val = forward(x_val)
loss_val = loss(y_pred_val, y_val)
l_sum += loss_val
mse_lst.append(l_sum / 3)
# 定义figure
fig = plt.figure(figsize=(10, 10), dpi=300)
# 将figure变为3d
ax = Axes3D(fig,auto_add_to_figure=False)
fig.add_axes(ax)
# 绘图,rstride:行之间的跨度 cstride:列之间的跨度
surf = ax.plot_surface(w, b, np.array(mse_lst[0]), rstride=1, cstride=1, cmap=cm.coolwarm, linewidth=0,
antialiased=False)
# Customize the z axis.
ax.set_zlim(0, 40)
# 设置坐标轴标签
ax.set_xlabel("w")
ax.set_ylabel("b")
ax.set_zlabel("loss")
ax.text(0.2, 2, 43, "Cost Value", color='black')
# Add a color bar which maps values to colors.
fig.colorbar(surf, shrink=0.5, aspect=5)
plt.show()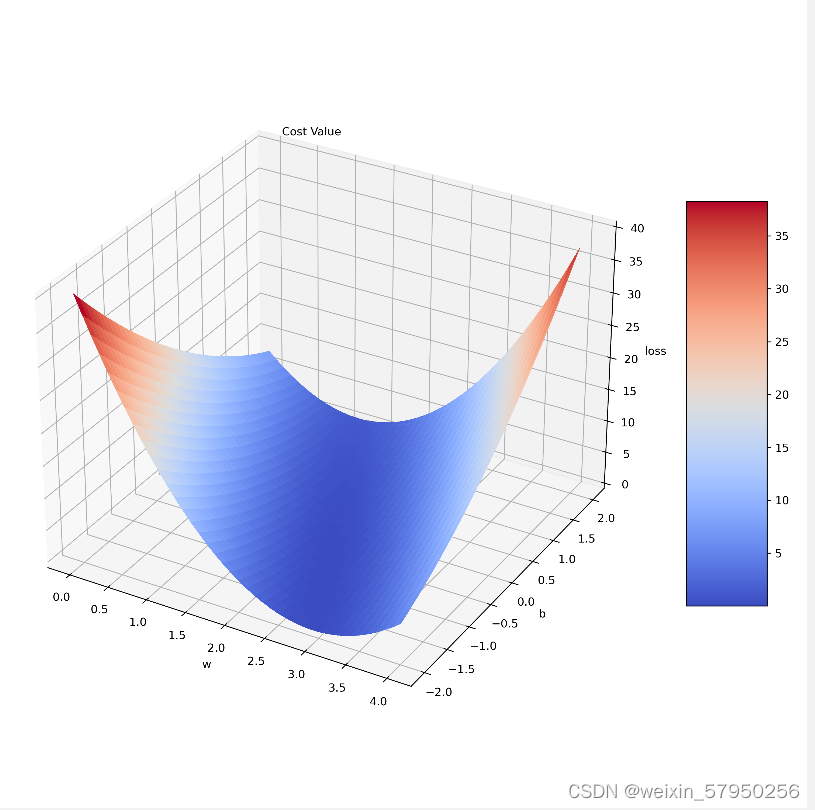
LESSON 2 梯度下降
梯度下降
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [1.5, 4.0, 6.5]
w = 1.0
epoch_list = []
cost_list = []
def forward(x):
return x * w
def cost(x_data, y_data):
cost_ans = 0
for x,y in zip(x_data,y_data):
y_pre = forward(x)
cost_ans += (y_pre - y) ** 2
return cost_ans / len(x_data)
def gradient(x_data, y_data):
grad = 0
for x,y in zip(x_data,y_data):
grad += 2 * x * (x * w - y)
return grad / len(x_data)
for epoch in range(100):
loss = cost(x_data, y_data)
w -= 0.01 * gradient(x_data,y_data)
print('epoch:', epoch, 'w=', w, 'loss=', loss)
epoch_list.append(epoch)
cost_list.append(loss)
print('predict (after training)', 4, forward(4))
plt.plot(epoch_list,cost_list)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.show()
结果
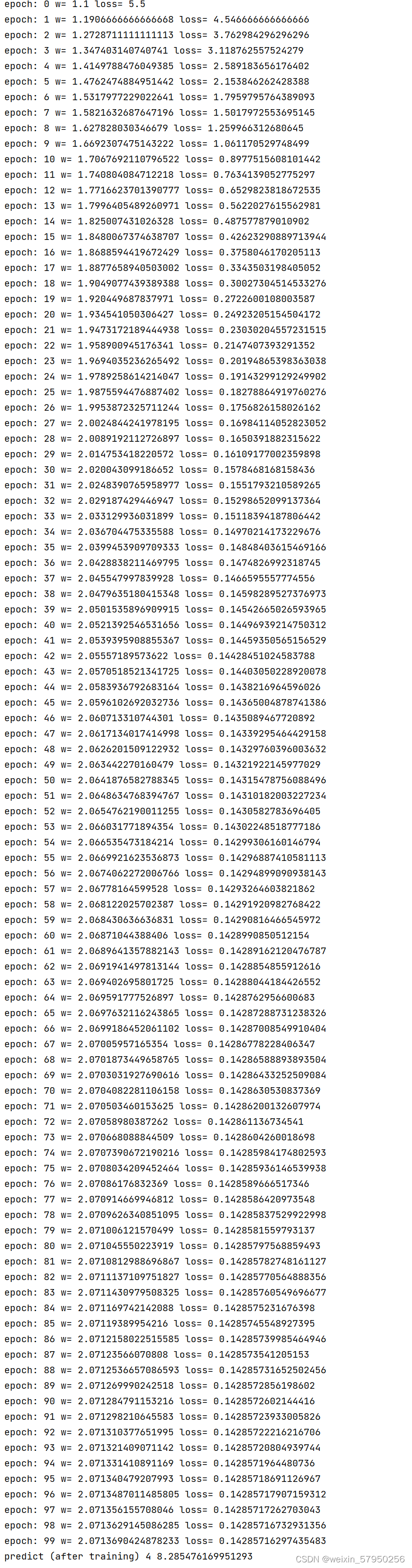
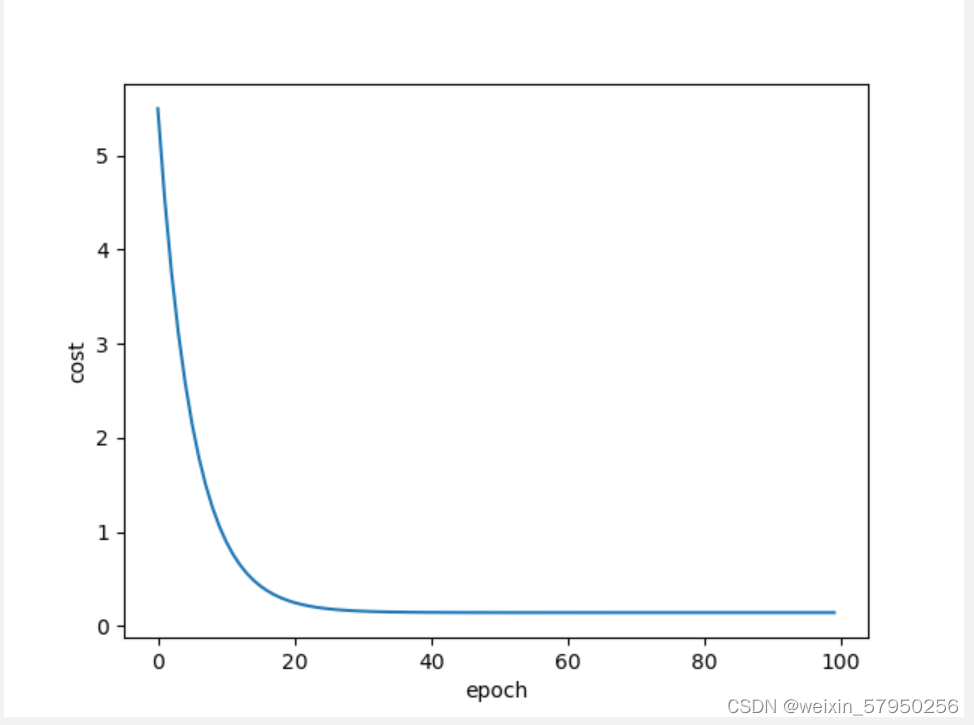
LESSON 3 随机梯度下降
随机梯度下降法
随机梯度下降法在神经网络中被证明是有效的。效率较低(时间复杂度较高),学习性能较好。
随机梯度下降法和梯度下降法的主要区别在于:
1、损失函数由cost()更改为loss()。cost是计算所有训练数据的损失,loss是计算一个训练数据的损失。对应于源代码则是少了两个for循环。
2、梯度函数gradient()由计算所有训练数据的梯度更改为计算一个训练数据的梯度。
3、本算法中的随机梯度主要是指,每次拿一个训练数据来训练,然后更新梯度参数。本算法中梯度总共更新100(epoch)x3 = 300次。梯度下降法中梯度总共更新100(epoch)次。
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [1.5, 4.0, 6.5]
w = 1.0
epoch_list = []
loss_list = []
def forward(x):
return x * w
def loss(x, y):
y_pre = forward(x)
return (y_pre - y) ** 2
def gradient(x, y):
return 2 * x *(x * w - y)
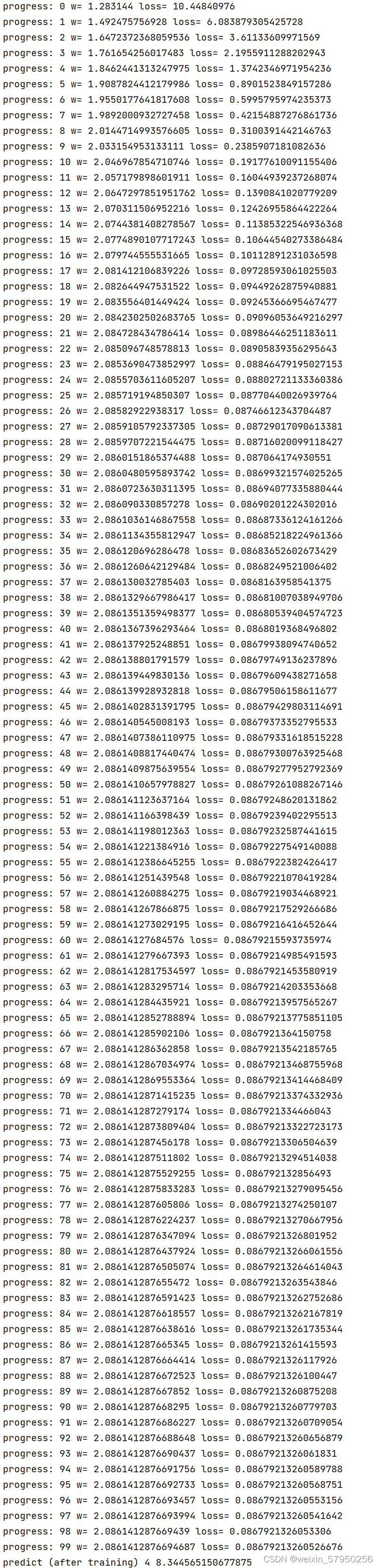
for epoch in range(100):
for x,y in zip(x_data, y_data):
l = loss(x, y)
w -= 0.01 * gradient(x, y)
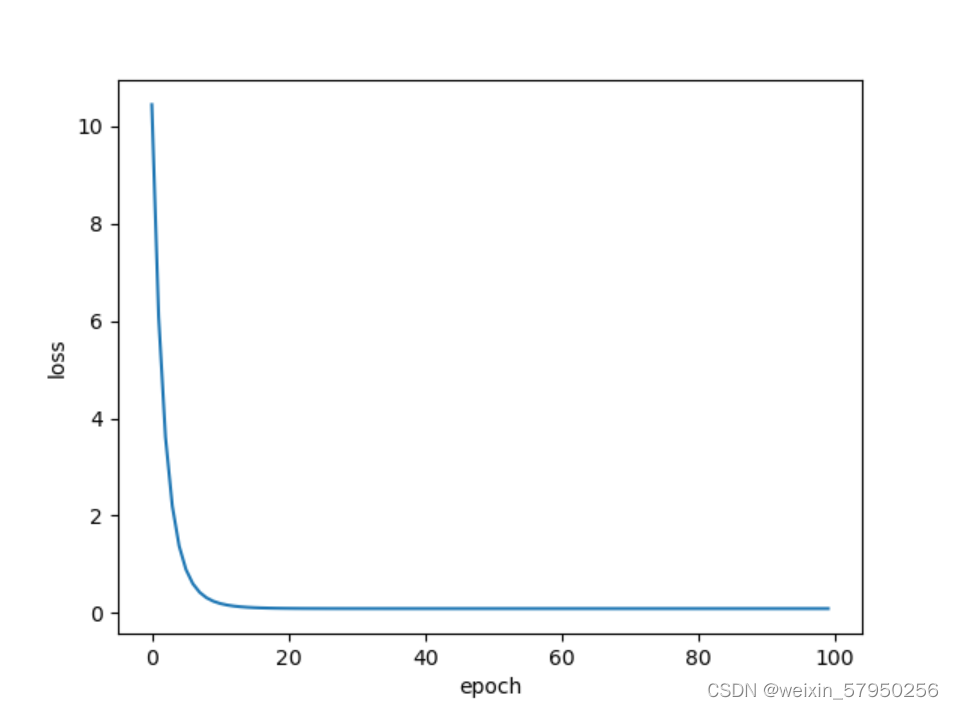
print("progress:", epoch, "w=", w, "loss=", l)
epoch_list.append(epoch)
loss_list.append(l)
print('predict (after training)', 4, forward(4))
plt.plot(epoch_list,loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
实验结果
LESSON 4 反向传播
1、w是Tensor(张量类型),Tensor中包含data和grad,data和grad也是Tensor。grad初始为None,调用l.backward()方法后w.grad为Tensor,故更新w.data时需使用w.grad.data。如果w需要计算梯度,那构建的计算图中,跟w相关的tensor都默认需要计算梯度。
刘老师视频中a = torch.Tensor([1.0]) 本文中更改为 a = torch.tensor([1.0])。两种方法都可以
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [1.5, 4.0, 6.5]
w = torch.Tensor([1.0])
w.requires_grad = True
def forward(x):
return x * w
def loss(x,y):
y_pre = forward(x)
return (y_pre - y)** 2
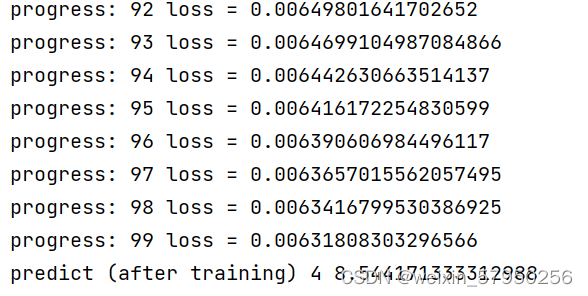
for epoch in range(100):
for x,y in zip(x_data,y_data):
l = loss(x,y)
l.backward()
w.data = w.data - 0.01 * w.grad.data
w.grad.data.zero_()
print('progress:', epoch, 'loss =',l.item())
print("predict (after training)", 4, forward(4).item())实验结果

作业
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w1 = torch.Tensor([1.0])
w1.requires_grad = True
w2 = torch.Tensor([1.0])
w2.requires_grad = True
b = torch.Tensor([1.0])
b.requires_grad = True
def forward(x):
return x * x * w1 + x * w2 + b
def loss(x,y):
y_pre = forward(x)
return (y_pre - y)** 2
for epoch in range(100):
for x,y in zip(x_data,y_data):
l = loss(x,y)
l.backward()
w1.data = w1.data - 0.01 * w1.grad.data
w2.data = w2.data - 0.01 * w2.grad.data
b.data = b.data - 0.01 * b.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
b.grad.data.zero_()
print('progress:', epoch, 'loss =',l.item())
print("predict (after training)", 4, forward(4).item())实验结果
LESSON 5 Pytorch实现线性回归
PyTorch Fashion(风格)
1、prepare dataset
2、design model using Class # 目的是为了前向传播forward,即计算y hat(预测值)
3、Construct loss and optimizer (using PyTorch API) 其中,计算loss是为了进行反向传播,optimizer是为了更新梯度。
4、Training cycle (forward,backward,update)
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.tensor([[2.0], [4.0], [6.0]])
class LinearModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self,x):
y_pre = self.linear(x)
return y_pre
model = LinearModule()
l = torch.nn.MSELoss(reduction = 'sum')
optimizer = torch.optim.SGD(model.parameters(),0.01)
for epoch in range(100):
y_pre = model(x_data)
loss = l(y_pre,y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









