







 论文介绍了Flownet,一种使用卷积神经网络解决光学流预测问题的方法。通过构建大规模合成数据集FlyingChairs,研究了网络结构、训练策略,并展示了在各种数据集上的性能。FlownetCorr网络包含关联层,对于训练数据集相似的场景表现更好。
论文介绍了Flownet,一种使用卷积神经网络解决光学流预测问题的方法。通过构建大规模合成数据集FlyingChairs,研究了网络结构、训练策略,并展示了在各种数据集上的性能。FlownetCorr网络包含关联层,对于训练数据集相似的场景表现更好。
Flownet: 用卷积神经网络学习光流法
目录
光流原理
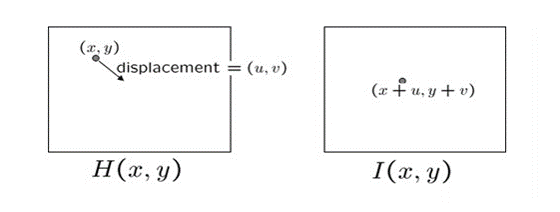
光流法,简单来说, 是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。
光流实现的假设前提:
- 相邻帧之间的亮度恒定。
- 相邻视频帧的取帧时间连续,或者,相邻帧之间物体的运动比较“微小”。
- 保持空间一致性;即,同一子图像的像素点具有相同的运动。
因为光流的预测涉及到每个像素点的精确的位置信息,这不仅涉及到图像的特征,还涉及到两个图片之间对应像素点的联系,所以用于光流预测的神经网络与之前的神经网络不同。
光流场是图片中每个像素都有一个x方向和y方向的位移,所以在上面那些光流计算结束后得到的光流flow是个和原来图像大小相等的双通道图像。不同颜色表示不同的运动方向,深浅表示运动的速度。

x和y转为极坐标,夹角(actan2(y,x))代表方向,极径(x和y的平方和开根号)代表位移大小,刚好用一下hsv的图像表示。上图的光流可以看到,红色的人在往右边动,那个蓝色的东西在往左上动

Abstract
以监督学习的方式构建了一个CNN用来解决光流估计问题。提出并比较了两种架构:一种是通用的架构,另一种则包含了一层不同图像位置特征向量关联层。
当前的GT数据集的规模不够用来训练一个CNN,本文构建了一个大规模的合成数据集Flying Chairs dataset。证明了在这个合成的数据集上训练的网络,仍然可以在其他数据集比如Sintel和KITTI上得到很好的效果,以帧率5到10FPS实现了富有竞争力的准确率。
(把一般的卷积神经网络去掉全连接层,改成两个网络,一种是比较一般普通的全是卷积层的神经网络,另一个除了卷积层之外还包括一个关联层。并且对这两种网络分别进行点对点的训练,使网络能从一对图片中预测光流场,每秒达到5到10帧率,并且准确率也达到了业界标准。)
1. 介绍
光流估计除了需要精确地像素级定位外,还需要在两张输入图片中进行特征匹配。这要求不仅仅需要对图像特征表示进行学习,还需要在两张图片中将不同位置的特征匹配起来。在这方面,光流估计与先前的CNNs应用有本质区别。
- 自制了非现实场景的飞椅(Flying Chairs)数据集,发现在非现实场景下训练的网络可以很好的推广到真实场景数据集。
- 用自制数据集(Flying Chairs)端到端训练光流网络。
- 因为光流估计涉及到相邻帧间的位置关系,不确定传统的CNN能否完成任务,所以提出并比较了两种网络,一种是通用架构,一种是包含一层网络,把不同图像位置的特征向量连接起来。
2. 网络架构
采用了一种端对端的学习方法来预测光流:给定一个包含图像对和GT光流的数据集,我们训练了一个神经网络直接从图像中预测 x − y 光流场。
最大池化层导致分辨率的降低,为了提供逐像素预测,需要重新细化粗糙的池化表示。给网络加了个扩展部分refine-ment,可以得到高分辨率的流场。神经网络包含了比较和扩展模块被作为一个整体来进行反向传播。
两个神经网络的整体思路:
首先有一个收缩部分,主要由卷积层组成,用于深度的提取两个图片的一些特征。但是pooling会使图片的分辨率降低,为了提供一个密集的光流预测,他们增加了一个扩大层,能智能的把光流恢复到高像素。用back progation 对这整个网络进行训练。
Figure 2. 两种网络架构:FlownetSimple(top)和FlowNetCorr(bottom)。
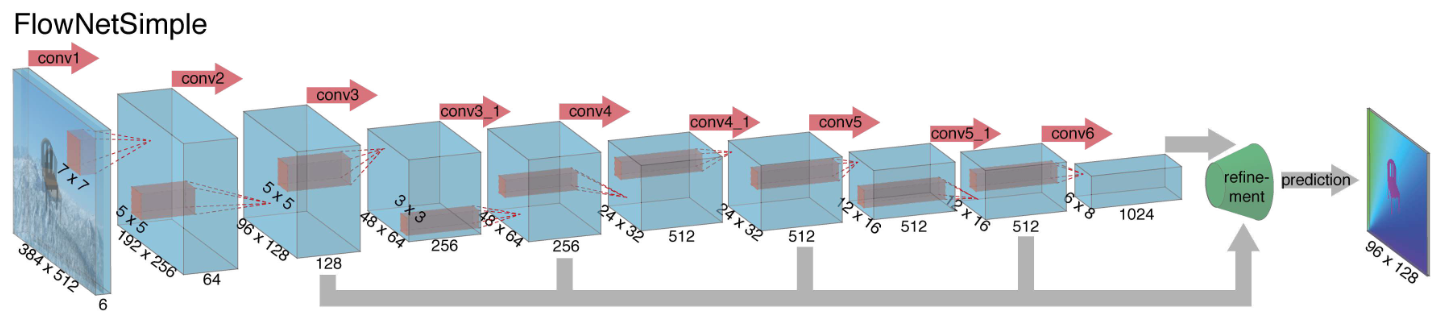
FlowNetSimple:一个stage的方法是,将两个输入图像叠加在一起,输入通用的网络模型,让网络自己学习处理图像对并提取运动信息。只包含卷积层。
这种卷积网络有九个卷积层,其中的六个stride为2, 每一层后面还有一个非线性的relu操作,这一网络没有全连接层,所以这个网络不能够把任意大小的图片作为输入,卷积filter随着卷积的深入递减,第一个7*7,接下来两个5*5,之后是3*3,feature map因为stride是2,每层递增两倍。
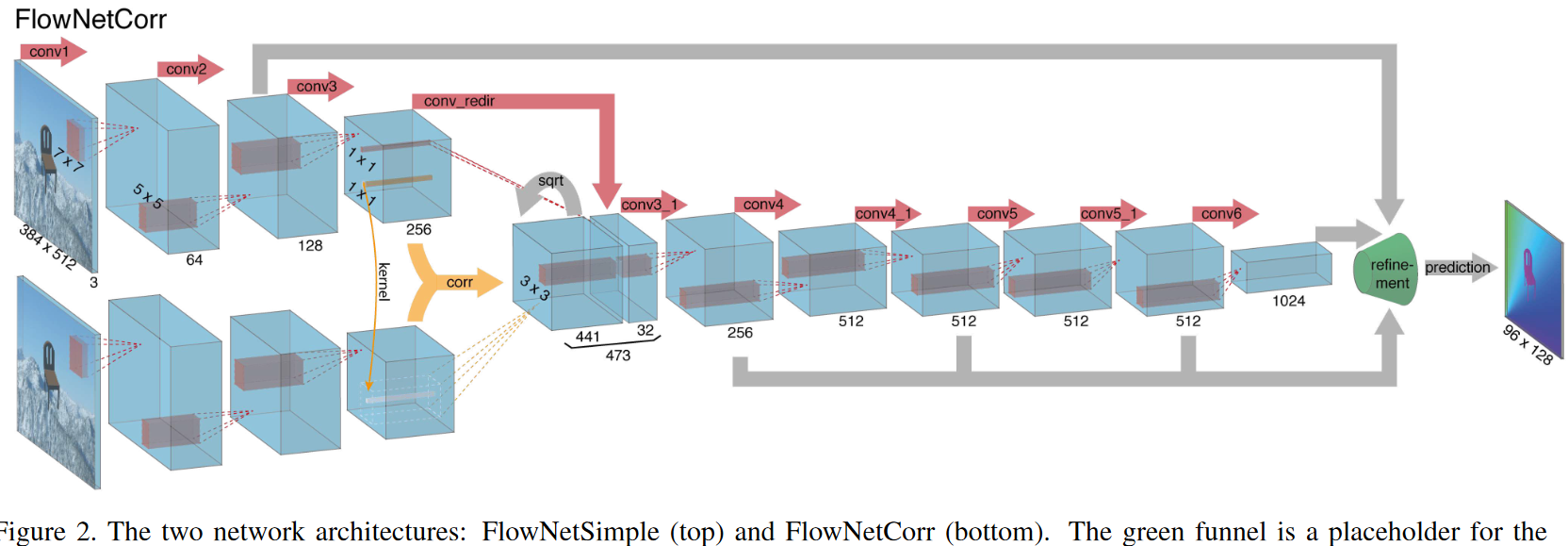
FlowNetCorr:两个stage的方法是,构建两个分开的、相同的特征提取模块,参数一致,用来处理两张输入图像,分别产生有意义的表示,后面添加一个步骤把它们结合起来,将处理后的输出作为stage2的输入,stage2匹配stage1的输出特征,计算运动信息。这种做法像标准的匹配方法:首先从图像对中的块中提取特征然后再比较它们的特征向量。但是,给定两张图像的特征表示,网络该如何进行特征匹配呢?
refine-ment:是为扩展细化模块所预留的位置,这在Fig 3中展示出来了。包含细化模块的神经网络被端对端的训练。
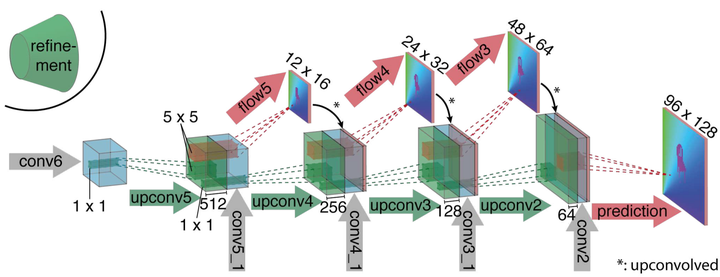
Figure 3. 特征图从粗糙细化为高分辨率。
2.1. Contracting part
为了帮助FlowNetCorr网络找到对应关系(给定两张图像的特征表示,网络进行特征匹配)引入correlation layer,可以在两个特征图间执行乘法块比较(multiplicative patch comparisons)。
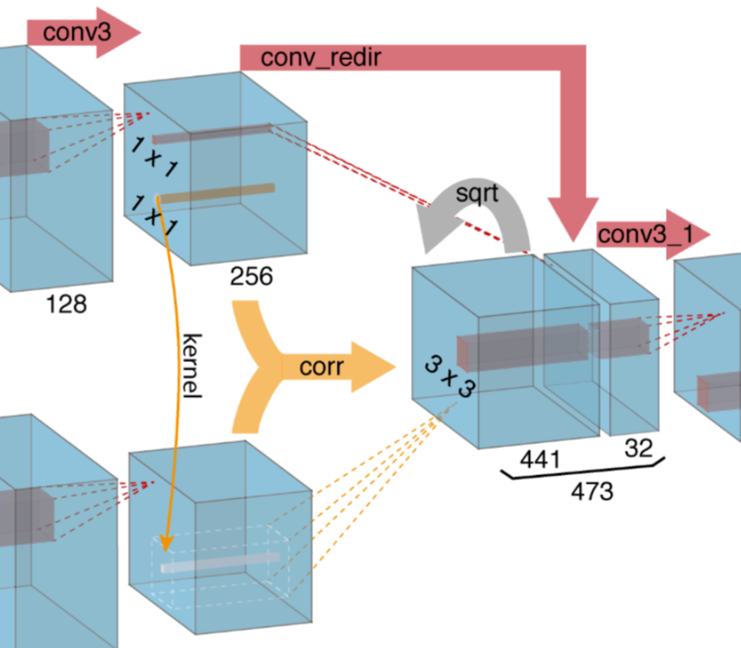
给定两个多通道的特征图f1和f2,两个特征图的尺寸都为(w,h,c),关联层使网络可以比较f1和f2之间的每个小块(patch)。考虑两个小块之间单独的比较。第一个特征图中的小块中心记为x1,第二个特征图中的小块中心记为x2,两个小块之间的关联(correlation)可以定义为:
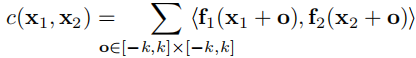
相当于两个patch之间做卷积。计算 c(x1,x2) 需要cK^2的计算量,所以设定最大位移量d和步长s。最大位移量d对每个x1,限制x2的范围,只在size D:=2d+1 的邻域内计算correlation。s1:用来设定x1在图片上的挪动步长。s2:用来设定在x1的限制下,x2的挪动步长。
一个patch的边长为 K:=2k+1。相当于一个卷积步骤。但是不同于采用滤波器来进行卷积,这里是用一批数据对另一批数据进行卷积,因此这里没有可以训练的权重。
(即,从第二个特征图中拿出一个小块作为卷积,然后把它覆盖第一个特征图的一个小块上做加权求和,对每个通道都做这样的操作,然后再把每个通道上的值相加,最后得到一个总和。这个过程和一般的卷积非常相像,唯一区别就是卷积核的参数是固定的,即没有可以训练的权重)
计算c(x1,x2)包括了c⋅K^2次乘法。由于特征图 f1 的所有小块将会分别和 f2 上的所有小块分别做上面的比较结合,所以共有 w^2 * h^2 次计算。为了计算量考虑,限制了最大的比较偏移量,同时在特征图对中引入了步幅s。给定最大的偏移量 d,对于第一个特征图中每个 x1 的位置,只在一个尺寸为 D:=2d+1 的邻域内计算关联c(x1,x2),从而限制了 x2 的范围。采用步幅 s1 和 s2 来全局量化 x1 和以 x1 为中心的邻域内的 x2。
(原来的操作是,对于两个特征图,都会从以每个像素为中心裁剪出一个小块,也就是wh个小块,第一个特征图中的每个小块都会和第二个特征图中的每个小块进行关联计算,每个关联计算都会产生一个标量值。总共w * h * w * h次计算。但是每个小块上的像素只可能在运动中偏移到其领域,不可能跑的非常远,所以两个距离非常远的小块的关联计算是没有必要的。因此对于第一个特征图上的某个小块,我们不再把它和第二个特征图上所有小块进行关联计算,而只是把它和第二个特征图上对应位置附近的小块进行计算,小块的中心分布在以D为边长的正方形内,总共有D*D个小块。由此,关联计算的次数锐减为w * h * D^2。对应到Fig 2 中,得到的输出特征图为w * h * 441,因此可以知道D=21。)
2.2. Expanding part
扩展层的主要组成是“上卷积层”(upconvolution),其中包含了“反池化层”(unpooling)(用以扩展特征图,与池化层正好相反)和一个卷积层。上卷积层进行细化,并且把它和来自比较模块的对应特征图,以及前面的上采样粗糙流场估计拼接在一起。 通过这种方式,我们同时保存了来自粗糙特征图的高层信息(指的是来自上一个特征图以及粗糙光流的信息)和来自低层特征图的细微局部信息(指的是比较模块那里来的特征图)。每个步骤将分辨率提高了两倍。重复该步骤四次,但分辨率仍然比输入图像更小。发现更加深入的细化对效果的提升很少,但是计算量消耗却比较大,还不如直接利用双线性差值来上采样为完全的输入图像的分辨率。
总结:
- 这部分是想要在网络上添加一个模块,提高输出分辨率。主要成分是upconvolutional,包括unpooling和convolution.
- 对特征图进行上卷积,与contract part的特征图和粗粒度的光流预测的上采样的特征图相互联系起来。
- 联系起来的目的是,CNN深层的感受野大,浅层的感受野小,将深层的coarse map提供的信息和浅层提供的local信息结合起来
- 结果表明,没什么用,不如双线性插值。
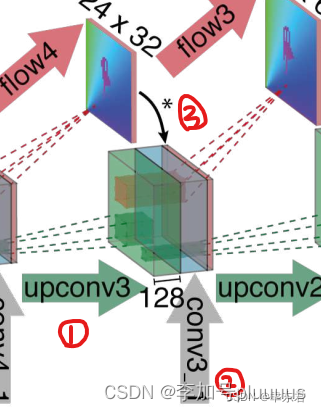
(可以看到某一层的输入特征图是由三部分组成的,即前一层特征图的上卷积+比较模块中同样尺寸的特征图+前一层特征图的预测流场的上卷积。由于前一层特征图的预测流场的大小小于本层特征图,所以也用上卷积处理了一下,也就是*号的操作)
2.3. Variational refifinement 变分细化

Figure 4. 变分细化的作用。第一行中运动是比较小的,经过变分细化后流场变化是比较大的。第二行中,运动更大一些,变分细化并不能消除大的误差,但是流场更加平滑了,也可以使得EPE降低。
另一种选择是,最后一个步骤中,不采用双线性插值,而是用论文Large displacement optical flow: descriptor matching in variational motion estimation中的不带匹配项的变分方法:一开始流场的分辨率只有输入图像的四分之一,把由粗到细的的方法迭代了20遍使得流场达到全分辨率。最后,在全分辨率的流场上再迭代多五次。用Efficient closed-form solution to generalized boundary detection中的方法额外地检测图像边缘,并且通过替代光滑系数的方法来respect检测出来的边缘,即:
![]() 其中 b(x,y)表示细边缘强度。
其中 b(x,y)表示细边缘强度。
总结:
- 目的:为了提高预测的分辨率,相当于做上采样。
- 构成:4层反卷积加ReLU激活函数层。
- 三块输入结合:在细化过程中,每层网络的通道由三个部分组成,1)前一层的upconv,2)前一层预测的低分辨率的光流,3)前面contract layer中相应的层。这样使得反卷积在细化时,不仅可以获得深层的感受野大的抽象信息,也可以获得浅层的,拥有小感受野的局部信息,从而弥补因为网络加深而损失的细节信息。
3. 训练数据
不像传统的方法,神经网络需要带有真实值的数据,不仅仅是用来优化参数,也是为了从零训练该任务。通常来讲,获得这种真实值是非常难的,因为在真实世界场景中准确的像素关联并不容易解出。当前可获得的数据集在Table 1中给出了。
4.1 Existing Datasets
使用了四种数据集,前三种是目前比较常见的训练光流所用的数据集,flying chairs是文章自己创建的数据集。其中:
Middlebury数据集:用于训练的图片对只有8对,从图片对中提取出的,用于训练光流的ground truth用四种不同的技术生成,位移很小,通常小于10个像素。
Kitti数据集:有194个用于训练的图片对,但只有一种特殊的动作类型(类似行车记录仪?),并且位移很大,视频使用一个摄像头和ground truth由3D激光扫描器得出,远距离的物体,如天空没法被捕捉,导致他的光溜ground truth比较稀疏。
Mpi sintel数据集:是从人工生成的动画sintel中提取训练需要的光流ground truth,是目前最大的数据集,每一个版本都包含1041个可一用来训练的图片对,提供的gt十分密集,大幅度,小幅度的运动都包含。
sintel数据集包括两种版本:
sintel final:包括运动模糊和一些环境氛围特效,如雾等。
sintel clean:没有上述final的特效。
现在的这些数据集在物体和运动特征上都不相同,为了增加正确率,我们针不同的数据集对网络进行优化,相关的优化方法就是fine-tunning,记为+ft。用于训练大规模的cnns,sintel的dataset依然不够大,所以作者他们自己弄出来一个flying chairs数据集。
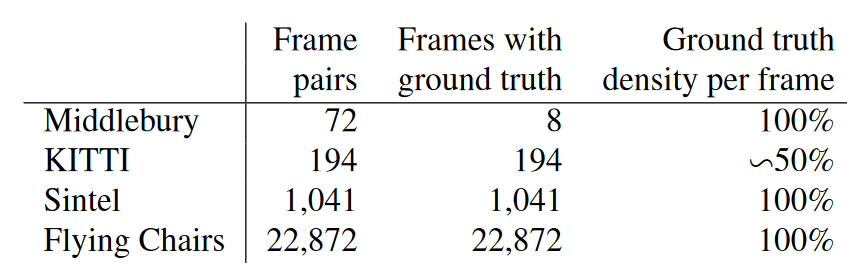
Table 1. 当前的数据集的规模和本文提出的Flying Chair数据集
4.2 Flying Chairs
已有的光流估计数据库不够大,为解决这个问题,通过将椅子的3D模型随机的覆盖在一些图像上,做成合成图像。在对椅子和背景分别做随机的仿射变化,从而获得带有光流真值的图像对。

Figure 5. Flying Chairs. 生成的图像对和颜色编码的流场(前三列),增强的图像对以及对象的颜色编码流场(后三列)。色调代表方向,强度代表大小。
4.3 Data Augmentation(数据增强)
使用的增强方法包括集和变换:平移、旋转和缩放,以及额外的高斯噪声和亮度、对比度、伽马矫正和颜色方面的变换。
4. 实验结果

三种光流预测方法在飞椅子数据集上预测的表现
其中:EPE是一种对光流预测错误率的一种评估方式。
指所有像素点的gound truth和预测出来的光流之间差别距离(欧氏距离)的平均值。可以看见Epicflow 这个很好的预测方法,但在一些大位移的情况下会找不到光流,而两种flownet好于它。
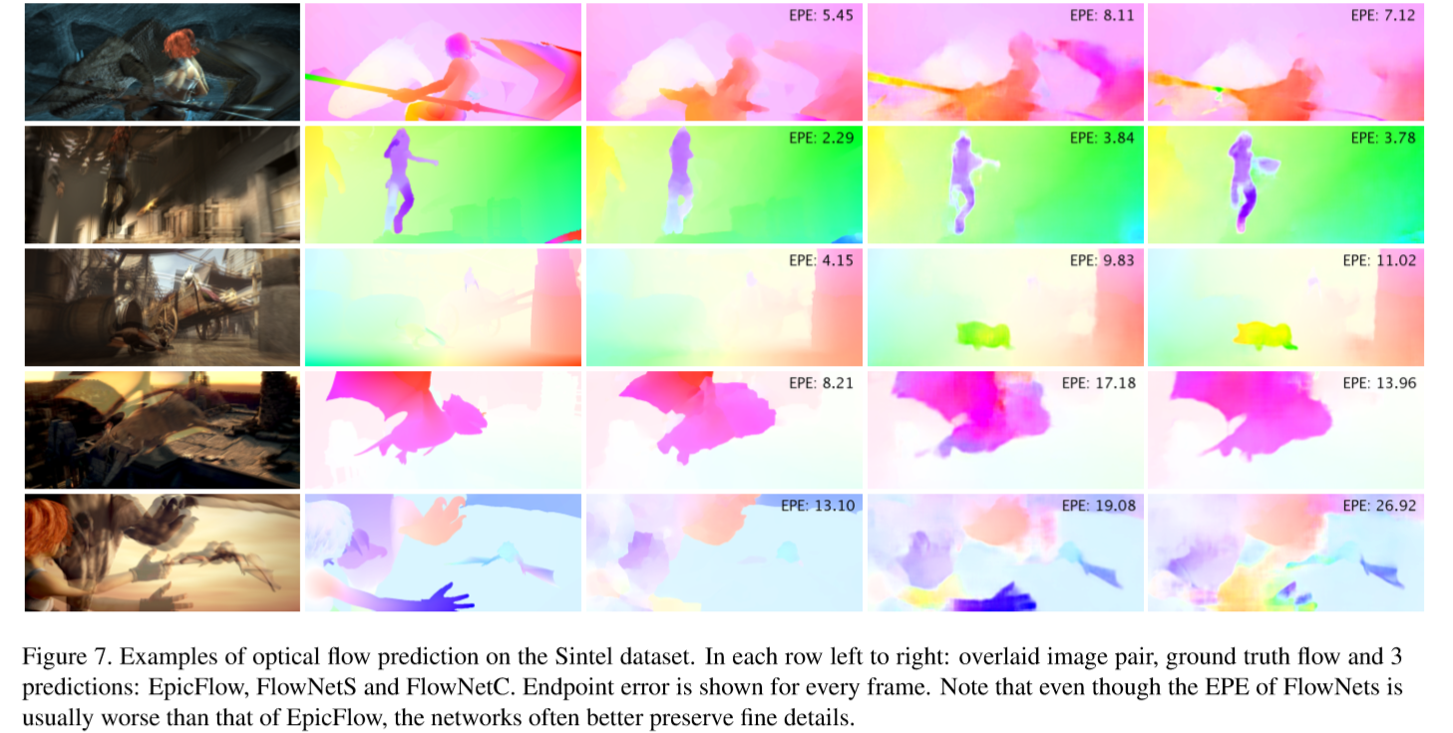
三种光流预测方法使用sinte数据集测试的光流预测效果
尽管flownet的正确率很烂,但是他能保存留下更多的细节信息(文章里说的)。
在虚拟数据集上训练图像,可以用来学习深度网络。
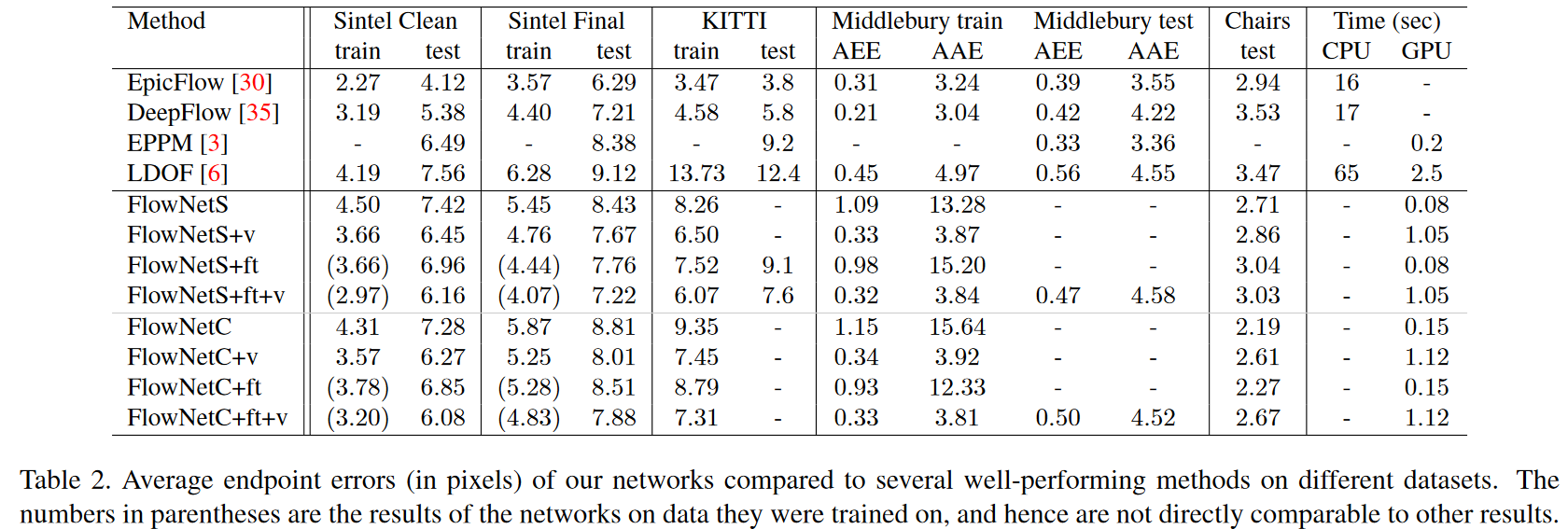
Sintel Clean数据集中: flownetc比flownets要好。
Sintel Final数据集中:相正好反,flownets比flownetc要好。可以看见在fls+ft+v时候的错误率甚至可与deepflow比肩。
Flyingchair数据集中:
Flownet大获全胜,其中c要比s好很多:
也仅仅只有在这一个数据集中,一些改善网络的方法,会使整个准确率下降,显然这个网络已经要比这些改善方式好很多
预示着,在训练集上更真实一些,flownet会比其他数据集表现的更好。
Kitti数据集中:Flownet很一般,c在位移比较大的情况下比s差一点。
Timming数据:文章中写到,一些方法只有在cpu上的runtimes运行库,flownet只在gpu上执行,NVIDIA GTX Titan GPU
Flownetsimple与Flownetcorr对比
仅仅看数据会感觉flownetcorr虽然加了关联层,但与s对比并没有太大的改善,因为flownetsimple的正确率也已经很不错了,flownetcorr并没有太大的优势。
但flownetcorr在flyingchair和sintel clean数据集的表现要好于flownetsimple,注意到sintel clean是没有运动blur和fog特效等的,和flyingchair数据集比较类似,这意味着flownetcorr网络能更好的学习训练数据集,更加过拟合over-fitting。
所以如果使用更好的训练数据集,flownetcorr网络会更有优势。
Appendix
评估指标
光流估计常用的评估指标有angular error(AE)和endpoint error(EPE)。假设某个像素的GT光流向量为 (u0,vo0),估计的光流向量为 (u1,v1),则:
AE定义如下,意为俩向量的夹角
![]()
EPE定义如下,意为俩向量末端距离
![]()
def viz_flow(flow):
# 色调H:用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°
# 饱和度S:取值范围为0.0~1.0
# 亮度V:取值范围为0.0(黑色)~1.0(白色)
h, w = flow.shape[:2]
hsv = np.zeros((h, w, 3), np.uint8)
mag, ang = cv2.cartToPolar(flow[...,0], flow[...,1])
hsv[...,0] = ang*180/np.pi/2
hsv[...,1] = cv2.normalize(mag,None,0,255,cv2.NORM_MINMAX)
# flownet是将V赋值为255, 此函数遵循flownet,饱和度S代表像素位移的大小,亮度都为最大,便于观看
# 也有的光流可视化讲s赋值为255,亮度代表像素位移的大小,整个图片会很暗,很少这样用
hsv[...,2] = 255
bgr = cv2.cvtColor(hsv,cv2.COLOR_HSV2BGR)
return bgr参考:【论文笔记】FlowNet: Learning Optical Flow with Convolutional Networks - 知乎【论文学习】神经光流网络——用卷积网络实现光流预测(FlowNet: Learning Optical Flow with Convolutional Networks)_光流神经网络开题报告-CSDN博客【论文笔记】FlowNet: Learning Optical Flow with Convolutional Networks - 知乎

















 1633
1633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









