






翻译自文章:Introduction to Autoencoders - PyImageSearch

将你的衣服整理成一个无尽、无限宽、高的衣柜。然后,当您请求特定的物品时,您只需告知 Alex 它的位置,他们就会使用可靠的缝纫机从头开始缝制该物品。您很快就会意识到,将相似的物品彼此靠近排列是至关重要的,这样Alex就可以仅根据它们的位置准确地重新创建它们。
经过几周的微调和调整壁橱的布置,你和Alex建立了对其结构的理解。现在,您只需通知 Alex 任何服装的位置,Alex就可以无可挑剔地复制它!
这一成就让你想知道:如果你在无限的壁橱里给Alex一个空位会怎样?令人惊讶的是,Alex设法创造了前所未有的全新服装!尽管该过程有不完美之处,但您现在拥有制作新奇服装的无限可能性。只需要在巨大的壁橱里选择一个空间,让Alex用缝纫机创造奇迹。
什么是自动编码器?
自动编码器是一种人工神经网络,用于无监督学习任务(即,没有类标签或标记数据),例如降维、特征提取和数据压缩。寻求:
● 接受一组输入数据(即输入);
● 在内部将输入数据压缩为潜在空间表示(即压缩和量化输入的单个向量);
● 从这个潜在表示(即输出)重建输入数据。
自动编码器由以下两个主要组件组成:
● 编码器(Encoder):编码器将输入数据压缩为称为潜在空间或代码的低维表示形式。这种潜在空间通常称为嵌入(Embedding),旨在保留尽可能多的信息,允许解码器以高精度重建数据。如果我们将输入数据表示为x ,将编码器表示为 E,则输出潜在空间s表示为s=E(x) 。
● 解码器(Decoder):解码器通过接受潜在空间表示s来重建原始输入数据。如果我们将解码器函数表示为D ,将检测器的输出表示为o ,那么我们可以将解码器表示为 o=D(s)。
编码器和解码器通常由一个或多个层组成,这些层可以是完全连接的、卷积的或循环的,具体取决于输入数据的性质和自动编码器的架构。
使用数学符号,自动编码器的整个训练过程可以编写如下:o=D(E(x))
图 2 展示了自动编码器的基本架构:
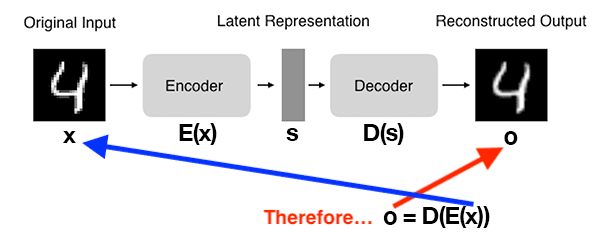
图2:自动编码器的架构(来自 Hubens, “Deep Inside: Autoencoders,” Towards Data Science, 2018)。
● 在自动编码器中输入一个数字。
● 编码器子网生成数字4的潜在表示,其维数比输入小得多。
● 解码器子网使用潜在表示重建原始数字。
可以将自动编码器视为旨在重建其输入的网络!
重建过程
自动编码器旨在减少解码器端原始数据和重建数据之间的差异或损失,旨在尽可能准确地重新创建输入。这种损失函数通常被称为重建误差。用于自动编码器的最常见损失函数是均方误差 (MSE:mean squared error) 或二进制交叉熵 (BCE:binary cross-entropy ),具体取决于输入数据的性质。
还记得上面的类比故事吗?让我们将其与自动编码器的技术概念联系起来。在故事中,你扮演编码器(Encoder),将每件服装整理到衣柜内的特定位置,并分配一个编码(encoding)。解码器(Decoder)在衣柜中选择一个位置并尝试重新创建衣服,这个过程称为解码decoding。
图 3 展示了潜在空间的可视化以及我们在故事中讨论的过程,这与编码器和解码器的技术定义一致。在下图中,您通过将裤子放置在无限壁橱内的特定位置(在 2D 空间中)来对其进行编码。然后,Alex使用相似的位置重建该项目。

图 3:壁橱的潜在空间可视化(来源: Kumar, “Autoencoder vs Variational Autoencoder (VAE): Differences,” Data Analytics, 2023).
自动编码器的类型
有几种类型的自动编码器,每种都有其独特的属性和用例。
普通自动编码器(Vanilla Autoencoder)
图 4 显示了自动编码器的最简单形式,由编码器和解码器的一个或多个全连接层组成。它适用于简单数据,可能难以处理复杂模式。
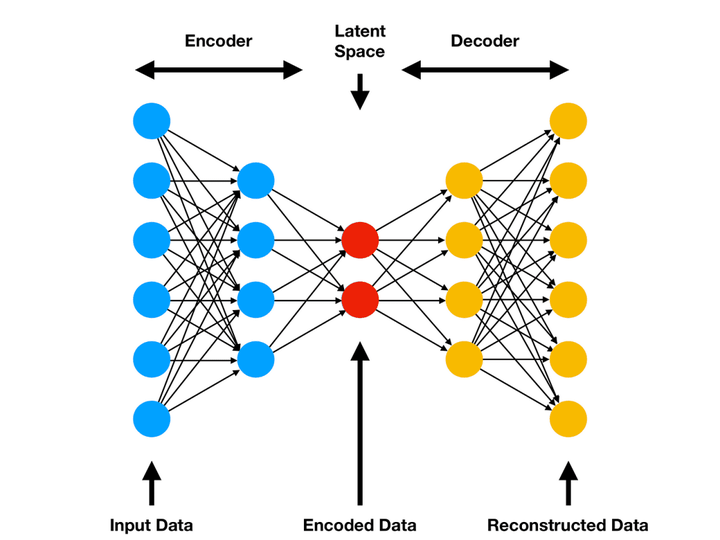
图 4:全连接自动编码器的架构(来源: Amor, “Comprehensive introduction to Autoencoders,” ML Cheat Sheet, 2021).
卷积自动编码器(CAE:Convolutional Autoencoder)
在编码器和解码器中利用卷积层,使其适用于处理图像数据。通过利用图像中的空间信息,CAE可以比普通自动编码器更有效地捕获复杂的模式和结构,并完成图像分割等任务,如图5所示。

图 5:用于图像分割的卷积自动编码器架构(来源: Bandyopadhyay, “Autoencoders in Deep Learning: Tutorial & Use Cases [2023],” V7Labs, 2023 )
降噪自动编码器(Denoising Autoencoder)
该自动编码器旨在消除损坏的输入数据中的噪声,如图6所示。在训练期间,输入数据通过添加噪声故意损坏,而目标仍然是原始的、未损坏的数据。自动编码器学习从噪声输入中重建干净的数据,使其可用于图像去噪和数据预处理任务。
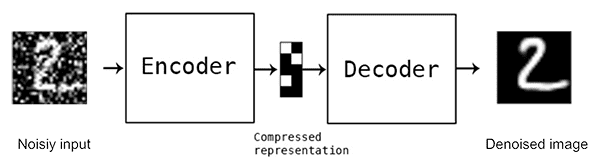
图 6:去噪自动编码器处理噪声图像,在输出端生成干净的图像(来源: Denoising Autoencoders with Keras, TensorFlow, and Deep Learning中引用的 Building Autoencoders in Keras)
稀疏自动编码器(Sparse Autoencoder)
这种类型的自动编码器通过向损失函数添加稀疏性约束来强制潜在空间表示的稀疏性(如图 7 所示)。此约束鼓励自动编码器使用潜在空间中的少量活动神经元来表示输入数据,从而实现更高效、更稳健的特征提取。
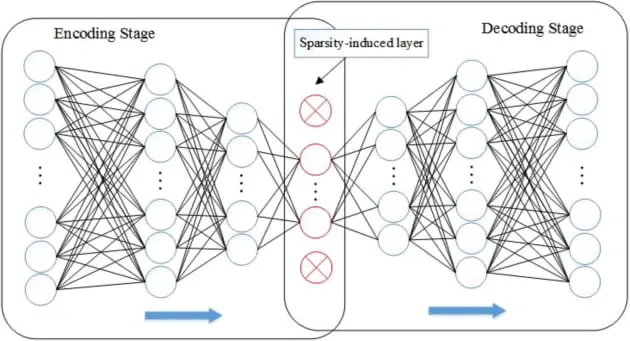
图 7:稀疏自动编码器的拓扑结构(来源:Shi, Ji, Zhang, and Miao, “Boosting sparsity-induced autoencoder: A novel sparse feature ensemble learning for image classification,” International Journal of Advanced Robotic Systems, 2019).
变分自动编码器(VAE:Variational Autoencoder)
图 8 显示了一个生成模型,该模型在潜在空间中引入了概率层,允许对新数据进行采样和生成。VAE可以从学习到的潜在分布中生成新的样本,使其成为图像生成和风格迁移任务的理想选择。
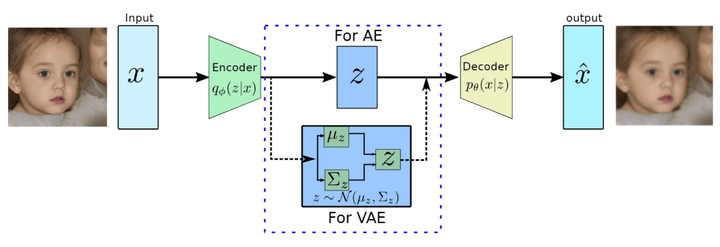
图 8:变分自动编码器的架构(来源: Yadav, “Variational Autoencoders,” Data-Science-Blog, 2022).
序列间自动编码器(Sequence-to-Sequence Autoencoder)
这种类型的自动编码器也称为循环自动编码器,在图 9 所示的编码器和解码器中利用循环神经网络 (RNN) 层(例如,长短期记忆 (LSTM) 或门控循环单元 (GRU))。此体系结构非常适合处理顺序数据(例如,时间序列或自然语言处理任务)。
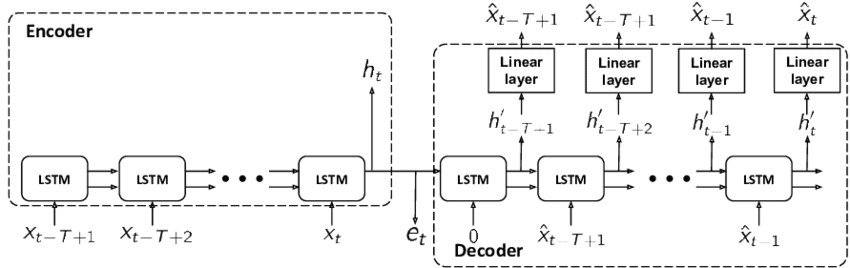
图 9:序列到序列自动编码器(来源: Zerveas, “Improving Clinical Predictions through Unsupervised Time Series Representation Learning,” Machine Learning for Health (ML4H) Workshop at NeurIPS, 2018).
这些只是各种可用自动编码器架构的几个示例。每种类型都旨在解决特定的挑战和应用,通过了解其独特的特性,您可以为您的问题选择最合适的自动编码器。
要在 PyTorch 中实现自动编码器,通常需要为编码器和解码器定义两个单独的模块,然后将它们组合到更高级别的模块中。然后,使用反向传播和梯度下降来训练自动编码器,从而最大限度地减少重建误差。
总之,自动编码器是功能强大的神经网络,在无监督学习中具有多种应用,包括降维、特征提取和数据压缩。通过使用 PyTorch 等框架了解它们的架构、类型和实现,您可以利用它们的功能来解决各种实际问题。
自动编码器有哪些应用?
自动编码器在各个领域都有广泛的应用,包括:
降维
自动编码器可以通过学习潜在空间中的紧凑而有效的表示来降低输入数据的维数。这对于可视化、数据压缩和加速其他机器学习算法很有帮助。
特征学习
自动编码器可以从输入数据中学习有意义的特征,这些特征可用于下游机器学习任务,如分类、聚类或回归。
异常检测
通过在普通数据实例上训练自动编码器,它可以学习以低错误重建这些实例。当呈现异常数据点时,自动编码器可能会有更高的重建误差,可用于识别异常值或异常值。
图像降噪
可以训练自动编码器从嘈杂的版本重建干净的输入数据。降噪自动编码器学习消除噪声并生成输入数据的干净版本。
图像修复
如图 10 所示,自动编码器可以通过学习数据中的底层结构和模式来填充图像中缺失或损坏的部分。

图 10:通过填充缺失像素完成人脸(来源:SymmFCNet)。
生成模型
变分自动编码器 (VAE) 和其他生成变体可以通过在训练期间学习数据分布来生成新的、真实的数据样本。这对于数据增强或创意应用程序非常有用。
推荐系统
自动编码器可用于学习推荐系统中用户和项目的潜在表示,然后可以预测用户偏好并做出个性化推荐。
序列间学习
自动编码器可用于序列到序列的任务,例如机器翻译或文本摘要,方法是调整其架构以处理顺序输入和输出数据。
图像分割
自动编码器也常用于语义分割。一个值得注意的例子是SegNet(图11),这是一个专为城市道路场景数据集上的像素级多类分割而设计的模型。该模型由剑桥大学计算机视觉小组的研究人员创建。
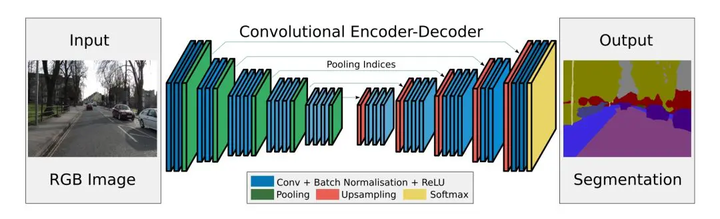
图 11:全卷积 SegNet 架构的图示(来源:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation).
这些只是自动编码器众多可能应用中的几个例子。它们的多功能性和适应性使其成为机器学习工具箱中的重要工具。
自动编码器和GAN有何不同?
模型结构
● 自动编码器由编码器和解码器组成。编码器将输入数据压缩为低维潜在表示形式,而解码器从潜在表示形式重建输入数据。
● GAN 由生成器和鉴别器组成。生成器从随机噪声创建假样本,鉴别器尝试区分数据集中的真实样本和生成器生成的假样本。
训练流程
● 自动编码器使用重建误差进行训练,该误差测量输入数据和重建数据之间的差异。训练过程的目的是尽量减少这种误差。
● GAN 在训练期间使用two-player minimax game。生成器试图产生判别器无法与真实样本区分开的样本,而判别器则试图提高其区分真假样本的能力。训练过程涉及在两个竞争网络之间找到平衡。
使用场景
● 自动编码器主要用于降维、数据压缩、去噪和表示学习。
● GAN 主要用于生成新的、逼真的样本,通常在图像领域,但也用于其他数据类型,如文本、音频等。
虽然自动编码器和GAN都可以生成新样本,但它们具有不同的优点和缺点。自动编码器通常产生更平滑、更连续的输出,而 GAN 可以生成更真实和多样化的示例,但可能会出现模式崩溃等问题。两种模型之间的选择取决于具体问题和期望的结果。















 2046
2046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









