






0前言
继VIT之后,transformer可以说是被大规模用于图像处理之中,但是vit论文只是将transformer用于分类问题之中,将其余问题留给了我们,本文的Swin Transformer不仅将tf用于分类也实验用于了分割和检测任务之中,并且都取得了很好的成绩,很多方面都处于最优的地位。

论文名称:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
原论文地址: https://arxiv.org/abs/2103.14030
官方开源代码地址:https://github.com/microsoft/Swin-Transformer
Pytorch实现代码: pytorch_classification/swin_transformer
Tensorflow2实现代码:tensorflow_classification/swin_transformer
1 网络整体框架
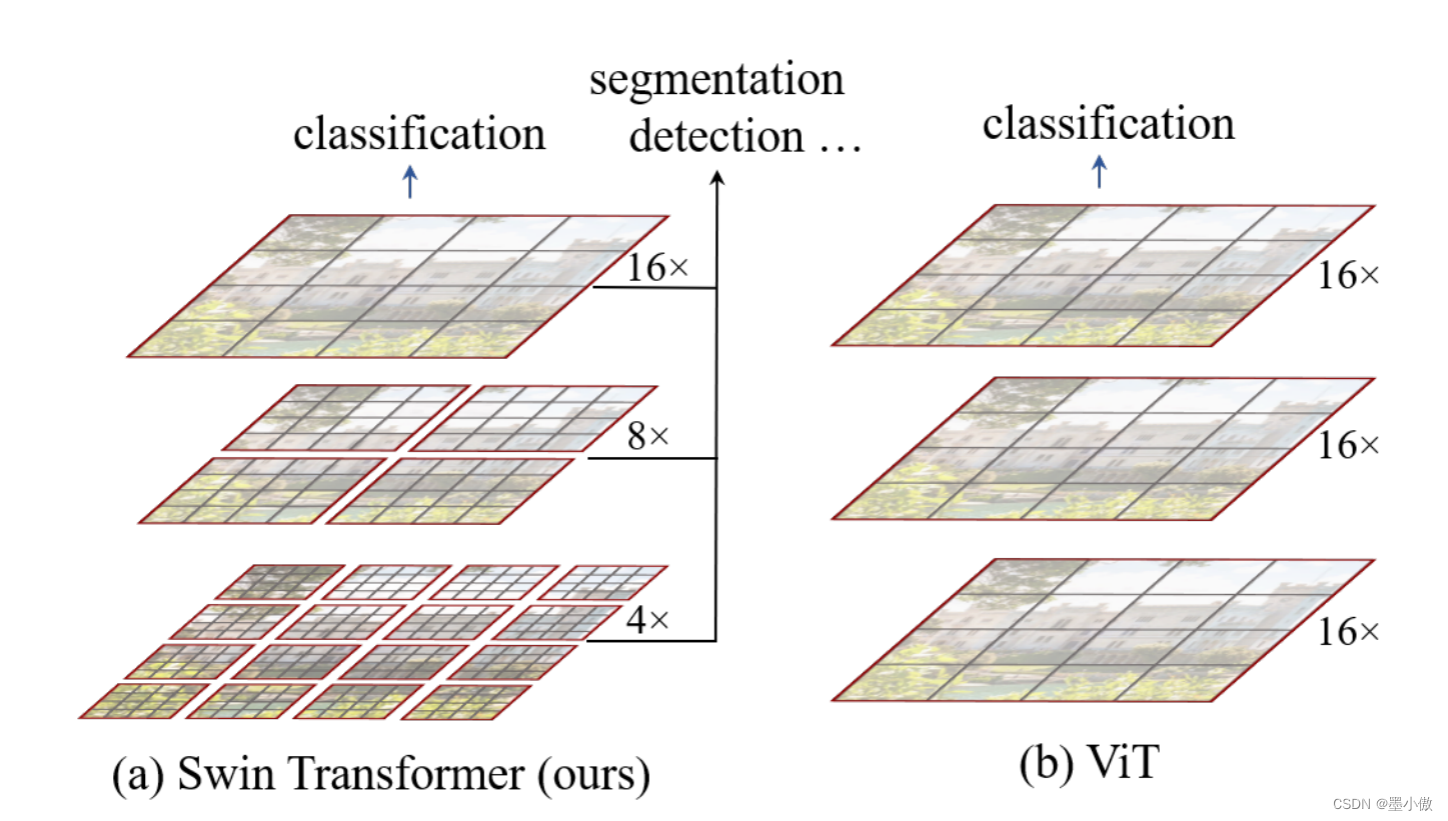
在正文开始之前,先来简单对比下Swin Transformer和之前的Vision Transformer(如果不了解Vision Transformer的建议先去看下我之前的文章)。下图是Swin Transformer文章中给出的图1,左边是本文要讲的Swin Transformer,右边边是之前讲的Vision Transformer。通过对比至少可以看出两点不同:
- Swin Transformer使用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变。
- 在Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA)的概念,比如在下图的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域(Window),并且Multi-Head Self-Attention只在每个窗口(Window)内进行。相对于Vision Transformer中直接对整个(Global)特征图进行Multi-Head Self-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以在论文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递,后面会细讲。
 接下来,简单看下原论文中给出的关于Swin Transformer(Swin-T)网络的架构图。通过图(a)可以看出整个框架的基本流程如下:
接下来,简单看下原论文中给出的关于Swin Transformer(Swin-T)网络的架构图。通过图(a)可以看出整个框架的基本流程如下:
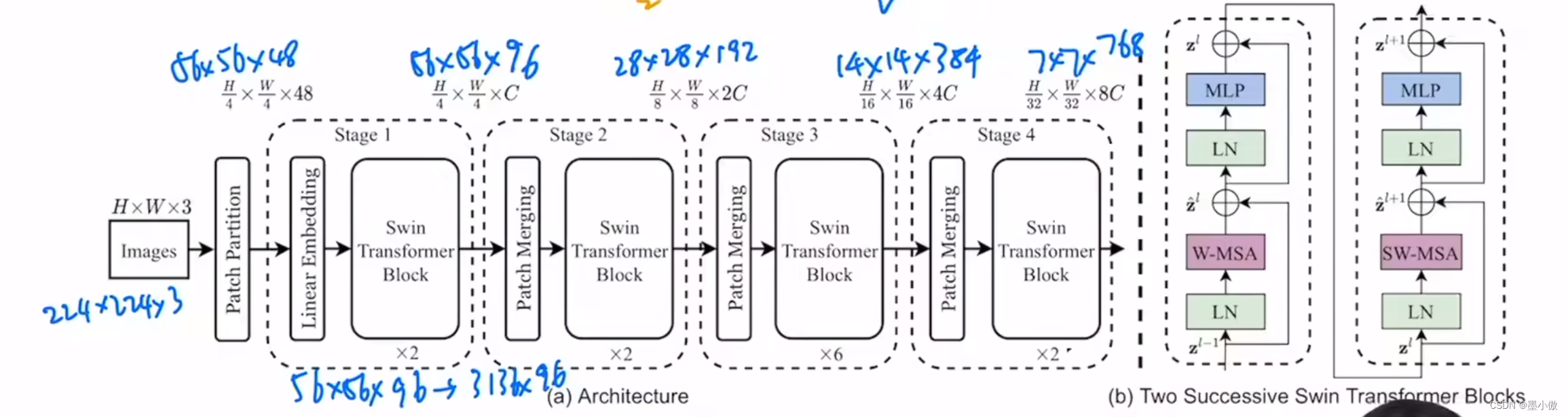
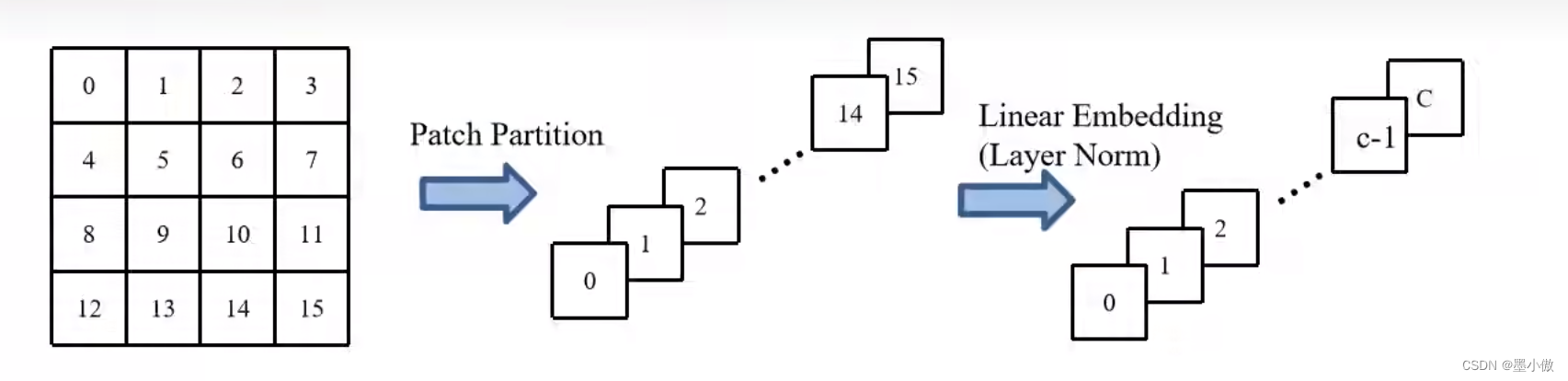
- 首先将图片输入到Patch Partition模块中进行分块,即每4x4相邻的像素为一个Patch,然后在channel方向展平(flatten)。假设输入的是RGB三通道图片,那么每个patch就有4x4=16个像素,然后每个像素有R、G、B三个值所以展平后是16x3=48,所以通过Patch Partition后图像shape由 [H, W, 3]变成了 [H/4, W/4, 48]。然后在通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由 [H/4, W/4, 48]变成了 [H/4, W/4, C]。其实在源码中Patch Partition和Linear Embeding就是直接通过一个卷积层实现的,和之前Vision Transformer中讲的 Embedding层结构一模一样。(卷积核为4*4,步长为4,输出通道为输入的两倍就可以实现这个要求),Linear Embeding会将其映射为向量形式(3136*96)这里的96就是之后模型的变体C,可以按照之后的需求更改。
注意:虽然现在还是以图片的形式来讲解,但是实际上程序运行时,经过Linear Embeding之后此时输入的数据都已经是向量的形式了,所有不用纠结为什么这里还是3维图像的数据形式,只是为了让读者好理解,他的基础还是transformer那么输入就一定得是向量!
- 然后就是通过四个Stage构建不同大小的特征图,除了Stage1中先通过一个Linear Embeding层外,剩下三个stage都是先通过一个Patch Merging层进行下采样(后面会细讲)。然后都是重复堆叠Swin Transformer Block注意这里的Block其实有两种结构,如图(b)中所示,这两种结构的不同之处仅在于一个使用了W-MSA结构,一个使用了SW-MSA结构。而且这两个结构是成对使用的,先使用一个W-MSA结构再使用一个SW-MSA结构。所以你会发现堆叠Swin Transformer Block的次数都是偶数(因为成对使用)。
- 最后对于分类网络,后面还会接上一个Layer Norm层、全局池化层以及全连接层得到最终输出。图中没有画,但源码中是这样做的。
接下来,在分别对Patch Merging、W-MSA、SW-MSA以及使用到的相对位置偏执(relative position bias)进行详解。关于Swin Transformer Block中的MLP结构和Vision Transformer中的结构是一样的,所以这里也不在赘述。
2 Patch Merging详解(等价于池化操作)
前面有说,在每个Stage中首先要通过一个Patch Merging层进行下采样(Stage1除外)。如下图所示,假设输入Patch Merging的是一个4x4大小的单通道特征图(feature map),Patch Merging会将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map。接着将这四个feature map在深度方向进行concat拼接,然后在通过一个LayerNorm层。最后通过一个全连接层在feature map的深度方向做线性变化,1*1的卷积降维,将feature map的深度由C变成C/2。通过这个简单的例子可以看出,通过Patch Merging层后,feature map的高和宽会减半,深度会翻倍。

3 W-MSA详解
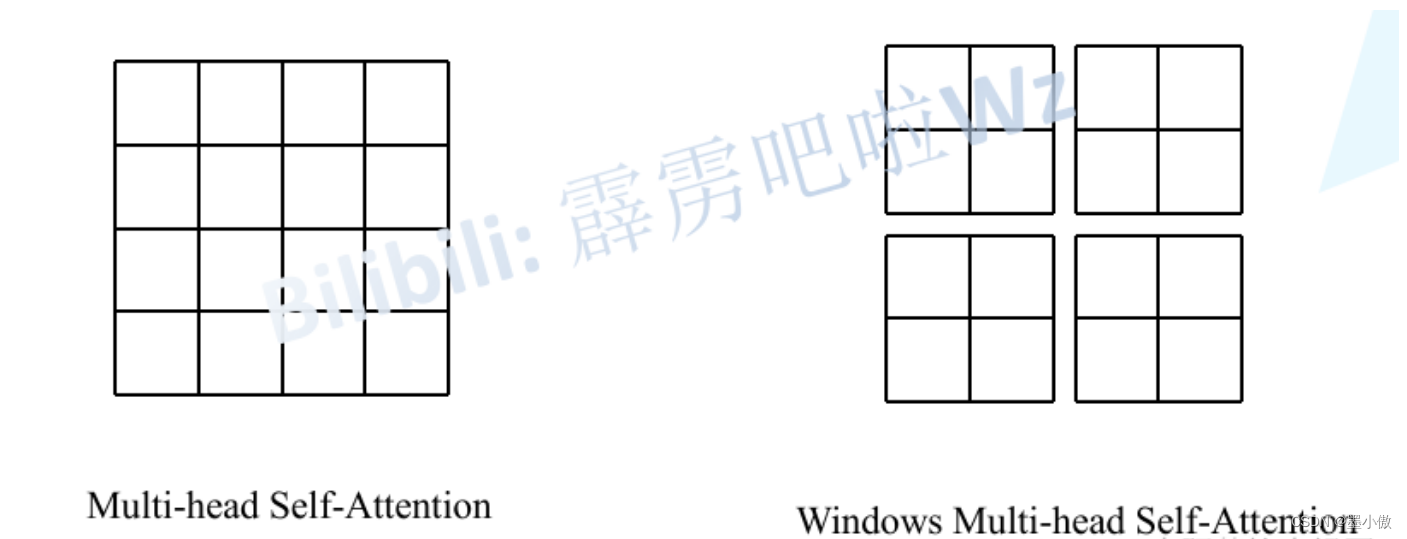
引入Windows Multi-head Self-Attention(W-MSA)模块是为了减少计算量。如下图所示,左侧使用的是普通的Multi-head Self-Attention(MSA)模块,对于feature map中的每个像素(或称作token,patch)在Self-Attention计算过程中需要和所有的像素去计算。但在图右侧,在使用Windows Multi-head Self-Attention(W-MSA)模块时,首先将feature map按照MxM(例子中的M=2)大小划分成一个个Windows,然后单独对每个Windows内部进行Self-Attention。
两者的计算量具体差多少呢?原论文中有给出下面两个公式,这里忽略了Softmax的计算复杂度。
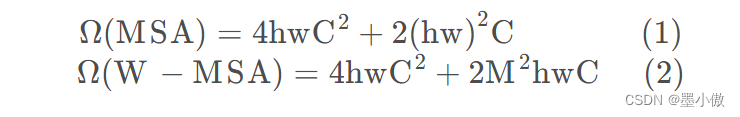
具体的计算过程文章没有给出,我认为只需要知道W-MSA的计算量减少了很多就可以了,没必要了解具体的计算过程,因为对模型的理解用处不大。
4 SW-MSA详解
前面有说,采用W-MSA模块时,只会在每个窗口内进行自注意力计算,所以窗口与窗口之间是无法进行信息传递的。为了解决这个问题,作者引入了Shifted Windows Multi-Head Self-Attention(SW-MSA)模块,即进行偏移的W-MSA。如下图所示,左侧使用的是刚刚讲的W-MSA(假设是第L层),那么根据之前介绍的W-MSA和SW-MSA是成对使用的,那么第L+1层使用的就是SW-MSA(右侧图)。根据左右两幅图对比能够发现窗口(Windows)发生了偏移(可以理解成窗口从左上角分别向右侧和下方各偏移了⌊ M/2 ⌋个像素)。看下偏移后的窗口(右侧图),比如对于第一行第2列的2x4的窗口,它能够使第L层的第一排的两个窗口信息进行交流。再比如,第二行第二列的4x4的窗口,他能够使第L层的四个窗口信息进行交流,其他的同理。那么这就解决了不同窗口之间无法进行信息交流的问题。

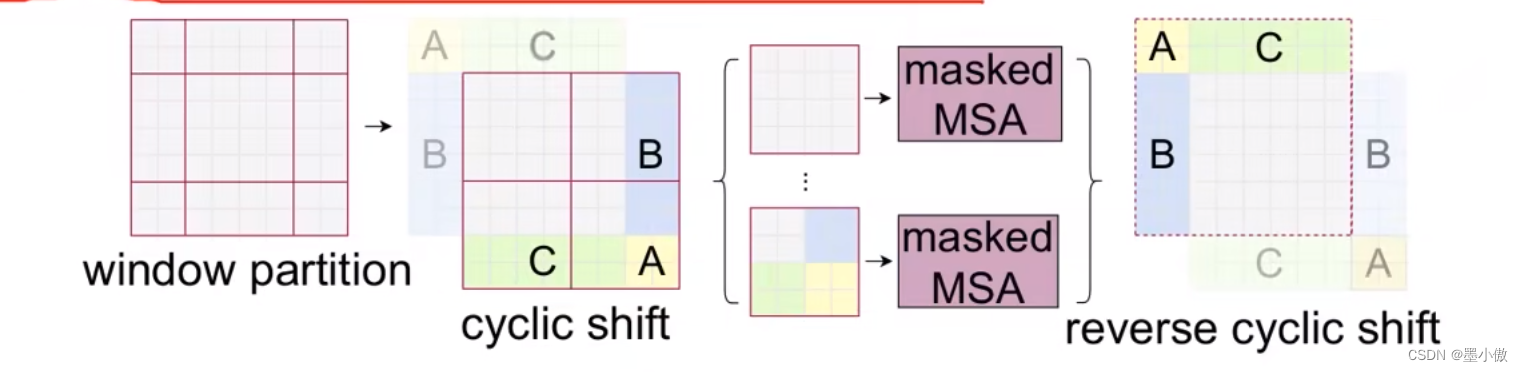
根据上图,可以发现通过将窗口进行偏移后,由原来的4个窗口变成9个窗口了。后面又要对每个窗口内部进行MSA,这样做感觉又变麻烦了。为了解决这个麻烦,作者又提出而了Efficient batch computation for shifted configuration,一种更加高效的计算方法。下面是原论文给的示意图。
感觉不太好描述,然后我自己又重新画了个。下图左侧是刚刚通过偏移窗口后得到的新窗口,右侧是为了方便大家理解,对每个窗口加上了一个标识。然后0对应的窗口标记为区域A,3和6对应的窗口标记为区域B,1和2对应的窗口标记为区域C。
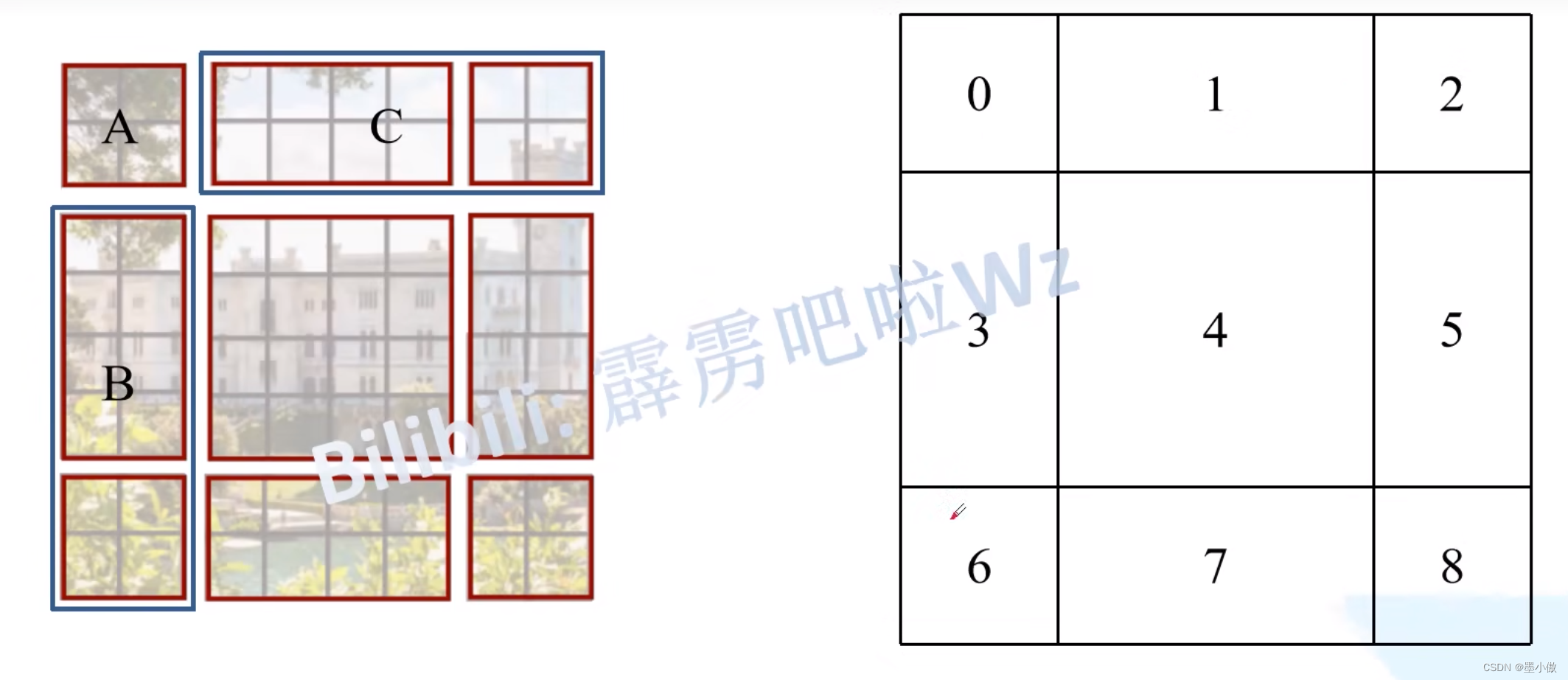
然后先将区域A和C移到最下方。
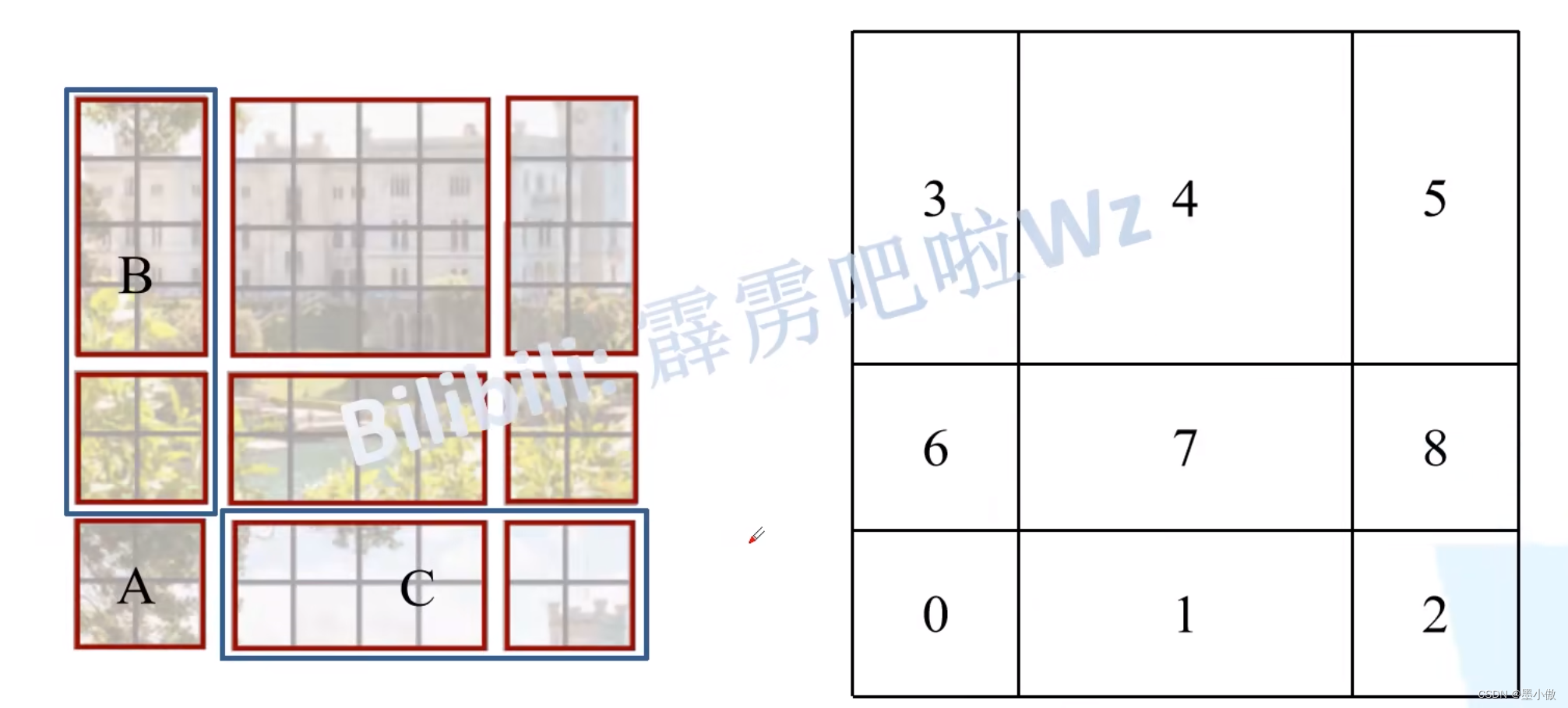
接着,再将区域A和B移至最右侧。
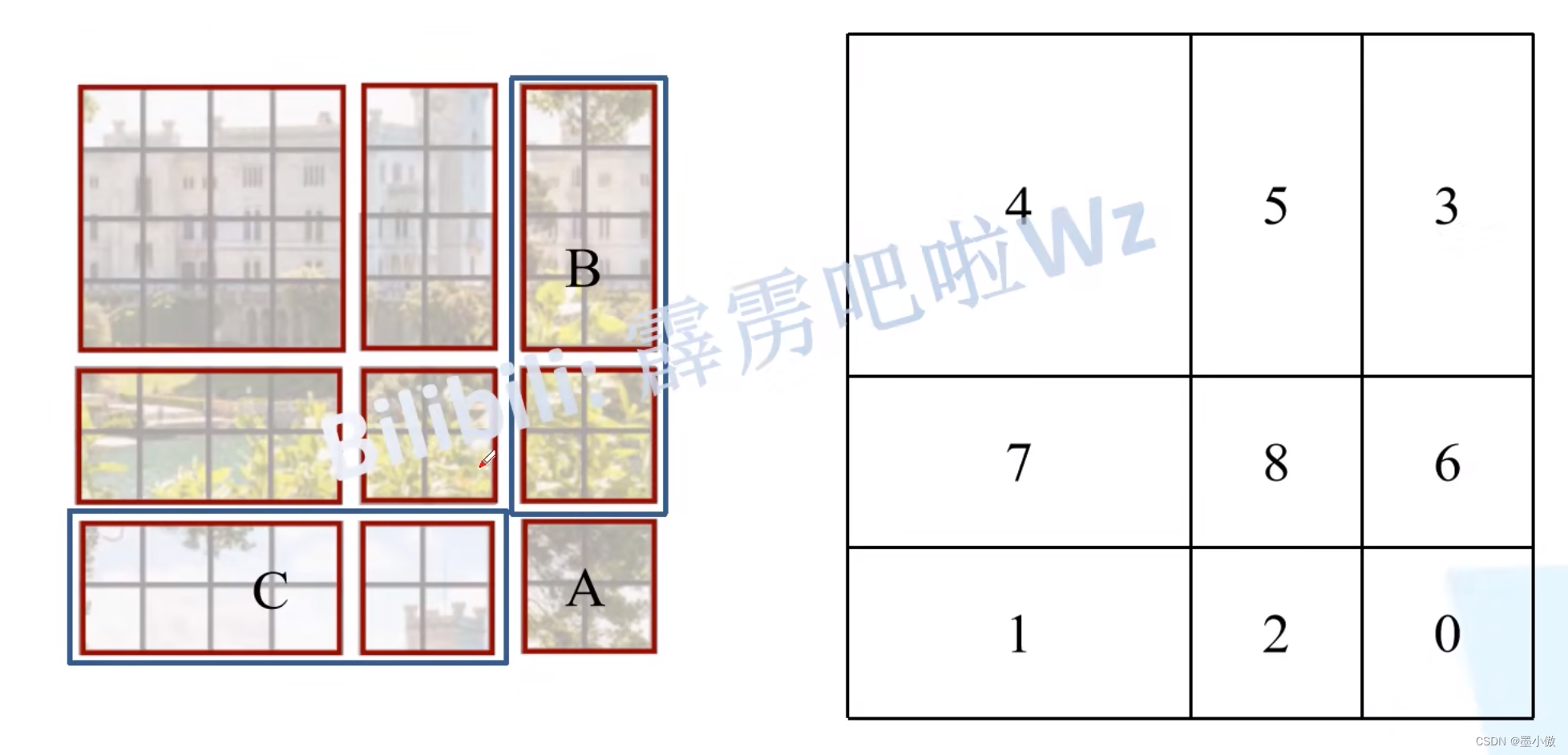
移动完后,4是一个单独的窗口;将5和3合并成一个窗口;7和1合并成一个窗口;8、6、2和0合并成一个窗口。这样又和原来一样是4个4x4的窗口了,所以能够保证计算量是一样的。这里肯定有人会想,把不同的区域合并在一起(比如5和3)进行MSA,这信息不就乱窜了吗?是的,为了防止这个问题,在实际计算中使用的是masked MSA即带蒙板mask的MSA,这样就能够通过设置蒙板来隔绝不同区域的信息了。关于mask如何使用,可以看下下面这幅图,下图是以上面的区域5和区域3为例。

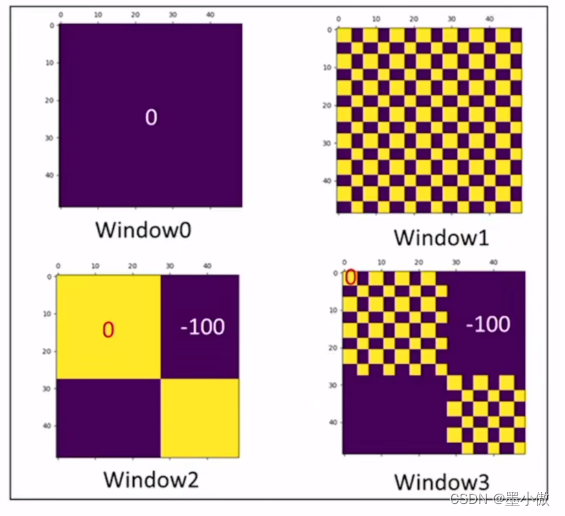
上图右边就是作者给出的可视化掩码模板,在W1、W2、W3、W4窗口都进行了MSA之后将结果与右图的掩码模板相加,就相当于把不相邻区域的计算结果加上一个负无穷让他变成0,也就等于不相邻区域没有进行运算了。
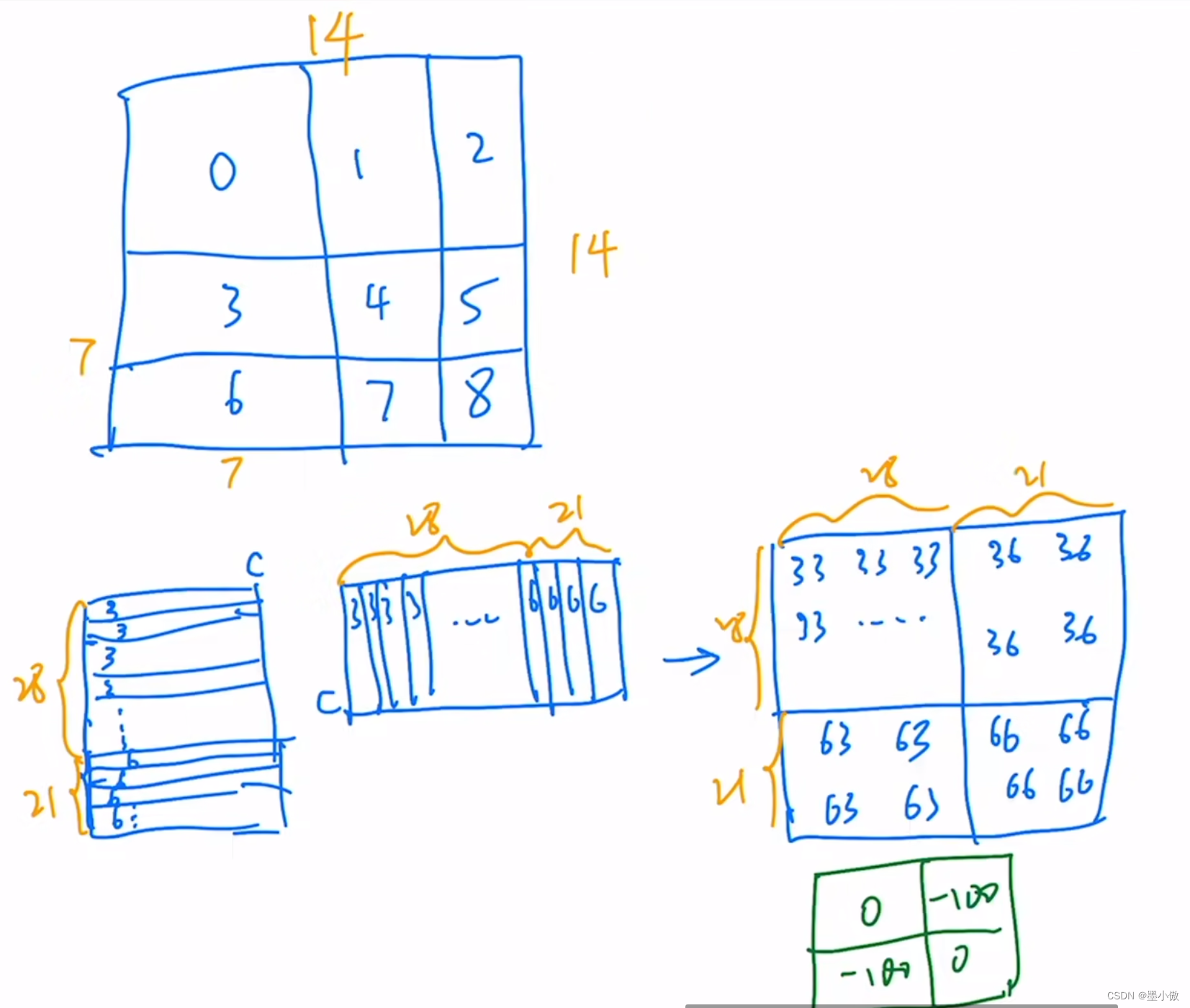
上图是给出的一个简单例子,可以看一下。















 9245
9245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









