






算法背景
对于多目标进化算法,针对问题的特性选择合适的进化算子(如GA,DE,PSO)产生后代对算法性能的影响至关重要。自适应算子选择(如FREEMAB)在复杂优化问题的优越性是显而易见的。然而,它面临着探索与利用的困境,具有较好历史表现的算子将被赋予更高的优先级,但同时具有较差历史表现的算子也需要被探索。MOEA/D-DQN基于强化学习,将自动算子选择嵌入到MOEA/D-DRA算法中,来缓解自动算子选择探索与利用的困境。
算法思想
The Proposed Reinforcement Learning Based Operator Selection Method
简介:进化算法通过种群的进化来优化问题,对于种群中的每一个个体,深度强化学习的智能体(神经网络)根据个体的状态,为个体选择合适的进化算子来产生后代,根据后代的改进程度给予智能体奖励,智能体根据奖励来调整策略(神经网络的权重)。
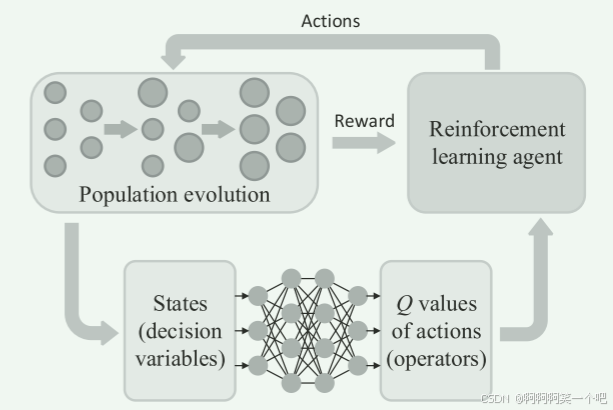
状态
,为解向量和权重向量的组合。
动作
动作表示选择的算子。
选择动作的步骤为,当有动作不存在经验回放池中,则直接选择该动作。若全部动作都存在经验回放池中,则将状态输入神经网络,估计每个动作的Q值,用轮盘赌的方法选择动作。
伪代码如下:

奖励
计算方式如下:
在MOEA/D-DRA选择的子问题中,对于每一个父代,智能体会根据父代的状态选择进化算子,产生子代
。
子代与其父代邻居子问题的解
进行比较,若子代优于父代,计算适应度的改进程度:
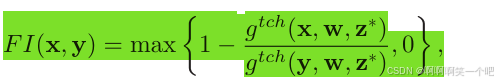
这里的指的是
对应的子问题的权重向量。
将子代在其父代邻居子问题中的改进进行累加,记为
,将其放入一个队列
。
在这个队列中找到的最大值,作为奖励。
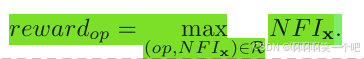
伪代码如下:

注意:算子的奖励设置为队列中的最大值,这是由于大的改进比小而频繁的改进更加重要。
训练算法
应用了DQN强化学习算法,智能体每次采取动作,获取奖励后会将存储在经验回放池
中。经验回放池中的数据用于训练神经网络。
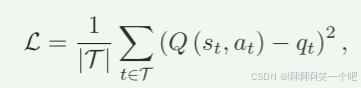
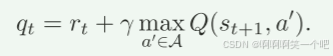

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









