






目录
1,car文件夹下创建mydata.yaml(当然别的位置创建也行)
一,构建数据集
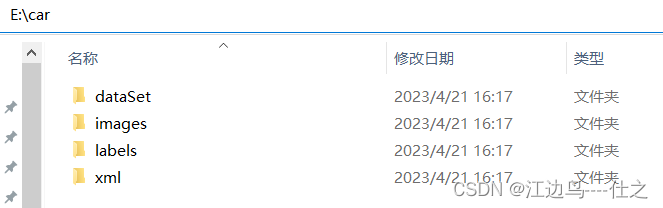
1,任意位置新建如下文件夹
|------car(目标检测类别名)
| |------dataSet(后续在文件夹下生成存放images中图像路径的txt文件)
| |------images(不可改名,存放图像文件,图像不需要统一格式)
| |------labels(不可改名,存放标签文件,标签与图像根据文件名一一对应)
| |------xml(存放xml文件,labelImg的VOC格式打标生成的xml文件)
labelImg打标,可以打标为VOC格式(xml文件)和YOLO格式(txt文件)
如果打标为VOC格式,后续需要转成YOLO格式,也就是xml文件转换为txt文件
所以直接打标为YOLO格式就不需要xml转txt,也不需要xml文件夹。
但是,xml转txt容易,txt转xml就难了
labelimg安装与使用:labelimg数据打标
2,xml转txt
代码如下,按提示修改即可
#trans
# voc_to_yolo.py
import os
import xml.etree.ElementTree as ET
from fnmatch import fnmatch
# 转换之前先修改类别和路径
classes = ["car"]
# 指定路径
IN_PATH = "./xml" # xml文件夹路径
OUT_PATH = "./labels" # txt文件夹路径
# 一般情况不修改:类别起始编号start_number
start_number = 0
# (lx,ly,rx,ry) -> (cx,xy,w,h)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(in_path, out_path, img_id):
i_p = os.path.join(in_path, img_id+'.xml')
in_file = open(i_p, 'rb')
o_p = os.path.join(out_path, img_id + '.txt')
out_file = open(o_p, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls) + start_number
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
def xml2txt(in_path,out_path):
file_lst = os.listdir(in_path)
for f in file_lst:
if fnmatch(f, '*.xml'):
print("Translate...",f)
img_id = f.split('.')[0]
convert_annotation(in_path, out_path, img_id)
xml2txt(IN_PATH, OUT_PATH)
标签文件夹labels中得到txt文件,内容:
![]()
· 每行代表标注的一个目标
· 每行第一个数代表类别
· 后边四个数是归一化后的((中心坐标),框的宽,框的高)
· 归一化的原理在上边给出的xml2txt代码中
3,划分数据集
将images中图像分为三部分:train,valid,test(推荐比例8:1:1)
执行代码(下边给出get_path.py),得到train.txt,valid.txt,test.txt,分别存放这三部分图像的路径
举例:
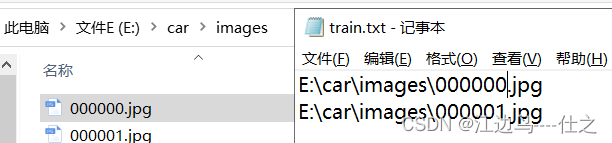
如果images中有100张图片,那么train.txt中约有80条路径,valid.txt和test.txt各约10条路径
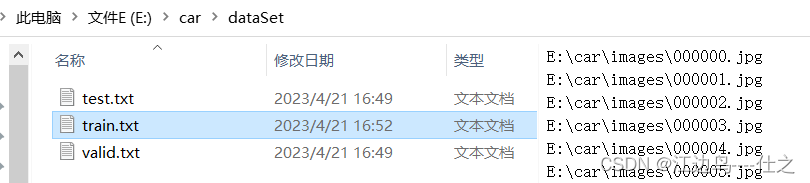
yolo训练数据查找图像对应标签时,自动将路径中的images替换为labels就可以定位图像对应的标签文件,所以images和labels文件夹不要改名
get_path.py:
"""
划分训练集\验证集\测试集的文件的路径
存入train.txt valid.txt test.txt
比例推荐8:1:1
"""
from pathlib import Path
import random
path_train = Path('./images')#--图片数据集目录
path_dataset = Path('./dataSet')#--存放数据集的划分文件
f_train = open(path_dataset/'train.txt', 'w')
f_valid = open(path_dataset/'valid.txt', 'w')
f_test = open(path_dataset/'test.txt', 'w')
for path in path_train.glob('*.*'):
i = random.random()
if i<0.1:
f_test.write(str(path)+'\n')
elif i<0.2:
f_valid.write(str(path)+'\n')
else:
f_train.write(str(path)+'\n')
# print(str(path))
二、配置yolov8训练文件
1,car文件夹下创建mydata.yaml(当然别的位置创建也行)

注意:
· 5,6,7行缩进要一致
· 每个冒号后边要有空格
· train.txt / valid.txt 可以是绝对路径也可以是相对路径
2,修改yolov8x.yaml
yolov8有两种训练执行方式,后续细说。一种是用yolov8x.yaml初始化模型进行训练,这种方式需要修改yolov8x.yaml。只需修改一个参数:类别数。如图
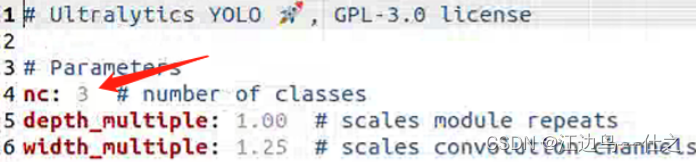

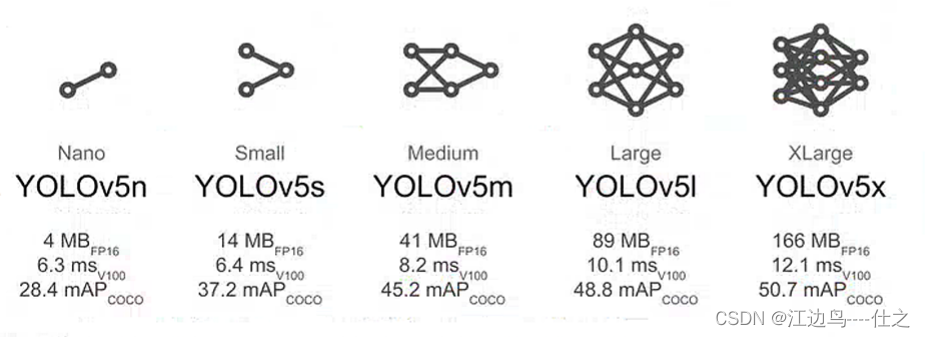
其他yaml网络大小参考yolov5:
三、训练
方式一,执行:yolo task=detect mode=train model=...../yolov8x.yaml(路径) data=./mydata.yaml(路径) epochs=200 batch=16
方式二,执行:yolo task=detect mode=train model=yolov8n.pt data=./mydata.yaml epochs=200 batch=16
若训练报错与内存有关,先试试调小batch的值
方式二中的yolov8n.pt训练时会自动下载,可能很慢。后续训练依然重新下载yolov8n.pt的话,可能是yolo运行目录下没有yolov8n.pt,复制一份到当前目录即可跳过下载
还可能下载Arial.ttf字体,可能也慢。但是都不影响训练
参数含义:
model传参可以是yaml文件,也可以是.pt文件,传.pt文件是加载预训练模型
epochs若设置300,表示训练300轮
batch即batch_size,若训练报错,先试试调小它的值
训练结果:
mydata.yaml同目录下生成run文件夹,runs/detect/train下存放训练结果
重点是weights文件夹下的best.pt last.pt,这是最优模型和当前训练的最后一轮的模型。
查看趋势图:
runs/detect/train目录下执行:tensorboard --logdir='./'
终端最后一行返回一个链接,点击打开网页可以看到当前训练的数据图

















 1077
1077











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









