






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
一、配置环境
1. 官网下载地址
官网地址:【YOLOv8开源地址】
2.安装需要的环境
安装环境依赖包,请进入项目文件在文件地址栏中直接输入cmd,打开cmd后输入如何打开CMD命令行_网络用户命令行工具在哪-CSDN博客
二、准备自己的数据集
1、标签转换
XML—TXT
import xml.etree.ElementTree as ET
import os
voc_folder = r"F:/person-car/annotations/" # 储存voc格式的标注文件的文件夹
yolo_folder = r"F:/person-car/txt/" # 转换后的yolo格式标注文件的储存文件夹
class_id = ["person","car"]
# voc标注的目标框坐标值转换到yolo标注的目标框坐标值的函数
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
# 对单个voc标注文件进行转换成其对应的yolo文件的函数
def convert_annotation(xml_file):
file_name = xml_file.rstrip(".xml") # 这一步将所有voc格式标注文件取出后缀名“.xml”,方便接下来作为yolo格式标注文件的名称
print(file_name)
in_file = open(os.path.join(voc_folder, xml_file),encoding='gb18030', errors='ignore') # 打开当前转换的voc标注文件
out_file = open(os.path.join(yolo_folder, file_name + ".txt", ), 'w',encoding='gb18030', errors='ignore') # 创建并打开要转换成的yolo格式标注文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
cls_id = class_id.index(cls)
print(cls_id)
print(obj)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text),
float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_fileList = os.listdir(voc_folder) # 将所有voc格式的标注文件的名称取出存放到列表xml_fileList中
for xml_file in xml_fileList:
# 这里的for循环开始依次对所有voc格式标注文件生成其对应的yolo格式的标注文件
print(xml_file)
convert_annotation(xml_file)2、数据集划分
训练集:验证集=8:2
import os
import random
import shutil
def moveFile(Txtdir):
pathDir = os.listdir(Txtdir) # 获取标签列表
filenumber = len(pathDir)
rate = 0.2 # 定义抽取图片的比例
random_imgnum = int(filenumber * rate) # 按照比例从文件夹中取一定数量标签
sample = random.sample(pathDir, random_imgnum) # 随机选取random_imgnum数量的样本标签
print(sample)
for labelname in sample:
nameimg = os.path.splitext(labelname)[0]
shutil.move(Txtdir + labelname, Txt_target_dir + labelname)
shutil.move(Imgdir + nameimg + '.png', img_target_dir + nameimg + '.png')
'''
for imgname in sample:
#name0 = os.path.join(outdir1,os.path.basename(name))
nametxt=os.path.splitext(imgname)[0]
shutil.move(Imgdir+imgname, img_target_dir+imgname)
shutil.move(Txtdir+nametxt+'.txt', Txt_target_dir+nametxt+'.txt')
'''
return
if __name__ == '__main__':
Imgdir = "F:/person-car/images/train/" # 图像文件夹
img_target_dir = "F:/person-car/images/val/" # 划分目标图像文件夹
Txtdir = "F:/person-car/labels/train/" # 标签文件夹
Txt_target_dir = "F:/person-car/labels/val/" # 划分目标标签文件夹
# moveFile(Imgdir)
moveFile(Txtdir)
3、创建 ab.yaml 文件
train: F:/person-car/images/train/
val: F:/person-car/images/val/
nc: 2
names: ['person','car']
三、开始用自己的数据集训练模型
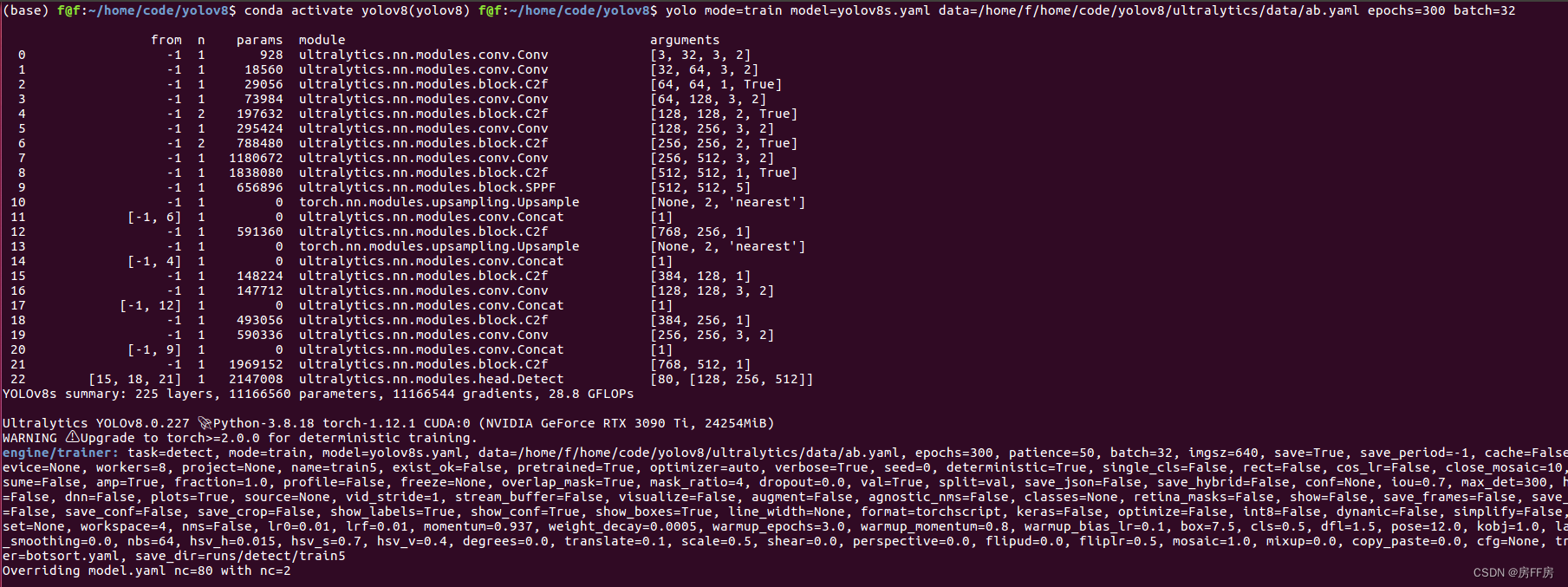
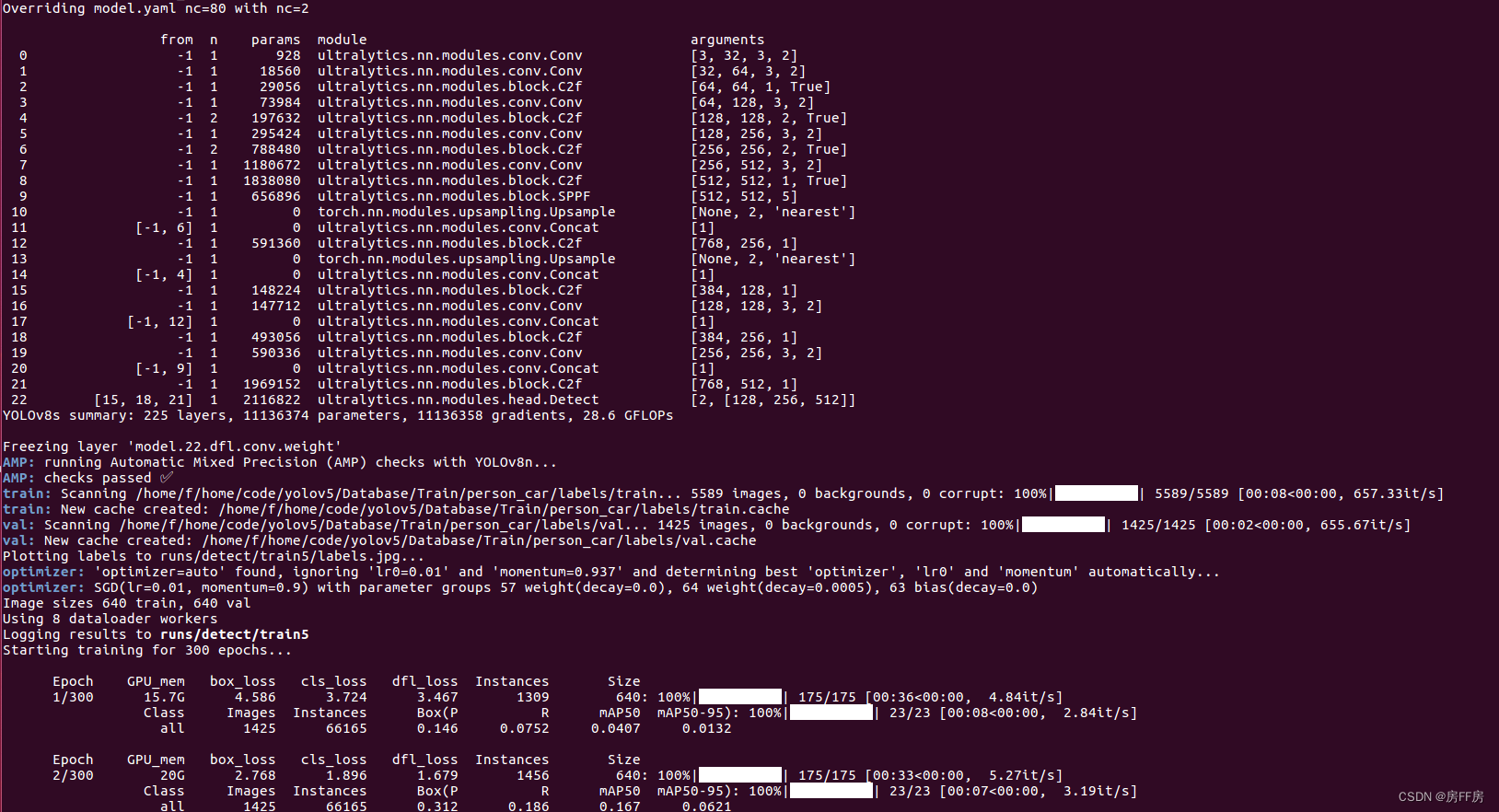
yolo task=detect mode=train model=yolov8s.pt args...
classify predict yolov8s-cls.yaml args...
segment val yolov8s-seg.yaml args...
export yolov8s.pt format=onnx args...
最后输入以下命令即可开始训练(参数很多可以修改,建议查看 官方文档
输入指令
yolo mode=train model=yolov8s.pt data=data/ab.yaml batch=16 epochs=50 imgsz=640
四、训练参数设置(default.yaml)
yolov8之配置文件yolo/cfg/default.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# Default training settings and hyperparameters for medium-augmentation COCO training
task: detect # (str) YOLO task, i.e. detect, segment, classify, pose
# yolo执行的任务类型
mode: train # (str) YOLO mode, i.e. train, val, predict, export, track, benchmark
# yolo算法的运行模式。
# Train settings 训练设置-------------------------------------------------------------------------------------------------------
model: # 选用的模型地址,比如yolov8.yaml(无预训练)和yolov8n.pt(有预训练)
data: # 数据信息地址:训练集、验证集、测试集、类别 yaml结尾的文件
epochs: 100 # 训练轮次,这里是训练100轮停止
patience: 50 # 模型在验证集上性能没有改善的情况下的连续迭代次数。
# 如果模型连续指定数量的迭代次数后仍未显示改善,则训练过程会提前停止,以避免过拟合。
# 这里是50轮没改善就停止训练
batch: 16 # batch_size,这里是一次输入16张图进行并行训练
imgsz: 640 # 输入图片尺寸,如果你输入的不是640×640,会自动调整成这个尺寸
save: True # 是否保存模型
save_period: -1 # 自动保存模型,例如100,每100轮保存一次模型,
# 除了best.pt和last.pt外,还有epoch100.pt,epoch200.pt...
# 这里-1表示禁用自动保存模型
cache: False # 是否缓存特征图,True:运行速度加快,占用内存增加;
# False:节省内存空间,运行速度变慢
device: # 指定模型运行设备 一个gpu就0,两个gpu可以选0或1,选cpu就cpu
# i.e. cuda device=0 or device=0,1,2,3 or device=cpu
workers: 8 # 并行处理图像的线程数,越高速度越快,内存占用越大
project: # 保存项目路径 i.e. data/train
name: # 保存项目名 i.e. exp
exist_ok: False # 在创建保存项目路径时如何处理该name已经存在的情况。
# True:不报错,继续执行;False:报错。一般name重了会往下排i.e.exp、exp2...
pretrained: True # 是否使用预训练的权重,不使用的话会随机生成
optimizer: auto # 用于指定在训练过程中使用的优化器
# choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto],
# 这里auto表示自动选择最优优化器
verbose: True # 用于指示是否打印出训练过程中的详细信息 i.e.每个epoch的损失值、准确率等
seed: 0 # (int) 用于控制随机数生成器的种子,用于初始化模型参数、数据扩充和随机化操作等。
# 在不同训练中seed一样,则每次运行时生成的随机数序列是相同的,有利于对比、复现;
# 不一样的话利用更大范围的随机性来增加模型的多样性和泛化能力
deterministic: True # (bool) 将模型的随机性设置为确定性的,消除模型中的随机性,
# 使得每次运行模型时都得到相同的输出结果,固定随机种子。失去随机化优势,保证可重复性
single_cls: False # (bool) 用于指定是否进行单类别检测,单目标时用能提高效率
rect: False # (bool) 是否使用数据增强中的随机裁剪,
# 适用场合:①目标物体尺寸变化②图像中存在遮挡物体③数据集类别分布不平均
# 不适场合:①物体位置关键②图像中存在重要的语义信息,i.e.文本或局部细节③数据集足够大
cos_lr: False # (bool) 是否使用余弦退火学习率
close_mosaic: 10 # (int) 禁用mosaic增强的最后第几个轮次。
# 可以指定一个整数值,表示在训练的最后第几个轮次中禁用mosaic增强。
# 用于处理由于马赛克(mosaic)效果引起的图像扭曲
# 可以减少马赛克效果对目标检测算法的干扰,提高物体检测的准确性和稳定性(不会用)
resume: False # (bool) 用于恢复训练过程中的模型检查点,可在上一次训练中断的地方接着训练
# 输入数据及模型结构要和中断前的一致
amp: True # (bool) 是否开启混合精度训练,可提高效率和性能
fraction: 1.0 # (float) 用于控制在图像上进行目标检测的尺度,默认值1.0。
# 代表了待检测图像的分辨率比例默认情况下,YOLO将整个图像传递给神经网络进行检测。
# 然而,在某些情况下,如当图像非常大时,处理整个图像可能会导致计算和内存开销增加。
# 为了解决这个问题,可以通过设置"fraction"参数来降低输入图像的分辨率。
# 例如,如果将"fraction"设置为0.5,那么YOLO将使用原始图像尺寸的50%来进行目标检测。
# 这样做可以减少计算负荷并提高性能。
# 需要注意的是,降低图像分辨率也会导致一定的信息损失,可能会影响检测精度。
profile: False # (bool) 是否开启性能分析。
# yolo会对每个检测帧进行性能分析,以便了解算法的运行时间和资源消耗情况,计算开销增加
overlap_mask: True # (bool) 用于控制是否计算目标框与网格单元的重叠掩码
# 可帮助模型筛选出包含目标物体的网格单元(segment train only)
mask_ratio: 4 # (int) 用于指定目标区域的裁剪比例 (segment train only)
# 具体来说,YOLO算法将输入图像分成一个网格,并为每个网格预测边界框和类别。
# 对于每个边界框,mask_ratio参数可以用来确定裁剪目标的区域。
# 例如,假设mask_ratio设置为0.5,表示裁剪目标的区域为原始边界框的一半大小。
# 这意味着在预测边界框时,只有中心部分的区域被用来计算目标的位置和类别信息。
# 通过使用mask_ratio参数,可以在一定程度上减少背景噪声对目标检测结果的影响,
# 提高算法的鲁棒性和准确性。(不会用)
# Classification 分类
dropout: 0.0 # (float) 使用 dropout 正则化 (classify train only)
# 0.0表示没有单元被丢弃,即不使用dropout
# 通常情况下,Dropout参数会设置为一个小于1.0的值,例如0.5。
# 这样可以随机地丢弃一部分单元,从而增加模型的鲁棒性和泛化能力。
# Val/Test settings 验证/测试设置----------------------------------------------------------------------------------------------------
val: True # (bool) 用于验证数据集的模式。
# 当val设置为True时,模型将运行在验证数据上,用以评估模型的性能和精度。
# 在这种模式下,模型通常不会进行训练或更新权重,仅仅用于评估验证集的结果。
# 这对于调整模型超参数、选择最佳模型或监控模型性能十分有用。
split: val # (str) split参数用于指定数据集的划分方式。split参数可以设置为不同的值,
# 例如"train", "val"或"test",以决定将数据集划分为训练集、验证集和测试集的比例。
# 当split参数设置为"train"时,意味着当前数据集用于训练模型,即用于更新权重。
# 当split参数设置为"val"时,意味着当前数据集用于验证模型,即用于评估模型在验证集上的性能。
# 当split参数设置为"test"时,意味着当前数据集用于测试模型,
# 即用于评估模型在未见过的测试集上的性能。
# 通过设置不同的split参数,可以将数据集划分为不同的数据子集,
# 以便在训练、验证和测试过程中使用不同的数据子集来监控和评估模型的性能。
save_json: False # (bool) 是否保存预测目标的JSON文件。
# 当save_json设置为True时,模型会将预测目标的坐标、类别等信息保存到一个JSON文件中。
# 通过保存JSON文件,可以记录和使用模型的预测结果,
# 例如进行后续的分析、可视化或与其他工具进行集成等。
save_hybrid: False # (bool) 是否保存模型的混合权重文件 (labels + additional predictions)
# 这样的保存方式使得模型可以在不同的深度学习框架中加载和使用,无需重新训练模型。
# 通过使用混合权重文件,可以方便地将YOLO模型在不同的深度学习框架中进行迁移、部署和使用。
conf: # (float, optional) 置信度(confidence)的阈值 (默认值:0.25 predict, 0.001 val)
# 通过调整conf参数,可以在准确性和召回率之间进行权衡
iou: 0.7 # (float) 用于控制在非最大抑制(NMS)过程中使用的IOU阈值
max_det: 300 # (int) 用于指定最大检测数
half: False # (bool) 是否使用半精度 (FP16),使用低精度技术进行训练和推理
# 在训练阶段,梯度的更新通常需要较高的精度,一般使用FP32以上的精度。
# 在推理阶段,对精度要求不高,可使用F16(半精度)甚至INT8(8位整型),对精度影响不会很大。
# 使用低精度的模型还可以减小模型的大小,有利于在嵌入式设备中进行部署。
dnn: False # (bool)使用OpenCV DNN进行ONNX推理,
# 如果设置为True,将使用OpenCV的DNN模块进行ONNX模型的推理。
# 这可以提供更快的推理速度,但需要安装和配置OpenCV。
# 使用ONNX格式,可以跨不同的深度学习框架(如PyTorch、TensorFlow等)共享和使用训练好的模型。
plots: True # (bool) 如果设置为True,训练/验证过程中会显示一些图表,如损失曲线和精度曲线。
# 这对于监控训练过程和调试模型很有帮助。
# Prediction settings 预测设置--------------------------------------------------------------------------------------------------
source: # (str, optional) 视频或图像地址
show: False # (bool) 是否显示预测结果图像,通常用于调试和可视化预测结果。
save_txt: True # (bool) 保存结果的txt文件
save_conf: True # (bool) 保存置信度文件
save_crop: False # (bool) 保存目标的裁剪文件,i.e.识别到一只鸟,把鸟裁剪下来保存
show_labels: True # (bool) 在图像中显示对象标签
show_conf: True # (bool) 在图像中显示置信度
vid_stride: 1 # (int) 视频帧率跨步,用于指定视频帧的采样间隔
# 它表示每隔多少帧采样一次,它的值为1表示连续帧采样,即每帧都进行目标预测。
# 如果将其设置为较大的值,比如2,则表示每隔2帧进行一次预测。
# 这样做可以减少预测的帧数,从而提高整体推理速度,但可能会降低检测的准确率。
line_width: # (int, optional) 边界框线宽
visualize: False # (bool) 可视化模型特征,当设置为True时,
# 模型会在图像上绘制边界框和类别标签来展示预测结果。
# 这对于调试和可视化模型的性能很有用,但可能会在生产环境中降低性能。
# show参数设置为True就会显示预测结果图像,visualize参数设置为True就会显示预测结果边界框和类别
# show参数设置为False,visualize参数设置为True,最终结果就是一个白色背景上标了预测框和类别
augment: False # (bool) 应用图像增强预测源,是否在预测过程中会应用数据增强技术
# 当augment设置为True时,预测时将会在每个输入图像上应用一些随机的变换,
# 例如随机裁剪、随机缩放、随机翻转等,从而模拟更多不同的实际情况,提高模型的鲁棒性和准确性。
agnostic_nms: False # (bool) 不考虑物体类别的NMS
# True时,表示不考虑不同类别之间的差异,即将所有类别的边界框组合在一起处理。
# 这意味着,如果边界框之间有重叠,不管这些边界框对应的物体是属于同一类别还是不同类别,
# 都会被NMS算法抑制,只保留具有最高置信度的边界框。
# False时,表示针对每个类别独立进行NMS处理。
# 这意味着每个类别的边界框都会被单独处理,不同类别之间的边界框不会相互影响。
# 通常情况下,当数据集中包含大量重叠较多的边界框时,设置agnostic_nms=True能够提高预测的准确性。
# 而当数据集中的物体较少或具有较少的重叠时,
# 设置agnostic_nms=False可以更好地保留不同类别之间的边界框。
classes: # (int | list[int], optional) 模型预测的类别
# i.e. class=0只预测ID号为0的类别, or class=[0,2,3]预测ID号为0、2、3的类别
retina_masks: False # (bool) 使用高分辨率分割蒙版?不会用
# 设置为True时,表示YOLO模型将使用RetinaNet中的mask分支,
# Retina masks通过在每个预测的目标上生成一个掩码,精确地表达目标的轮廓信息。
# 这样检测模型就可以更好地理解目标的形状,并为后续的分割任务提供更准确的输入。
boxes: True # (bool)在分割预测中显示框
# Export settings 导出设置(不会用)------------------------------------------------------------------------------------------------------
# export模式用于将YOLOv8模型导出为可用于部署的格式。
# 在此模式下,模型转换为可供其他软件应用程序或硬件设备使用的格式。
# 此模式在将模型部署到生产环境时很有用。
format: torchscript # (str) 导出的格式,可在https://docs.ultralytics.com/modes/export/#export-formats上选择
keras: False # (bool) 是否使用Keras进行TF SavedModel导出,
optimize: False # (bool) TorchScript: optimize for mobile
int8: False # (bool) CoreML/TF INT8 quantization
dynamic: False # (bool) ONNX/TF/TensorRT: dynamic axes
simplify: False # (bool) ONNX: simplify model
opset: # (int, optional) ONNX: opset version
workspace: 4 # (int) TensorRT: workspace size (GB)
nms: False # (bool) CoreML: add NMS
# Hyperparameters 超参数------------------------------------------------------------------------------------------------------
lr0: 0.01 # (float) 初始学习率。
# 学习率是控制模型参数更新步幅的超参数,初始学习率确定了训练开始时的参数更新速度。
# (i.e. SGD=1E-2, Adam=1E-3)
lrf: 0.01 # (float) 最终学习率(lr0 * lrf)
# 最终学习率是通过初始学习率乘以一个比例系数得到的,用于控制训练过程中学习率的衰减。
# 注意lrf其实是系数,最终学习率相较于初始学习率的系数。
momentum: 0.937 # (float) SGD 优化器的动量/Adam 优化器的 beta1。
# 动量是一种加速梯度下降过程的技术,表示在更新权重时,考虑先前的权重更新量的影响程度
# 将动量参数设置为0.937意味着在计算权重更新时,会考虑到当前梯度和先前权重更新量的约93.7%的影响,
# 先前权重更新量的影响会稍微多一些。
# 这可以用于加速优化算法的收敛,在训练过程中更好地克服局部最小值问题,并提高模型的训练效果。
weight_decay: 0.0005 # (float) 优化器的权重衰减(weight decay)。
# weight decay即L2正则化,目的是通过在Loss函数后加一个正则化项,通过使权重减小的方式,减少模型过拟合的问题。
# 设置为0.0005意味着在模型的损失函数中,将通过将所有权重的平方值乘以0.0005来增加正则化惩罚项。
# 较大的weight_decay值会增加正则化的强度,提高防止过拟合的能力,但可能会损失模型的拟合能力。
# 反之,较小的weight_decay值则可能导致过拟合。
warmup_epochs: 3.0 # (float) 热身阶段的轮数。
# 训练过程中初始阶段的一部分,在此阶段内,学习率和动量等参数逐渐增加至预设值
# 设置为3.0,意味着模型的预热轮次为3。在前3个轮次内,学习率会逐渐增大以便模型更好地适应训练数据。
# 之后,模型会使用设定的最大学习率进行训练。
warmup_momentum: 0.8 # (float) 热身阶段的初始动量。在热身阶段开始时,动量的初始值。
warmup_bias_lr: 0.1 # (float) 热身阶段的初始偏置学习率。在热身阶段开始时,偏置学习率的初始值。
box: 7.5 # (float) 边界框损失权重。用于调整边界框损失的权重,以控制其在总损失中的贡献程度。
cls: 0.5 # (float) 类别损失权重。
# 用于调整类别损失的权重,以控制其在总损失中的贡献程度(按像素进行缩放)。
# 调整策略:
# 如果你想更强调一些分类也就是更精准的类别判断你可以增加cls的值;
# 如果你想更强调一些边界框的定位你可以增加box的值。
dfl: 1.5 # (float) DFL(Dynamic Freezing Loss)损失权重。
# 用于调整 DFL 损失的权重,以控制其在总损失中的贡献程度。
# 通俗解释:
# DFL损失函数在训练神经网络时考虑了类别不平衡的问题。当某些类别出现频率过高,而另一些类别出现频率较低时,就会出现类别不平衡的情况。例如,在街景图像中,假设有100张照片,其中有200辆汽车和只有10辆自行车。我们希望同时检测汽车和自行车。这就是类别不平衡的情况,在训练神经网络时,由于汽车数量较多,网络会学习准确地定位汽车,而自行车数量较少,网络可能无法正确地定位自行车。通过使用DFL损失函数,每当神经网络试图对自行车进行分类时,损失会增加。因此,现在神经网络会更加重视出现频率较低的类别。
# 调整策略:
# 类别不平衡时使用,也就是当某些类别出现频率过高,而另一些类别出现频率较低时。
pose: 12.0 # (float) 姿态损失权重(仅姿态)。
# 用于调整姿态损失的权重,以控制其在总损失中的贡献程度(仅应用于姿态相关任务)。不会用
kobj: 1.0 # (float)关键点目标损失权重(仅姿态)。
# 用于调整关键点目标损失的权重,以控制其在总损失中的贡献程度(仅应用于姿态相关任务)。不会用
label_smoothing: 0.0 # (float) 标签平滑(label smoothing)。
# 标签平滑是一种正则化技术,用于减少模型对训练数据的过拟合程度。
nbs: 64 # (int) nominal batch size
hsv_h: 0.015 # (float) image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # (float) image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # (float) image HSV-Value augmentation (fraction)
degrees: 0.0 # (float) image rotation (+/- deg)
translate: 0.1 # (float) image translation (+/- fraction)
scale: 0.5 # (float) image scale (+/- gain)
shear: 0.0 # (float) image shear (+/- deg)
perspective: 0.0 # (float) image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # (float) image flip up-down (probability)
fliplr: 0.5 # (float) image flip left-right (probability)
mosaic: 1.0 # (float) image mosaic (probability)
mixup: 0.0 # (float) image mixup (probability)
copy_paste: 0.0 # (float) segment copy-paste (probability)
# Custom config.yaml ---------------------------------------------------------------------------------------------------
cfg: # (str, optional) for overriding defaults.yaml
# Debug, do not modify -------------------------------------------------------------------------------------------------
v5loader: False # (bool) use legacy YOLOv5 dataloader (deprecated)
# Tracker settings ------------------------------------------------------------------------------------------------------
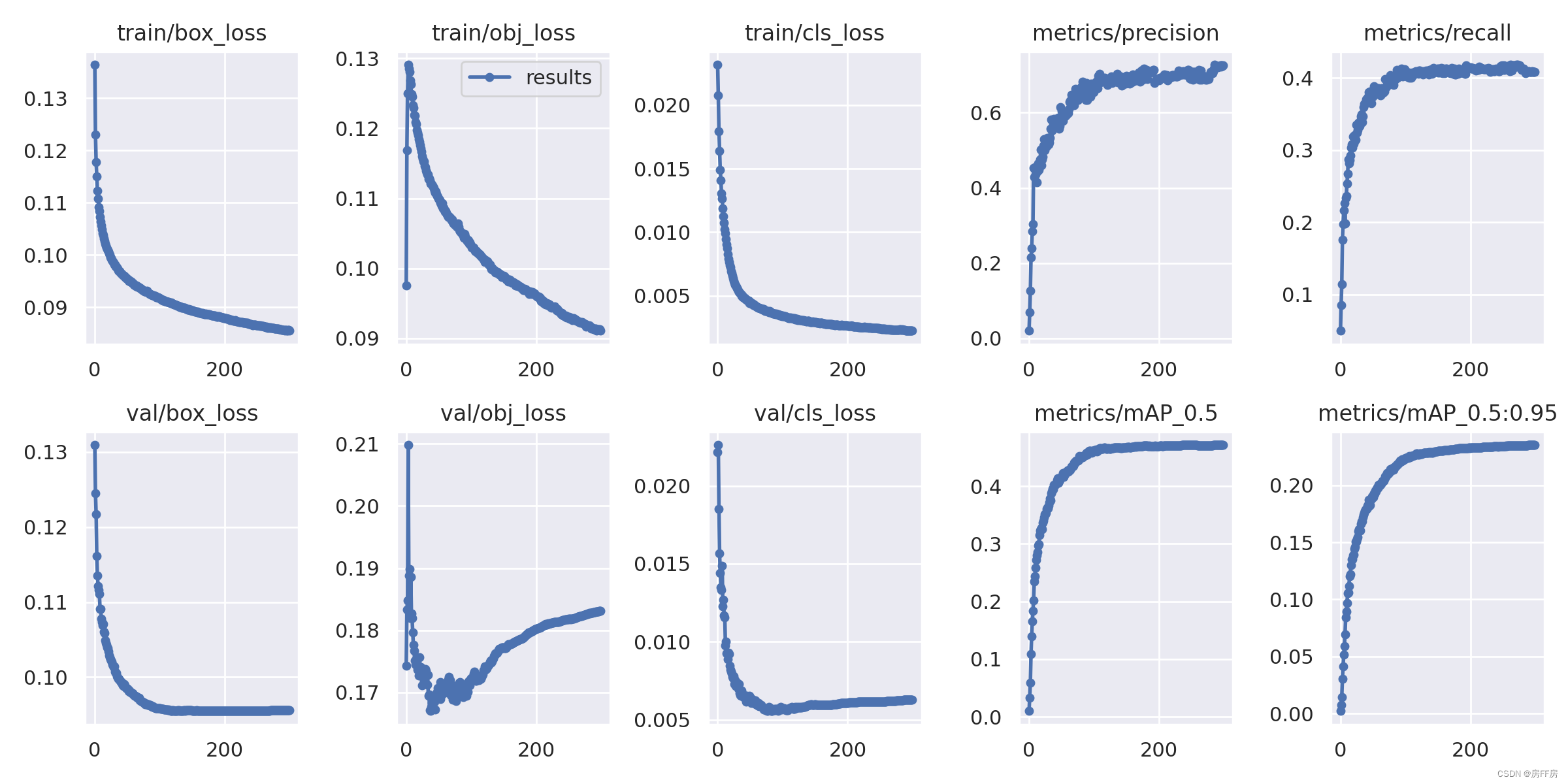
tracker: botsort.yaml # (str) tracker type, choices=[botsort.yaml, bytetrack.yaml]五、效果对比
yolov8
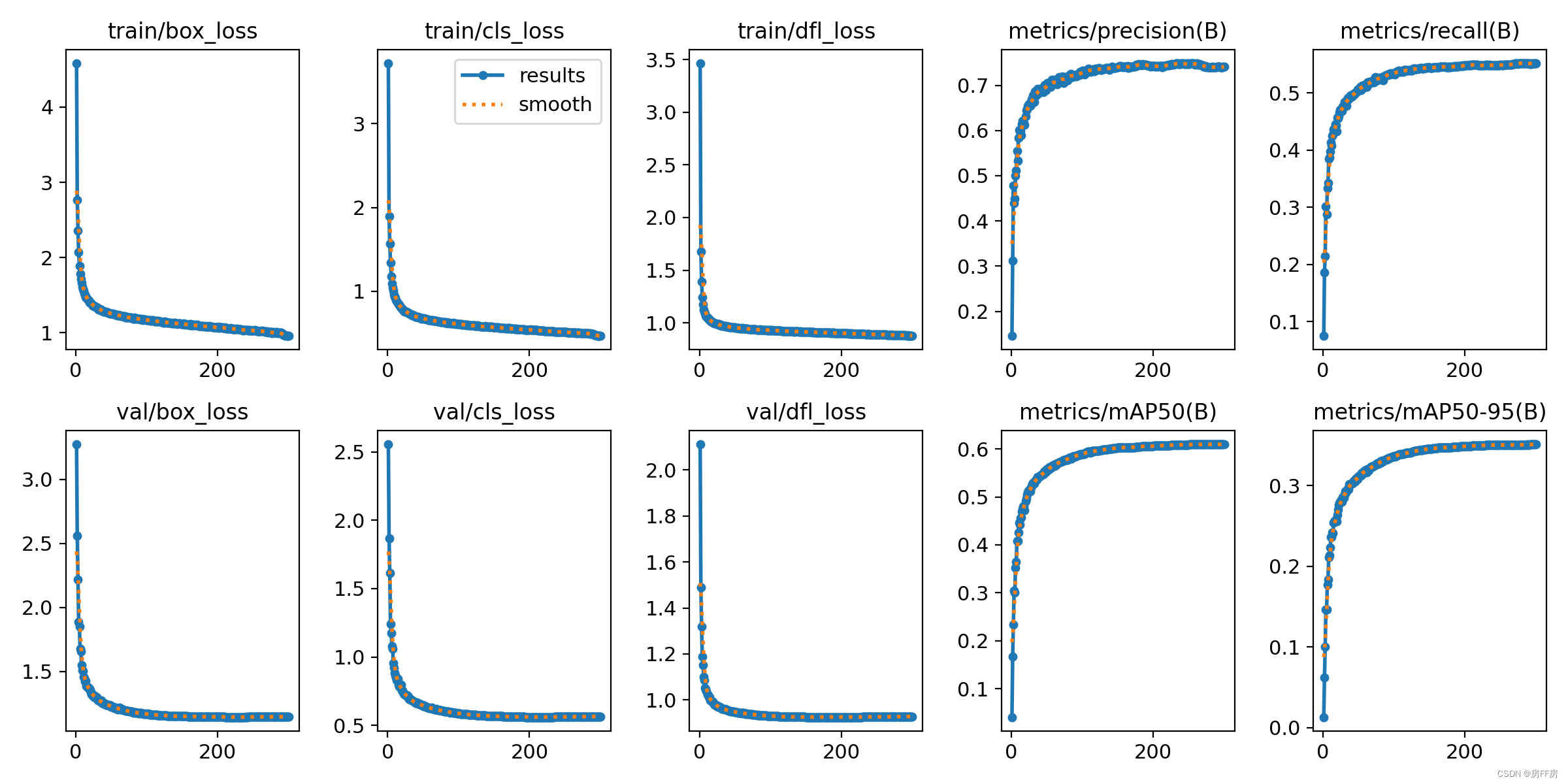
yolov5


















 4305
4305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











