






1.1 Data Preprocessing
1. clean corpus整理语料库
常见所需处理
- 小写化
- 去除中括号中的字符(如引用等)
- 去除链接
- 去除标点符号
- 去除数字等
def clean_text(text):
'''Make text lowercase, remove text in square brackets,remove links,remove punctuation
and remove words containing numbers.'''
text = str(text).lower()
text = re.sub('\[.*?\]', '', text)
text = re.sub('https?://\S+|www\.\S+', '', text)
text = re.sub('<.*?>+', '', text)
text = re.sub('[%s]' % re.escape(string.punctuation), '', text)
text = re.sub('\n', '', text)
text = re.sub('\w*\d\w*', '', text)
return text6. 去除停用词(如助词等)
停用词stopwords是指在文本中频繁出现但通常没有太多有意义的词语。这些词语往往是一些常见的功能词、虚词甚至是一些标点符号,如介词、代词、连词、助动词等,这类设计语法较多,可参考nltk库中所收录的停用词表
2. Stemming 词干提取
在语法中,一个词往往需要演化出不同的词态,如进行时,完成时等,词干提取需要从这些变化词态中推导单词的变化形式,甚至是派生相关的形式,并提取出基态 。
主要分为两种操作
1. 词干提取Stemming
区分时态, 正确地砍掉单词末尾(例如派生词词缀)
2. 词形还原 Lemmatization
分析单词,返回单词的基本形式和字典形式

词干提取algorithm
1. PorterStemmer: 通过去除后缀来生成词干,简单粗暴,比如简单的把cats剥离为cat。他并不遵循语言学,而是分阶段逐步去除后缀并生成词干
2. LamcasterStemmer: 通过查表法迭代去除后缀。一张表通常包含120条规则,按后缀的最后一个字母检索索引,在每次迭代中,尝试通过单词的最后一个字符找到适用的规则,如果没有这样的规则则终止,(还有一些其他的终止条件如如果一个单词以元音开头并且只剩下两个字母,或者如果一个单词以辅音开头并且只剩下三个字符等语法形条件)
1.2 向量化与tokenization
1.向量化
通过前处理我们可以得到一连串词干,现在我们需要将词干串转为向量以便后续模型处理,
常用的向量化处理方法有:
1. 传统的基于语法字典的向量化方法:WordNet电子词典: 将字典搬到电脑上,通过查询词得到其相关信息
2. 基于统计的向量化方法
2.1 one-hot表示:对词汇进行离散的表示, 词向量的维数为整个词汇表的长度,对于每个词,将其对应词汇表中的位置置为1,其余维度都置为0。
缺点是
- 维度非常高,编码过于稀疏,易出现维数灾难问题;
- 不能体现词与词之间的相似性,每个词都是孤立的,泛化能力差。
几个概念:
1. Tokenization:将自然语言分解为独立子模块的方法(如单词,数字等)
2. 共现矩阵:为了统计相似性,我们可以直接统计哪些词是经常一起出现的,那么这些单词肯定是类似的
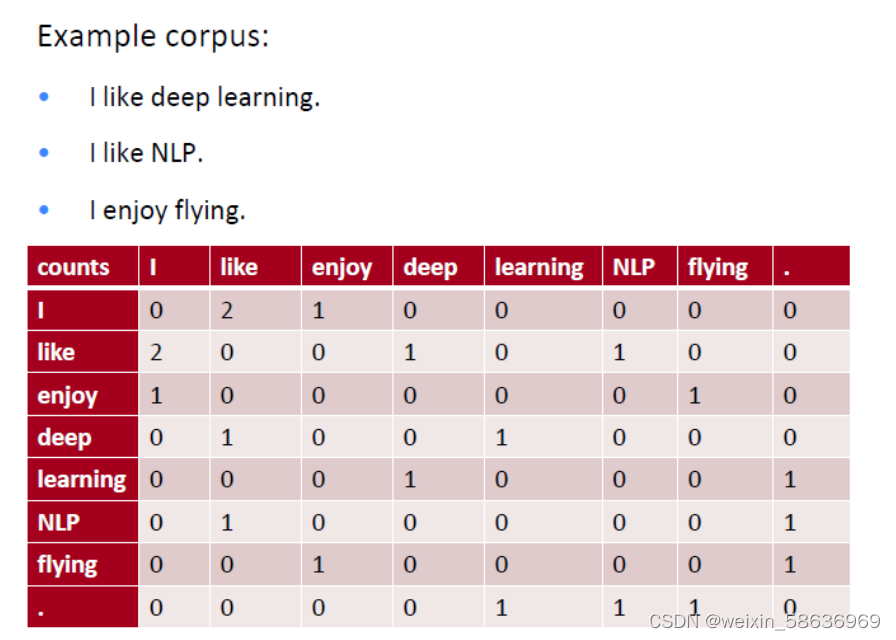
为了解决共现矩阵中以单词为单元所造成的维度过大问题,可以采用SVD分解的方法,只选取最重要的几个特征值,得到每个词的低维表示
2.2. 其他的基于统计的向量化处理方法有词袋法(Bag of word) 与词频法(TF-IDF: Term frequency-Inverse Document frequency )
1. 词袋法:
不考虑句子中单词的顺序,只考虑单词在句子中出现的次数
2. 词频法
统计单词在句子中的出现频率,根据频率决定权重,(如频率越高则重要性越低)
TF:

IDF:

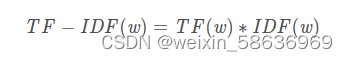
2.3. 向量空间模型VSM:
在给定文档集合C和词典D的条件下,将某篇文档通过词袋模型表示成一个个的词,而后根据 TF-IDF 为每个词计算出一个实数值;
有了文档向量,就可以利用余弦公式计算文档之间的相似度
2.4. 在向量化中可能可以用上的一些小技巧
1. 去除停用词: 如上文所提,由于停用词出现频率往往较高,需要去除以改善对关键词的提取
2. N-gram 算法:N gram的基本思想是将文本中的内容根据字节进行长度为N的滑动窗口操作,形成长度是N的字节片段序列
该算法基于类马尔科夫链的假设,第N个词的出现只与前面N-1个词相关,而与其他任何词都不相关(应用于搜索联想等)
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤 (最大频率,最小频率等),形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
每一个句子即可表示为一连串Gram计算而来的链式概率性统计
3. 基于机器学习的向量化方法
基于上述处理可引入机器学习的分类器等进行统计
如NNLM (Neural Network Language model)利用神经网络建立统计语言模型的框架
NNLM的主要思想
1. 假定词表中的每一个Word都对应着一个连续的特征向量
2. 假定一个连续平滑的概率模型,输入一段词向量的序列,模型的输出应为该序列的联合概率
3. 同时学习词向量的权重和概率模型中的参数
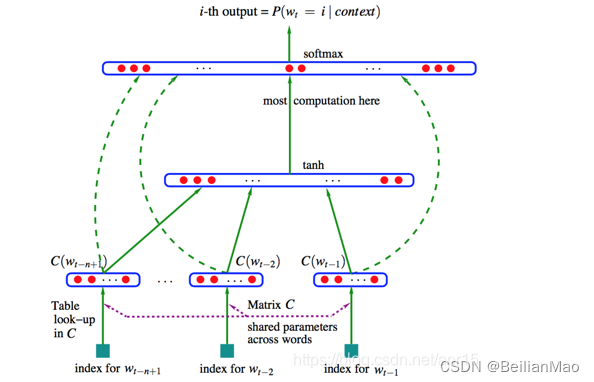
如图,模型的输入为N-1个one hot向量,通过一个共享的矩阵C,映射为N-1个distributed vector。再经过前馈网络tanh与softmax输出层映射为输出概率分布向量
模型的损失参数为Cross Entropy:
4. Word2Vec:
Word2Vec的主要思想:一个词的意义,应该由其周围经常出现的词来表达,我们所构造的向量,应该能够让相邻的词表示相似
通过将所有词向量化,定量度量词与词之间的关系。















 3233
3233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









