






Proximal Policy Optimization (PPO, 近端策略优化算法), 是OpenAI于2017年提出的强化学习算法,已成为OpenAi内部的默认强化学习算法。
强化学习与机器学习不同,他是根据agnet与环境不停实时地交互来学习的,因此与机器学习固定的数据集相比,强化学习的数据集是动态的,具有很强的随机性
Base:Policy gradient
本文所介绍的PPO是基于强化学习中Policy gradient类上改进的,而Policy gradient又是强化学习的一大重要分支,他在获得agent的状态后直接学习策略,指引agent如何与环境互动, 所以policy gradient 的输出往往可以呈一连串的state组成,被称为trajectory
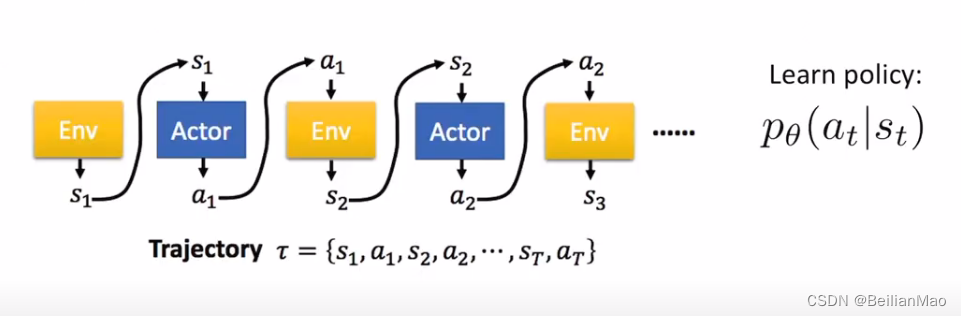
某一条trajectory发生的概率为
其中p(s_1)为初始状态概率, p_{\theta}(a_t|s_t)为action probability, p(s_{t+1}|s_t, a_t) 为state transfer probabilty
在不同的trajectory所带来的期望reward为:
将该reward 求导,由于 reward与action probability没有关系,且为了避免过大或过小的数影响连续乘积的结果,将求导过程转换为加减法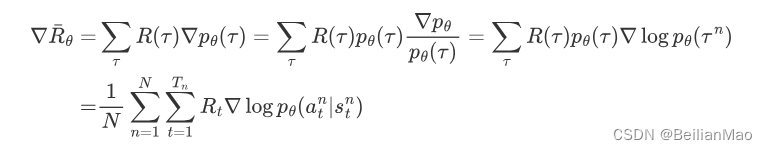
那么整条的gradient更新可写为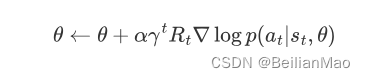
为了避免reward都是正的情况下,没有采样到的策略可能占比更新就很低。为了解决这一情况使得分布更加均匀,可以加一个Baseline使得整个reward有正有负
e,g: advantage function
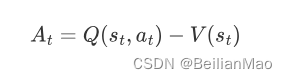
PPO
Policy gradient 存在的问题有:
1. 对于每个new policy,需要生成一个完整的trajectory,且每次gradient更新都需要生成,这就导致训练过程非常慢
2. 实验发现step size对于policy gradient的影响非常大
为了解决上述问题, PPO主要采用了三种方法进行改善
1, Minibatch: 不采用完整的一条trajectory, 而是一小部分dataset\
2. KL正则项,用KL正则华限制更新size
3. CLIP objective function,限定更新区间,稳定学习
Minibatch training
设计Reply buffer,将agent采集的数据存储到Reply buffer中,并按照mini batch的方法去sample并重新训练
即将与环境互动的on-policy训练转化成了off-policy训练,用过往经验训练,让学习数据更加高效

Regularization
用KL distance描述两个分布间的差距
在学习过程中,输入与输出的分布(即输入policy与输出policy)如果区别过大,那么他就需要更多的采样才能够让输入能够逐渐地拟合输出,因此应该保持输入与输出的policy分布不会太大
调整Objective function为:
如果KL距离大于上界,增加\beta , 若KL距离小于下界,减小\beta
CLIP Mechanism
剪切限制policy的参数在一定范围内,避免出现更新特别大的情况(如因为异常或有杂音的现象)
PPO in LLM
PPO是大模型常见的fine tune的方法, 在大模型模仿人类语言的过程中是很难设置一个准确的label判断的,但人可以给模型提供一定的feedback,把人类的思路引入fine tune的过程(RLHF)
但是人的反馈总会有延迟的,不可能训练一次给一次feedback,因此OpenAI基于自家PPO的思路,设置reward predictor神经网络,根据过往经验预测用户反馈,
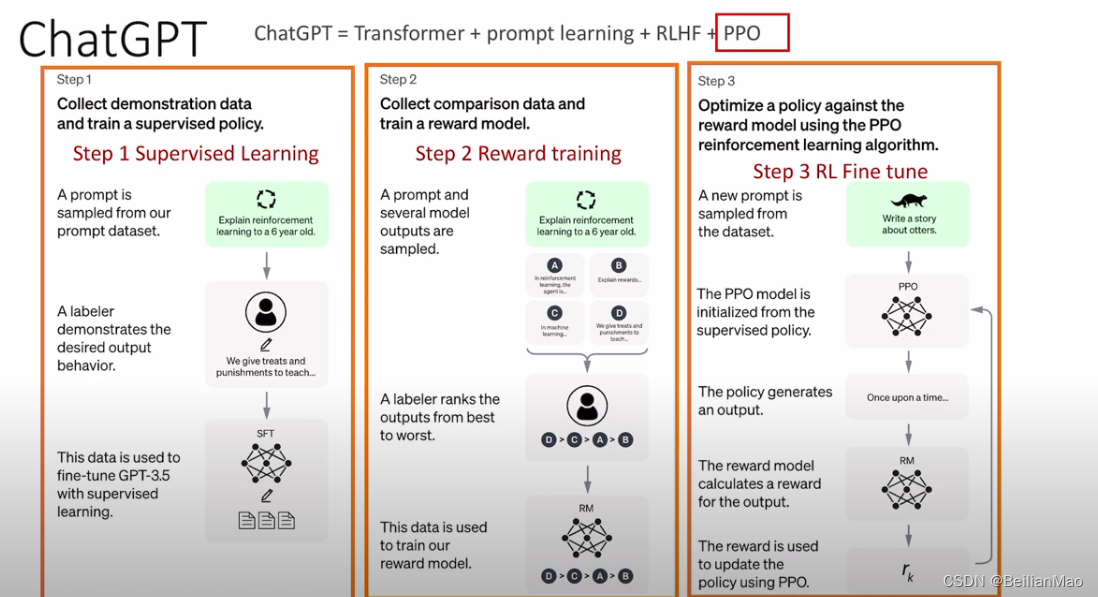
具体步骤为:
1. 根据各种数据pretrain一个模型
2. 训练reward的模型:实验人员评分模型回答的各类性能,根据评分训练一个输入为text输出为reward得分的模型
3. PPO 根据reward的模型fine tunning预训练模型,根据KL散度限制与预训练模型的差异,完成fine tuning微调















 2074
2074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









