






写在前面:词向量的意义:将字典中的单个词映射为一个固定长度的向量
基于词向量,语言可以更好地被引入机器学习模型并进行训练
1. Word2Vec
Word2Vec于2013年被提出,成为后来绝大多数NLP模型的理论基础
Word2Vec的本质就是一个将单词,依据其与上下文的关系映射为一个向量的轻量级的神经网络,这些向量应该能体现单词之间的联系
有两类Word2Vec的模型框架
1. 连续词袋模型CBOW (continuous bag of words): 知道词 的上下文
的情况下预测当前词
2. 跳词模型Skip-gram: 在知道 的情况下预测
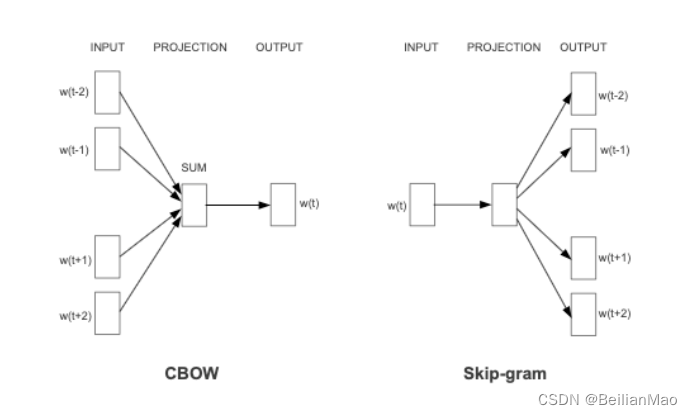
两类框架的主要区别:
1. CBOW对上下文词,无论顺序将他们的词向量拿来做当前词的预测。而Skip只用一个输入词预测,因此相比下来,CBOW比Skip gram训练快,而skip-gram对生僻词训练更好
1.1 CBOW模型
CBOW的三层结构
1. Input Layer : 接受one-hot张量 (词表长度)作为网络输入,里面存储着当前句子中上下文的one-hot表示
2. Hidden Layer: 将张量 乘以一个 word embedding张量
, 得到一个
形状的张量
3. Output Layer: 将隐藏层的结果乘以张量 , 该张量经过softmax变换后,得到使用上下文对该中心的预测结果
在实际操作中,使用一个滑动窗口(一般情况下,长度是奇数),从左到右开始扫描当前句子。每个扫描出来的片段被当成一个小句子,每个小句子中间的词被认为是中心词,其余的词被认为是这个中心词的上下文。
目标函数:
1.2 Skip-gram Model
Skip-gram model是通过输入一个词去预测多个词的概率。输入层到隐藏层的原理和simple CBOW一样,不同的是隐藏层到输出层,损失函数变成了C个词损失函数的总和,权重矩阵W'还是共享的。
几个问题:
1. Word2Vec在学什么?
本质还是在学习word和context的关系,既可以理解为学习word和context的co-currence
2. Word2Vec和对One-hot降维处理学习有啥优势
本质是相似的计算,word2vec同样可以得到中间向量与输出向量,减少one-hot输入的稀疏性。但是word2vec减少了计算量
1.3 Word2Vec训练技巧
1. Hierarchical Softmax
采用哈夫曼树,即带权路径长度最短的二叉树,即最优二叉树
在word2vec中,对词汇表中所有单词都作更新的话,随着词汇表的延长训练也会越发困难,而用哈夫曼树去构造这V个神经元(词),越靠近root节点的地方,词频是越高的,我们可以更快的使用到该词,而越靠近叶节点的地方,词频越低,这样就提高了训练效率
哈夫曼树的每一个节点都是一个逻辑回归判断,从根节点开始,向下判断,直到落到目标节点上,此时把已走的路径的LR值相乘,即得到此时的条件概率,而训练的目标就是使得整个条件概率达到最大。
- 由于是二叉树, 之前计算量为V,现在变成了log 2V。
- 由于使用霍夫曼树是高频的词靠近树根,这样高频词需要更少的时间会被找到,这符合我们的贪心优化思想。
Ref : https://www.cnblogs.com/rossiXYZ/p/13427829.html
2. 负采样
词汇表规模越大,word2vec的训练权重系数越多,使得训练速度缓慢
负采样(negative sampling)解决了这个问题,它是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。
当我们用训练样本 ( input word: "fox",output word: "quick") 来训练我们的神经网络时,“ fox”和“quick”都是经过one-hot编码的。如果我们的vocabulary大小为10000时,在输出层,我们期望对应“quick”单词的那个神经元结点输出1,其余9999个都应该输出0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们称为“negative” word。
如何选取negative words?
1, 出现频次越高的单词越容易被选作negative words。联想于停用词
2。 对于小规模数据集,选取5-20个negative words, 对于大规模数据集,选取2-5个negative words















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









