






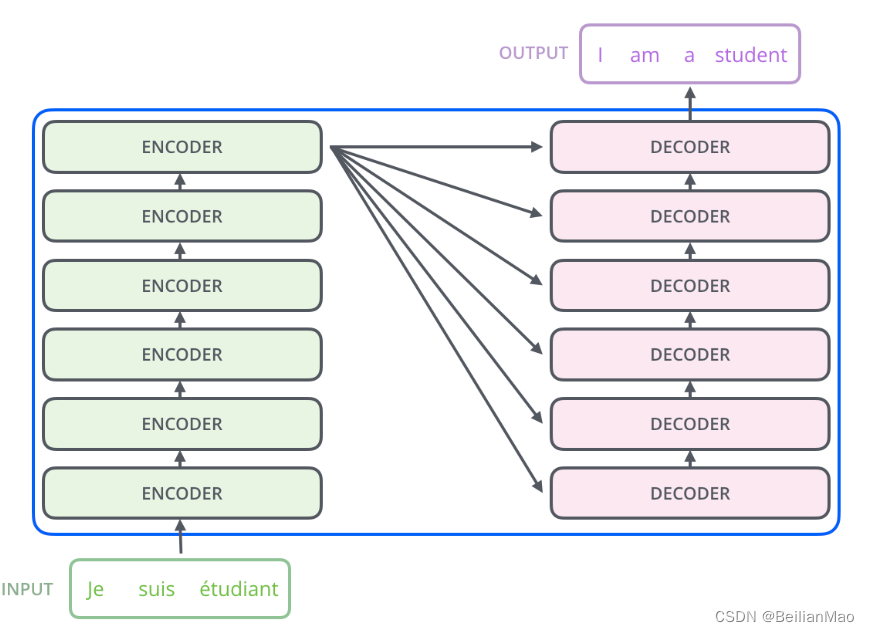
Transformer是第一个将注意力机制发挥到机制的encoder-decoder模型,其中encoder component部分由一系列encoder堆叠而成,而decoder component部分由一系列decoder堆叠而成
1. 大致结构
2. Encoder:
1. 每一个Encoder由self-attention层与feed-forward组成
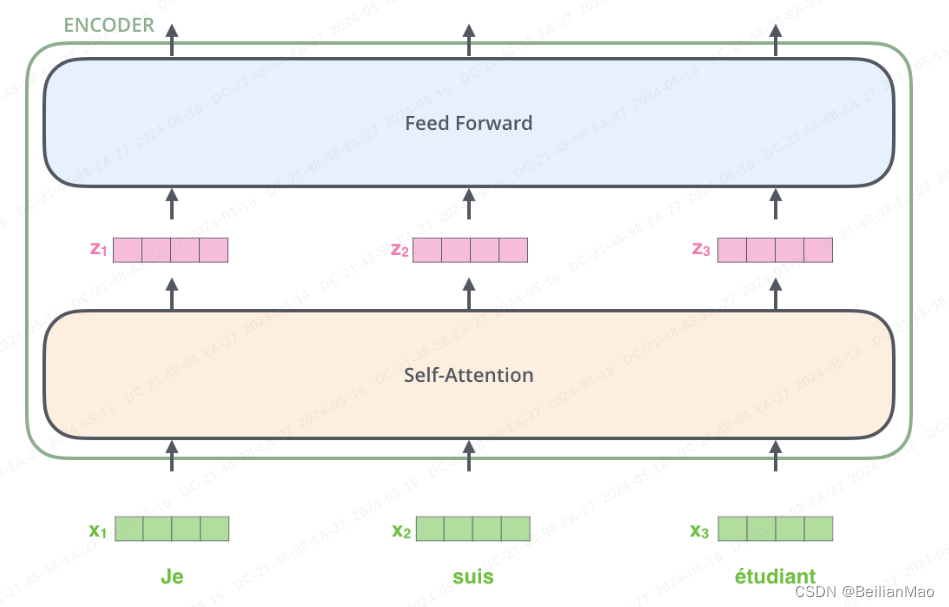
self attention: 学习同一个输入序列中不同token之间的关系
这一层从输入序列开始,由
推导attention score, 主要分为以下几个步骤
1) 将输入文本word2vec序列化
2) 序列化token经过投影(简单的全连接层映射, 分别对应 ) 得到三个不 同的矩阵
.
1. Q主要表征的是当前词与其他词的关系
2. K主要表征的是句子中所有单词的标签
3. V主要是最后输出单词的实际表示
3)dot product Q, K再经过softmax计算两个向量之间的匹配度/相似度
采用softmax的原因:
1. 归一化:softmax函数会将相似度分数转换为在[0, 1]区间内的概率分布,并且所有 概率的和为1。这种归一化处理有助于模型学习和解释每一步的注意力分配,使得 模型能够关注更重要的部分。
2. 可微性:softmax函数是可微的,这使得它可以在反向传播过程中有效地更新权 重,有助于模型的训练。
3. 非线性特性:引入了非线性特性,这有助于模型捕捉到更复杂的关系。
4)将该匹配度乘以得到最终的注意力
feed-forward: 简单的全连接层网络
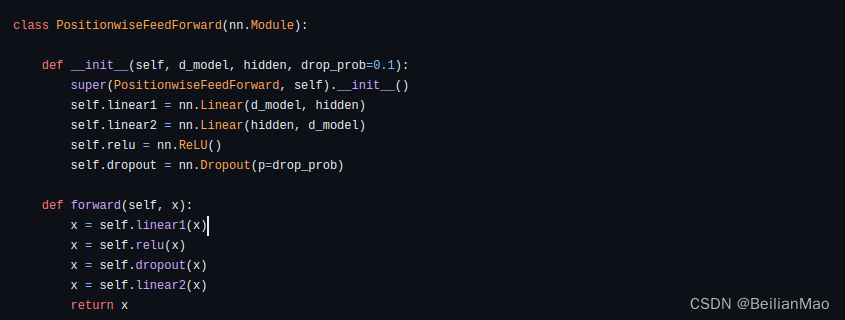
为什么Encoder采用这样的两层结构?
1. 在self attention层中,输入序列中的不同token相互连接,相互计算匹配度,而在前馈层中没有涉及匹配度的计算,而是将各匹配度平行地进行后处理
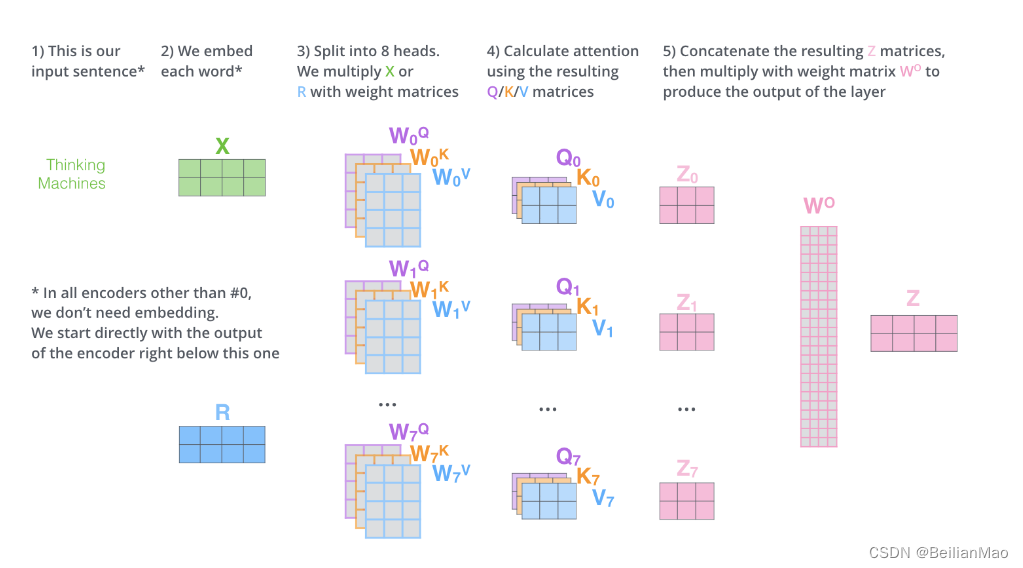
多头注意力
多头注意力将注意力进一步细分,从不同位置间的注意力映射到子空间"representation subspace"中,以应对实际语境中更加错综复杂的代词等
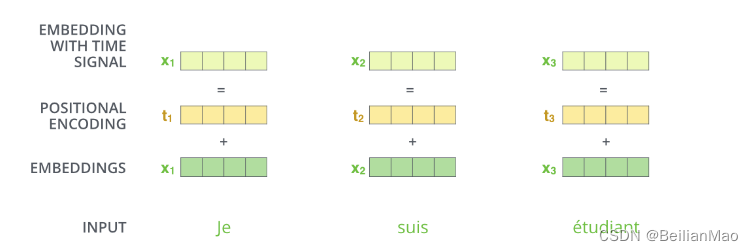
Positional Encoding
输入token序列前为了强调当前token在输入语句中的位置还需要附上位置信息
除了原版的绝对位置信息之外还有后来发展出的强调相对位置信息的旋转位置编码
Ref: https://zhuanlan.zhihu.com/p/454482273
Layer norm
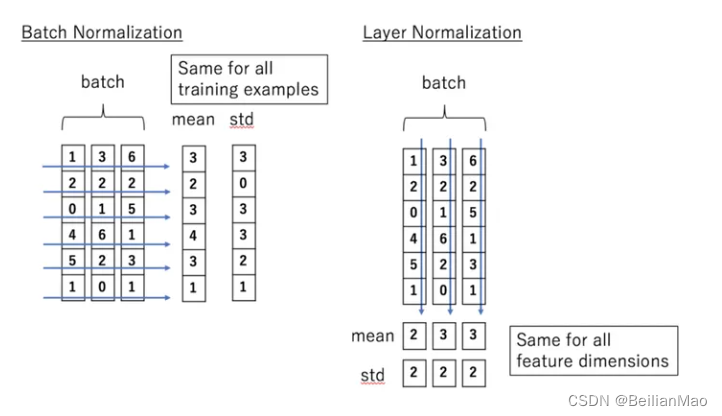
为什么不用batch norm?
- BN在mini-batch较小的情况下不太适用。BN是对整个mini-batch的样本统计均值和方差,当训练样本数很少时,样本的均值和方差不能反映全局的统计分布信息,从而导致效果下降。
因此,BN在RNN类似的不定输入的任务时,效果较差
BN是对batch的维度去做归一化,也就是针对不同样本的同一特征做操作。LN是对hidden的维度去做归一化,也就是针对单个样本的不同特征做操作。因此LN可以不受样本数的限制。
3. decoder
每一个decoder则由self-attention, encoder-decoder attention和feed-forward 组成, decoder结合encoder所计算的注意力,根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask 操作遮盖住 i+1 之后的单词。
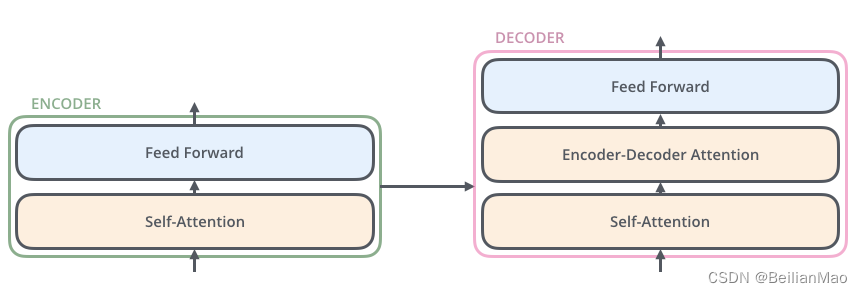
self attention与encoder中近乎类似,只有在处理叠加当前所得结果时,会添加mask,保证注意力集中在当前
Encoder-Decoder layer用来接收Encoder所计算得出的QKV注意力分数
整个Decoder的工作以一个起始符开始,以一个结束符结束,期间一个个token,根据之前的预测往前吐















 2928
2928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









