






我们在分析问题的时候经常使用临时列,如果新列全部使用赋值的方式生成,原数据将会比较杂乱。采用`df.assign`的方法生成新的列可以使用链式编程完成。
#导入数据
data = [['1', '2020-11-28', '4', '32'], ['1', '2020-11-28', '55', '200'], ['1', '2020-12-3', '1', '42'], ['2', '2020-11-28', '3', '33'], ['2', '2020-12-9', '47', '74']]
employees = pd.DataFrame(data, columns=['emp_id', 'event_day', 'in_time', 'out_time']).astype({'emp_id':'Int64', 'event_day':'datetime64[ns]', 'in_time':'Int64', 'out_time':'Int64'})
#注意df.assign(k,v)中,v必须三与原来数据同索引的一个series
employees.assign(total=employees.out_time-employees.in_time)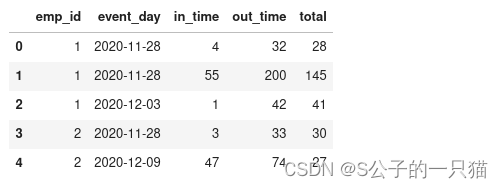
问题:间leetcode 1741
方法一:
import pandas as pd
def total_time(employees: pd.DataFrame) -> pd.DataFrame:
df=employees.groupby(by=['event_day','emp_id'],as_index=False).sum()
df['total_time']=df.out_time-df.in_time
return df[['event_day','emp_id','total_time']].rename(columns={'event_day':'day'})
采用直接赋值的方法得到新列“total_time”
如果首聚合再使用assign方法,与先使用assign方法创建新列再聚合结果不同。如图:
import pandas as pd
def total_time(employees: pd.DataFrame) -> pd.DataFrame:
return employees.groupby(by=['event_day','emp_id'],as_index=False).sum().assign(total_time=employees.out_time-employees.in_time)[['event_day','emp_id','total_time']].rename(columns={'event_day':'day'})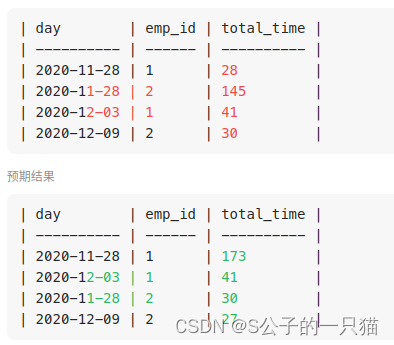
对比:
import pandas as pd
def total_time(employees: pd.DataFrame) -> pd.DataFrame:
return employees.assign(total_time=employees.out_time-employees.in_time).groupby(by=['event_day','emp_id'],as_index=False).sum()[['event_day','emp_id','total_time']].rename(columns={'event_day':'day'})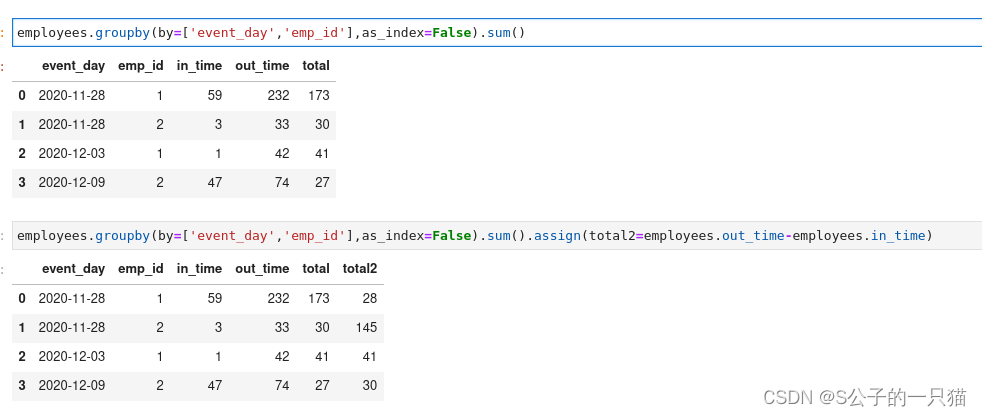
assign内的employees还是没有合并前的employees表。因此total与total2不一致。
总结:如果使用assign方法应该现建新列再聚合。


















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









