






本次想为大家介绍如何在YOLOv5中加入CBAM通道注意力机制。我会从三个方面来介绍CBAM注意力机制:CBAM注意力机制、CBAM注意力机制计算过程以及它的代码实现。
一. CBAM注意力机制
CBAM注意力机制是在ECCV2018年提出的。
论文名称:《CBAM: Convolutional Block Attention Module》
论文地址:https://arxiv.org/abs/1807.06521v2![]() https://arxiv.org/abs/1807.06521v2
https://arxiv.org/abs/1807.06521v2
1.1 模型简介
针对传统的卷积神经网络只关注特征图的局部信息,往往忽略了全局信息的弊端。作者提出了Convolutional Block Attention Module(CBAM)注意力机制,该注意力模型是一种结合空间(spatial)和通道(channel)的注意力机制模块。相比于SEnet,多了对于空间通道的关注力。
1.2 模型网络结构
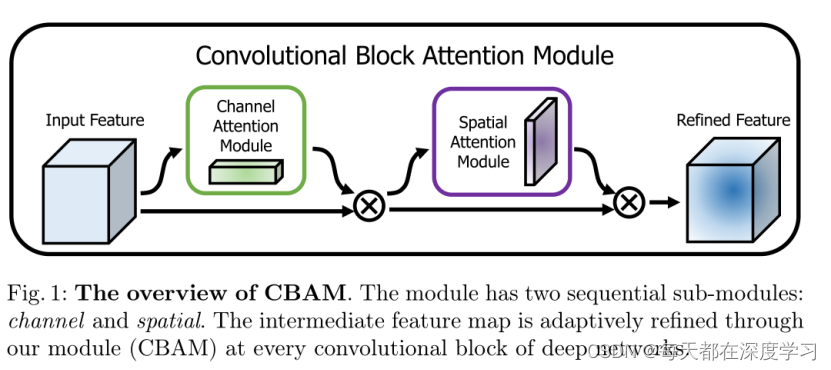
可以看出该网路中有两个重要的模块。即Channel Attention Module(通道注意力模型)和Spatial Attention Module(空间注意力模型)两个部分。模型总体的计算流程如下:
算法流程:
- 输入一张特征图。
- 输入图像经过Channel Attention Module,Channel Attention Module用Mc表示,得到通道注意力权重图Mc(N)。
- 得到的Mc(N)与输入特征图进行相乘操作,得到M。
- M继续输入到Spatial Attention Module,Spatial Attention Module用Ms表示,得到空间注意力权重图 Ms(M)。
- 得到的Ms(M)与输入特征图M进行相乘操作,得到最终的特征图Q。
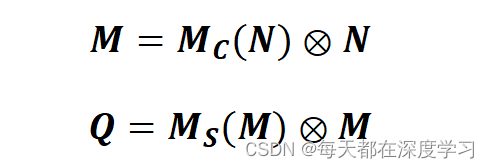
1.2.1 Channel Attention Module(通道注意力模块)
通道注意力模块需要将输入经过两步操作,一步是经过MaxPool提取特征图的局部信息;另一步是经过AvgPool提取特征图的全局信息。经过两步池化操作,提升了模型对于特征图的特征的提取能力。
1.2.2 Spatial Attention Module(空间注意力模块)
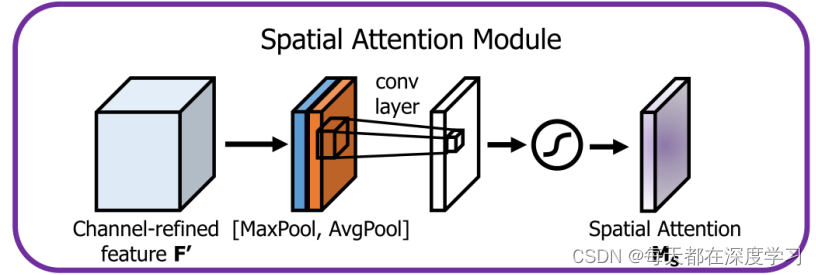
输入特征图经过全局最大池化和全局平均池化分别将输入特征图压缩为两个维度为[H,W,1]的特侦图,将两个特征图concat到一起,之后经过一个卷积[7*7(padding为3)或者3*3(padding为1)]操作,将输出通道数再变为1,融合局部和全局的信息,使得网络可以学习到图像中最重要的区域。最后经过sigmoid激活函数,得到想要的Spatial Attention Maps。
二. 模型计算过程
下面是我自己的推理过程,可能会有细节的理解错误,希望看到的各位大佬给指出一下(不玻璃心)。

三. 代码实现
我所选择的是YOLOv5(6.2)版本,尝试过可以在6.0版本加模块成功。具体的操作如下:
3.1 修改common.py
需要在common.py中加入如下代码,最好加载代码的最后,这样是不会出错的。
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class CBAM(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, ratio=16, kernel_size=7): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAM, self).__init__()
# c_ = int(c2 * e) # hidden channels
# self.cv1 = Conv(c1, c_, 1, 1)
# self.cv2 = Conv(c1, c_, 1, 1)
# self.cv3 = Conv(2 * c_, c2, 1)
# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
self.channel_attention = ChannelAttention(c1, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
out = self.channel_attention(x) * x
# print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return out3.2 修改yolo.py
首先在yolo.py中找到def parse_model(d, ch)这个函数,只需要在里面加上CBAM这个模块就可以,具体可以参照我给的照片。
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
with contextlib.suppress(NameError):
args[j] = eval(a) if isinstance(a, str) else a # eval strings
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x]:
args.insert(2, n) # number of repeats
n = 13.3 修改yolov5s.yaml文件
这里加入CBAM模块即可,加模块的方法有很多。
第一种是在每一种SPPF后面加入CBAM注意力机制。
第二种是在每个特征提取模块C3后加入CBAM注意力机制。
第一种代码如下:
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
[-1, 3, CBAM, [1024]], # 10
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]第二种代码修改方式如下:
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 3, CBAM, [128]], # 3
[-1, 1, Conv, [256, 3, 2]], # 4-P3/8
[-1, 6, C3, [256]],
[-1, 3, CBAM, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 9, C3, [512]],
[-1, 3, CBAM, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 10 -P5/32
[-1, 3, C3, [1024]],
[-1, 3, CBAM, [1024]],
[-1, 1, SPPF, [1024, 5]], # 13
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 9], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 21 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 18], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 24 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 27 (P5/32-large)
[[21, 24, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]好了,到这里我们就完成了今天的任务,祝大家实验提点多多!















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









