







一.文章提出背景:
传统的深度学习学习范式以混合线性投影(即卷积和线性层)和非线性激活构成。在做将输入特征从低维到高维映射时的解决办法为:增加网络的深度(其实也就是提高通道数),这样带来的直接影响就是大大增加了模型的复杂度、计算量(这是一种显示高维特征映射的方法);那对于这个问题呢,在Transformer中也提出了一种高维特征映射的方法:自注意力机制最显著的特征是将特征映射到不同的空间,然后通过点积运算构建一个注意力矩阵。然而,这种实现并不高效,随着标记数量的增加,注意力复杂度呈二次增长。(这也就是我们常说的Transformer二次计算复杂度)。
本文就提出了一种隐式高维空间映射的操作——星操作。只需要几层,就可以将输入特征维度映射到近乎无限的维度。
(问:为什么要将特征映射到高维?
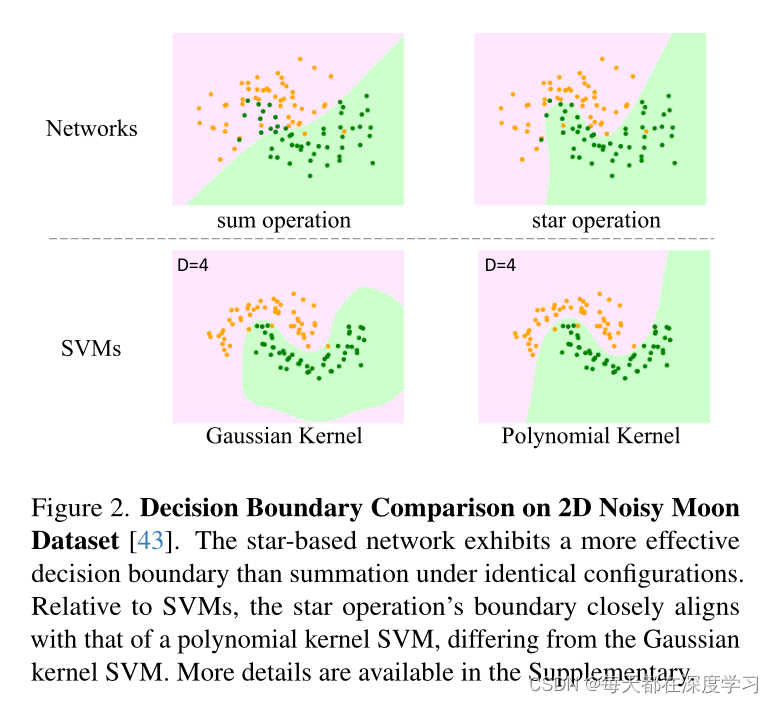
解:高维空间可以提供更多的信息和表达能力,因为它可以捕获数据之间更细微的差别和复杂的模式。例如,在图像处理中,高维特征空间可以包含关于图像的更多细节,如颜色、纹理、形状等。我们考虑,一个在二维是简易非线性的函数关系到了四维或者更高维度可能就变成了一个简单的线性函数,这样的优点是什么?我们可以更好地区分他们的特征了。给个图理解一下,这个图说明什么?正是由于star operation可以将特征映射到很高的维度,我们才可以很容易的学习这些数据的特征。当然理解不一定正确,欢迎大家指正!)
二.关于这个问题,其它学者提出了哪几类的解决方案?
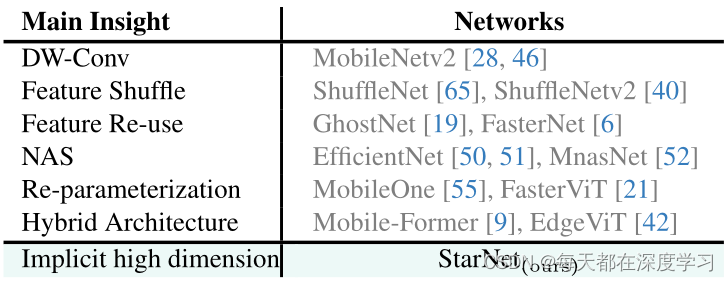
-
DW-Conv(深度可分离卷积):
深度可分离卷积是一种减少计算量的技术,它分开处理空间卷积和深度卷积。MobileNetv2利用这种技术来降低模型的计算复杂性。优点:大幅减少计算量和参数数量适用于计算资源受限的环境,如移动设备。缺点:可能会损失一些空间特征的学习能力,并且对于复杂场景需要充分提取和利用深浅特征的场景利用率差一些。 -
Feature Shuffle(特征洗牌):
特征洗牌技术用于改善网络中特征的流动性,增强模型的表达能力。ShuffleNet和ShuffleNetv2通过洗牌操作减少计算量,同时保持特征的有效混合。优点:通过重组特征通道,增强了特征之间的交互。 缺点:需要精心设计网络特征融合架构。 -
Feature Re-use(特征重用):
特征重用是一种减少模型参数和计算量的技术,通过重用已经计算的特征图。GhostNet和FasterNet通过特征重用来构建高效的网络。优点:通过重用已经计算的特征图,减少了计算量和参数数量;可以有效增加模型的深度而不受参数量的限制。 缺点:需要精心设计网络特征融合架构;重用特征可能导致信息的损失,影响模型性能。 -
Re-parameterization(重新参数化):
重新参数化是一种技术,通过改变网络的参数表示来减少计算量或提高性能。MobileOne和FasterViT通过重新参数化技术来优化网络。 优点:通过改变网络参数的表示方式,可以减少参数数量或提高性能。缺点:重新参数化可能会引入额外的设计复杂性。 -
Hybrid Architecture(混合架构):
混合架构结合了不同的网络设计原则,以提高效率和性能。Mobile-Former和EdgeViT结合了卷积网络和Transformer架构的特点。优点:结合了不同架构的优点,如卷积网络的精确空间建模和Transformer的长距离依赖捕获能力,提高模型对不同类型特征的学习能力。 缺点:融合架构带来参数量以及计算量的增加必不可免。
三.文章的方法
3.1 原理
简单分析一下原理吧。在单层神经网络中,星操作通常写为:
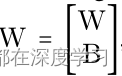
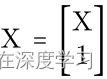
![]()
其实就和普通的矩阵乘法没有什么区别。作者在文中说到,经过这种操作呢,可以实现在低维空间内实现高维特征映射。具体体现如下图所示:

最终的结果实现了在(d+1)(d+2)/2近似维度的表示,显著放大了特征维度。当考虑到将这种操作扩展到多层时,则每一层可实现计算过程中维度的扩展可达到
(其中d为输入通道数),由此类推可以验证仅仅叠加几层即可达到近乎无限的特征维度。
3.2 结构和代码
作者在文章中反复指出,此操作可以实现在不用设计复杂的网络结构并且不用任何细致的超参数微调情况下达到很好的精度。
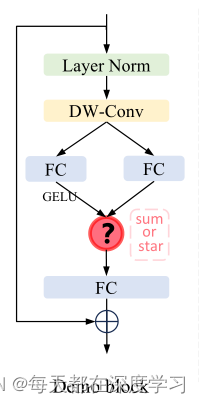
对应代码:
class Block(nn.Module):
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6, mode="sum"):
super().__init__()
self.mode = mode
self.norm = nn.LayerNorm(dim)
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.f = nn.Linear(dim, 6 * dim)
self.act = nn.GELU()
self.g = nn.Linear(3 * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else 1.
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.norm(x)
x = self.dwconv(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
x = self.f(x)
B, H, W, C = x.size()
x1, x2 = x.reshape(B, H, W, 2, int(C // 2)).unbind(3)
x = self.act(x1) + x2 if self.mode == "sum" else self.act(x1) * x2
x = self.g(x)
x = input + self.drop_path(self.gamma * x)
return x解读一下:在这个block里面保留两种张量结合模式:一种是普通的求和(sum)操作,这个操作的优点就是计算效率快,缺点是不能实现高维特征映射,依赖于网络深度的堆叠;另一种就是提出的元素明智乘法(star-operation在代码里叫做mul),这种操作的优点是:隐式实现高维特征映射,不需要堆叠网络深度。
3.3 无激活函数网络
在以往的神经网络搭建中,常常利用激活函数来增强模型的非线性。然而作者提出,是否可以构建一个无激活函数网络,并且也在实验中进行了尝试(作者在Demonet),以下是他的验证结果:
class DemoNet(nn.Module):
def __init__(self, in_chans=3, num_classes=1000,
depth=12, dim=384, drop_path_rate=0.,
layer_scale_init_value=1e-6, head_init_scale=1.,
mode="mul", **kwargs):
super().__init__()
assert mode in ["sum", "mul"]
self.num_classes = num_classes
self.stem = nn.Conv2d(in_chans, dim, kernel_size=16, stride=16)
dp_rates = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]
self.blocks = nn.Sequential(*[Block(dim=dim, drop_path=dp_rates[i],
layer_scale_init_value=layer_scale_init_value, mode=mode)
for i in range(depth)])
self.norm = nn.LayerNorm(dim) # final norm layer
self.head = nn.Linear(dim, self.num_classes)
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.stem(x).permute(0, 2, 3, 1)
x = self.blocks(x)
x = self.norm(x.mean([1, 2]))
x = self.head(x)
return x
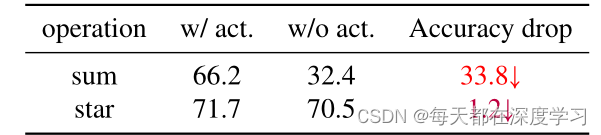
可见,star相较于sum,不依赖于激活函数来强化模型非线性表达能力。(究其原因也是因为隐式高维特征映射)
四.实验分析
作者在实验部分使用了一个新的网络——StarNet。
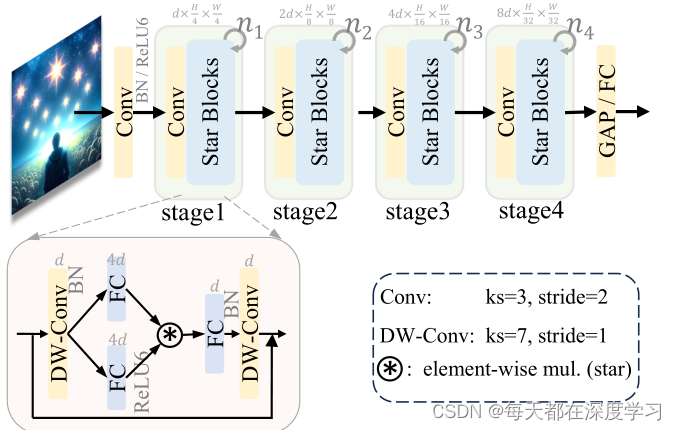
class StarNet(nn.Module):
def __init__(self, base_dim=32, depths=[3, 3, 12, 5], mlp_ratio=4, drop_path_rate=0.0, num_classes=1000, **kwargs):
super().__init__()
self.num_classes = num_classes
self.in_channel = 32
# stem layer
self.stem = nn.Sequential(ConvBN(3, self.in_channel, kernel_size=3, stride=2, padding=1), nn.ReLU6())
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth
# build stages
self.stages = nn.ModuleList()
cur = 0
for i_layer in range(len(depths)):
embed_dim = base_dim * 2 ** i_layer
down_sampler = ConvBN(self.in_channel, embed_dim, 3, 2, 1)
self.in_channel = embed_dim
blocks = [Block(self.in_channel, mlp_ratio, dpr[cur + i]) for i in range(depths[i_layer])]
cur += depths[i_layer]
self.stages.append(nn.Sequential(down_sampler, *blocks))
# head
self.norm = nn.BatchNorm2d(self.in_channel)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.head = nn.Linear(self.in_channel, num_classes)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear or nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm or nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
x = self.stem(x)
for stage in self.stages:
x = stage(x)
x = torch.flatten(self.avgpool(self.norm(x)), 1)
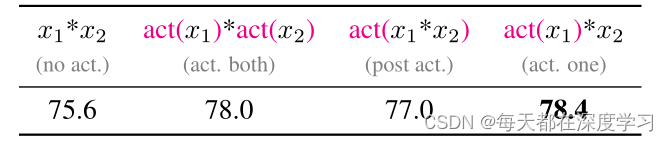
return self.head(x)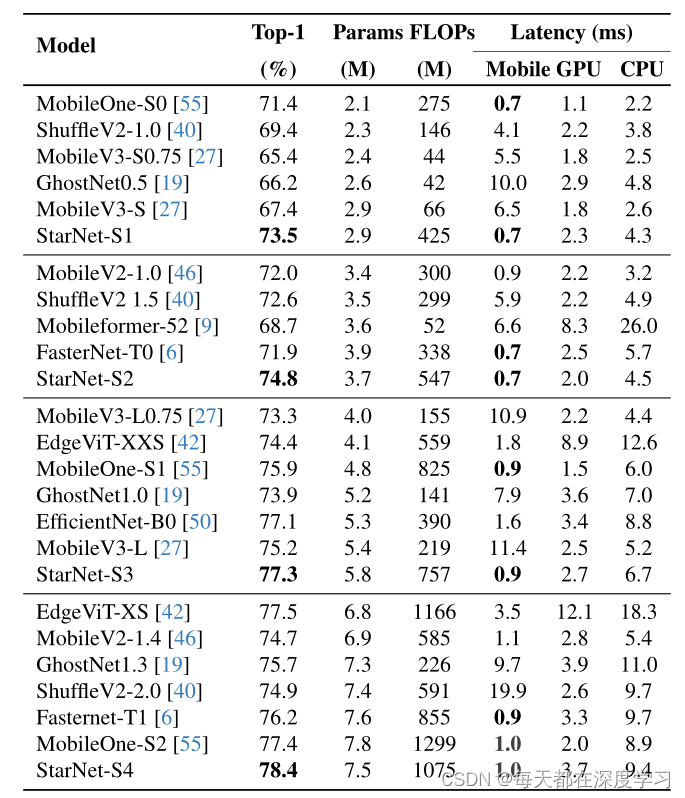 StarNet确实快且准。作者在该实验的基础上还进行了其他实验。包括star block不同位置的消融实验,结果显示:前两个block的结果并不是很好,原因可能是:在非常窄的宽度下,ReLU6激活会导致一些特征变为零。在星形运算的背景下,这导致其隐含的高维空间中的许多维度也变为零,从而限制了其全部潜力;另外还进行了激活函数位置的实验,实验结果表示:不同的激活函数放置位置对结果也有细微的影响。
StarNet确实快且准。作者在该实验的基础上还进行了其他实验。包括star block不同位置的消融实验,结果显示:前两个block的结果并不是很好,原因可能是:在非常窄的宽度下,ReLU6激活会导致一些特征变为零。在星形运算的背景下,这导致其隐含的高维空间中的许多维度也变为零,从而限制了其全部潜力;另外还进行了激活函数位置的实验,实验结果表示:不同的激活函数放置位置对结果也有细微的影响。
至此,文章阅读结束。见解不一定正确,恳请大家批评指正!

















 2535
2535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









