







代码地址: mirrors / MCG-NJU / mixformer · GitCode
论文地址:2302.02814.pdf (arxiv.org)
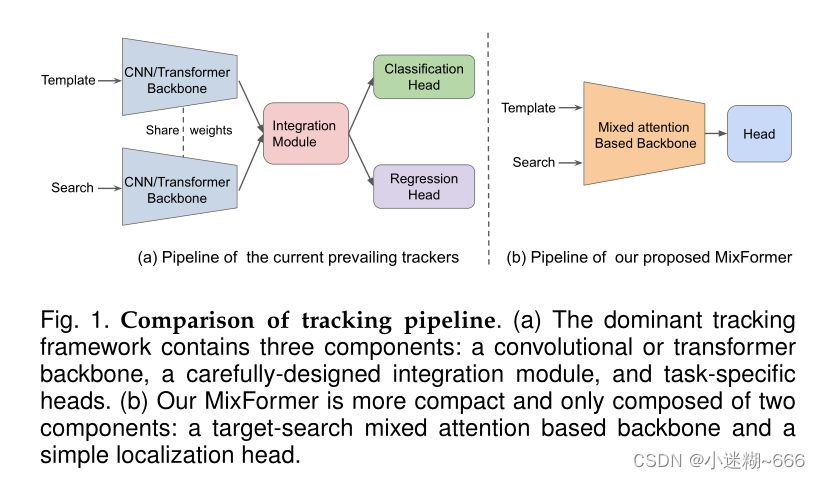
常用的目标跟踪器流程是特征提取、目标信息融合、边界框估计;为了简化这一流程,文章提出了一个基于transformer的跟踪框架,将特征提取和目标信息融合整合到了一块,即MixFormer,核心就是提出MAM(混合注意力模块),用来同时提取特征以及目标信息融合,Mixformer也就是堆叠多个MAM,最后再加个定制化头所构成。此外,为了在线跟踪中处理多个模板,文章提出了一个有效的分数预测模块来选择高质量的模板。
MAM的输入是模板和搜索图像,在这二者之间可分离的token序列执行双重混合注意力操作,也就是对模板和搜索图像本身的token序列作自注意力,同时对其二者之间的token序列做交叉注意力,如下图a所示。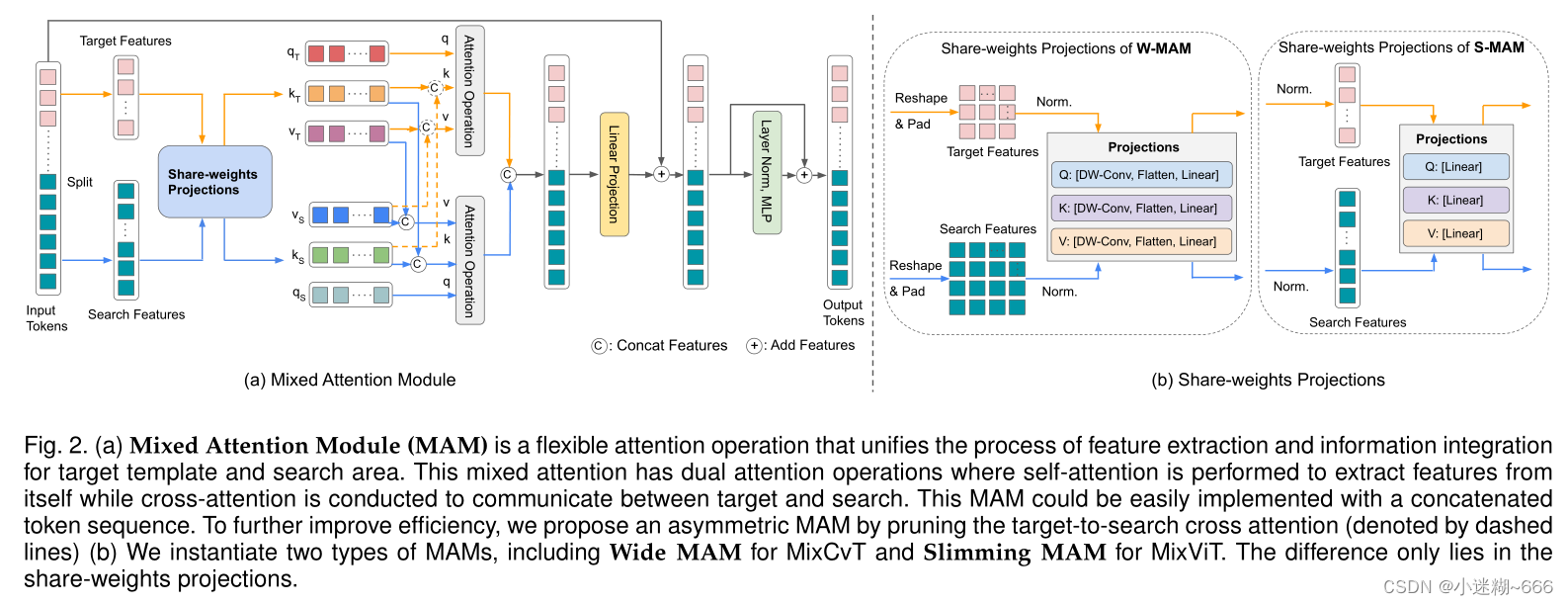 W-MAM:在每个特征图(q、k、v)上执行可分离的深度卷积,接着展平每个目标和搜索特征图,并通过线性投影生成qkv,将此时所得到的目标qkv和搜索qkv经混合注意力操作,Attention Operation被定义如下:
W-MAM:在每个特征图(q、k、v)上执行可分离的深度卷积,接着展平每个目标和搜索特征图,并通过线性投影生成qkv,将此时所得到的目标qkv和搜索qkv经混合注意力操作,Attention Operation被定义如下: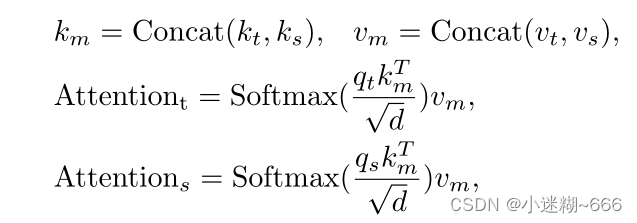
其中d时k的维度,Attentiont和Attentions分别是目标和搜索的注意力图。然后将目标token和搜索token连接起来通过线性投影,最后通过层规范化和MLP函数。
S-MAM:W-MAM由于reshape操作和深度卷积操作导致跟踪速度缓慢,而且缺乏灵活性。为解决这些问题,提出了S-MAM,其实就是将W-MAM里边的深度卷积那个操作移除掉了,后续的操作和W-MAM一样。
非对称混合注意力方案:从目标查询到搜索区域的交叉注意力并不是很重要,很有可能会因为一些潜在的干扰带来负面影响。为了降低MAM的计算成本,提出了一种定制的非对称混合注意力方案,定义如下: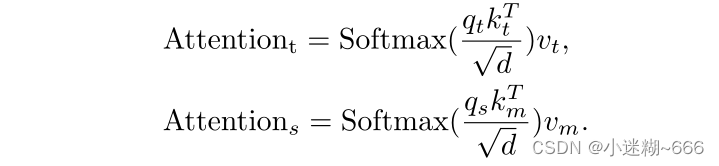
分数预测模块(SPM)由两个注意力块和一个三层感知器组成,首先,可学习分数token用作参与搜索ROI token的查询,接着得分token关注初始目标token的所有位置,将挖掘的目标与第一目标进行比较,最后通过MLP层和sigmoid激活生成最后得分结果。SPM训练是在骨干网络训练之后进行的,使用标准的交叉熵损失进行训练: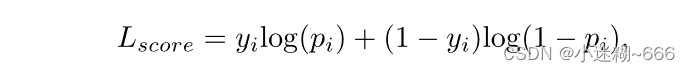
其中,yi是真实标签,pi是预测的置信度分数,只有在达到更新间隔时才更新在线模板,并选择置信度得分最高的样本。















 282
282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









