







一、本文的内容
1. 研究目的
本文提出了一种基于transformer的人物交互的新的框架,它能够根据图像预测出a pair of 三元组( 人,物,交互),通过该集合预测,能够利用图像中的语义信息,并且,不需要后处理。
2. 研究现状
目前对于人机交互的主要方式是:
(1)对人和物体定位
(2) 对交互的标签分类
局限性:
(1) 他们需要额外的后处理步骤(向相似的预测值的抑制)
(2)关系建模对于目标检测有帮助,但是考虑到HOI 的交互中的高级别的依赖关系是否有效,还需要进一步研究
3.本文贡献
(1)在HOI 检测中,第一个基于transformer的集预测方法,它消除了之前的检测器的手工的后处理阶段,对交互关系进行建模
(2)提出了各种用于HOTR的训练和推断的技术,提出了HO pointrts 将两个并行的decoders的输出进行关联,一个recomposition step来预测最终的HOI triplets集合,一个新的损失函数来实现端到端的训练
4. 相关工作
(1)顺序的方法:首先进行目标检测,然后将检测的目标对分别送入到神经网络进行预测交互
InteractNet , iCAN, No-Frills HOI 检测器 Graph-based approaches ,eep Contextual Attention,heterogeneous graphnetwork
(2)并行的方法:将目标检测和交互预测并行进行,在将他们使用distance or IoU 联系起来
(3)Object Detection with Transformers
DETR
二、研究方法
1.detection as set prediction
(1)object detection as set prediction
将目标检测的集预测体系结构直接扩展到HOI 预测DETR中的transformer将N 个位置embeding 转换为对象类和边界框的N个预测集。
(2)HOI Detection as Set Prediction.
与目标检测类似,包含对于人物区域,物体区域的定位,以及交互类型的多标签分类,一个改进就是修改了DETR的MPL 头,将每个position embeding转换为预测一个人物框,物体框和行为类别,但是对于同一个对象具有不同的交互时会对该对象进行重复的定位,从而会产生冗余。
2.HOTR 结构
 组成(带有encoder-decoder的transformer结构):带有一个共享的encoder和两个并行的deconder(instance decoder and interaction decoder)然后使用我们提出的HO pointers将这两个解码器的结果联系起来,并产生最终的三元组。
组成(带有encoder-decoder的transformer结构):带有一个共享的encoder和两个并行的deconder(instance decoder and interaction decoder)然后使用我们提出的HO pointers将这两个解码器的结果联系起来,并产生最终的三元组。
(1)具有encoder-decoder的transformer结构
与DETR 类似,通过CNN 和共享编码器提取全局上下文信息,然后将这两组positional embeddings(instance and interaction queries)喂入到两个并行的解码器中,实例解码器将这些queries转变为目标检测是实例表示,而交互解码器将这些interaction queries转变为交互检测中的交互表示。
然后对交互表示使用一个FFN (feed-forward network),并得到一个human pointer 和objct pointer 和一个交互类别,这种交互表示是使用HO pointers 指出相关的实例表示,来定位人体和物体区域,而不是采用直接回归的方法,直接回归中,对相同的目标的多次交互中的定位是不同的,我们使用HO pointrer 对于位置的定位更加高效,并且 不需要对每交互的位置进行重复定位。
 (2)HO pointers
(2)HO pointers
HO指针包含交互中人和对象的对应实例表示的索引,交互解码器将K 维的queries转变为k维的交互表示,并将每一个交互表示送入两个FFN网络中(FFN h,FFNo),并得到两个最终的向量vih,vio,最终的人/物指针就是就是最高分数的实例表示的索引。
 (3)对HOI的基于测重组
(3)对HOI的基于测重组
经过上面步骤之后,我们得到了N个实例表示µ,K 个交互表示z以及对应的HO指针,重组的过程就是利用前馈网络进行bounding box的回归和动作分类。
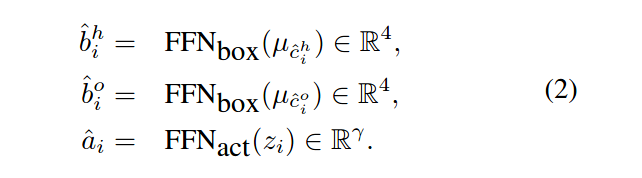 最终的表示就是如下的三元组:
最终的表示就是如下的三元组:
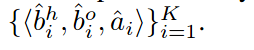
训练HOTR
1.Hungarian Matching for HOI Detection.
HOTR预测了k个HOI 三元组(包含一个人物框,物体框,以及一个行为的类别),每一个预测结果捕获带有一个或多个交互的人物对,K设置为比图像中交真正的交互对的数量大一点。
损失函数包含对于真实的和预测的HOI 三元组之间进行二值匹配的损失函数,和对交互表示进行匹配的损失函数。
由于k比真实的交互对更大,因此我们将y使用空集进行填充至大小为k。
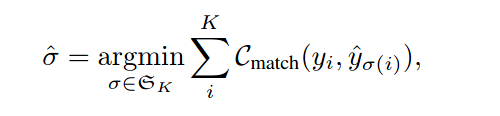 yi is in the form of〈hbox,obox,action〉andˆyσ(i)is in the form of〈hidx,oidx,action〉
yi is in the form of〈hbox,obox,action〉andˆyσ(i)is in the form of〈hidx,oidx,action〉
Φ :idx→box 设置为预测的ground truth 到真实的ground truth之间的映射函数
Φ−1:box→idx,设置为相反的映射,从真实的ground truth到预测的ground truth之间的预测,
设M由一组标准化实例表示组成
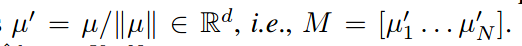
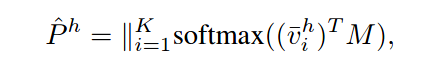
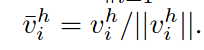
 最后的三元组损失包含定位的损失,和行为分类的损失
最后的三元组损失包含定位的损失,和行为分类的损失
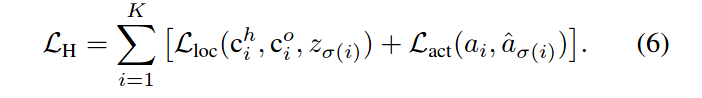 对于定位损失为:
对于定位损失为:
 (2)Defining No-Interaction with HOTR.
(2)Defining No-Interaction with HOTR.
由于缺乏显示式类来抑制冗余预测,最终会对同一个人物对进行多次预测,因此HOTR设置了一个显示类来学习交互性(如果这些人物对之间存在任意的交互性就为1,否则就为0,),然后对于这些交互性得分比较低的人物对进行抑制














 1152
1152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









