







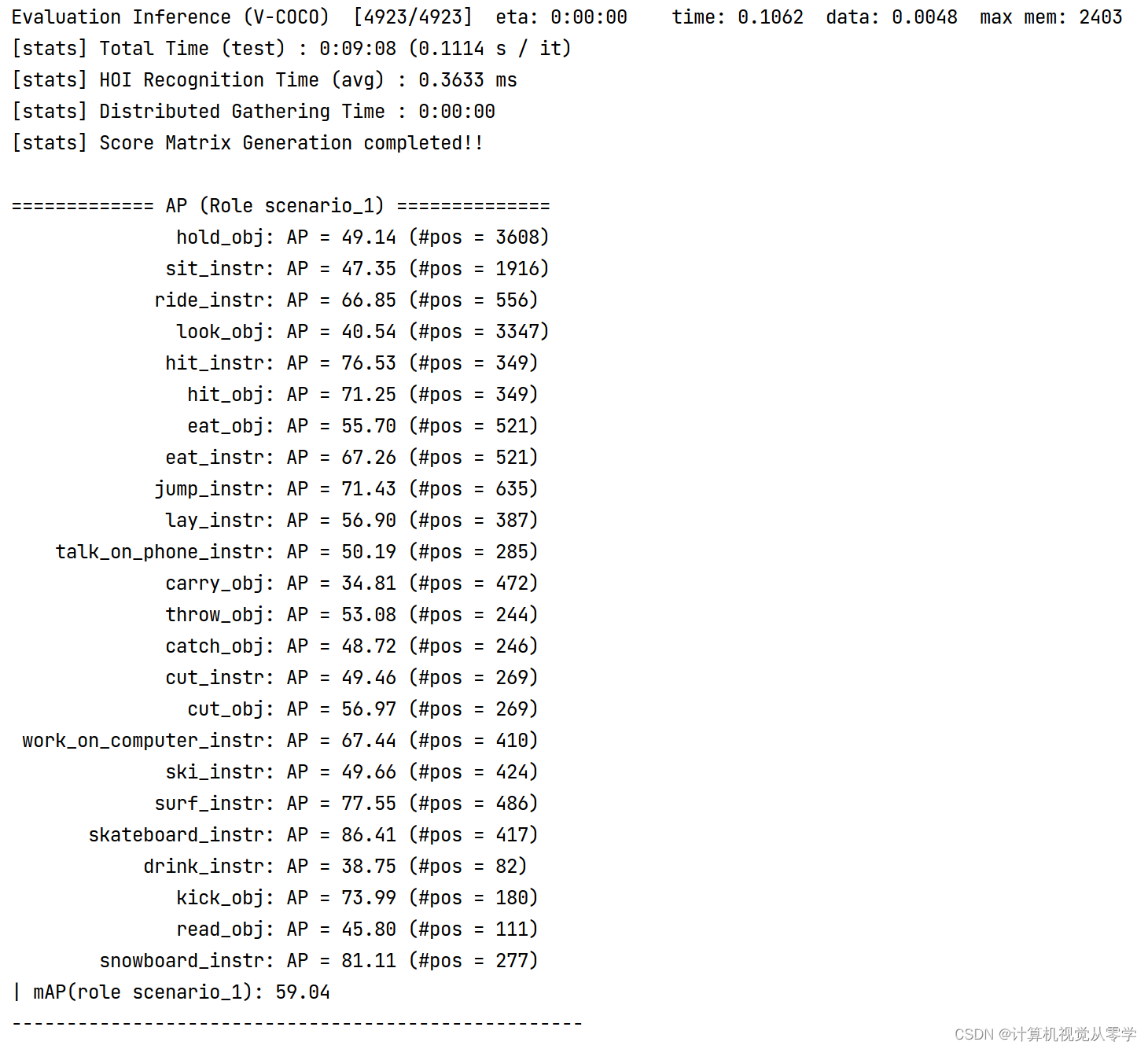
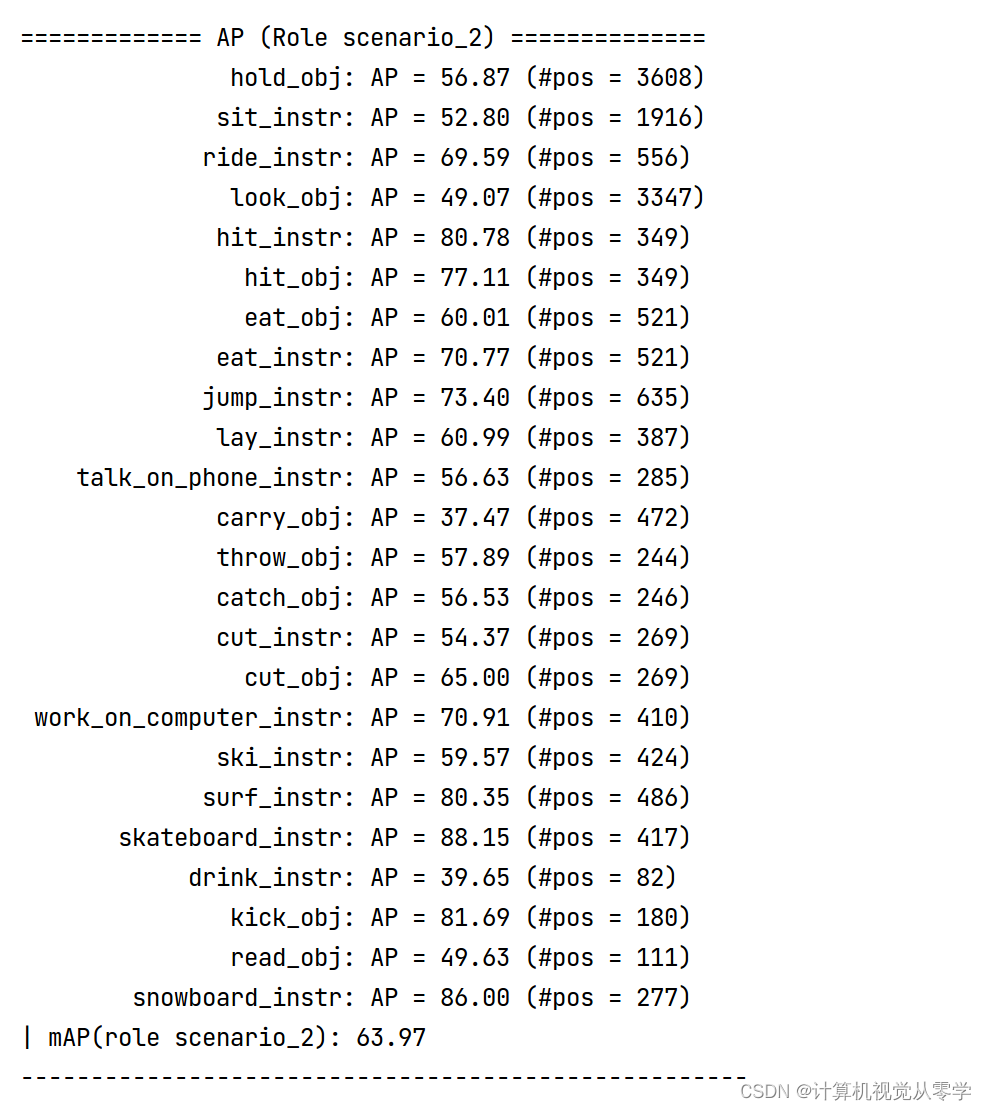
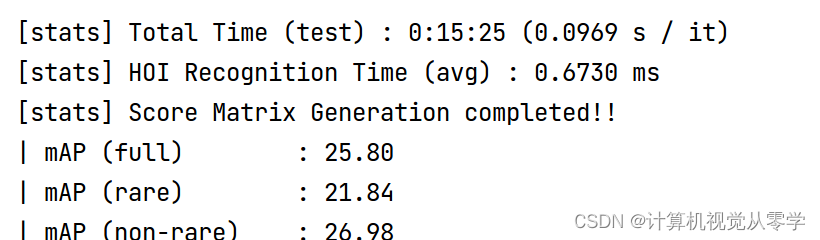
模型在vcoco场景1上的验证效果
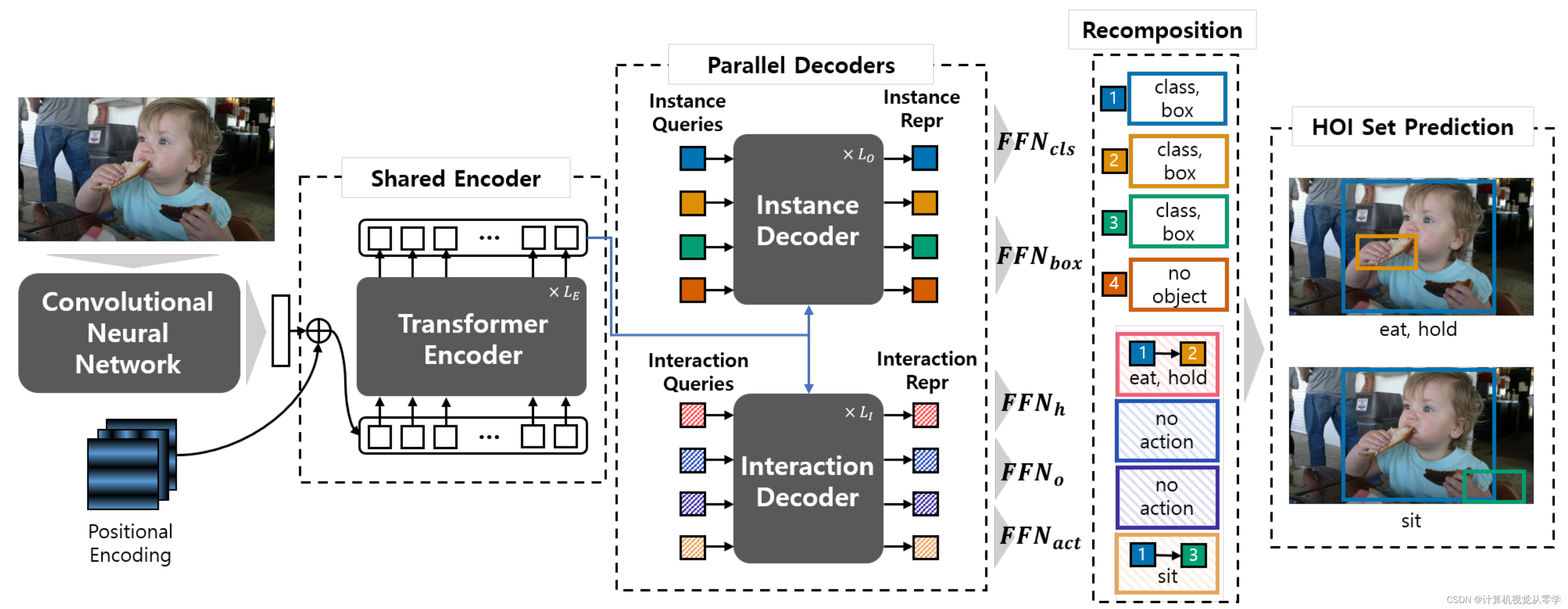
HOTR的模型结构图如下所示:
 在代码中如何实现的?
在代码中如何实现的?
-
在Backbone中:
(1)将图片([bs,3,H,W])送入CNN模型中进行特征提取,使用了ResNet50,得到特征图src([bs,2048,h,w])
(2)引入位置编码pos_embed[bs,256,h,w],query_embed([100,256]) -
在进入Transformer前,将特征图src降维([bs,256,h,w])
-
进入Transformer:
(1)Encoder:
首先将src与pos_embed降维,并交换维度:
src由[bs,256,h,w]→[hw,bs,256],
pos_embed由[bs,256,h,w]→[hw,bs,256],
query_embed由[100,26]→[100,bs,256],B. 将src,pos_embed,query_embed送入Encoder中,得到memory : [hw,bs,256]
(2)Decoder
首先新引入一个全0的Tensor:tgt,其维度与query_embed([100,bs,256])一样
将tgt,memory,pos_embed,query_embed送入Decoder中,得到hs : [6,bs,100,256]hs的维度为[6,bs,100,256],这是因为在Transformer中将6个Decoder的输出(Tensor[bs,100,256])整合到一个Tensor中,得到维度为[6,bs,100,256]的Tensor
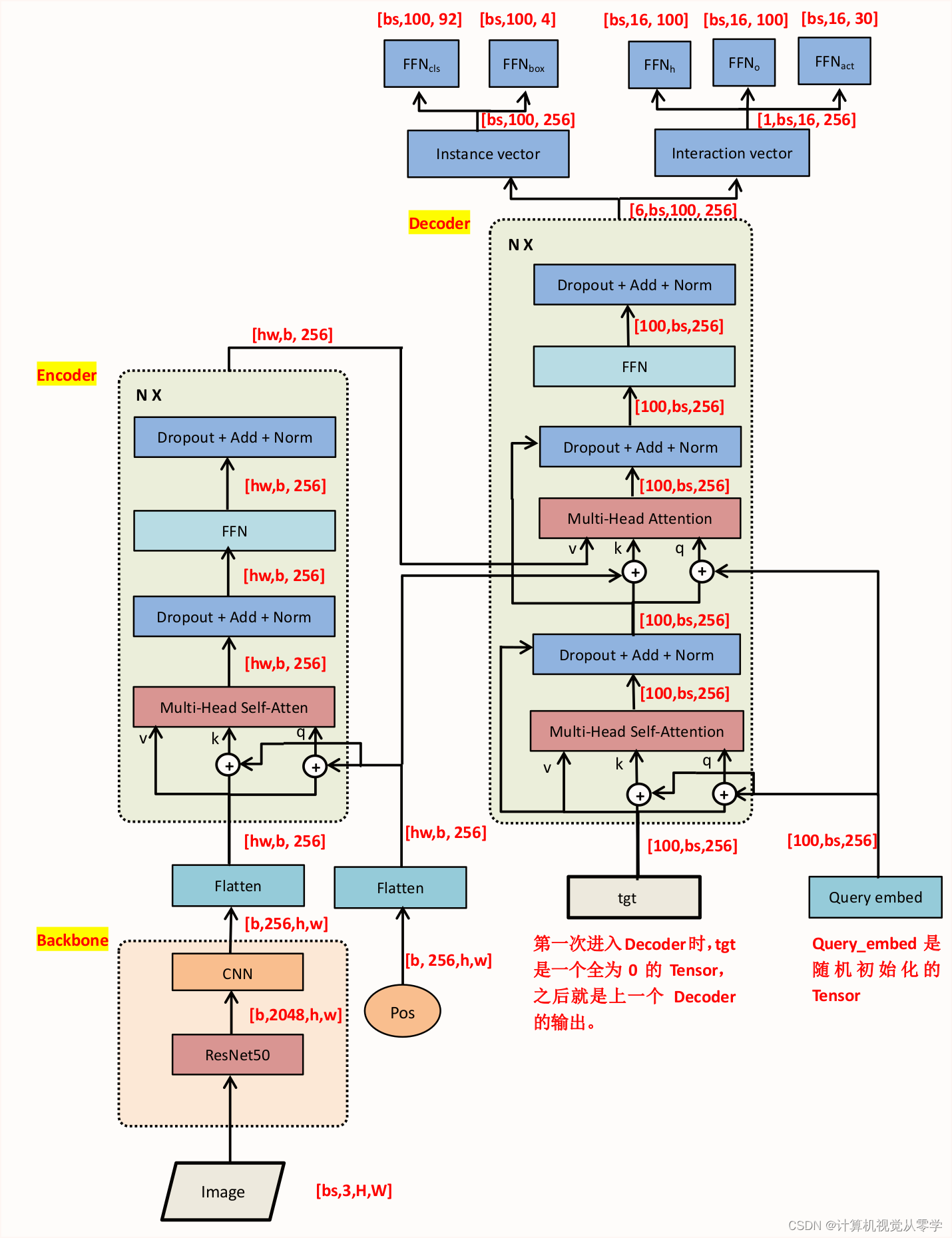
4. 实例表示:执行目标检测
inst_repr = F.normalize(hs[-1], p=2, dim=2) # 处理最后一个解码器的结果,得到实例表示
outputs_class = self.detr.class_embed(hs) #[6,bs,100,92],class_embed是一个nn.Linear(256,num_classes + 1)
outputs_coord = self.detr.bbox_embed(hs).sigmoid() # [6,bs,100,4], bbox_embed是一个MLP(256, 256, 4, 3)
其中:
self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1162
1162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









