







近年来,对于检测和识别单个物体实例取得了飞速的发展,但是如果要理解一个场景中的情况,计算机需要识别出人与周围的物体是如何交互的,本文的核心思想是人体或物体实例的外观特征包含信息线索,这些图像相关的部分需要注意的线索以促进交互预测。为了利用这些线索,我们提出了以实例为中的注意力模块,这个模块学习根据每个实例的外观动态的突出图像的区域。这种基于注意力的网络使得我们能够有选择地聚合与HOI识别相关的特征。
1 研究背景
过去几年,在视觉识别任务(目标检测,分割,行为识别等)上取得了飞速进展,然而对于一个场景的理解不仅要检测单个目标实例,也需要识别出目标对之间的视觉关系。视觉关系检测中非常重要的一类就是检测和识别出每个人与周围的物体是如何交互的,这个任务就称为人物交互检测, 其目标是定位出一个人体,一个物体,以及识别出该人与物之间的交互。给出一个输入图像,以及从目标检测器中检测到的实例,我们需要识别出<human,verb,object>这个三元组。

为什么需要使用HOI?
检测和识别HOI是对一个场景进行深入理解中非常重要的一步。而不仅仅是描述出“什么在哪里(对图像中的目标实例的定位)”。HOI检测是为了回答“发生了什么”。对于HOI检测问题的研究也能为其他相关的高级视觉任务(姿态估计,图像字幕,图像检索)提供重要的研究思路。
为什么要使用注意力
在目标检测的进展的驱动下,最近的一些工作开始致力于图像中的HOI检测,一些现存的方法使用人,物以的外观特征以及他们的空间关系来推断交互行为。除了只使用人物的外观特征,最近的行为识别算法也会利用图片中的语境信息。编码语境的例子包括选择一个备选框,使用人、物边界框的并集,提取人体关键点周围特征,或者利用整个图像的全局语境,尽管融入语境能够提高性能,但是这些手工设计的注意力区域对于识别行为或交互可能并不总是相关的。例如,关注人体姿势可能有助于识别“骑”和“扔”等动作,关注交互点可能有助于识别涉及手-物互动的动作,例如“用杯子喝酒”和“用勺子吃饭”,关注背景可能有助于区分“用网球拍击球”和“用棒球棒击球”。为了解决这些局限,最近的一些研究利用了端到端的可训练的注意力模块进行行为识别和图像分类。
2 研究内容
本文提出了一个端到端的可训练的以实例为中心的注意力模块,该模块能够学习使用人体或物体实例的外观突出信息区域。作者认为实例(人或物)的外观能够提供关于图像中我们应该注意的地方。如为了确定一个人是否拿着一个东西,那么就应该将注意力集中到他手所在的区域。以实例为中心的注意力网络(iCAN)能够动态的为每个被检测的人体或物体实例产生一个注意图,突出显示于任务相关的区域。

本文贡献
(1)我们引入了以实例为中心的注意力模块,允许网络动态地显示用于提高HOI检测的突出信息区域。
(2)我们在两个大的HOI基准数据集上取得先进的表现。
3 相关工作
1. 目标检测
目标检测视觉理解的必要构件,我们的方法使用faster R-CNN,对人和物体实例进行定位,当得到被检测的实例,我们的方法旨在识别出这些人-物实例对之间的交互。
2. 视觉关系检测
一些方法采用场景图来检测视觉关系,也有一些研究利用先验语言的形式来解决具有多个关系suject-predicate-object三元组和有限的数据例子的问题,但是HOI于视觉关系检测相比,其subject就是人,与其他通用对象相比,与对象的交互(即谓词)更加细粒度和多样性。
3. 注意力
最近的一些研究将注意力融入到行为识别和任务交互任务中,这些方法通常使用手工设计的注意力区域去提取语境特征,最近提出了一个端到端的可训练的基于注意力的方法提高了 行为识别和图像分类的性能,然鹅其只是图像级的分类任务,我们的工作建立在基于注意力的最先进的进展上,并且将其用于解决实例级的HOI识别任务。
4. 人物交互
有一些研究将场景中的物体于各种语义信息联系起来能够获得当前动作状态的细粒度理解。还有一些方法基于被检测到的人体的外观的目标物体上引入特定种类的稠密图,除此之外还有使用CNN对人与物体之间的空间关系进行编码的方法。现存的方法识别交互都是基于单个线索(人物外观,物体外观,人-物对之间的空间关系),但是这些方法都会存在缺少语义信息的问题,我们提出的以实例为中心的注意力模块提取语义特征作为定位区域的外观特征的补充信息。
4 研究方法(Instance-Centric Attention Network)
1. 算法概述
(1)算法步骤
- 目标检测
首先给出一张输入图像,使用Faster R-CNN去检测所有的人体,物体实例,使用bh表示被检测的人体实例的边界框,使用bo表示被检测到的物体实例的边界框。使用sh,so分别表示被检测的人体和物体的置信分数。 - HOI预测
通过提出的以实例为中心的注意力网络对所有的人-物边界框对进行评估去预测交互所得到的分数。
(2)推理过程
对于每个人-物边界框对(bh,bo),我们对每个交互类别预测一个分数Sh,oa,a∈{1,· · · ,A},A表示可能的交互行为的总数量。Sh,oa取决于(1)每个被检测目标的分数(sh,so),(2)基于人或物的外观预测的分数(Sha,Soa),(3)基于人与物之间的空间关系得到的预测分数(Sspa)。
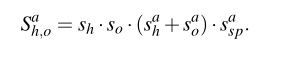
对于一些不包含物体的动作(走路,微笑),我们仅仅使用人物流得到的行为分数(Sha),其最终的分数为Sh*Sha。
(3)训练
由于一个人可以同时对一个目标物体或多个目标物体执行不同的操作,如一个人可以同时“拿”和“挥动球拍”,因此HOI检测是一个多分类的标签问题,每个类别是独立的并且不是相互排斥的,我们对每个行为类别使用一个二元的sigmoid分类器,然后使行为分数Sha,Soa,Sspa与每个类别的动作标签的真实值之间的交叉熵损失最小化。以实例为中心的注意力模块先从一张图片中提取有用的特征,然后描述一个计算这些类别分数Sha,Soa,Sspa的多流网络结构。

2. 以实例为中心的注意力模块(iCAN 模块)

(1)使用标准的过程提取实例的外观特征xinsth,如ROI池化,通过残差块进行传递,然后使用一个全局的平均池化。
(2)根据感兴趣的目标实例动态的生成一个注意图。将实例的外观特征xinsth和卷积特征映射嵌入到512维的向量空间,并使用向量点乘来度量这种嵌入空间的相似性。
(3)应用softmax获得以实例为中心的注意图。这种注意图突出图像中的相关区域有助于识别于给出人/物实例相关的HOI。使用这种注意图,我们可以通过计算卷积特征加权平均值来提取语境特征xcontexth
(4)iCAN模块最终的输入就是将实例的外观特征xinsth与基于注意力的语境特征xcontexth连接起来。
iCAN的优点
(1)注意图能够自动的学习与其他网络共同训练以提高性能。
(2)相比用于图像分类的注意力模块 ,以实例为中心的注意图更加灵活,因为它能根据不同的目标实例关注不同去的区域。
3. 多流网络
(1)人/物流
对于人体流和物体流,我们提取实例的外观特征xinsth(xinsto),基于注意图的语境特征xcontexth(xcontexto),然后将这两个特征连接起来,并送入两个全连接层产生对应的动作分数Sha(Soa)。
(2)成对流
为了对人与物的空间关系进行编码,我们使用双通道二值图像来描述交互模式,将两个边界框的并集作为参考框构建一个两通道的二值图像,第一个通道中,人体的边界框的值为1,其他地方为0,第二个通道中,物体边界框的地方像素值为1,其他地方为0,然后使用CNN从这个两通道二值图像提取空间特征。但由于这种粗糙的空间信息,这种空间特征本身无法产生精确的行为预测,为此我们将空间特征和人体的外观特征连接起来,因为人物的外观特征能够帮助辨别具有相似空间布局的不同行为(骑自行车与推着自行车走)。
5 实验
(1)数据集
V-COCO与HICO-DET
(2)评价指标
role mAP,其目标是检测该动作的各种角色的代理或物体,就是(人,动作,物体)三元组,若这个三元组为正,那么它应该具有正确的动作标签,并且人与物的边界框与真实标注的边界框的IoU要大于等于0.5。
(3)实施细节
我们使用ResNet-50-FPN的主干去产生人与物的边界框,我们使人的边界框得到的分数高于0.8,物体的边界框得到的分数高于0.4.。我们的方法基于使用ResNet-50的Faster R-CNN 作为特征主干。在V-COCO数据集上,前300K次迭代中使用学习率为0.001,权重衰减为0.0001,动量为0.9。


6 结论
本文提出了一个以实例为中心的注意力模块用于HOI检测,该方法的和核心思想学习使用人体或物体实例的外观特征突出显示图像中相关信息的区域,能够帮助我们收集相关的语境信息以加速HOI的检测。
在计算分数时,不仅使用了它们本身的特征,还结合了语境特征特征,语境特征是根据实例产生的注意力图得到的。
为了判断人与物之间的关系,使用空间交互模式并结合人物实例的外观特征连接起来计算得到。















 1441
1441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









