







在HOI中,通常的方法是将人的身体看作一个整体,使用一样的注意力,但是忽略了人与物体的交互是使用的身体的一些部位.因此,本文认为在HOI的识别中,不同的部位应该使用不同的注意力,并且由于我们的身体都是协同工作的,还需要进一步考虑不同部位之间的联系.本文提出了一个成对的身体部位注意力模型,它能够关注HOI识别中的关键部位,以及部位之间的联系.该模型介绍了一个基于特征选择的注意力方法以及一个能够捕获成对的身体部位之间联系的特征表示方案,该方法在HICO数据集上实现了10%的提高(36.1%->39.9).
论文地址:https://arxiv.org/abs/1807.10889
研究背景
通常的方法在整个身体层面或者相对粗糙的部分(头,腿)进行考虑HOI识别问题,但是科学研究发现,人的注意力并不是统一的,人们在不同的环境中更加趋向于关注不同的身体部位,如下图中.都是拿杯子动作,但是人们的姿势却并不相同,因此我们提出一个非统一注意力模型,能够高效的发现HOI识别中最具信息量的身体部位.

仅在身体部位建立注意力并不能捕获重要的HOI语义,因为忽略了身体部位之间的联系,这种成对的集合定义了一组新的相关的特征映射,其特征能够被同时提取.我们还引入了成对的ROI pooling能够汇集了成对的身体部位的关节特征图,并丢弃其他部位的特征.这种表示对不相关的人体姿势具有一定的鲁棒性,并且检测到的HOI标签的误报率也显著降低,通过成对的特征集合,我们建立了一个注意力模型,能够自动的发现HOI具有一定意义的身体部位之间的联系.该文是HOI识别中第一个将注意力用于身体部位之间的联系的方法,
相关工作
- 人物交互
当两个人的动作几乎一致时候,能够解决动作识别中的歧义,并且在识别标签中提供更高的语义信息,在使用静态图的行为识别中,之前试图使用人的姿势来识别人的动作,但是静态图像中没有运动线索对仍然无法很好的识别人的行为,因此提出了人物交互.但是这种方法很难识别小的目标,一些方法通过识别可区分的图像块来简化目标识别,还有方法利用图像的高级属性,如BoF,融入色彩信息和语义分层来帮助HOI识别.
本文中的改进:(1)考虑了身体部位以及他们之间的联系(2)提出了注意力机制关注与身体的特定部分以及空间结构. - 注意力模型
人的感知仅仅关注视野的部分区域并获得细节信息忽略掉部相关的信息,现在一些研究将其用于深度学习中,并在很多计算机视觉任务中取得了很好的效果,注意力机制第一次用于行为识别中,是使用LSTM关注视频帧中的重要部分,
研究内容
本文提出了借助身体部位的信息来帮助HOI识别,并通过建立部位对来发现身体部位之间的联系,采用注意力机制选择最有用的部位对,忽略那些对于HOI识别不相关的身体部位对.最后结人,物,场景的全局外观特征,实现最终的HOI识别.
本文的亮点:利用了身体部位的特征来协助HOI的识别,并通过注意力机制选择最有用的身体部位.同时为了利用人与物体的空间关系,将人与物体的边界框联合起来提取特征.
研究方法

1.全局外观特征
(1)场景和人物外观特征
为了利用人与场景中的特征,给出一张输入图片,首先进行裁剪,然后送入VGG网络中进行传播,得到特征图,ROI池化层对或场景中给出的边界框提取ROI特征,对每个被检测到的人将其特征与场景的特征连接起来得到全局的外观特征并通过一个全连接层前向传播,对预定义的列表中的每个HOI估计一个分数.在HICO数据集中,一张图片中可能存在多个人物,只要观察到相关的HOI,那么其标签就被被标记为正,提出了多实例学习(multiple instance learning,MIL)框架来解决多人问题,其输入是对每个人的预测结果,输出为一个分数数组,它取所有输入预测中每个HOI的最高分数.
(2)融合物体特征
特征表示:给出一个物体边界框,直接将物体特征与人体特征和场景特征连接起来效果并不好,因为没有对人与物体之间的位置关系进行编码,因此我们将ROI设置为检测到的人与物体的联合框.
处理多个物体:一个人周围可能存在多个物体,为此,可以采用多个不同的人-物联合框,并对每个联合框分别使用ROI 池化.
最后将物体特征和人与场景的特征连接在一起,就建立起一个捕获全局外观特征的网络.
2.局部成对身体部位特征

(1)ROI-parwise pooling
其目标是提取关节特征图,并保留相关的空间关系.R1(r1,c1,h1,w1),R2(r2,c2,h2,w2)表示两个ROI对,他们的联合框为Ru(ru,cu,hu,wu),(r,c)表示ROI的左上角,(h,w)表示高度和宽度,将两个身体部位框之外的激活值设置为0来忽略不相关区域的特征,将联合边界框Ru的特征图转化为HW的固定尺寸,最后统一使用最大池化:将huwu划分成H*W的小格子,然后每个小格子池化后的输出就是其最大值.这种池化方法就能保留两个身体部位的关联特征和位置关系.对于许多不相关的身体区域,我们使用注意力模块来发现相关的联系.
(2)Attention Module
采用经过ROI-pariwise池化之后的所有可能的身体部位对P={p1,p2,…,pm}的特征图作为输入,m=C(n,2) 表示身体部位对的数量,对于每个部位对pi,全连接层会得到一个注意力分数si,所有部位对的分数S={s1,s2,…,sm}表示每个部位对的重要性.
- 特征选择
选择层会保留身体部位对分数最高的k个特征图,丢掉剩下的,其表示如下所示:
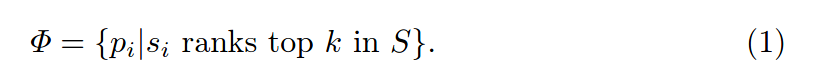
- 注意力分配
由于不同的特征图可能会存在相同的分数值,尽管他们对于HOI识别作出的贡献并不一致,因此需要重新调整特征图,使得其能够正确反映它在HOI识别中的影响.因此我们可以将其与相关的注意力分数乘起来

c(j) 是Φ中第j个元素的索引,fj表示第j个重新调整的特征图 - 讨论
在一次迭代中只允许k个成对的特征,与输入的交互相关的部位对会分配更大的分数,以此实现无监督的注意力机制. - 训练
由于公式(1)不是一个可微函数,在反向传播是,只会从后向前传播梯度,只有被选择的k个部位对特征图的梯度会复制到前一层,其他被丢弃的特征图的相关的值会被设置为0,公式(2)可以求导数,因此注意力分数在反向传播中可以自动更新,并且注意力模块采用端到端的方式进行训练. - 总结:该方法结合了每个身体部位的局部特征以及更高级的部位之间空间关系,对于不同的HOI,pairwise body-part attention module能够自动发现相关的身体部位与他们之间的关系.
- 结合全局特征和局部特征
通过获得的成对身体部位特征与全局外观特征,分别通过最后的全连接层进行传播一估计最终的预测结果.该结果用于每个被检测的人物实例.
实验细节
使用faster RCNN作为检测器来获得人物边界框,每张图片采样3个人物建议框和4个物体建议框,如果人或物体少于预期的,我们就将剩余的区域用0填充.对于身体部位使用姿态估计器来检测所有的人物关键点,基于关键点定义10个身体部位,每个部位定义一个边界框,其大小与对应的人体躯干大小成比例.部位对的数量为45
损失函数为加权sigmoid交叉熵:
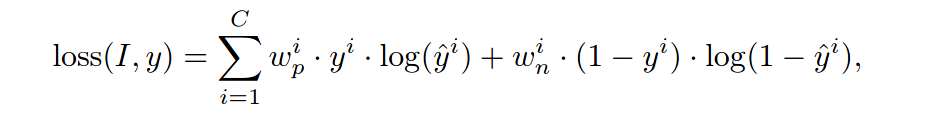
 实验结果:
实验结果:
在HICO数据集上实现mAP39.9,在MPII数据集(只标注了一个交互即使有多个人与多种交互)上实现精度为37.5
 识别发生错误的情况:
识别发生错误的情况:
1.会忽略人的动作
2.无法识别多个人物与同一物体之间的交互
3. 无法检测出人与物体的情况也无法正确识别HOI
4. 当背景很模糊也也无法正确识别

结论
本文提出一个成对身体部位注意力模型能够对不同的部位对采用不同的注意力.引入了ROI pairwise pooling以及成对的身体部位注意力模块提取有用的身体部位对,然后再选择部位对的特征图与背景,人,物,特征连接起来形成最终的预测结果,在HICO数据集上实现了39.9%的mAP.














 1475
1475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









