






一、基本卷积神经网络
1、AlexNet
网络结构:
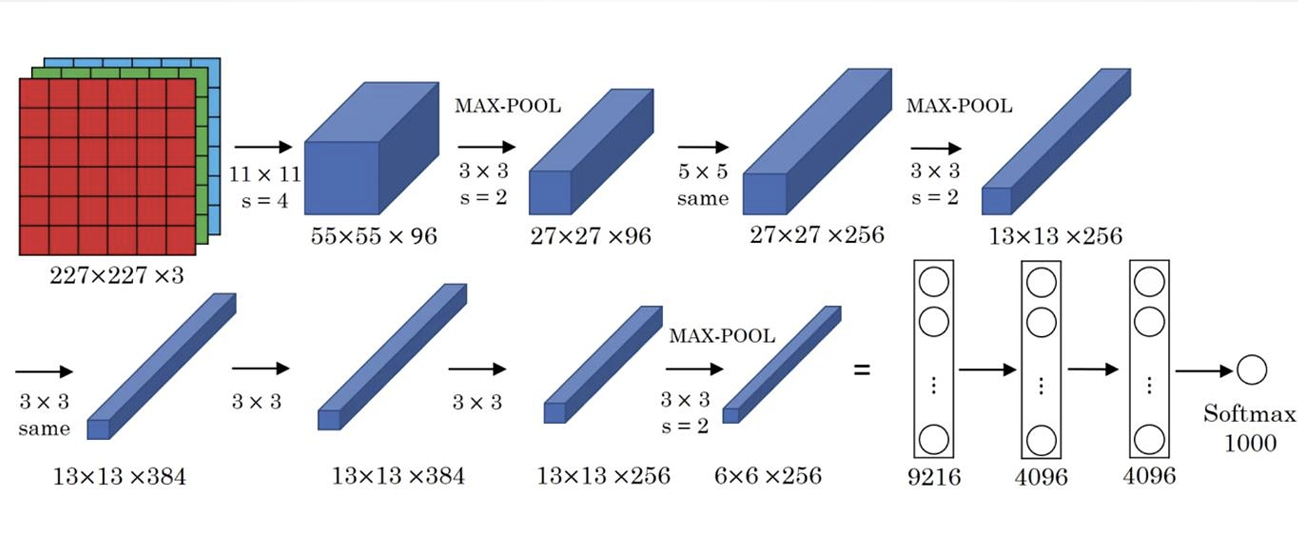
网络说明:
网络一共有8层可学习层——5层卷积层和3层全连接层
➢ 改进
-池化层均采用最大池化
-选用ReLU作为非线性环节激活函数
-网络规模扩大,参数数量接近6000万
-出现“多个卷积层+一个池化层”的结构
➢ 普遍规律
-随网络深入,宽、高衰减,通道数增加
代码:
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
2、VGG-16
网络结构:
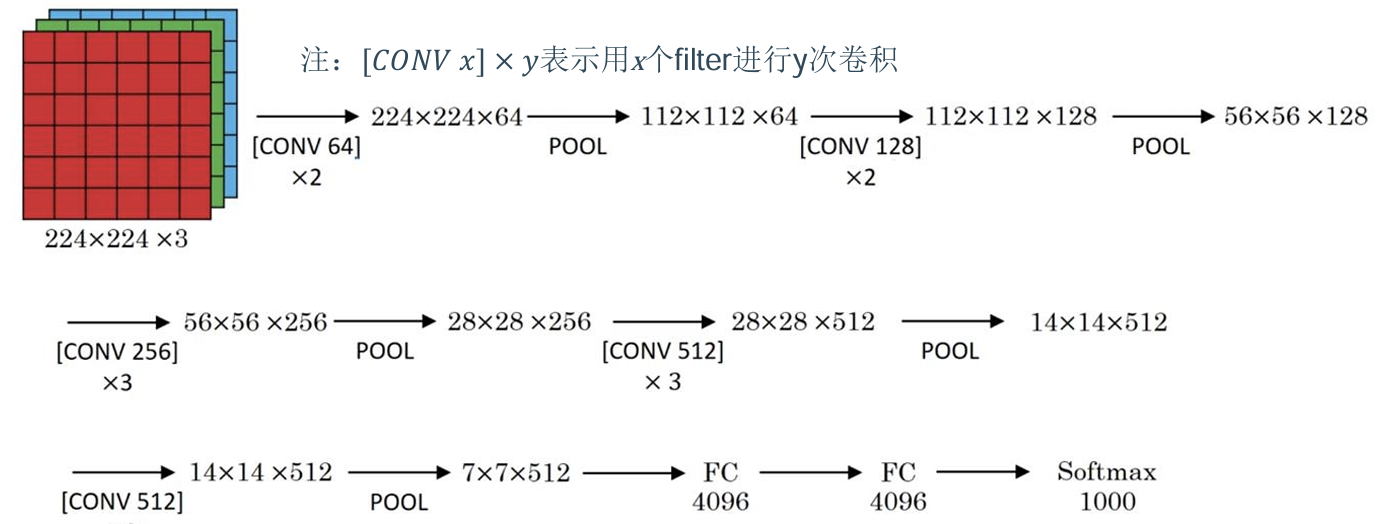
网络说明:
➢ 改进
-网络规模进一步增大,参数数量约为1.38亿
-由于各卷积层、池化层的超参数基本相同,整体结构呈现出规整的特点。
➢ 普遍规律
-随网络深入,高和宽衰减,通道数增多。
代码:
class VGG16(nn.Module):
def __init__(self, num_classes=1000):
super(VGG16, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1), nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
3、残差网络
为什么需要残差网络(ResNet)?
深度神经网络(DNN)的表现往往随着网络深度的增加而提升,但当层数增加到一定程度后,模型的训练误差反而增大,出现梯度消失或梯度爆炸的问题,导致网络难以训练。
1. 梯度消失与梯度爆炸
当网络层数增加时,反向传播中的梯度逐层相乘,导致:
-
梯度消失(Vanishing Gradient): 梯度值趋于0,权重更新停滞,网络不学习。
-
梯度爆炸(Exploding Gradient): 梯度值过大,权重发散,损失不收敛。
2. 网络退化问题
-
理论上,增加层数不应导致训练误差增大,较深网络至少应达到浅层网络的性能。
-
但实际上,由于梯度消失/爆炸,深层网络反而表现更差,即退化问题。
-
退化现象: 随着层数增加,训练误差和测试误差都变大。
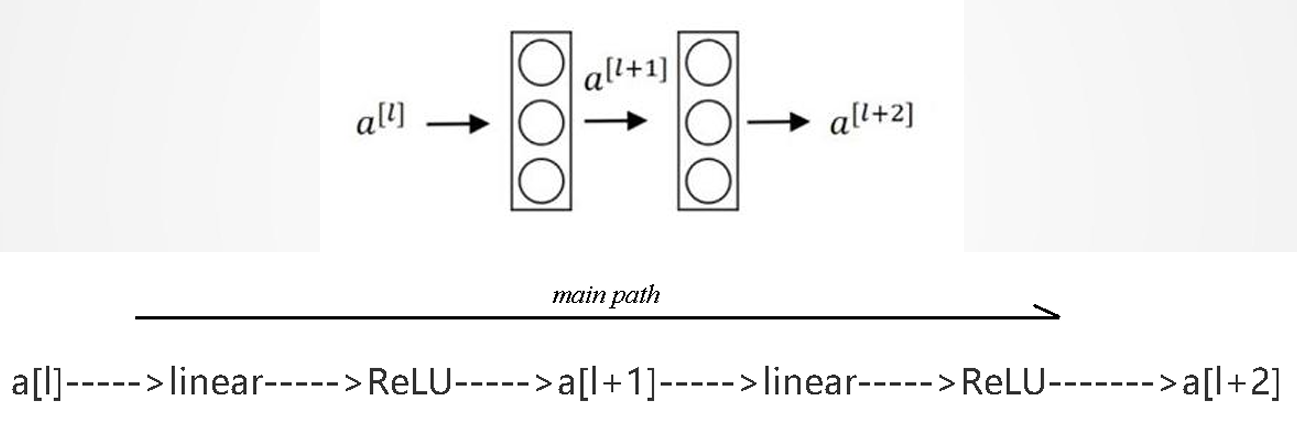
3. 残差网络(ResNet)的核心思想
ResNet通过跳跃连接(Shortcut Connection),使网络学习残差映射而非直接映射。
残差块(Residual Block):
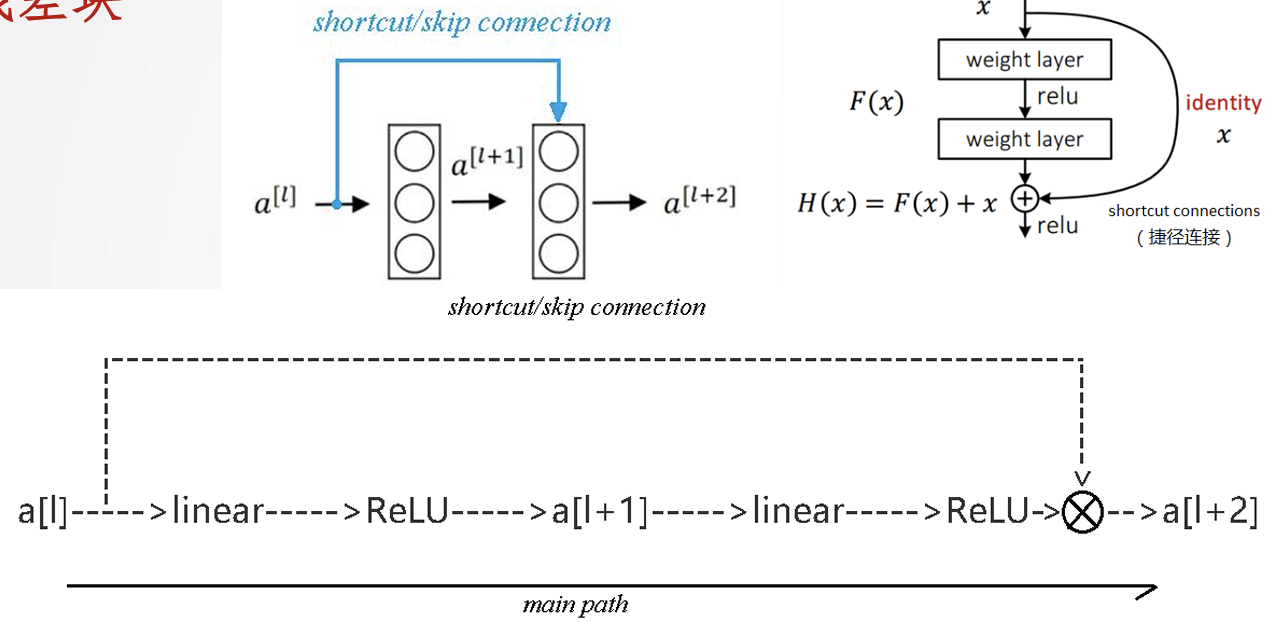
4. 残差网络结构
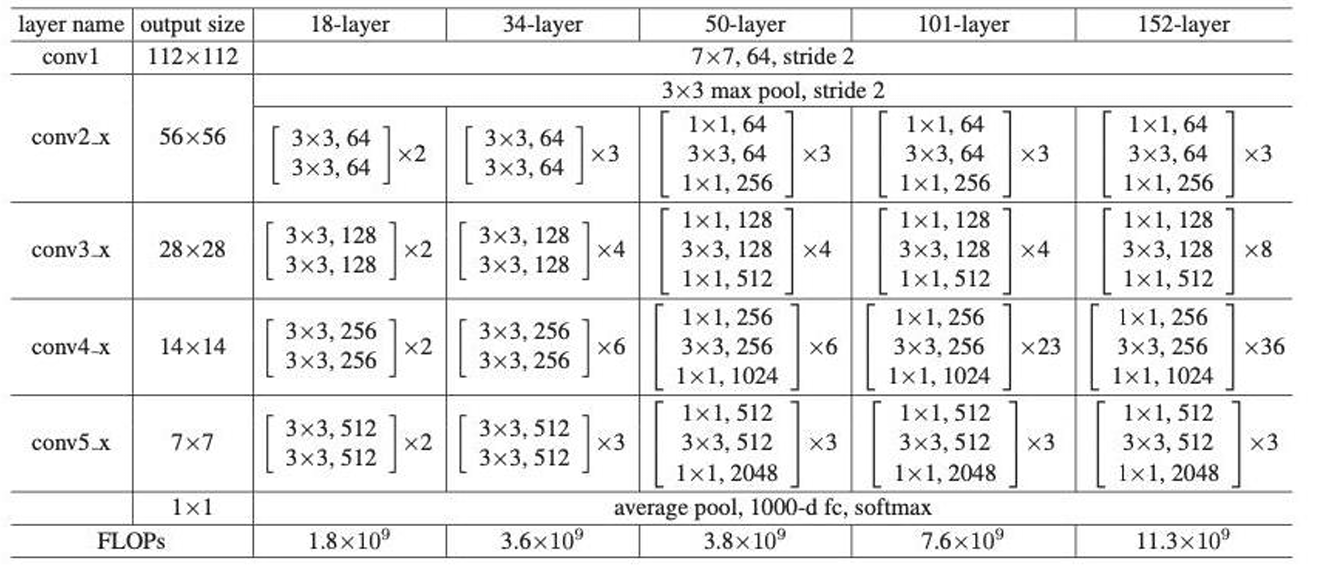
5. 网络解释:
➢ 普通网络的基准模型受VGG网络的启发
➢ 卷积层主要有3×3的过滤器,并遵循两个简 单的设计规则:①对输出特征图的尺寸相同的 各层,都有相同数量的过滤器; ②如果特征 图的大小减半,那么过滤器的数量就增加一 倍,以保证每一层的时间复杂度相同。
➢ ResNet模型比VGG网络更少的过滤器和更低的复杂性。ResNet具有34层的权重层,有36亿 FLOPs,只是VGG-19(19.6亿FLOPs)的18%。
6. 代码
import torch
import torch.nn as nn
# 定义Bottleneck模块
class Bottleneck(nn.Module):
expansion = 4 # Bottleneck的输出通道数是中间卷积核数的4倍
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels, out_channels * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
# 定义ResNet-50主结构
class ResNet50(nn.Module):
def __init__(self, num_classes=1000):
super(ResNet50, self).__init__()
self.in_channels = 64
# 初始卷积层
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 残差块堆叠
self.layer1 = self._make_layer(64, 3)
self.layer2 = self._make_layer(128, 4, stride=2)
self.layer3 = self._make_layer(256, 6, stride=2)
self.layer4 = self._make_layer(512, 3, stride=2)
# 全局平均池化和全连接层
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * Bottleneck.expansion, num_classes)
def _make_layer(self, out_channels, blocks, stride=1):
downsample = None
# 如果输入和输出通道数不同或步长不是1,需要下采样
if stride != 1 or self.in_channels != out_channels * Bottleneck.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * Bottleneck.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * Bottleneck.expansion),
)
layers = [Bottleneck(self.in_channels, out_channels, stride, downsample)]
self.in_channels = out_channels * Bottleneck.expansion
for _ in range(1, blocks):
layers.append(Bottleneck(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
二、常见数据集
1、MINST
MNIST 数据集主要由一些手 写数字的图片和相应的标签组成,图片一共有 10 类,分别对应从 0~9。
MNIST数据集是由0〜9手写数字图片和数字标签所组成的,由60000个训练样本和10000个测试样 本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。

2、Fashion-MINST
➢ FashionMNIST 是一个替代 MNIST 手写数字集 的图像数据集。 它是由 Zalando旗下的研究部门提供,涵盖了来自 10种类别的 共 7万个不同商品的正面图片。
➢ FashionMNIST 的大小、格式和训练集/测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。你可以直接用它来测试你的机器学习和深度学习 算法性能,且不需要改动任何的代码。
3、CIFAR-10数据集
➢ CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每 个类有6000个图像。有50000个训练图像和10000个测试图像。
➢ 数据集分为五个训练批次和一个测试批次,每个批次有10000 个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。
以下是数据集中的类,以及来自每个类的10个随机图像:

4、PASCAL VOC数据集
➢ PASCAL的全称是Pattern Analysis, Statistical Modelling and Computational Learning
➢ VOC的全称是Visual Object Classes
➢ 目标分类(识别)、检测、分割最常用的数据集之一
➢ 第一届PASCAL VOC举办于2005年,2012年终止。常用的是 PASCAL 2012
➢ 20类图像实例:

5、MS COCO数据集
➢ MS COCO的全称是Microsoft Common Objects in Context,起源 于微软于2014年出资标注的Microsoft COCO数据集
➢ 数据集以scene understanding为目标,主要从复杂的日常场景中 截取
➢ 包含目标分类(识别)、检测、分割、语义标注等数据集
➢ ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检 测等领域的一个最权威、最重要的标杆
➢ 官网:http://cocodataset.org
6、ImageNet数据集
➢ 始于2009年,李飞飞与Google的合作: “ImageNet: A Large-Scale Hierarchical Image Database”
➢ 总图像数据:14,197,122
➢ 总类别数:21841
➢ 带有标记框的图像数:1,034,908

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









