






本节课程由西北工业大学博士生、书生·浦源挑战赛冠军队伍队长、第一期书生·浦语大模型实战营优秀学员安泓郡主讲。
本期课程内容主要分为四个部分:
1、大模型部署背景;2、大模型部署方法;3、LMDeploy简介;4、动手实践环节。
1、大模型部署背景
所谓模型部署,其实就是把已经训练好的模型,放在特定的环境中进行运行的过程。前面我们已经学习过用RAG等技术让大模型的回答更贴近我们的需求,但最终我们的模型都是要服务于实际业务场景的,这就牵扯到需要把大模型部署到服务器或者是移动端边缘端。此时会牵扯到许多问题,比如没有部署到服务器、需要部署到CPU的服务器还是GPU/TPU/NPU等其他的设备的服务器、是否会部署到集群,如果要部署到集群的话,如何分布式推理大模型……这些都是实际生活环境需要考虑的一些问题。大模型的参数量和计算量都是十分巨大的,如果要部署到手机或者边缘端,那么计算能力是否足够?我们如何在有限的资源里去加载推理大模型,都是实际在部署模型中要面临的难点。
那么模型在部署的过程中具体面临哪些挑战?
痛点一:大模型的计算量巨大。

痛点二:大模型的内存开销巨大。
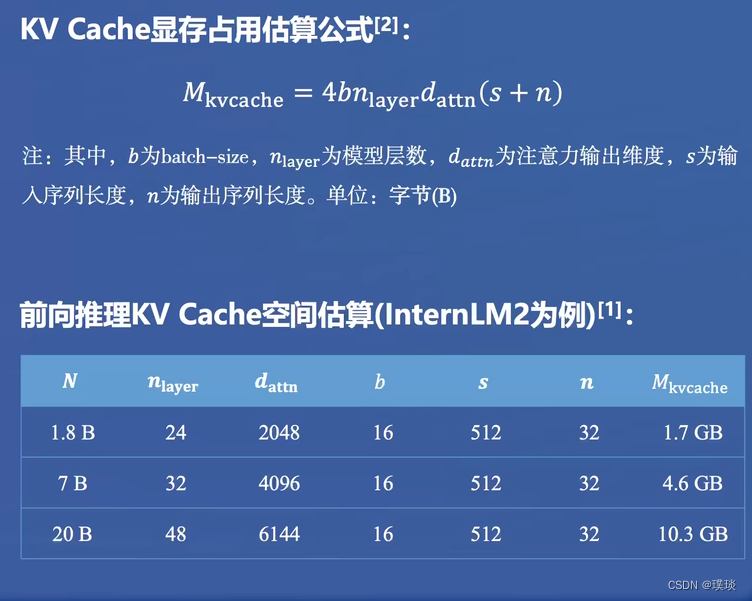
痛点三:访存瓶颈

痛点四:动态请求
我们在实际生产环境中,同一时间会有多少用户发起请求是不确定的,而且大模型生成的回答是逐个Token生成的,在回答结束前,我们无法预测生成的回答的长度。请求的长短不同,响应和处理的时间长短也不同,可能出现长进程等待段进程的情况。
2、大模型部署方法(模型剪枝、知识蒸馏、模型量化)
(1)模型剪枝(Pruning)
模型的参数虽然非常多,但并非全部有用,我们可以通过特定的策略,对模型中贡献有限的冗余参数进行剪枝,通过减少参数量,在保证性能最低下降的同时,减少存储需求,提高计算效率。
从方法论上可分为:非结构化剪枝、结构化剪枝

(2)知识蒸馏(Knowledge Distillation, KD)
它依然是通过减少模型参数的角度来提高计算效率。对于一个存在冗余参数的模型,我们认为该模型具备基于较少的参数达到同等性能效果的潜力。我们如果直接训练一个少参数的一个小模型,还要达到同等效果的话,是比较困难的。我们可以采取间接的方式,先训练一个大模型作为教师网络,然后再让该教师网络去训练一个参数量比较少的一个学生网络,进行一个知识的迁移,从而去降低训练的难度。这种方法最早是用在CV领域(计算机视觉-图像分类),把CN换成大模型它也可以work
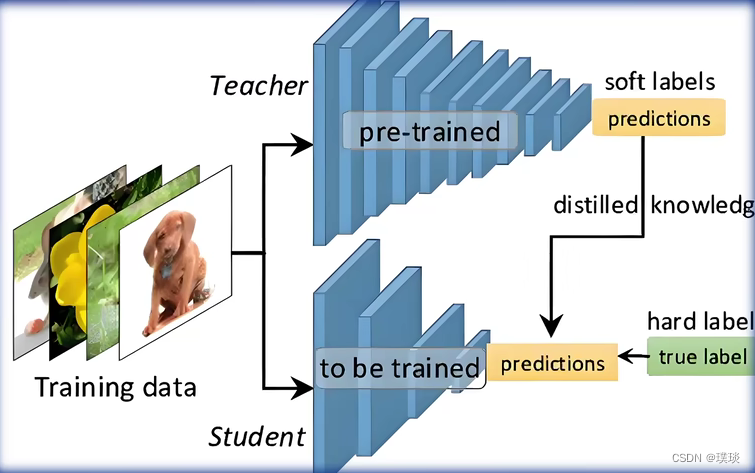
(3)模型量化(Quantization)
其核心思想是将浮点数转换为整数或者其他离散形式,以减轻深度学习模型的存储和计算负担。因为模型参数一般以32位的浮点数进行存储,一个数需要占用四个字节,32位的浮点数能表示的数值范围很广,我们不一定全部用得到,因此我们可以稍微损失一些表示精度,在不怎么影响模型回答效果的前提下,把浮点数量化为定点数或者是16位、8位、4位甚至平均1位的整数,去存储模型的参数,从而大幅减少模型参数所需的内存空间。另一个原因是模型量化可以提高计算效率,通过量化可以降低访存量,从而降低数据传输的时间,提升计算效率的同时减少了推理时间。

3、LMDeploy简介
LMDeploy是涵盖LLM任务的全套轻量化、部署和服务解决方案。核心功能包括高效推理、可靠量化、便捷服务和状态推理。

LMDeploy核心功能

LMDeploy性能表现

在新版本的LMDeploy中,不仅支持语言模型,还支持多模态视觉大模型的推理。

LMDeploy也支持一些第三方的主流大模型的部署(具体可去LMDeploy官方项目主页查看)
4、动手实践环节——安装、部署、量化
首先还是创建开发机,选择镜像Cuda12.2-conda;选择10%A00*1GPU。
进入开发机后,打开终端,接下来输入命令“studio-conda -t lmdeploy -o pytorch-2.1.2”创建conda环境。成功创建后如下所示:
接下来开始安装LMDeploy。在终端输入命令“conda activate lmdeploy”激活刚刚创建的虚拟环境。

记下来输入命令“pip install lmdeploy[all]==0.3.0”安装0.3.0版本的lmdeploy。

接下来利用LMDeploy模型进行对话。
本次实战营已经在开发机的共享目录中准备好了常用的预训练模型,可以运行相应的目录查看,如下图所示,每一个文件夹都对应一个预训练模型。

本节课以InternLM2-Chat-1.8B模型为例,去官方仓库下载模型。首先“cd ~”进入home目录,然后运行下一条指令去开发机的共享目录,进行软链接或者拷贝模型。此处先运用软链接的方式“ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/”(其实就是把共享目录下的那个模型权重文件,在当前的home目录下创建一个映射,这样就不需要占用开发机本身的一个存储空间)。执行完如上指令后,可以运行“ls”命令。可以看到,当前目录下已经多了一个Internlm2-chat-1_8b文件夹,即下载好的预训练模型。

使用Transformer库运行模型。(作为于LMDeploy的对比例子)
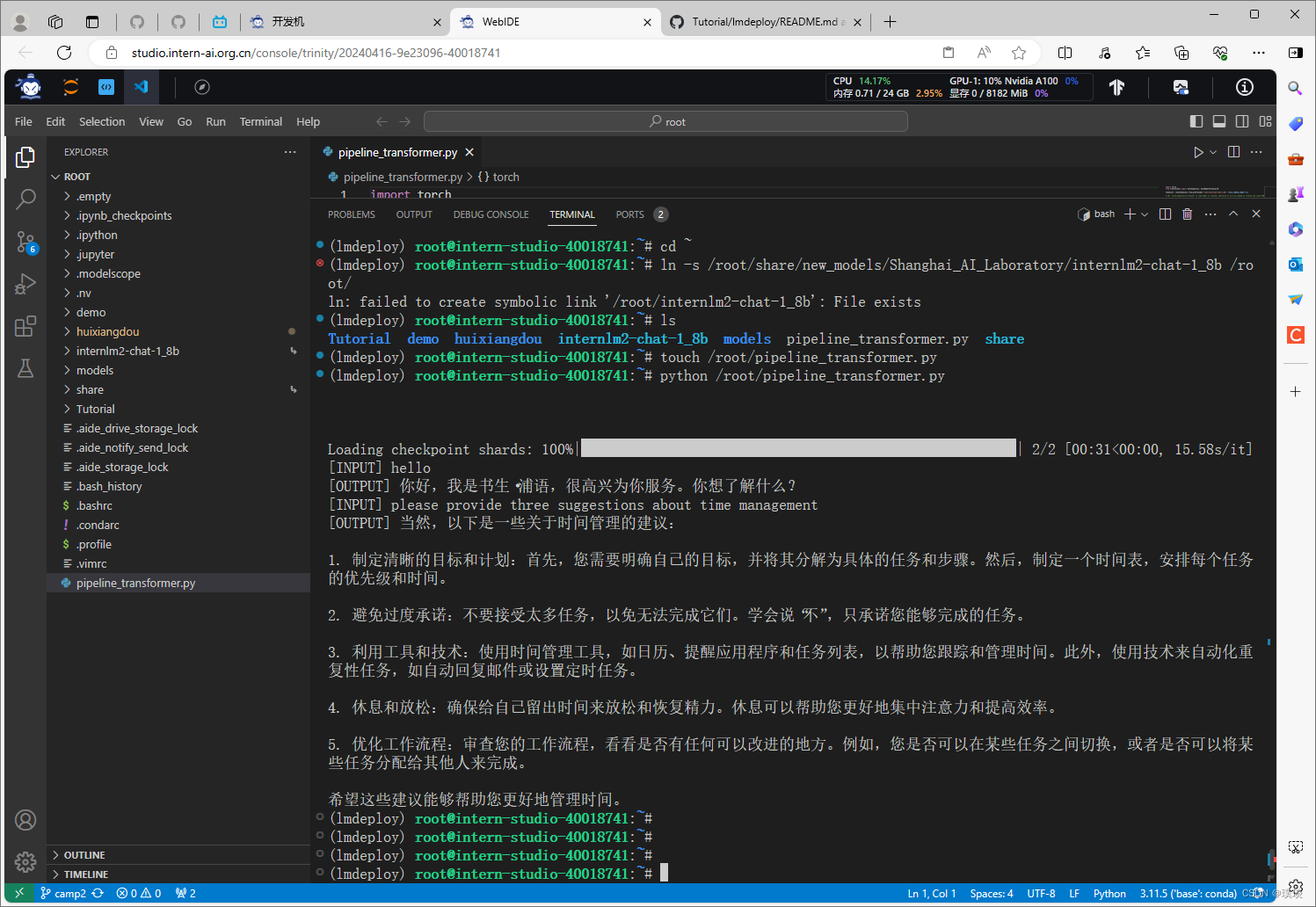
打开vs code,进入终端。在终端里输入指令“touch /root/pipeline_transformer.py”创建新文件“pipeline_transformer”。运行该指令之后可以看到界面的左边栏已经多出一个文件。打开该文件,将下图中的代码输入该文件并保存。

保存好后激活之前创建的conda环境,运行刚刚创建的Python代码。得到的输出如下:
接下来使用LMDeploy与模型进行对话。
首先激活创建好的conda环境(上述步骤中已经激活好了),执行命令“lmdeploy chat /root /.conda/envs/InternLM2_Huixiangdou /internlm2-chat-1_8b”运行1.8B模型。接下来可以与大模型进行对话,输入“请给我讲一个小故事吧”,然后按两下回车。
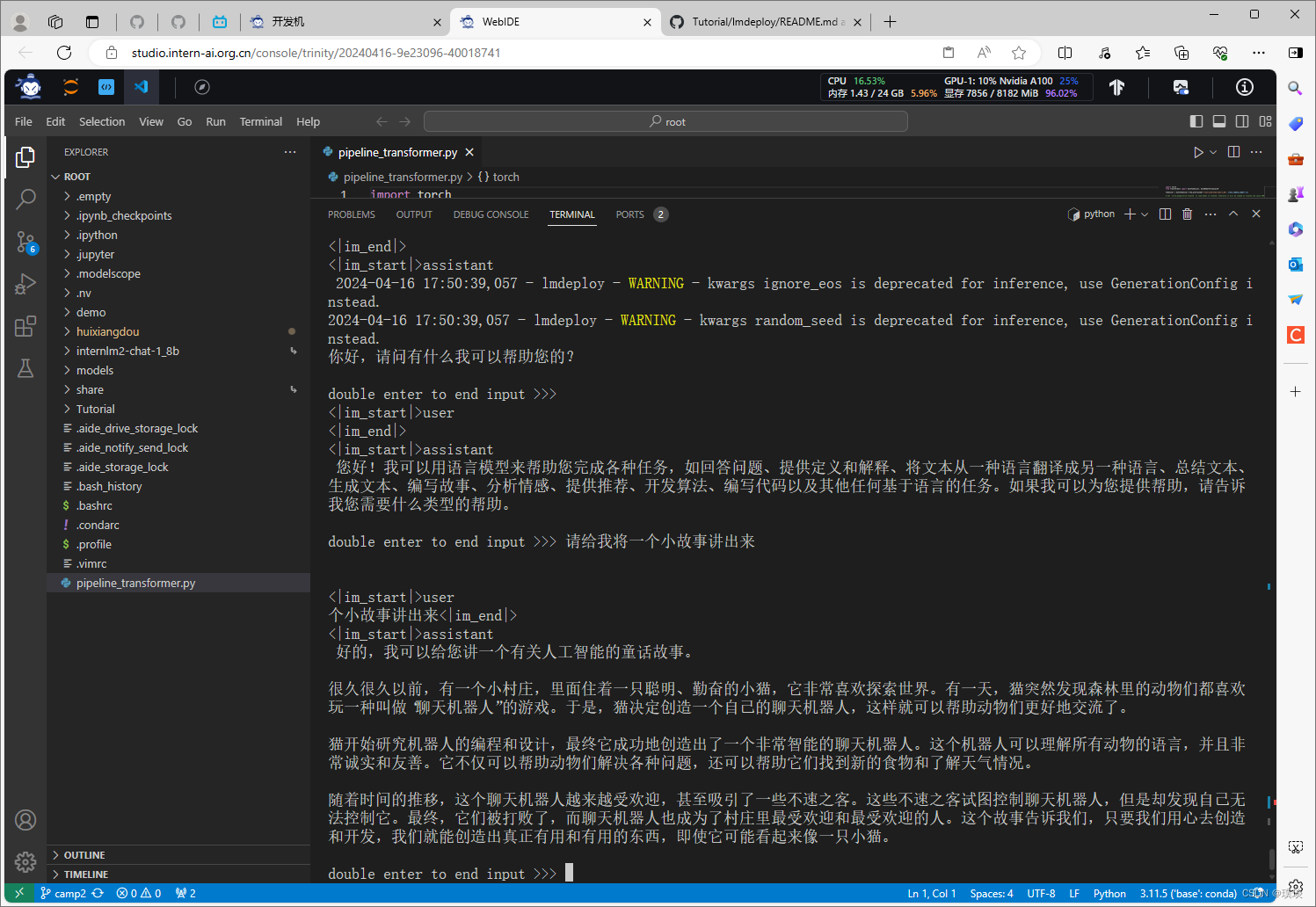
如果不想跟模型进行对话,那就输入“exit”然后回车,就可以退出了。

有关LMDeploy的chat功能的更多参数可通过-h命令(lmdeploy chat -h)查看。
5、小结和疑问
在本次实验中,一开始跟着视频和文档的步骤在终端上先执行下载conda环境等操作,也成功执行,但是继续跟着步骤在vs code使用Transformer运行模型的时候会报错无法执行,显示没有conda环境。后续解决的办法是从一开始的安装conda环境等操作均在vs code的终端上执行,最终才成功完成实验。还有我下载预训练模型的时候,用ls命令,显示的Internlm2-chat-1_8b文件夹会带有前缀,这又是为什么呢?欢迎在评论区与我讨论!















 280
280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









