







嘿,你能搜索到这个问题,说明你说一个认真学习的同学,这个问题的细节值得思考。
欢迎收藏,会持续更新。请仔细看后面的调试界面。
本文属于pytorch高级知识,有点难度,请仔细看分析。
load_state_dict函数,它用于加载模型的参数字典。
先上代码,
print('汀兰 Pytorch人工智能大模型')
import torch
import torch.nn as nn
class My_Net(nn.Module):
def __init__(self):
super().__init__()
self.my_fc_0 = nn.Linear(5, 2)
self.my_fc_1 = nn.Linear(2, 1)
def forward(self, x):
x = self.my_fc_0(x)
x = self.my_fc_1(x)
return x
model = My_Net()
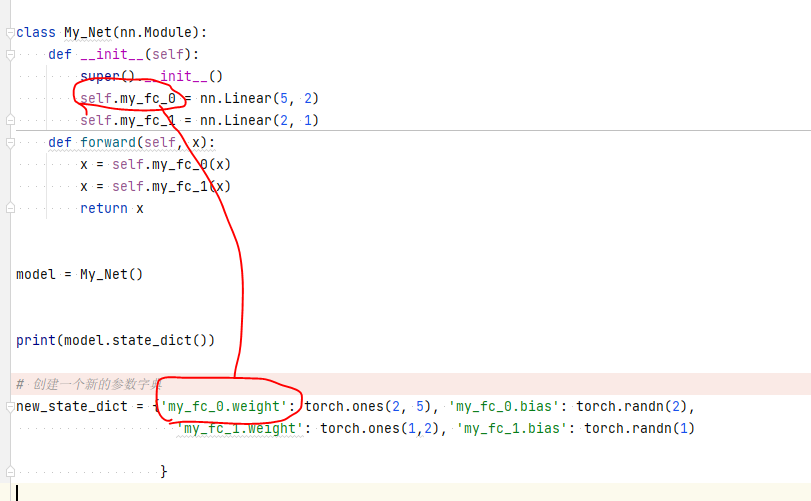
print(model.state_dict())
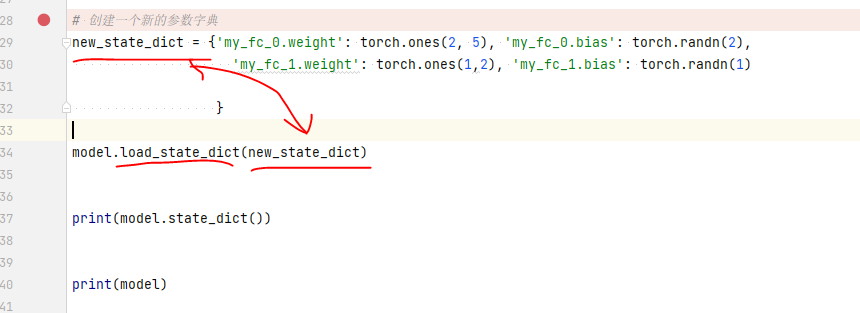
# 创建一个新的参数字典
new_state_dict = {'my_fc_0.weight': torch.ones(2, 5), 'my_fc_0.bias': torch.randn(2),
'my_fc_1.weight': torch.ones(1,2), 'my_fc_1.bias': torch.randn(1)
}
model.load_state_dict(new_state_dict)
print(model.state_dict())
print(model)
if __name__ == '__main__':
print('汀兰 Pytorch人工智能大模型')
print("end")
整体运行结果
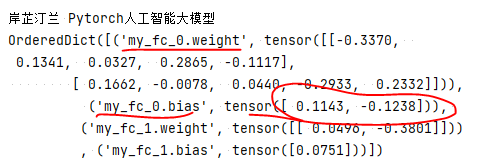
汀兰 Pytorch人工智能大模型
OrderedDict([('my_fc_0.weight', tensor([[-0.3370, 0.1341, 0.0327, 0.2865, -0.1117],
[ 0.1662, -0.0078, 0.0440, -0.2933, 0.2332]])), ('my_fc_0.bias', tensor([ 0.1143, -0.1238])), ('my_fc_1.weight', tensor([[ 0.0496, -0.3801]])), ('my_fc_1.bias', tensor([0.0751]))])
OrderedDict([('my_fc_0.weight', tensor([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])), ('my_fc_0.bias', tensor([0.9425, 0.6157])), ('my_fc_1.weight', tensor([[1., 1.]])), ('my_fc_1.bias', tensor([0.4228]))])
My_Net(
(my_fc_0): Linear(in_features=5, out_features=2, bias=True)
(my_fc_1): Linear(in_features=2, out_features=1, bias=True)
)
汀兰 Pytorch人工智能大模型
end
分段解析
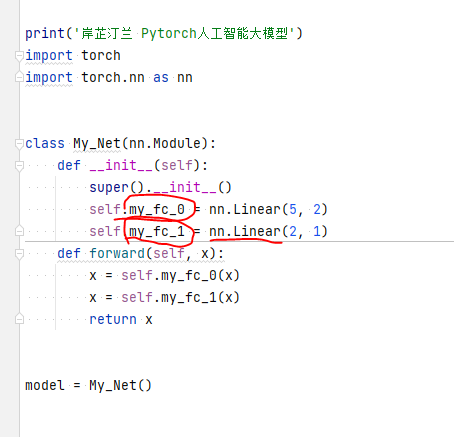
自定义模型,然后两个线性层,初始 的时候,两个线性层的参数是随机的,如下
下面自定义某个线性层的参数,特别注意,参数的字典名一定要跟模型定义的字典名一致,这才能加载到相应的模型架构。
然后将定义好的字典,通过load_state_dict,加载到模型中。
打印结果如下,因为我们使用全1,打印出来的结果是全1,
但是bias我们没有对全1,所以打印出来是随机值

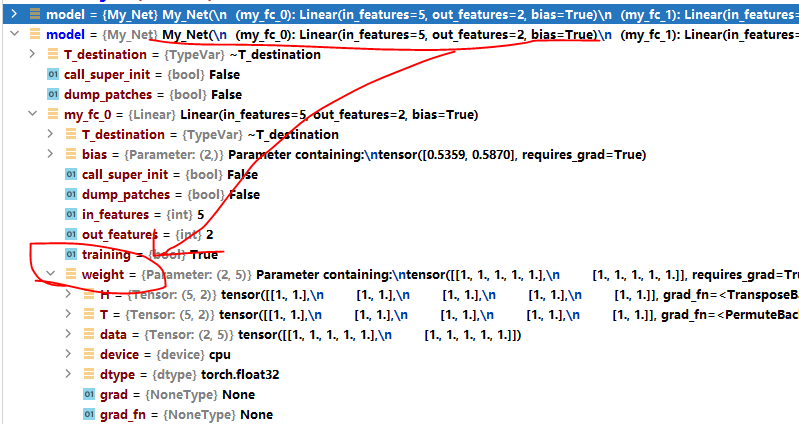
调试可见模型结构的参数已经设置为我们想要的算1,实际中,我们可以根据需要,设置成想要的任何值。
欢迎【点赞关注收藏】,深度学习神经网络的内容,会持续更新,如果你遇到什么疑问,也可以评论和留言,大家共同进步。
















 3674
3674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











