







关注我,持续分享逻辑思维&管理思维; 可提供大厂面试辅导、及定制化求职/在职/管理/架构辅导;
有意找工作的同学,请参考博主的原创:《面试官心得--面试前应该如何准备》,《面试官心得--面试时如何进行自我介绍》, 《做好面试准备,迎接2024金三银四》。
推荐热榜内容:《C#实例:SQL如何添加数据》
-------------------------------------正文----------------------------------------
算法是所有程序员必备的基本功,不会算法的程序员都容易被耻笑,今天就为大家盘点出 所有程序员都需要掌握的十大算法,可以依次进行学习
一.Floyd Warshall算法
Floyd-Warshall算法,中文称弗洛伊德算法或佛洛伊德算法,是解决任意两点间的最短路径的一种算法,可以正确处理有向图或负权(但不可存在负权回路)的最短路径问题,同时也被用于计算有向图的传递闭包。

#include <vector>
#include <iostream>
using namespace std;
void floydWarshall(vector<vector<int>>& dist) {
int n = dist.size();
for (int k = 0; k < n; ++k) {
for (int i = 0; i < n; ++i) {
if (dist[i][k] != INT_MAX) {
for (int j = 0; j < n; ++j) {
dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j]);
}
}
}
}
}
int main() {
int n, m;
cout << "Enter the number of vertices and edges: ";
cin >> n >> m;
vector<vector<int>> graph(n, vector<int>(n, INT_MAX));
vector<vector<int>> dist = graph;
int u, v, weight;
cout << "Enter edge and weight:\n";
for (int i = 0; i < m; ++i) {
cin >> u >> v >> weight;
graph[u][v] = weight;
dist[u][v] = weight;
}
floydWarshall(dist);
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
if (dist[i][j] != INT_MAX) {
cout << "Shortest path from " << i << " to " << j << " is: " << dist[i][j] << endl;
} else {
cout << "No path from " << i << " to " << j << endl;
}
}
}
return 0;
}二.二分查找
也称折半查找算法、对数查找算法,是一种在有序数组中查找某一特定元素的搜索算法。
搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。
如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。

#include <iostream>
#include <vector>
int binarySearch(const std::vector<int>& nums, int target) {
int left = 0;
int right = nums.size() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
return mid; // 找到目标,返回索引
} else if (nums[mid] < target) {
left = mid + 1; // 在右半区继续查找
} else {
right = mid - 1; // 在左半区继续查找
}
}
return -1; // 未找到目标,返回-1
}
int main() {
std::vector<int> nums = {2, 5, 8, 12, 16, 23, 38, 56, 72, 91};
int target = 23;
int index = binarySearch(nums, target);
if (index != -1) {
std::cout << "Element found at index " << index << std::endl;
} else {
std::cout << "Element not found" << std::endl;
}
return 0;
}三.贝尔曼福特算法
贝尔曼福特算法是求解单元最短路径问题的一种算法,由理查德贝尔曼和莱斯特福特创立的。有时候这种算法也被称为Moore-Bellman-ford算法,因为Edward F . Moore也为这个算法的发展做出了贡献。
它的原理是对图进行|V|-1次松弛操作,得到所有可能的最短路径。其优于迪克斯彻算法的方面是边的权值可以为负数、实现简单,缺点是时间复杂度过高,高达O(|V||E|)。但算法可以进行若干种优化,提高了效率。

#include <vector>
#include <queue>
#include <limits>
using namespace std;
typedef pair<int, int> PII;
const int INF = numeric_limits<int>::max();
struct Edge {
int to, cost;
Edge(int to, int cost) : to(to), cost(cost) {}
};
vector<Edge> graph[1000]; // 邻接表存储图
int dist[1000]; // 存储源点到其他点的当前最短路径
bool inq[1000]; // 判断某个点是否在队列中
int n, m; // 图中的点数和边数
void bellman_ford(int start) {
fill(dist, dist + n, INF);
dist[start] = 0;
queue<int> q;
q.push(start);
inq[start] = true;
while (!q.empty()) {
int u = q.front();
q.pop();
inq[u] = false;
for (auto &e : graph[u]) {
int v = e.to;
if (dist[v] > dist[u] + e.cost) {
dist[v] = dist[u] + e.cost;
if (!inq[v]) {
q.push(v);
inq[v] = true;
}
}
}
}
}
int main() {
// 初始化图
// ...
// 执行贝尔曼福特算法
bellman_ford(0); // 假设我们要找0号点到其他点的最短路径
// 输出最短路径结果
for (int i = 0; i < n; ++i) {
printf("dist[%d] = %d\n", i, dist[i]);
}
return 0;
}四.快速排序
快速排序是一种交换类排序,可以理解成对冒泡排序的一种改进排序,但快速排序的复杂度相对于冒泡排序的提升相当大。
他的思路是,选取一个关键字K,将所有比K小的记录放在K前面,比K大的数放在K后面,一趟快速排序完成,完整的快速排序就是对分出的每个新数组再进行一次快速排序,也就是一趟排序的递归操作。

#include <iostream>
using namespace std;
void swap(int* a, int* b) {
int t = *a;
*a = *b;
*b = t;
}
int partition (int arr[], int low, int high) {
int pivot = arr[high];
int i = (low - 1);
for (int j = low; j <= high - 1; j++) {
if (arr[j] < pivot) {
i++;
swap(&arr[i], &arr[j]);
}
}
swap(&arr[i + 1], &arr[high]);
return (i + 1);
}
void quickSort(int arr[], int low, int high) {
if (low < high) {
int pi = partition(arr, low, high);
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
void printArray(int arr[], int size) {
for (int i = 0; i < size; i++)
cout << arr[i] << " ";
cout << endl;
}
// 主函数
int main() {
int arr[] = {10, 7, 8, 9, 1, 5};
int n = sizeof(arr)/sizeof(arr[0]);
quickSort(arr, 0, n-1);
cout << "Sorted array: \n";
printArray(arr, n);
return 0;
}五.贪心算法
顾名思义,贪心法,贪心算法总是做出在当前看来是最好的选择。虽然贪心算法不是对所有问题都能得到整体最优解,但对范围相当广的许多问题都能产生整体最优解或是问题的次优解。因此有很好使用它的必要性。贪心算法既是一种解题策略,也是一种解题思路。

#include <iostream>
#include <vector>
int greedyRangeSum(const std::vector<int>& nums, int target) {
int result = 0;
int currentSum = 0;
int left = 0;
for (int right = 0; right < nums.size(); right++) {
currentSum += nums[right];
while (currentSum > target) {
currentSum -= nums[left++];
}
if (currentSum == target) {
result += 1;
}
}
return result;
}
int main() {
std::vector<int> nums = {1, 2, 3, 4, 5};
int target = 9;
std::cout << greedyRangeSum(nums, target) << std::endl; // 输出: 3 (子数组 [1, 2, 3], [2, 3, 4] 和 [3, 4, 5] 的和均为 9)
return 0;
}六.拓扑排序
拓扑排序是一种把有向无环图转换成线性序列的排序算法,算法的输入是一个有向无环图,经过算法分析吧图中的所有节点按照先后顺序进行拆解,最后得到一个有顺序的队列,在前的节点靠前,越靠后的节点或有多个节点指向该节点,那这个节点再队列中的位置就越靠后。

#include <iostream>
#include <vector>
#include <queue>
#include <algorithm>
std::vector<int> topologicalSort(int n, std::vector<std::vector<int>>& edges) {
std::vector<int> inDegree(n, 0);
std::vector<int> result;
std::queue<int> zeroInDegree;
// 计算每个顶点的入度
for (auto& edge : edges) {
++inDegree[edge[1]];
}
// 将所有入度为0的顶点加入队列
for (int i = 0; i < n; ++i) {
if (inDegree[i] == 0) {
zeroInDegree.push(i);
}
}
// 进行拓扑排序
while (!zeroInDegree.empty()) {
int node = zeroInDegree.front();
zeroInDegree.pop();
result.push_back(node);
for (auto& edge : edges) {
if (edge[0] == node) {
--inDegree[edge[1]];
if (inDegree[edge[1]] == 0) {
zeroInDegree.push(edge[1]);
}
}
}
}
if (result.size() != n) {
result.clear(); // 图中存在环,无法进行拓扑排序
}
return result;
}
int main() {
int n = 6; // 顶点数
std::vector<std::vector<int>> edges = {
{5, 2}, {5, 0}, {3, 4}, {4, 2}, {3, 0}, {1, 2}, {1, 4}
}; // 边数,表示有向边<from, to>
std::vector<int> sorted = topologicalSort(n, edges);
if (!sorted.empty()) {
for (int vertex : sorted) {
std::cout << vertex << " ";
}
} else {
std::cout << "Graph has a cycle, cannot perform topological sorting." << std::endl;
}
return 0;
}七.动态规划
很多人都会觉得动态规划很难,动态规划的核心思想有以下两点:
第一,任何看似很复杂很难解决的问题,其实都可以归结为一系列子问题,无论一个问题有多复杂,只要他有解决方案,就可以归结为N个子问题,某种意义上,我们可以认为动态规划是对递归的一种优化;
第二,我们在解决N个子问题的时候,要留心整体上有没有做无用功,通过备忘录的方式保存中间状态,使得不反复去计算已经求得的中间解。

以下是一个简单的动态规划算法的C++实现例子,它解决了一个简单的子序列和问题。
问题描述:给定一个整数序列 A 和一个整数 S,找出 A 中最长的子序列,其总和大于或等于 S。
#include <iostream>
#include <vector>
using namespace std;
int findLongestSubsequence(const vector<int>& nums, int target) {
vector<int> dp(nums.size(), 0);
int longest = 0;
for (int i = 0; i < nums.size(); ++i) {
dp[i] = 1; // 初始化长度为1
for (int j = 0; j < i; ++j) {
if (nums[i] > nums[j] && dp[j] > 0) {
if (nums[i] - nums[j] >= target) {
dp[i] = max(dp[i], dp[j] + 1);
}
}
}
longest = max(longest, dp[i]);
}
return longest;
}
int main() {
vector<int> nums = {2, 3, 1, 4, 3};
int target = 3;
cout << "The longest subsequence with sum greater than or equal to " << target << " is: " << findLongestSubsequence(nums, target) << endl;
return 0;
}八.最小生成树
最小生成树问题,简称MST,指给定一个带权的无向连通图,如果选取一棵生成树,使树上所有边上权的总和为最小,这叫最小生成树。
图有N个顶点,就一定有N-1条边,且必须包含所有顶点,所有边都在图中。解决最小生成树问题的算法主要有普利姆算法和克鲁斯卡尔算法。

在C++中,可以使用Prim算法或Kruskal算法来构建最小生成树。以下是使用Prim算法的一个简单示例:
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
vector<vector<int>> graph;
vector<int> parent;
int V;
void prim() {
vector<bool> visited(V, false);
vector<int> key(V, INT_MAX);
key[0] = 0; // Assuming graph is connected
parent[0] = -1;
for (int i = 0; i < V - 1; i++) {
int u = min_element(key.begin(), key.end()) - key.begin();
visited[u] = true;
for (int v = 0; v < V; v++) {
if (!visited[v] && graph[u][v] && key[v] > graph[u][v]) {
key[v] = graph[u][v];
parent[v] = u;
}
}
}
// Print the parent and key vectors
for (int i = 0; i < V; i++) {
cout << "Edge " << i << " - " << parent[i] << " is part of MST\n";
}
}
int main() {
V = 5; // Number of vertices in the graph
graph = vector<vector<int>>(V, vector<int>(V, INT_MAX));
parent = vector<int>(V, -1);
// Fill the graph edges
graph[0][1] = 2;
graph[0][2] = 4;
graph[0][3] = 6;
graph[1][2] = 3;
graph[1][4] = 5;
graph[2][4] = 6;
graph[3][4] = 6;
prim();
return 0;
}九.深度搜索和广度搜索算法
又称DFS和BFS。深度优先搜索的原理是:首先选择一个顶点作为起始点,接着从他各个相邻点出发进行依次访问,直到所有与起始点有路径相通的顶点都被访问到。若此时有没被访问到的节点,则选择一个其他顶点进行再次访问。
广度优先搜索的原理是:选择一个顶点作为起始点,依次访问该起始点的所有邻接点,再根据邻接点访问他们各自的邻接点,并保证先访问节点的邻接点先与后访问节点的邻接点被访问。

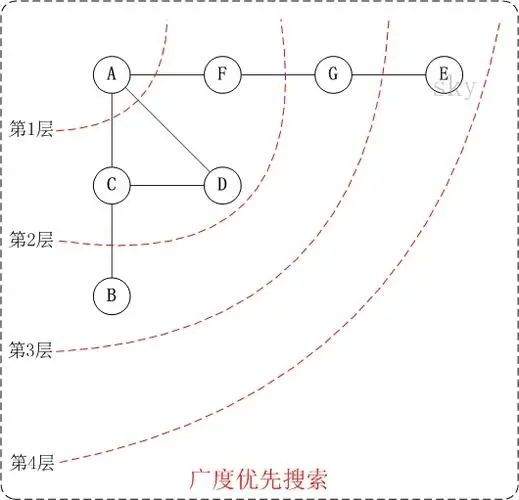
假设我们有一个无向图,用邻接矩阵表示,我们需要实现DFS来遍历所有的顶点。
#include <iostream>
#include <vector>
using namespace std;
void dfs(vector<vector<int>>& graph, vector<bool>& visited, int start) {
visited[start] = true;
cout << start << " ";
for (int i = 0; i < graph[start].size(); ++i) {
if (!visited[graph[start][i]]) {
dfs(graph, visited, graph[start][i]);
}
}
}
int main() {
int n = 4; // 假设图有4个顶点
vector<vector<int>> graph = {{1, 2}, {0, 2}, {0, 3}, {1, 3}}; // 邻接矩阵
vector<bool> visited(n, false); // 访问标记数组
// 从顶点0开始深度优先搜索
dfs(graph, visited, 0);
return 0;
}在这个例子中,dfs函数是深度优先搜索的核心,它使用一个递归函数来访问还未访问的每个顶点,并且用cout语句输出当前访问的顶点编号。visited数组用于记录每个顶点是否已经被访问过。
这个例子假设图是用邻接矩阵表示的,并且没有负权边或自环。如果需要处理带权图或者不规则图结构,你可能需要修改代码以适应相应的数据结构和算法细节。
广度搜索算法通常用于遍历或搜索图、树等结构的节点,以便找到从起始节点到目标节点的最短路径或执行其他任务。下面是一个简单的C++实现示例,使用队列来实现广度搜索算法。
#include <iostream>
#include <queue>
#include <vector>
using namespace std;
// 广度优先搜索算法
void bfs(vector<vector<int>>& graph, int start, int target) {
queue<int> q;
vector<int> visited(graph.size(), 0);
q.push(start);
visited[start] = 1;
while (!q.empty()) {
int node = q.front();
q.pop();
if (node == target) {
cout << "找到了目标节点!" << endl;
return;
}
for (int neighbor : graph[node]) {
if (!visited[neighbor]) {
q.push(neighbor);
visited[neighbor] = 1;
}
}
}
cout << "未找到目标节点。" << endl;
}
int main() {
// 图的表示
vector<vector<int>> graph = {
{1, 2},
{0, 3},
{0, 4},
{3, 4}
};
// 广度优先搜索的起点和目标节点
int start = 0;
int target = 4;
bfs(graph, start, target);
return 0;
}这段代码定义了一个bfs函数,它接受一个图(用邻接列表表示的邻接矩阵)、一个起始节点和一个目标节点作为参数。使用一个队列来保存待访问的节点,并且使用一个标志数组visited来记录哪些节点已经被访问过。如果找到了目标节点,算法将停止,否则输出未找到目标节点。
十.朴素贝叶斯分类算法
朴素贝叶斯分类算法是一种基于贝叶斯定理的简单概率分类算法。
贝叶斯分类的基础是概率推理,就是在各种条件的存在不确定,仅知其出现概率的情况下,如何完成推理和决策任务。概率推理是与确定性推理相对应的。而朴素贝叶斯分类器是基于独立假设的,即假设样本每个特征与其他特征都不相关。

以下是一个简化的C++源代码示例,演示了如何实现一个朴素贝叶斯分类器的基本框架。注意,这里没有包含任何特征缩放或标准化的步骤,也没有实现完整的训练和分类过程,仅提供了一个可能的框架。
#include <iostream>
#include <vector>
#include <map>
#include <string>
using namespace std;
class NaiveBayesClassifier {
public:
// 训练函数,更新贝叶斯参数
void train(const string& classLabel, const vector<double>& features) {
// 更新类先验概率
++classPriors_[classLabel];
// 更新特征条件概率
for (size_t i = 0; i < features.size(); ++i) {
featureConditionals_[classLabel][i][features[i]] += 1;
}
}
// 分类函数,基于贝叶斯定理返回最佳类别
string classify(const vector<double>& features) {
double maxPosterior = 0.0;
string maxClass;
// 遍历所有类别并找到最大后验概率的类别
for (const auto& classLabel : classPriors_) {
double posterior = classPrior(classLabel.first) * featurePosterior(classLabel.first, features);
if (posterior > maxPosterior) {
maxPosterior = posterior;
maxClass = classLabel.first;
}
}
return maxClass;
}
private:
// 计算特定类别的先验概率
double classPrior(const string& classLabel) const {
return (double)classPriors_[classLabel] / totalTrainingExamples_;
}
// 计算给定特征下的后验概率
double featurePosterior(const string& classLabel, const vector<double>& features) const {
double posterior = 1.0;
for (size_t i = 0; i < features.size(); ++i) {
posterior *= featureConditional(classLabel, i, features[i]);
}
return posterior;
}
// 计算特定特征条件的概率
double featureConditional(const string& classLabel, size_t featureIndex, double featureValue) const {
auto it = featureConditionals_.find(classLabel);
if (it != featureConditionals_.end()) {
auto featureIt = it->second.find(featureIndex);
if (featureIt != it->second.end()) {
auto valueIt = featureIt->second.find(featureValue);
if (valueIt != featureIt->second.end()) {
return (double)valueIt->second / classPriors_[classLabel];
}
}
}
return 1.0 / featureConditionals_[classLabel][featureIndex].size(); // 平滑处理
}
map<string, int> classPriors_; // 每个类别的先验概率
map<string, map<size_t, map<double, int>>> featureConditionals_; // 每个特征条件的概率
int totalTrainingExamples_ = 0; // 总训练例数
};
int main() {
NaiveBayesClassifier classifier;
// 示例用法:训练分类器
string classLabel = "A";
vector<double> features = {1.0, 2.0};
classifier.train(classLabel, features);
// 示例用法:分类
features = {0.1, 0.2};
classLabel = classifier.classify(features);
cout << "Classified as: " << classLabel << endl;
return 0;
}关注我,持续分享逻辑、算法、管理、技术、人工智能相关的文章。
博主其它经典原创:《管理心得--工作目标应该是解决业务问题,而非感动自己》,《管理心得--如何高效进行跨部门合作》,《管理心得--员工最容易犯的错误:以错误去掩盖错误》,《技术心得--如何成为优秀的架构师》、《管理心得--如何成为优秀的架构师》、《管理心理--程序员如何选择职业赛道》。欢迎大家阅读。
















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











