







指针
指针一直是一个让我非常头疼的问题,后来我在CSDN的一篇博客上看到了对指针的讲解,让我恍然大悟,下面我就先来说一下关于指针的问题,并通过链表的知识来具体的应用一下指针。
首先,指针是什么?按照我的理解,他就是一个指向变量的内存地址的变量,可能有点绕,对于指针,我们可以定义一个指针变量,他同样也是一种数据类型,并且在32位计算机中都是占4个字节的大小,下面我们来定义一个指针:
#include<iostream>
using namespace std;
int main(){
int b = 3;
int* a = &b;
return 0;
}在这一段代码中,我们首先定义了一个整型变量b,并赋值为3,然后定义了一个指针变量a,用来存储b的地址,&是取地址符号,而int* a则是对指针变量的定义,表示指针变量a是一个用来存储整型数据的地址的一个指针。
这里我们要注意一下在指针的定义和使用时的区别,我们看下面的一段代码:
#include<iostream>
using namespace std;
int main(){
int b = 3;
int* a = &b;
cout<< *a <<endl;
return 0;
}这一段代码输出的结果是变量b的值,也就是3,由于int* a和cout中的*a长的非常相似,并且在指针变量的定义中,我们也可以用这种格式进行指针变量的定义:int *a;因此,我刚开始学习的时候总是会把这两者给搞混,不明白为什么含义会不一样。所以我要强调,这两者是完全不一样的东西,cout中的*a是将指针a指向的地址所代表的值输出,也就是在指向b的地址中,将b的值输出出来。
下面我们画一个图来表示这一层关系: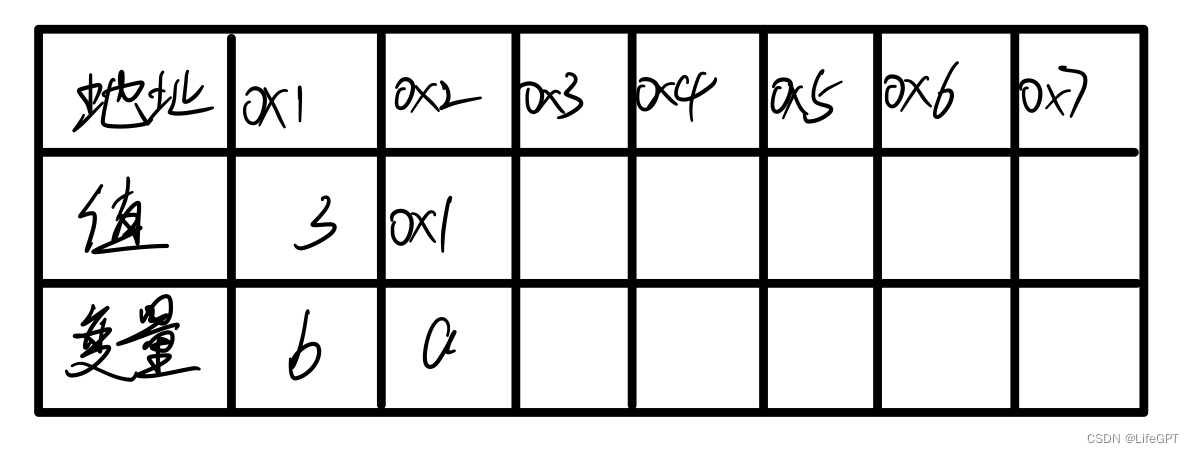
我们知道指针变量也是一个变量,他存储着b的地址0x1(实际不是,这里是假设),而cout<<*a;的原理就是先找到a存储的地址是谁的地址,然后将这个地址上的存储的值给输出出来,本质上和b其实没有太大的关系(可能有吧,个人理解)。
为了深入理解,我们多来几个变量:
#include<iostream>
using namespace std;
int main(){
int b = 3;
int c = 4;
int d = 5;
return 0;
}这里我们依旧用图来表示:
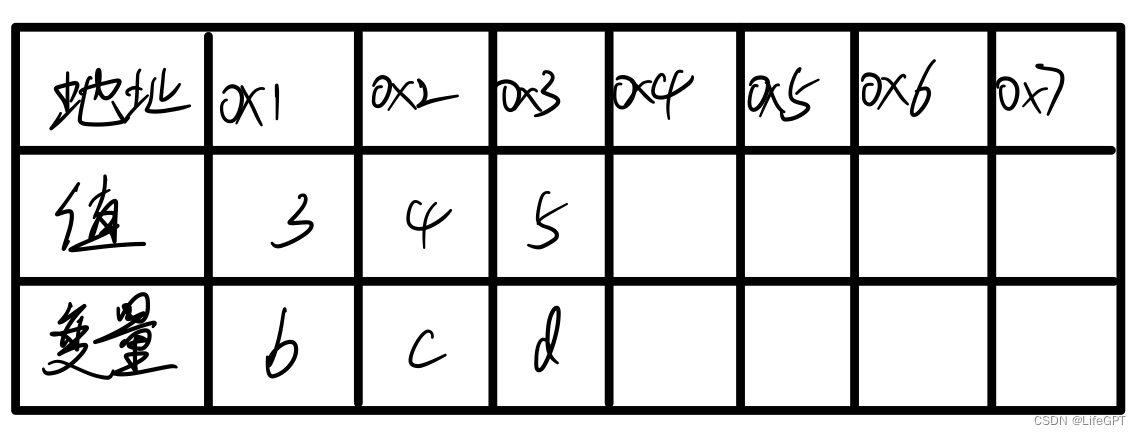
那如果我们现在定义一个指针变量a,并且我们想通过指针变量a来改变c的值该怎么办呢?其实非常简单,我们前面知道了,在除了变量的定义中,其他地方我们使用*a都是代表a存储的地址上的那个具体的值,所以我们只需要这样:
#include<iostream>
using namespace std;
int main(){
int b = 3;
int c = 4;
int d = 5;
int* a = &c;
*a = 6;
cout<<c<<endl;
return 0;
}这样的操作就可以在内存中将c的值彻底的覆盖成6了。
指针的指针
也许这才是让你们感觉到指针可怕的地方,指针可以有指针的指针,也可以有指针的指针的指针.....(禁止套娃),但其实概念都是一样的,只不过难在思考和逻辑,我们知道指针本身就是一个变量,那么变量就在内存中就一定会有地址,所以指针变量也会有地址,那指向指针变量的地址的指针,不就是指针的指针了嘛?那指向指针的指针变量的地址的指针,不就是指针的指针的指针了嘛!!!算了不说了,再说下去我就怕被喷了哈哈哈。
下面直接上代码:
#include<iostream>
using namespace std;
int main(){
int b = 3;
int c = 4;
int d = 5;
int* a = &c;
int** s = &a;
cout<<**s<<endl;
return 0;
}大家独立思考一下的话,可以知道最后输出的是什么嘛?我就不等你们啦,下面我们看一下图解:
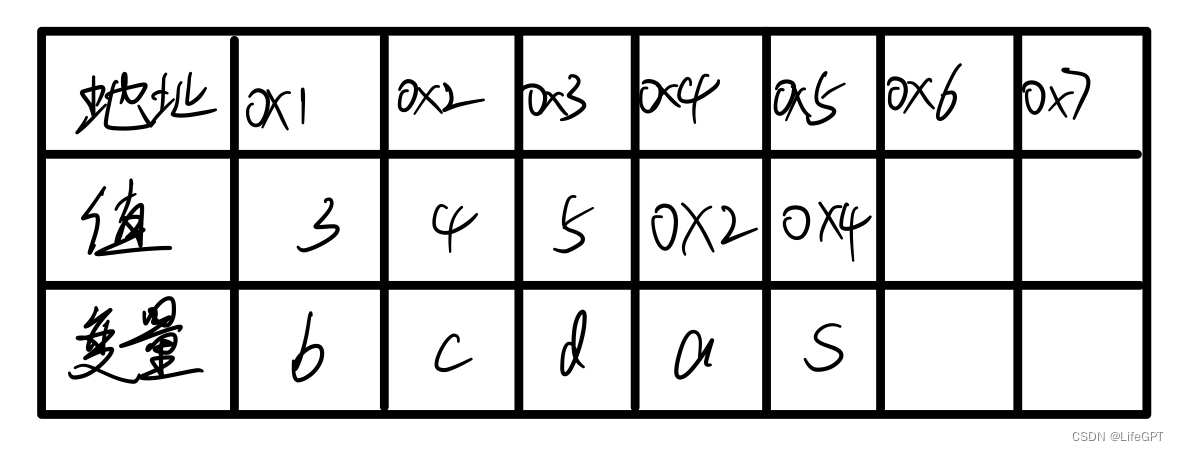
在输出的时候,程序知道*a是指针,**s是指针的指针。
那么当需要输出*a的值的时候,程序他就明白了:哦!这是一个Easy的指针,只需要将他存储的地址所在的值输出就好啦!所以只需要寻找一次地址就可以了。
那当程序遇到**s,程序就会觉得:厚礼蟹?指针的指针?那s存储的是另一个指针的地址啊!害的我还要先找到另一个指针存储的地址,再根据另一个地址找到那个值!太麻烦了!
所以在图中,就是这样一个过程:
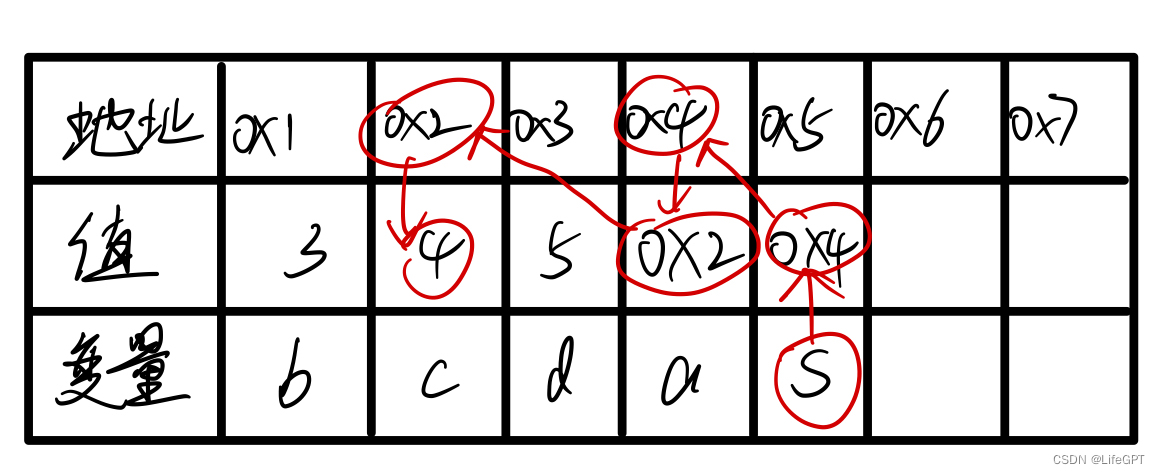
因此,**s输出的值其实就是c的值啦:4,那么如果输出的是*s呢?那当然就是0x2了~~~
对于指针的理解就到此为止,其实还是需要去刷题来了解,以便加深印象的!下面我们就通过学到的指针的知识来说一说链表的原理吧!(先学一下结构体哦!!!So easy的)
链表
我初步学到链表,我会感觉他和一个数组很像,但是当我深入的学习后,才发现和数组的天差地别,如果可以熟练的应用链表,那么某些算法问题将会非常的简单。这里默认大家已经学过结构体了,所以我直接给出下面的代码:
struct Node{
int val;
List* next;
Node(int x) : val(x),next(NULL){}
};这是一个结构体Node,Node中文名就是节点的意思,这也是链表中一个节点的最常用的写法,用图像来表示可以将上面的代码画成这样:
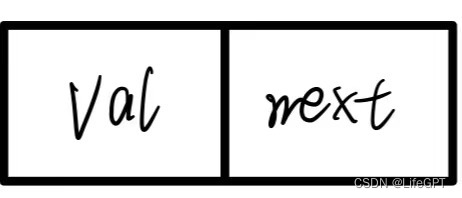
这一整个矩形就是一个结构体Node,也就是一个节点,每个节点中存储着一个整型变量val以及一个结构体类型的指针next。
这里突出强调一下结构体指针next,我们不可以定义Node next,为什么呢?因为在代码的执行过程中,当执行到Node next的时候,整个结构体的语句还没有执行完,也就是说结构体其实还没有定义,即没有给这个结构体Node分配内存,居然都没有分配内存,又怎么能给一个变量定义他自己的类型呢?就比如int我们知道占4个字节,所以通过int 我们可以直接定义一个整型变量,但是此时的Node next中,Node是未知的,所以不可以定义,但是Node* next可以,因为不论是什么类型的指针变量,指针都是只占4个字节,这是程序规定好的,所以这句话其实大家不要多想,你只要记得,Node* next的意思就是,next是一个指针,并且这个指针只能用来存储Node这个结构体类型的地址,因此next被称为Node结构体类型的结构体指针。至于到底有什么用,看下去,相信我,你会懂的!!!
构造函数就不多说了,这是结构体的知识~~
有了结构体,我们就可以写主函数来看看他有什么用:
#include<iostream>
using namespace std;
struct Node{
int val;
Node* next;
Node(x) : val(x),next(NULL){}
}
int main(){
Node* p = new Node(1);
cout<<p->val<<endl;
cout<<p->next<<endl;
return 0;
}注释:这里先简单说一下->的作用,由于我们定义了结构体指针p,所以p是一个结构体指针,不是一个结构体变量,如果结构体指针想要读取结构体中的某变量的值,就必须要使用 ->,如果是结构体变量就可以写成p.val和p.next了。
这里我们定义了一个结构体指针变量 p ,并将1传给结构体内部中,此时val = 1,next = NULL,如果这里不理解,马上去学习结构体,不要往下看了!!!!!
也就是说,指针p指向这个结构体的地址,并且这个结构体中的两个值val=1,next=NULL,所以这里输出的值就是1和0(NULL就是空,也就是0)。
下面我们多来几个节点:
#include<iostream>
using namespace std;
struct Node{
int val;
Node* next;
Node(x) : val(x),next(NULL){}
}
int main(){
Node* p = new Node(1);
Node* q = new Node(2);
Node* k = new Node(3);
return 0;
}如果前面理解了,这里应该没什么难度,这里定义了三个结构体指针p,q,k,每个指针指向的地址的val的值分别是1,2,3,next都是NULL,现在节点我们已经定义好了,也就是下面这样:
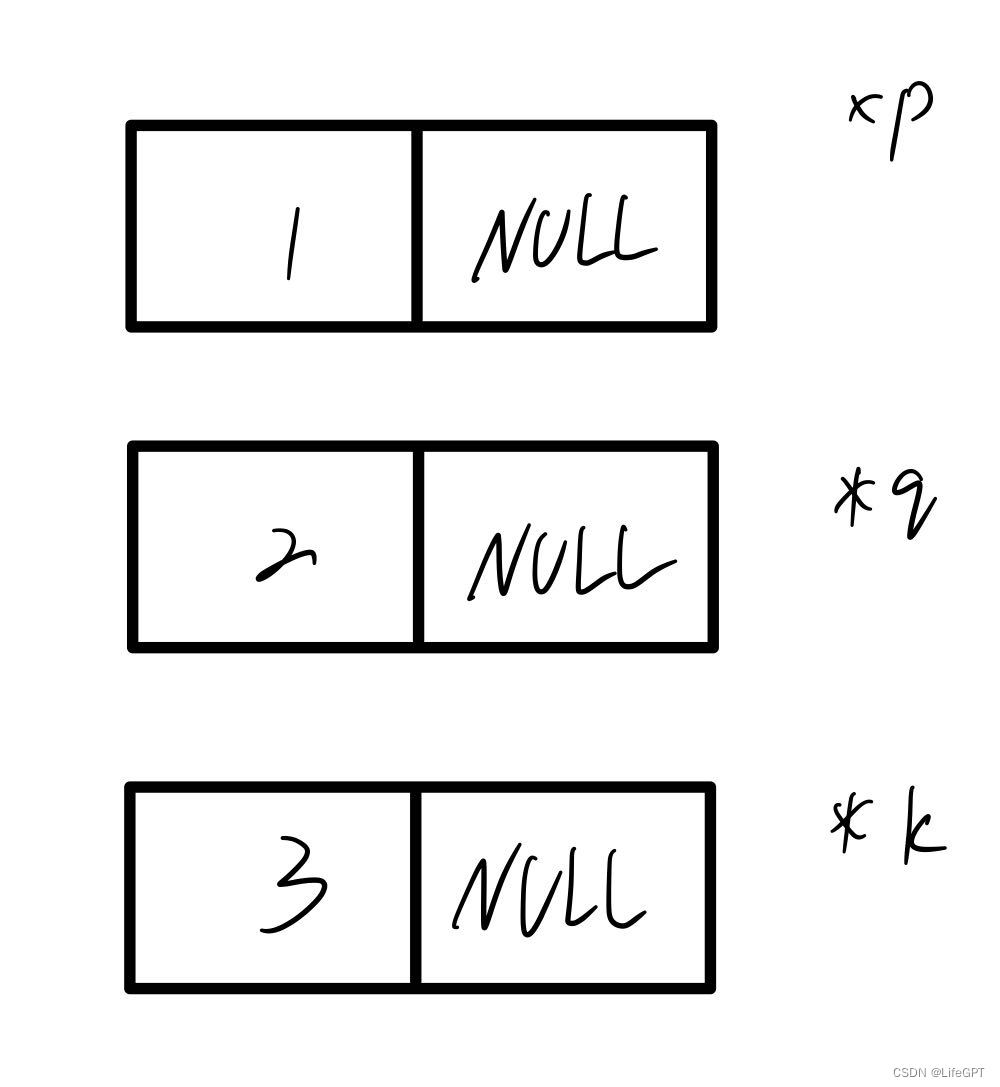
那么所谓的链表,当然是一条链啦,怎么把他们三个串一条链呢?我们先来看一下他们串号的样子吧:
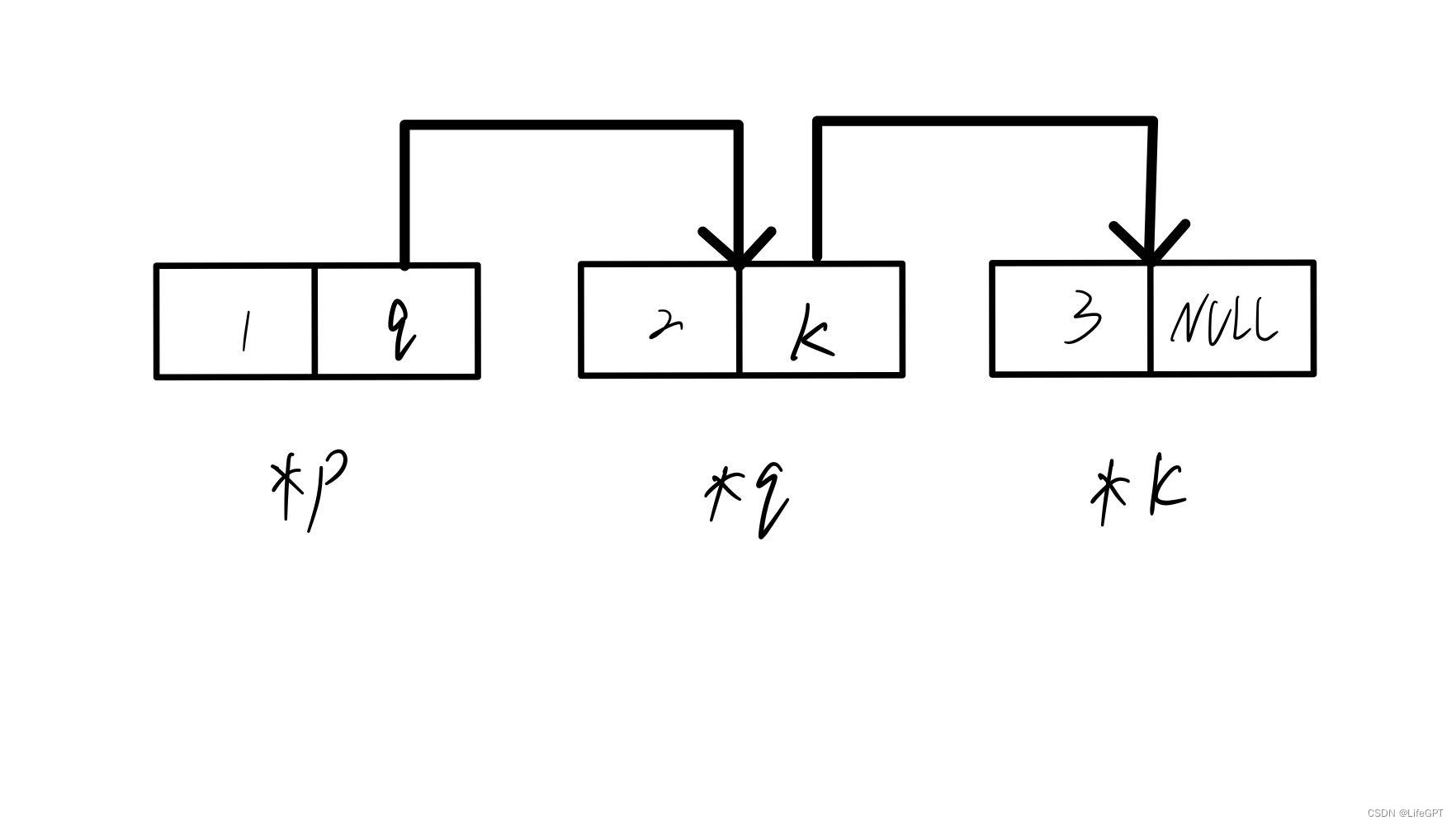
我们知道,p,q,k存储的都是Node结构体类型的地址,所以可以被指针next存储,对于每一个节点,其next存储的都是下一个节点的地址。这样我们就把他们串在了一起,其实就是相互之间有对应的联系罢了。
那要怎么实现呢?代码如下:
#include<iostream>
using namespace std;
struct Node{
int val;
Node* next;
Node(x) : val(x),next(NULL){}
}
int main(){
Node* p = new Node(1);
Node* q = new Node(2);
Node* k = new Node(3);
p->next = q;
q->next = k;
return 0;
}是的,就是加了两行简单的代码就实现了,我们将p中next的值存储为地址q,q是第二个节点的地址,而q中的next节点存储为地址k,k也是相对于q来说下一个节点的地址,这样我们的一个简单的初步链表就建好啦,当然这有一个专门的称呼,叫做单向链表,因此也有双向链表,双向链表其实就是在我们这个节点的基础上,在每个节点中再多加一个prev指针变量来存储上一个节点的地址,实现双向操作,这里就不细说了。
OK,链表的基础知识其实就是那么简单,但是题目可不简单,我们来看道题目来加深印象吧:
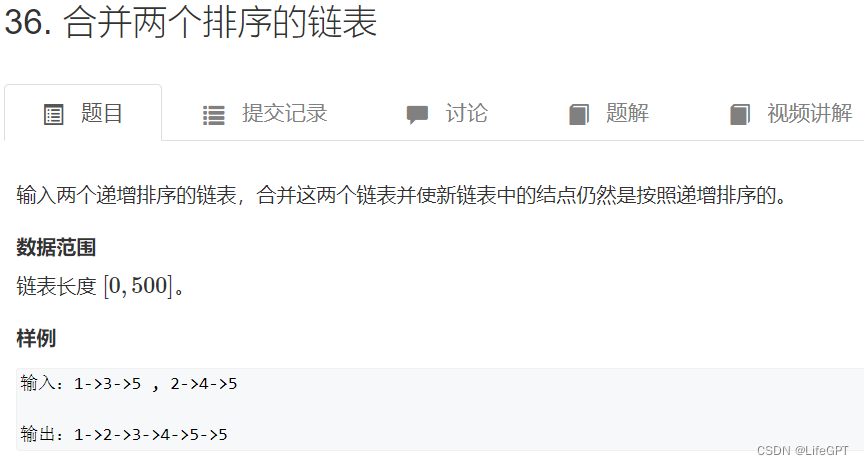
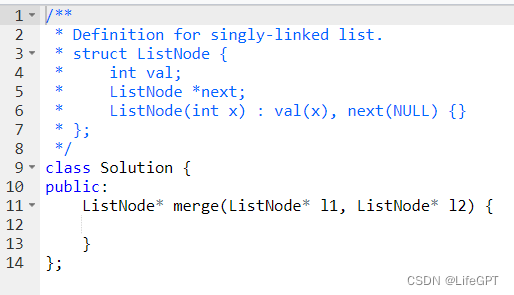
注意一下,这里的主函数和结构体已经在平台写好了,不需要我们写,只需要写函数中的内容并返回最后的链表即可。
答案如下:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* merge(ListNode* l1, ListNode* l2) {
ListNode* head = new ListNode(0);
ListNode* tail = head;
while(l1&&l2){
if(l1->val < l2->val){
tail->next = l1;
l1 = l1->next;
}else{
tail->next = l2;
l2 = l2->next;
}
tail = tail->next;
}
if(l1) tail->next = l1;
if(l2) tail->next = l2;
return head->next;
}
};主要思路是:
1、定义虚拟链表头部指针,并设置一个尾指针,尾部指针的地址和虚拟头指针head相同,即一方的值改变,另一个也改变。
2、l1和l2分别都是俩链表的头部,从头部开始遍历,直到有一个为NULL(即0)为止,每遍历一个判断一次两者的大小,小的那个的值的结构体的地址传给tail的下一个节点,即next,最后tail向前移动一个节点,进行下一次的尾部添加。
3、如果其中一个链表遍历完毕,另一个还没有,那么也就是说另一个链表的所有值都是从小到大并且最小的值比现在的tail的最大值还要大,只要将没有遍历完之后的所有值接到tail的后面即可,由于l1/l2本身就是指针,即上一个节点的next是下一个节点的地址,所以直接接入没有遍历完的第一个即可,后面已经是一个链表就不用处理了。
4、由于tail是从0开始的,只保存下一个节点的地址,而val是从下一个节点开始保存的,也就是head的头部节点的val是一个无效的值,而他的next才是指向下一个节点的有效值的地址,所以输出的时候要从head的第二个节点开始。
另外一个题是比较经典的链表题,叫做约瑟夫环(洛谷P1996),就当做练习啦~~~
















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











