







 研究提出了一种名为DCL-Net的深度学习网络,能够在无外部跟踪设备的情况下,利用超声视频的上下文信息进行3D图像重建。DCL-Net采用3D卷积和自注意力模块,关注散斑丰富区域以提高运动预测准确性。通过案例相关损失函数增强训练,防止过拟合,提高了重建的精确度。
研究提出了一种名为DCL-Net的深度学习网络,能够在无外部跟踪设备的情况下,利用超声视频的上下文信息进行3D图像重建。DCL-Net采用3D卷积和自注意力模块,关注散斑丰富区域以提高运动预测准确性。通过案例相关损失函数增强训练,防止过拟合,提高了重建的精确度。
论文:https://arxiv.org/abs/2006.07694
代码:https://github.com/DIAL-RPI/FreehandUSRecon
1. 研究概述
目前从徒手超声扫描(freehand US)重建 3D 图像需要外部跟踪设备来提供每一帧的空间位置。本文提出了一种深度上下文学习网络(DCL-Net),它可以有效地利用超声扫描各帧之间的图像特征关系,在不需要任何跟踪设备的情况下重建 3D 图像。所提出的 DCL-Net 通过对超声视频片段运用 3D 卷积来进行特征提取。嵌入的自注意力(self-attention)模块使网络关注散斑丰富的区域,以获得更好的空间运动预测。本文还提出了一种新的案例相关损失(case-wise correlation loss)来稳定训练过程,以提高准确率。实验结果表明,本文提出的 DCL-Net 能够很好地提取多帧超声图像之间的信息,提高超声探头运动估计的精度。
2. 研究背景
3D 超声成像通过重建一系列 2D 超声图像来可视化 3D 感兴趣区域(ROI),可以通过各种扫描技术(如机械扫描和徒手跟踪扫描)来获得超声图像。在各种扫描技术中,徒手跟踪扫描是许多临床场景中最适合的方法。例如,在前列腺活检过程中,徒手扫描允许临床医生在 ROI 周围自由移动超声探头,并以更大的灵活性生成超声图像。常用的跟踪装置包括光学或电磁跟踪系统,用于在成像平面之间建立空间变换关系,以进行三维重建。
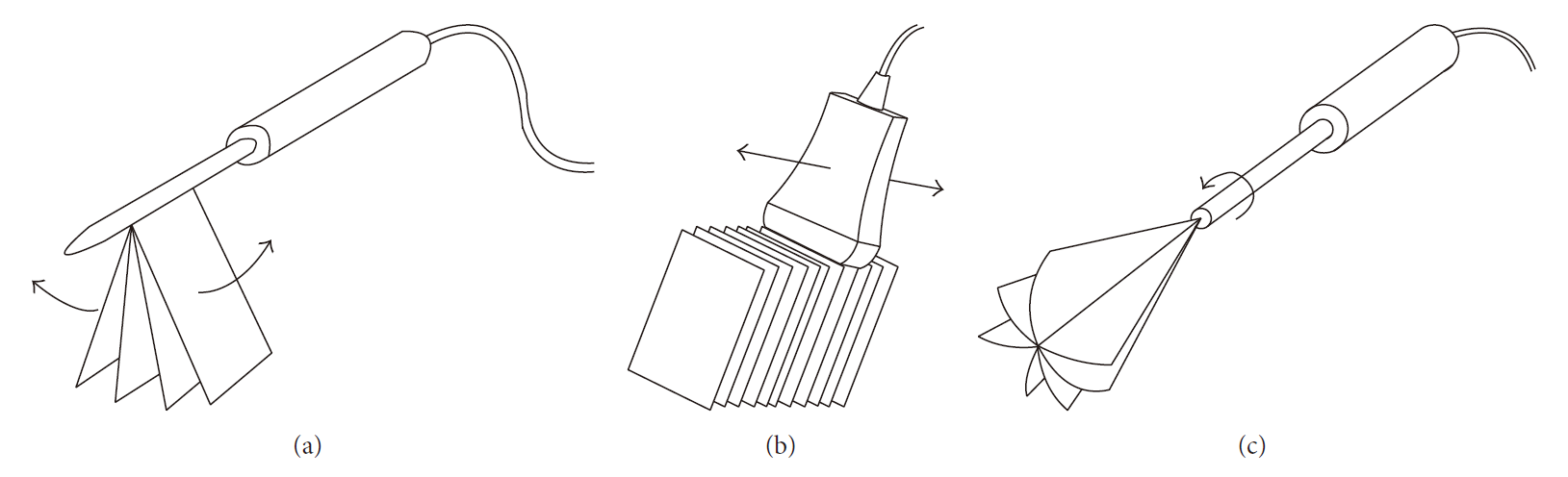
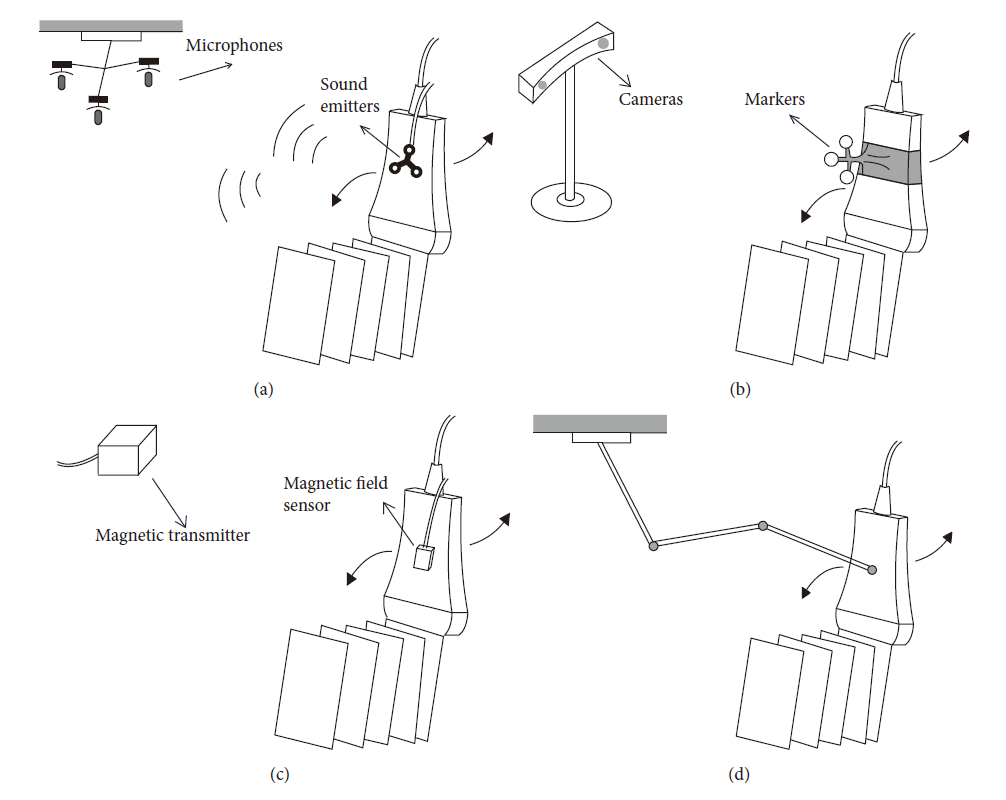
对徒手扫描超声 3D 重建的研究通过移除附在超声探头上的跟踪装置进一步向前推进。先前对此的研究主要基于散斑去相关(speckle decorrelation) ,散斑去相关将相邻超声图像之间位置和方向的相对差异映射为其散斑图案的相关性,即,散斑相关性越高,相邻帧之间的高程(elevational distance)越小。通过移除跟踪装置,这种无传感器重建允许临床医生以较少的约束移动探头,而无需担心阻挡跟踪信号。此外,它还降低了硬件成本。尽管散斑相关性携带相邻帧之间的相对变换信息,但仅依赖去相关会导致性能不可靠。
在过去的十多年中,基于卷积神经网络的深度学习方法被认为是自动特征提取的重要工具。在超声3D 重建领域,Prevost 等人开展了一项开创性的工作[2],探讨了使用 CNN 直接估计两个二维超声扫描图像之间运动的可行性。Prevost等人将两个连续帧和它们之间产生的光流场 作为叠加输入,以估计这两个帧之间的相对旋转和平移。然而,超声扫描视频包含两个相邻帧之外更加丰富的上下文信息。使用一系列帧可以提供超声探头运动轨迹的更一般的表示。仅使用两个相邻帧可能会丢失时间信息,从而导致较不准确的重建。另外,适合于描述平面内运动的光流场对平面外的运动分析可能没有帮助。此外,前人对去相关的研究表明,对散斑丰富的区域给予更多的关注可以提高重建性能。
在本文中,我们基于上述研究结果,提出了一种新的深度上下文学习网络(DCL-Net),用于无传感器徒手扫描三维超声重建。该网络以多个超声连续帧作为输入,而不是只有两个相邻帧,通过有效地利用丰富的上下文信息来估计超声探头的轨迹。此外,为了使网络关注散斑丰富的图像区域以利用帧之间的去相关信息,在网络体系结构中嵌入了注意力机制 。最后,我们引入了一种新的案例相关损失来增强判别性特征学习,以防止过度拟合扫描风格。
We introduce a new case-wise correlation loss to enhance the discriminative feature learning to prevent overfitting the scanning style.
3. 研究方法
3.1 数据集
研究中所有的经直肠超声扫描(TRUS)视频均由电磁(EM)跟踪设备从临床中获得。该数据集包含 640 个 TRUS 视频,每一帧对应于一个 EM 跟踪向量,该向量包含该帧的位置和方向信息。我们将此向量转换为三维齐次变换矩阵 M = [R T; 0 1],其中 R 是 3×3 旋转矩阵,T 是 3D 平移向量。
三维超声重建的首要任务是获得多个连续帧的相对空间位置。在不失一般性的情况下,这里我们以两个相邻帧为例进行说明。设 和
分别表示具有变换矩阵
和
的两个连续帧。相对变换矩阵
可计算为
。通过将
分解为 6 个自由度
,其中包含以毫米为单位的平移和以度为单位的旋转,我们可以使用从 EM 跟踪计算出的这个
作为网络训练的真实值(ground-truth)。
将数据集分为 500 个、70 个和 70 个视频,分别用于训练、验证和测试。我们的网络使用 Adam 优化器训练了 300 个周期,批次大小 K=20,初始学习率为 ,5 个周期后衰减 90%。由于前列腺超声图像只占每一帧图像较小的一部分,因此每一帧都被裁剪,然后将大小调整为 224×224。DCL-Net 的整个训练阶段大约需要 4h,以 5 帧作为输入。在测试过程中,生成一个100 帧超声视频的所有变换矩阵大约需要 2.58 s。
3.2 超声三维重建
3.2.1 DCL-NET 网络结构
下图显示了本文提出的 DCL-NET 网络结构,该架构设计在 3D ResNext 模型之上。我们的模型由 3D 残差块(ResBlock)和基本CNN 层组成。跳跃连接有助于保留梯度以训练非常深的网络。在网络设计中使用 3D 而不是 2D 卷积核,主要是因为 3D 卷积可以更好地提取沿通道轴的特征映射 ,在本文的例子中,通道轴是时间方向。这些特性使网络能够关注连续帧之间图像特征的轻微位移,因此可以训练网络利用散斑相关特征来估计相对位置和方向。
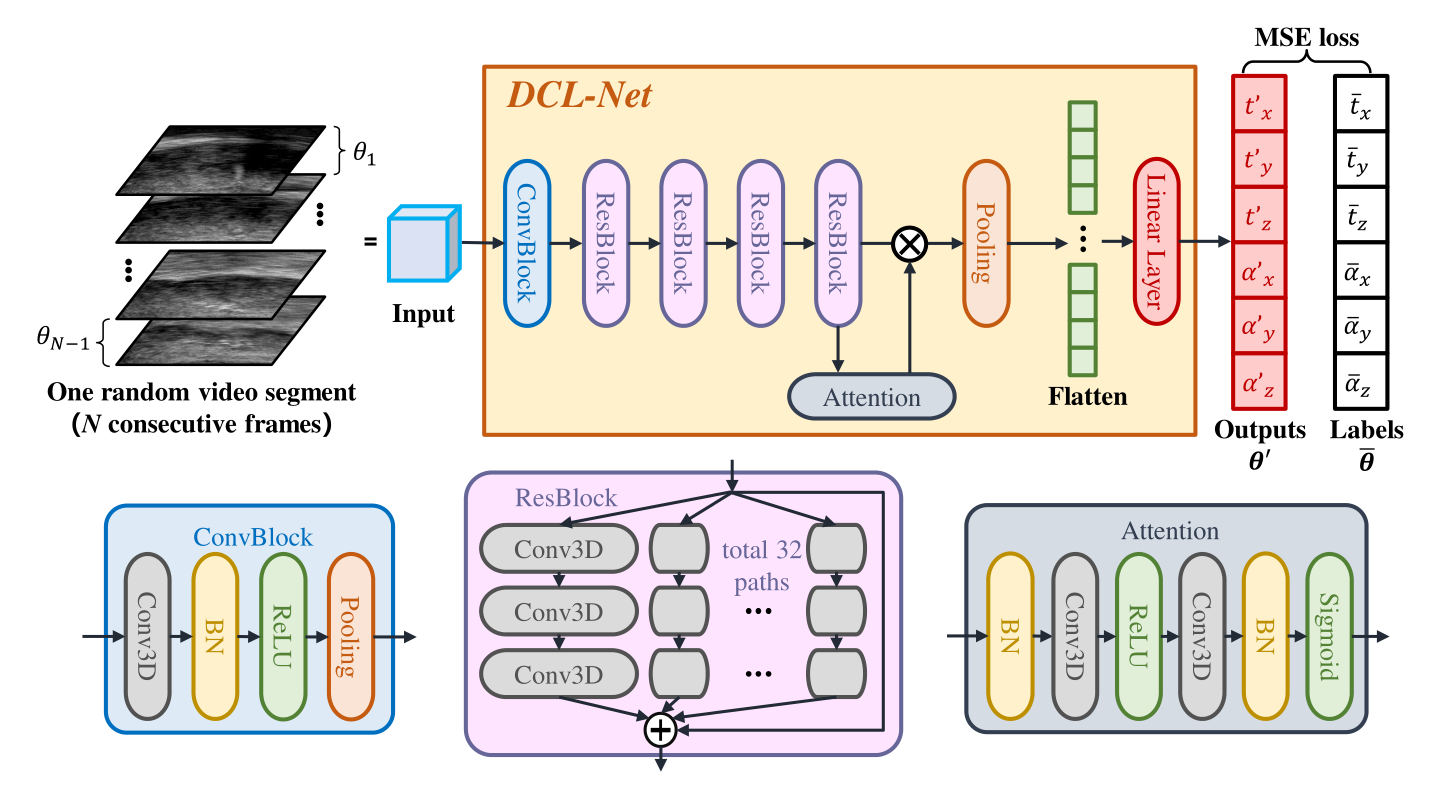
在训练过程中,我们将高度和宽度分别用 H 和 W 表示的 N 帧序列堆叠起来,形成 N×H×W 形状的 3D 输入块。令 表示相邻帧之间的相对变换参数。不是直接使用这些参数作为网络训练的真值,而是使用这些参数的均值:
使用均值的主要原因是,由于两帧之间的运动幅度很小,因此使用平均值可以有效地平滑探头运动中的噪声。在测试期间,我们使用大小为 N 的窗口沿着视频序列滑动。两个相邻帧之间的相对运动是所有批次的平均运动。
3.2.2 注意力模块
深度学习模型中的注意力机制使CNN关注图像的特定区域 ,该区域携带目标任务的显著信息。在本研究中,具有强散斑模式的区域在估计变换时非常重要,因此,我们引入了一个自注意力模块。它将最后一个残差块产生的特征图作为输入,然后输出一个注意力图(attention map)。这有助于为信息量大的区域分配更多权重。
3.2.3 案例相关损失(Case-wise Correlation Loss)
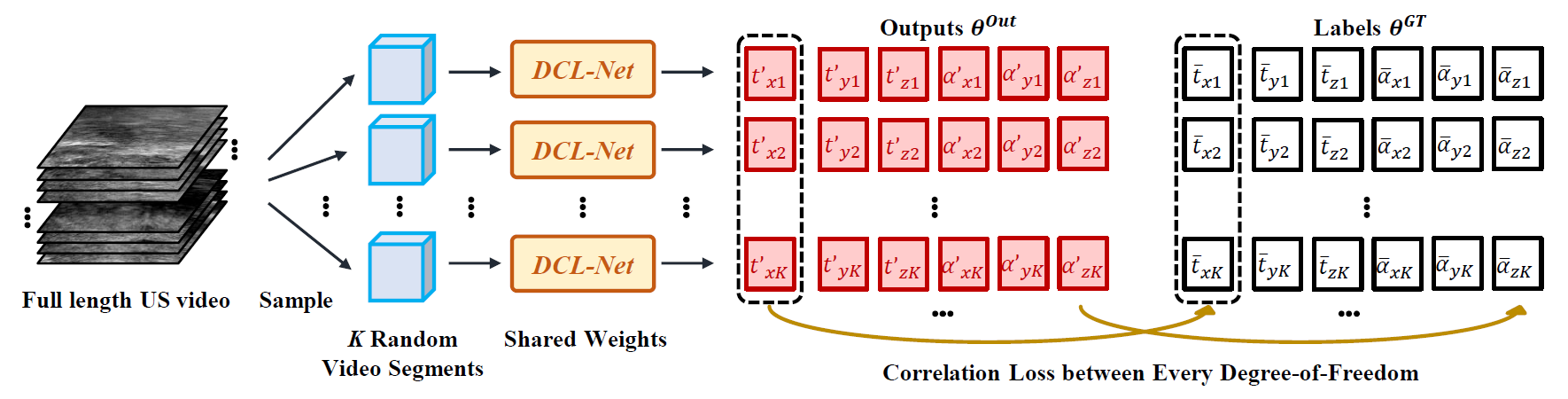
本文提出的DCL-Net的损失函数由两部分组成。第一种是均方误差(MSE)损失,这是回归问题中最常用的损失。然而,仅使用MSE损失会导致对运动的平滑估计 ,训练的网络倾向于记住探头移动的一般风格,即超声探头的平均轨迹。为了解决这一问题,我们引入了基于皮尔逊相关系数 的案例相关损失来强调扫描的特定运动模式。
下图显示了计算案例相关损失的工作流程。从 TRUS 视频中随机采样 K 个视频片段,每个视频片段具有 N 帧。对于每个自由度,计算估计的运动和真实平均值之间的相关系数,损失表示为:
其中 Cov 给出协方差,σ 计算标准差。总损失是均方误差损失和案例相关损失之和。
4. 研究结果
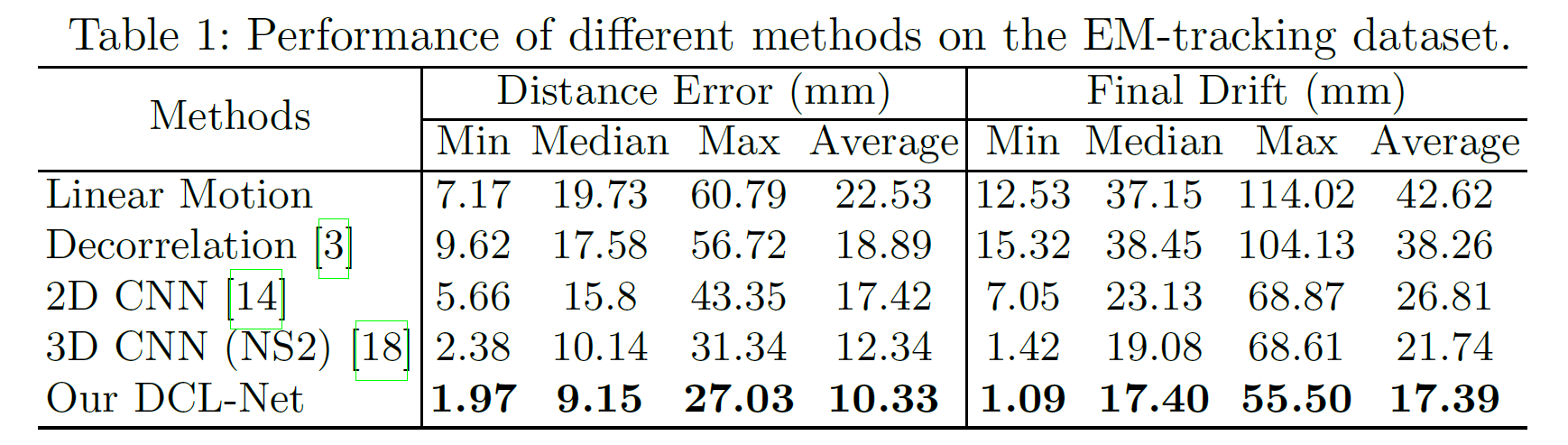
下表总结了本文提出的 DCL-Net 与其他方法的比较。"Linear Motion" 方法首先计算训练集的平均运动向量,然后将这个固定向量应用于所有测试用例。"Decorrelation" 指的是散斑去相关算法[1]。"2D CNN" 指的是 Prevost 等人提出的方法[2]。"3D CNN"指的是ResNext网络[3],将两个切片作为输入。
使用两个评估指标来评价结果。第一个是整个视频中所有对应帧角点之间距离的平均。这个距离误差揭示了整个视频中速度和方向变化的差异。另一个是最终漂移( final drift),这是使用 EM 跟踪数据和 DCL-Net 计算得到的的视频片段最后帧的中心点之间的距离。
The first one is the average distance between all the corresponding frame corner-points throughout a video. This distance error reveals the difference in speed and orientation variations across the entire video.
The other one is the final drift, which is the distance between the center points of the transformed end frames of a video segment using the EM tracking data and our DCL-Net estimated motion.
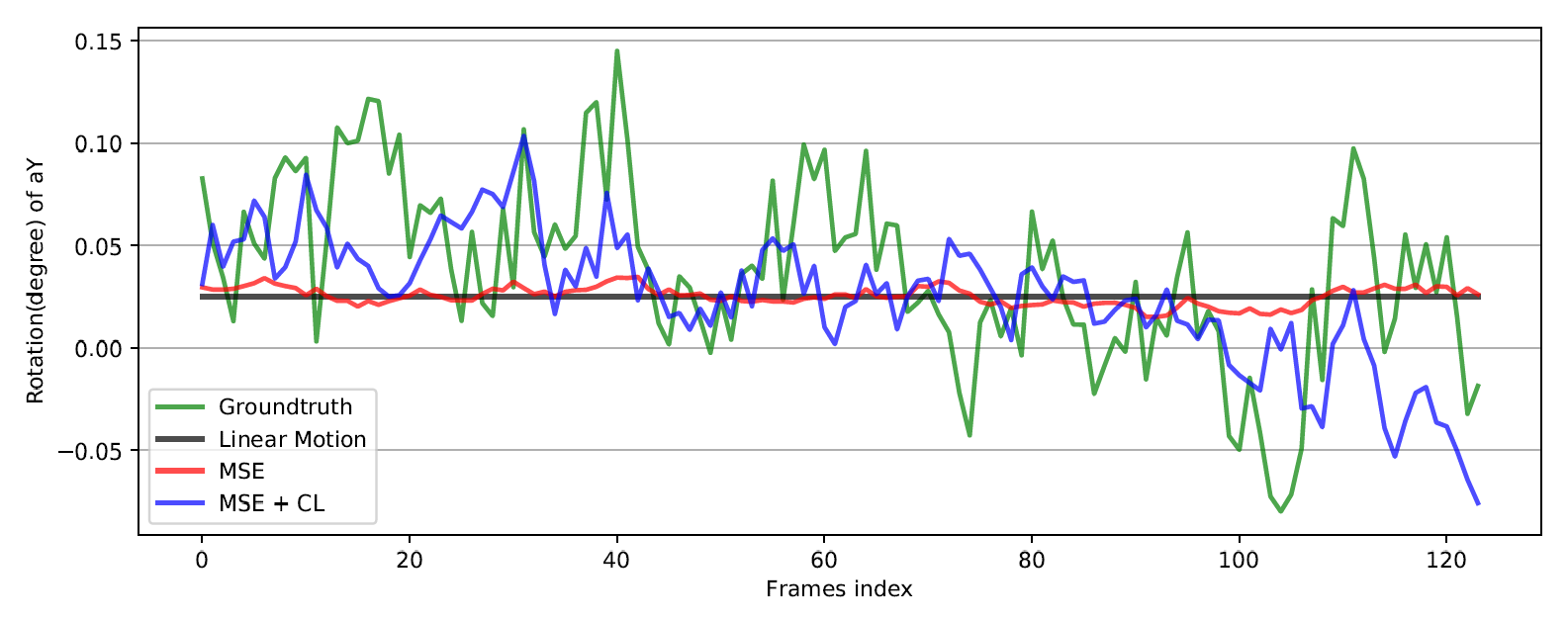
接下来,我们展示了在网络训练中引入案例相关性损失的有效性。下表显示了视频序列 的预测结果。可以观察到,用 MSE 损失训练的网络只能产生几乎恒定的结果(红线),对速度和方向的变化不敏感。所有测试用例的相关系数平均值为 0.09±0.03,相关性较小。这表明单独使用 MSE 会使网络记住探头运动轨迹的一般风格,而不能根据图像内容产生有效的预测。通过将相关性损失计入损失函数(蓝线),所有测试用例的相关系数平均为 0.21±0.09,代表弱相关性。基于 α=0.05的配对 t 检验 ,发现这明显优于先前的结果。也就是说,网络的预测对探头实际平移和旋转(绿线)的变化反应更灵敏。
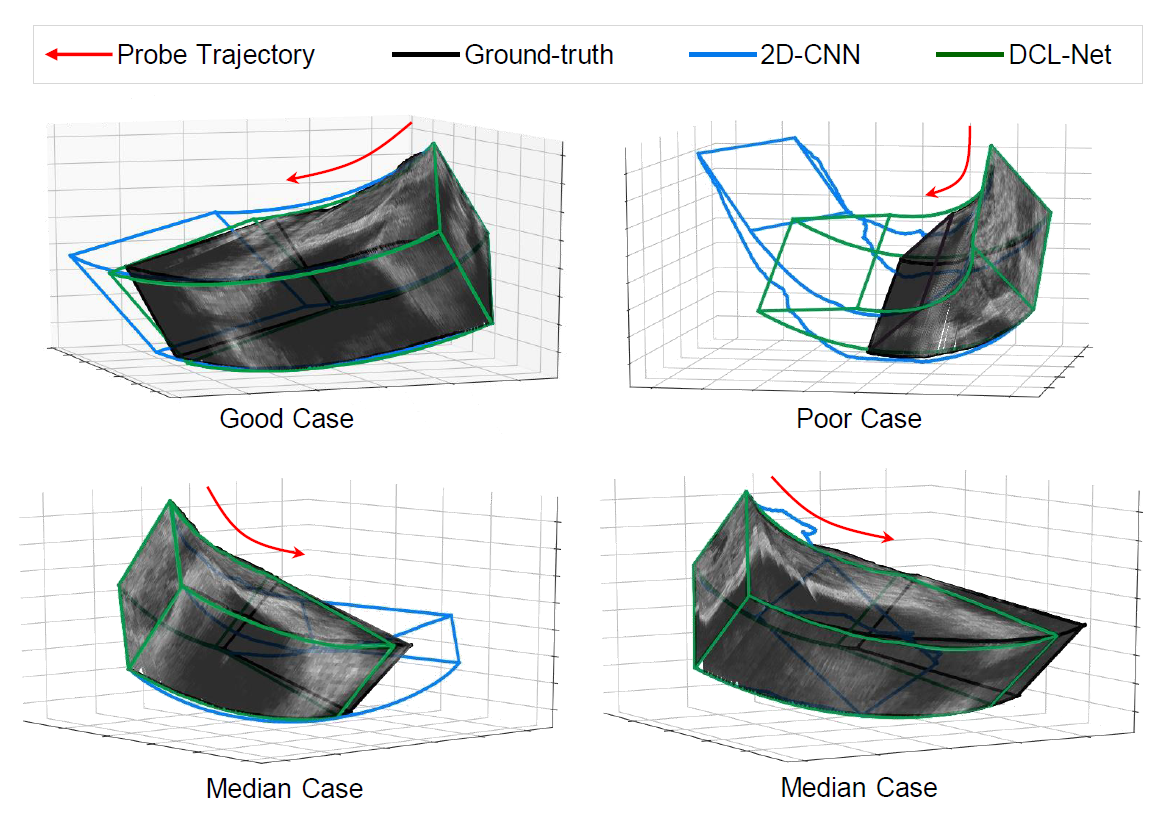
最后,下图展示了四个不同重建质量的测试用例的 3D 重建结果。其中包括一个好的例子,一个坏的例子和两个中等的例子。2D-CNN 方法对超声探头速度变化的敏感度较低,估计的轨迹存在噪声振动,有时结果甚至严重偏离真值。由于视频片段提供的上下文信息,本文提出的 DCL-Net 显示了更平滑的轨迹估计。
[1] Chang, Ruey-Feng, et al. "3-D US frame positioning using speckle decorrelation and image registration." Ultrasound in medicine & biology 29.6 (2003): 801-812.
[2] Prevost, Raphael, et al. "3D freehand ultrasound without external tracking using deep learning." Medical image analysis 48 (2018): 187-202.
[3] Xie, Saining, et al. "Aggregated residual transformations for deep neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. (Code)


















 2510
2510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









