







目录
step2:在地平线OE主目录下,启动docker并挂载OE目录和数据集目录
step3:cityscapes_packer.py文件位置
step1:deeplabv3plus.py 配置文件中的数据集路径( data_rootdir )设置为 数据集 LMDB 文件所在位置
官方文档
地平线x3开发资料,版本2.6.2b
旭日X3派用户手册![]() https://developer.horizon.ai/api/v1/fileData/documents_pi/Quick_Start/Quick_Start.html地平线X3J3算法工具链
https://developer.horizon.ai/api/v1/fileData/documents_pi/Quick_Start/Quick_Start.html地平线X3J3算法工具链![]() https://developer.horizon.cc/api/v1/fileData/horizon_xj3_open_explorer_cn_doc/oe_mapper/source/advanced_content.html
https://developer.horizon.cc/api/v1/fileData/horizon_xj3_open_explorer_cn_doc/oe_mapper/source/advanced_content.html
操作流程
1.数据集打包
step1:在宿主机上,准备两个目录
——地平线OE主目录:
/home1/lixinyiDownloads/horizon_xj3_open_explorer_v2.6.2b-py38_20230606
——cityscapes数据集主目录:
/home1/lixinyi/Downloads/dataset/cityscapes
step2:在地平线OE主目录下,启动docker并挂载OE目录和数据集目录
./run_docker_lxy.sh /home1/liXinYi/Downloads/dataset/cityscapes/,进入Docker环境
注意:这里如果使用从机训练,遇到docker权限不够的情况,先登录主机,在主机内添加设置docker权限:
1.检查docker用户组内成员
grep docker /etc/group2.如果输出结果为空,新建一个docker用户组。如果输出了组内成员等信息则跳过此步。
sudo groupadd docker3.添加用户到docker组中
sudo usermod -aG docker username4.确保更改生效,终端关了重开一个。然后就能正常使用了
step3:cityscapes_packer.py文件位置
在docker环境中,数据集主目录变成了/data/horizon_x3/data。且cityscapes_packer.py经查找发现在/open_explorer/ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/datasets/cityscapes_packer.py
step4:进行训练数据集打包
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/datasets/cityscapes_packer.py --src-data-dir /data/horizon_x3/data --split-name train --pack-type lmdb
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/datasets/cityscapes_packer.py --src-data-dir /data/horizon_x3/data --split-name train --pack-type lmdbstep5:进行验证数据集打包
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/datasets/cityscapes_packer.py --src-data-dir /data/horizon_x3/data --split-name val --pack-type lmdb
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/datasets/cityscapes_packer.py --src-data-dir /data/horizon_x3/data --split-name val --pack-type lmdbstep6:退出docker环境
exit
step7: 获得data.mdb、lock.mdb
退出docker后,在宿主机cityscapes数据集主目录下发现打包好的目录data.mdb、lock.mdb
2.模型训练
step1:deeplabv3plus.py 配置文件中的数据集路径( data_rootdir )设置为 数据集 LMDB 文件所在位置
vi /home1/lixinyi/Downloads/horizon_xj3_open_explorer_v2.6.2b-py38_20230606/ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/configs/segmentation/deeplabv3plus_efficientnetm0.py
vi /home1/lixinyi/Downloads/horizon_xj3_open_explorer_v2.6.2b-py38_20230606/ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/configs/segmentation/deeplabv3plus_efficientnetm0.py将data_rootdir变量改为/data/horizon_x3/data
step2:测试一下网络的计算量和参数数量
root下
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/calops.py --config ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/configs/segmentation/deeplabv3plus_efficientnetm0.py --input-shape "1,3,1024,2048"
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/calops.py --config ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/configs/segmentation/deeplabv3plus_efficientnetm0.py --input-shape "1,3,1024,2048"
step3:启动训练
(注意,这里手册上的原有写法python3 tools/train.py --step float --config configs/segmentation/deeplabv3plus_efficientnetm0.py无法运行,参数写错了,且没指定gpu编号)
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/train.py --stage float --device-ids 0,1 --config ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/configs/segmentation/deeplabv3plus_efficientnetm0.py
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/train.py --stage float --device-ids 0,1 --config ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/configs/segmentation/deeplabv3plus_efficientnetm0.py开始训练模型
日,报错超多,总的来说就是CUDA设备序号错误:
2024-04-02 18:55:11,221 INFO [logger.py:148] Node[0] ==================================================BEGIN FLOAT STAGE==================================================
2024-04-02 18:55:11,280 INFO [logger.py:148] Node[0] init torch_num_thread is `12`,opencv_num_thread is `12`,openblas_num_thread is `12`,mkl_num_thread is `12`,omp_num_thread is `12`,
/usr/local/lib/python3.8/dist-packages/horizon_plugin_pytorch/nn/interpolate.py:236: UserWarning: default upsampling behavior when mode=bilinear is changed to align_corners=False since torch 0.4.0. Please specify align_corners=True if the old behavior is desired.
warnings.warn(
ERROR:__main__:train failed!
-- Process 1 terminated with the following error:
Traceback (most recent call last):
File "/root/.local/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 59, in _wrap
fn(i, *args)
File "/usr/local/lib/python3.8/dist-packages/hat/engine/ddp_trainer.py", line 448, in _main_func
torch.cuda.set_device(local_rank % num_devices)
File "/root/.local/lib/python3.8/site-packages/torch/cuda/__init__.py", line 311, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: CUDA error: invalid device ordinal
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Traceback (most recent call last):
File "./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/train.py", line 287, in <module>
raise e
File "./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/train.py", line 273, in <module>
train(
File "./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/train.py", line 254, in train
launch(
File "/usr/local/lib/python3.8/dist-packages/hat/engine/ddp_trainer.py", line 377, in launch
mp.spawn(
File "/root/.local/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 230, in spawn
return start_processes(fn, args, nprocs, join, daemon, start_method='spawn')
File "/root/.local/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 188, in start_processes
while not context.join():
File "/root/.local/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 150, in join
raise ProcessRaisedException(msg, error_index, failed_process.pid)
torch.multiprocessing.spawn.ProcessRaisedException:
-- Process 1 terminated with the following error:
Traceback (most recent call last):
File "/root/.local/lib/python3.8/site-packages/torch/multiprocessing/spawn.py", line 59, in _wrap
fn(i, *args)
File "/usr/local/lib/python3.8/dist-packages/hat/engine/ddp_trainer.py", line 448, in _main_func
torch.cuda.set_device(local_rank % num_devices)
File "/root/.local/lib/python3.8/site-packages/torch/cuda/__init__.py", line 311, in set_device
torch._C._cuda_setDevice(device)
RuntimeError: CUDA error: invalid device ordinal
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
解决过程:
查看当前系统中的 GPU 设备信息和设备序号
nvidia-smi发现当前GPU一个没开,开一个。开启命令:
nvidia-smi -pm 1现在GPU1就开启了,0为关闭状态,此时是在主机下开启的

进入docker空间内再查看一下,以docker空间内编号为准,因此我的GPU编号是0。其他情况同理,以docker空间内为准。
注:docker空间内GPU编号在进入docker时的.sh文件中进行设置

开始正常训练了。中途打印的信息:
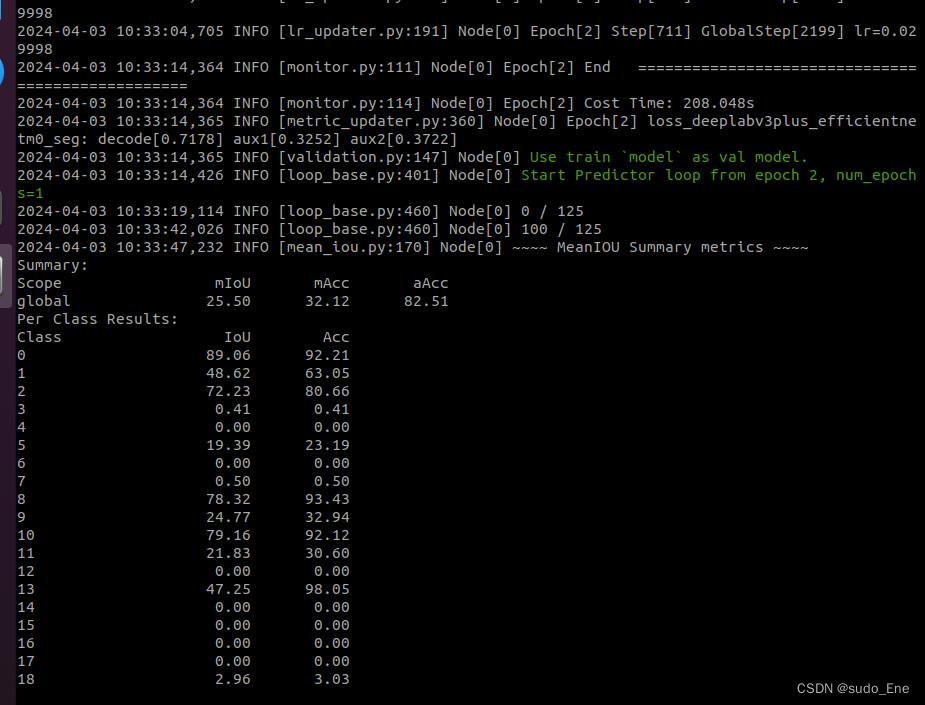
step4:验证模型精度
(注意,手册上的原有写法无法运行,参数写错了,且没指定gpu编号,自己修改参数内容)
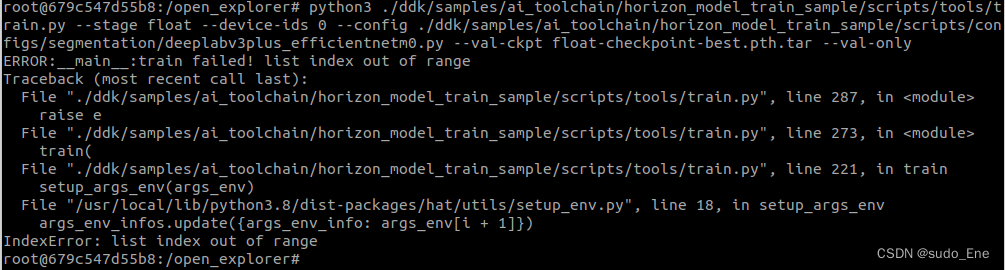
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/train.py --stage float --device-ids 0 --config ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/configs/segmentation/deeplabv3plus_efficientnetm0.py --val-ckpt float-checkpoint-best.pth.tar --val-only
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/train.py --stage float --device-ids 0 --config ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/configs/segmentation/deeplabv3plus_efficientnetm0.py --val-ckpt float-checkpoint-best.pth.tar --val-only无法运行,地平线2.6.2b版本的docker中,train.py文件不支持此参数。我不信,再试试。
行吧,确实不行。
step5:导出onnx模型
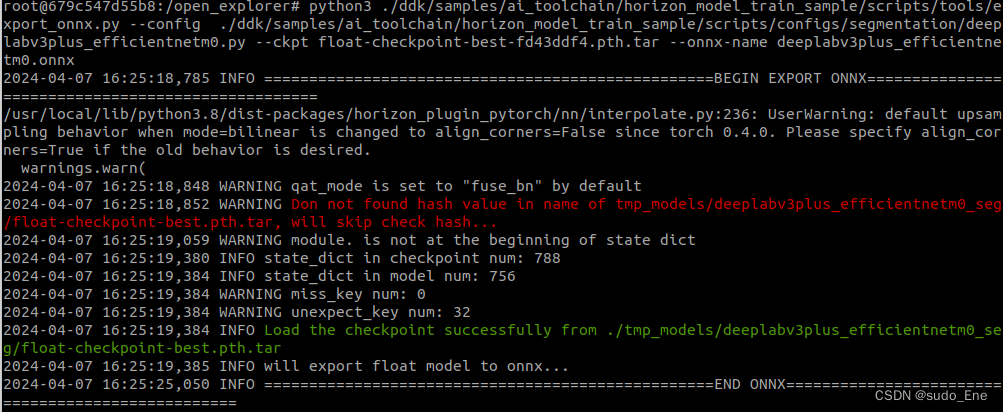
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/export_onnx.py --config ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/configs/segmentation/deeplabv3plus_efficientnetm0.py --ckpt float-checkpoint-best-fd43ddf4.pth.tar --onnx-name deeplabv3plus_efficientnetm0.onnx
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/export_onnx.py --config ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/configs/segmentation/deeplabv3plus_efficientnetm0.py --ckpt float-checkpoint-best-fd43ddf4.pth.tar --onnx-name deeplabv3plus_efficientnetm0.onnx这东西!export_onnx.py脚本只能输出固定的onnx文件名,我不信,我试试。
行吧,真的对不上...没事儿
3.模型单图测试
看训练的模型单图推理效果
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/infer.py --config ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/configs/segmentation/deeplabv3plus_efficientnetm0.py --dataset cityscapes --input-size 1024x2048x3 --input-images /data/horizon_x3/data/leftImg8bit/test/berlin/berlin_000467_000019_leftImg8bit.png --input-format yuv --is-plot
python3 ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/tools/infer.py --config ./ddk/samples/ai_toolchain/horizon_model_train_sample/scripts/configs/segmentation/deeplabv3plus_efficientnetm0.py --dataset cityscapes --input-size 1024x2048x3 --input-images /data/horizon_x3/data/leftImg8bit/test/berlin/berlin_000467_000019_leftImg8bit.png --input-format yuv --is-plot报错说
FileNotFoundError: [Errno 2] No such file or directory: './tmp_models/deeplabv3plus_efficientnetm0_seg/calibration-checkpoint-best.pth.tar'
估计是需要进行量化感知训练QAT的calibration步骤之后得到的伪量化模型才能进行单图推理效果,有待验证。
4.模型转换验证
地平线ai工具链中,py模型转onnx再转bin格式是总体流程。在onnx转bin的过程中,不仅是将onnx转成地平线特有的bin格式,而且还进行了模型量化。量化有两种方式:
1.边训练边量化的“量化训练QAT”
2.训练完成后量化的“训练后量化PTQ”
地平线的文档中说PTQ比较简单,且已经大量应用在多种场景中了,所以推荐PTQ。参考3.2. 算法模型PTQ量化+上板 快速上手 — Horizon Open Explorer
步骤分成两步:
1.对浮点型onnx模型进行验证,以确保其符合计算平台的支持约束
命令举例:hb_mapper checker --model-type onnx \
--model efficientnet_lite0_fp32.onnx \
--march bernoulli2
hb_mapper checker --model-type onnx \
--model efficientnet_lite0_fp32.onnx \
--march bernoulli2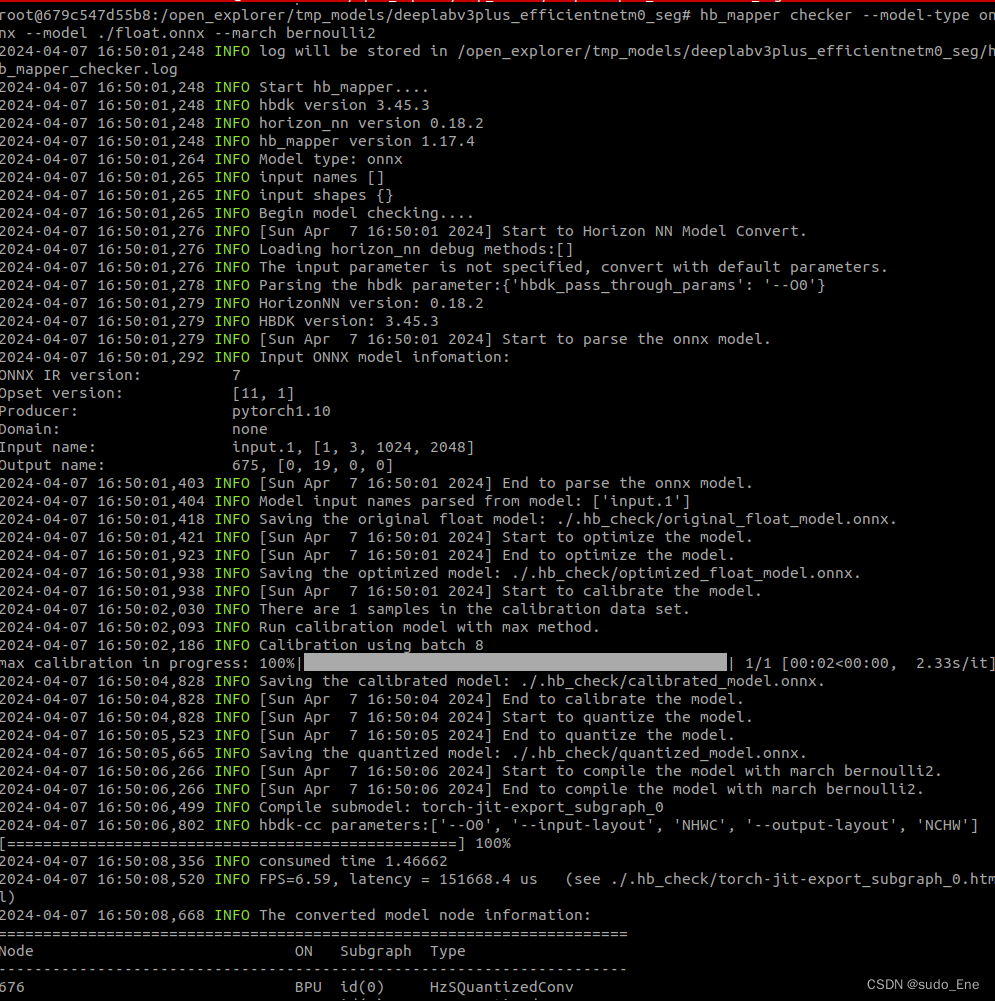

生成内容: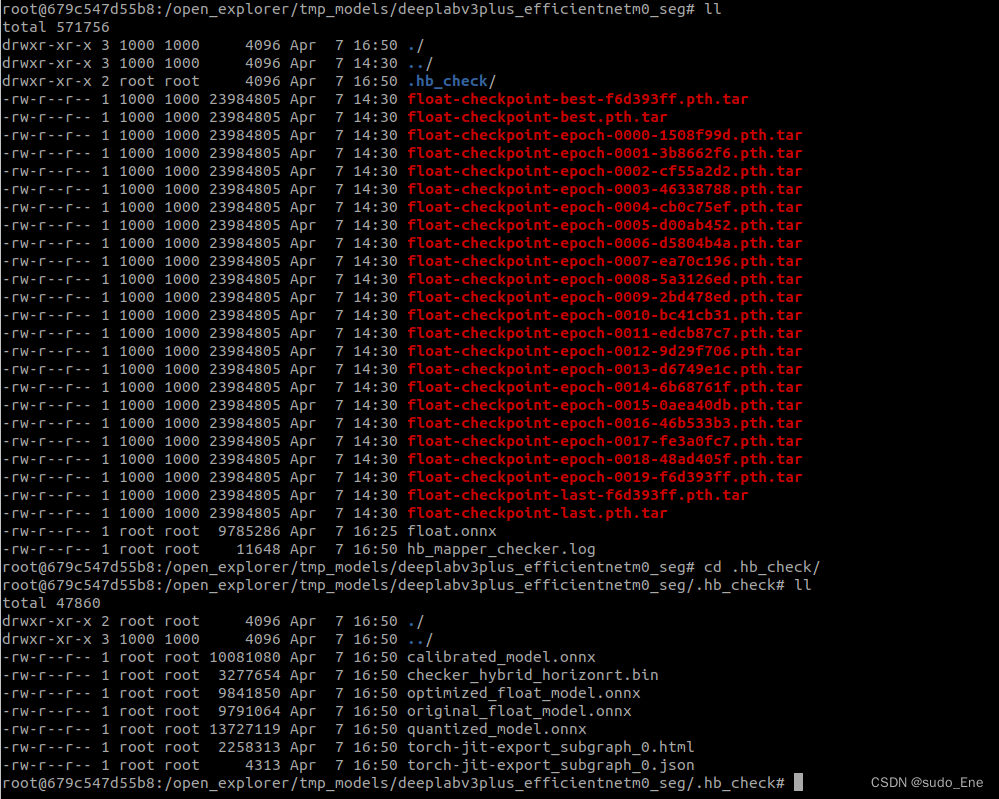
5.模型的转换和量化
模型验证通过后,就可以使用 hb_mapper makertbin 工具进行模型转换,参考命令如下:
hb_mapper makertbin --config mobilenet_config.yaml \
--model-type caffe
hb_mapper makertbin --config mobilenet_config.yaml \
--model-type caffe 其中, mobilenet_config.yaml 为模型转换对应的配置文件,将在 Yaml配置文件 中进行介绍。 model-type 则用于指定检查输入的模型类型,可配置为caffe或者onnx,不同模型类型对应的配置文件参数会稍有不同。 另外,PTQ 方案的模型量化还需要依赖一定数量预处理后的样本进行校准,将在 校准数据预处理 中进行介绍。
准备完校准数据和yaml配置文件后,即可一步命令完成模型解析、图优化、校准、量化、编译的全流程转换。
- 配置yaml文件
- 准备校准数据
- 量化&格式转换
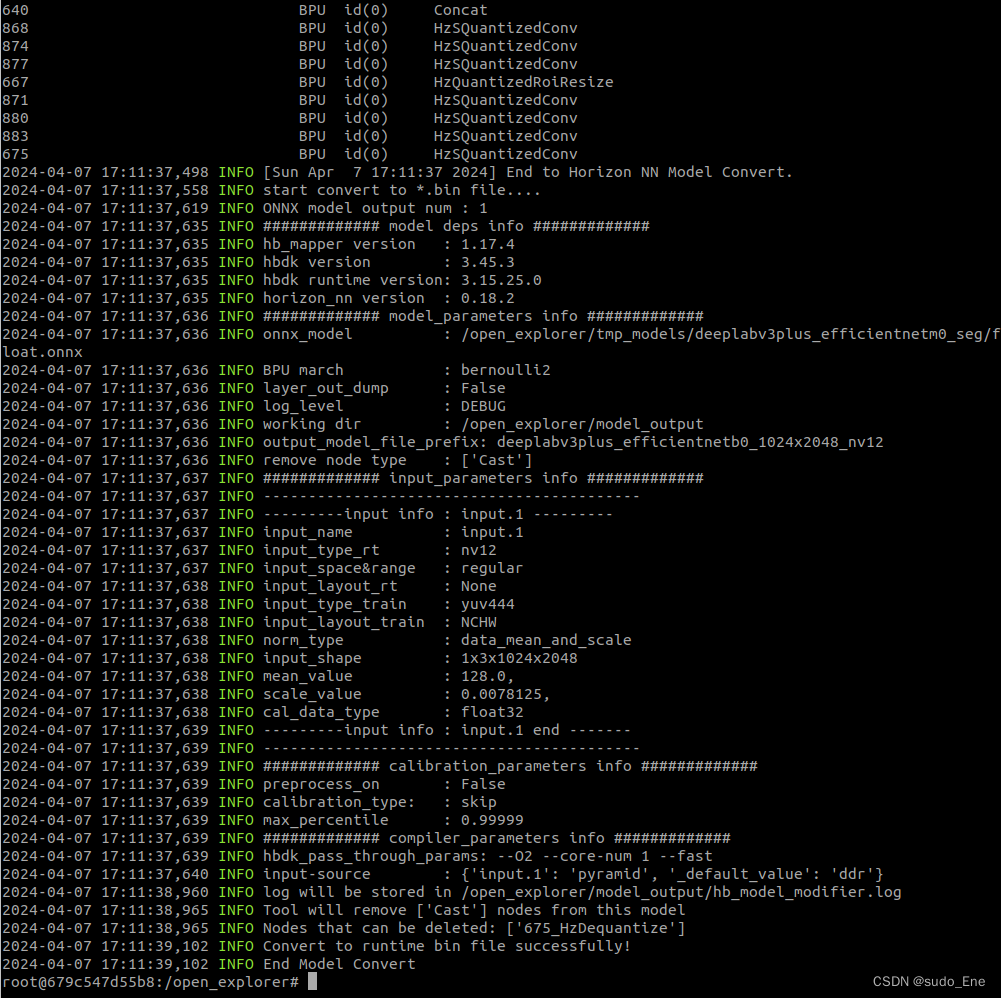
hb_mapper makertbin --config deeplabv3plus_efficientnetb0_config_lxy.yaml --model-type onnx
hb_mapper makertbin --config deeplabv3plus_efficientnetb0_config_lxy.yaml --model-type onnx最后转换得到的量化的bin格式模型
bin文件是用于在地平线计算平台上加载运行的模型
6. 动态性能评估
1.确保完成开发板部署,当前使用地平线旭日x3
2.将转换生成的bin文件拷贝至开发板/userdata 下任意路径
3.通过 hrt_model_exec perf 工具快捷评估模型的耗时和帧率














 1955
1955











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









