







非线性模型
- 常见的非线性模型:
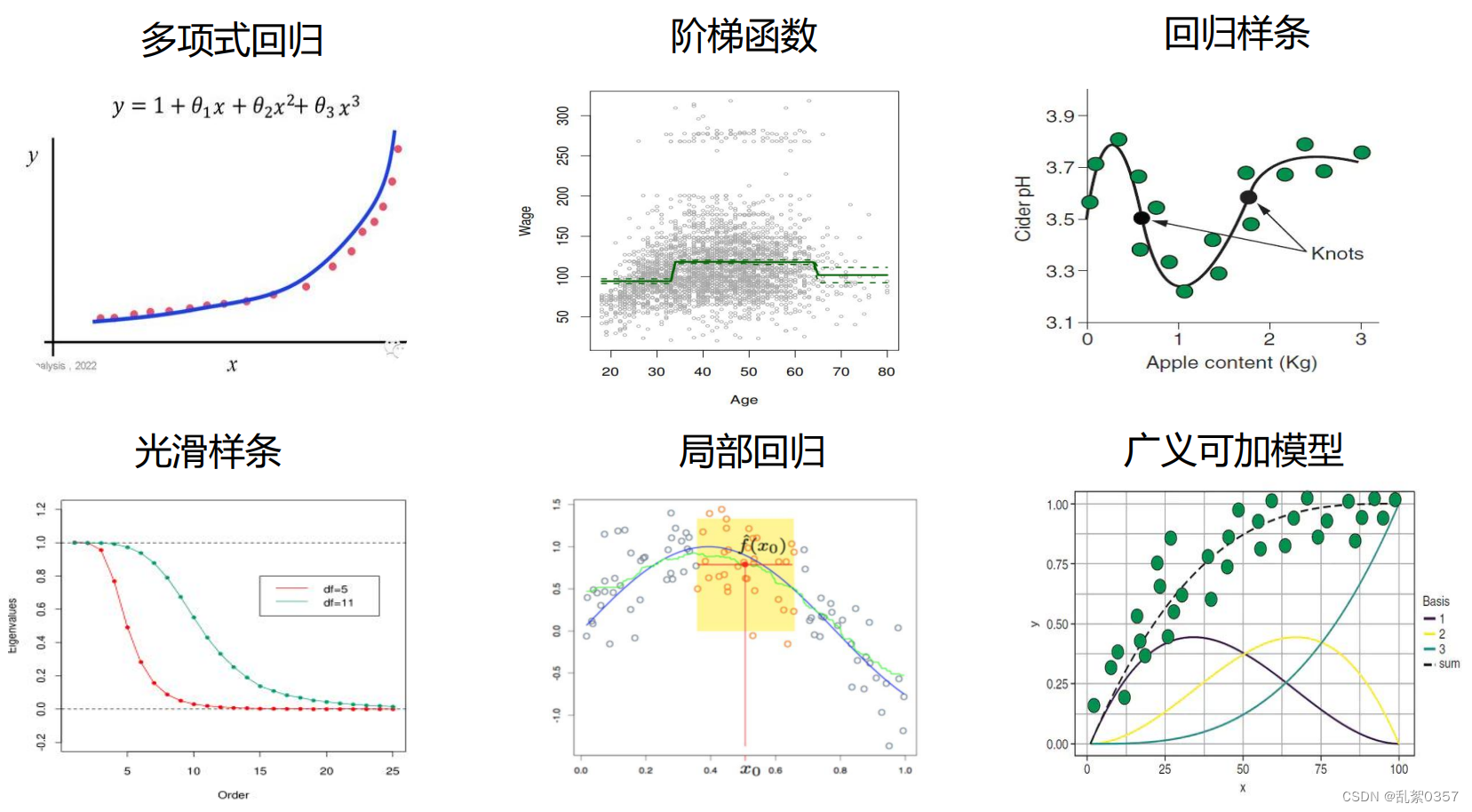
- 多项式回归(polynomial regression):以预测变量的幂作为新的预测变量以替代原始变量。例如,三次回归模型有三个预测变量X,X²,X³
- 标准线性模型:
- 转换成多项式函数:

- 其中d的取值不宜过大,一般不超过3或4,因为d越大,多项式曲线就会越光滑甚至会在变量最定义域的边界处呈现异样的形状
- 阶梯函数(step function):是将某个预测变量的取值空间切割成K个不同区域,以此来生成一个新的定性变量,分段拟合一个常量函数
- 首先在X取值空间上创建分割点c1,c2,···,ck,然后构造K+1个新变量如下:

-
I(·) 是示性函数,当条件成立时返回1否则返回0,而X只能落在K+1个区间中的某一个,于是对任意X的取值
 ,以
,以 为预测变量用最小二乘法来拟合线性模型:
为预测变量用最小二乘法来拟合线性模型:

- 首先在X取值空间上创建分割点c1,c2,···,ck,然后构造K+1个新变量如下:
-
基函数(basis function):是对变量X的函数或变换
 进行建模
进行建模-
可以概括为以下形式:

-
多项式和阶梯函数回归模型实际上是特殊的基函数方法
-
- 回归样条(regression spline):将X的取值范围切割成K个区域,在每个区域分别独立拟合一个多项式函数
- 存在限制以保证在区域边界或称为结点的位置,使这些多项式得到光滑的连接

- k个结点的三次样条:先以三次多项式的基为基础,即x、x2、x3,然后在每个节点添加一个截断幂基:



- 拟合三次样条总共需要K+4个自由度,因为自由度是可以自由变化的量的个数,那么对于有K个联结点的三次样条拟合来说,就有K+1段三次曲线,每段曲线拥有自己的β0、β1、β2、β3四个变量,那共有(K+1)*4个自由度。然而,每个联结点处都有额外的限制,连续、一阶导数、二阶导数连续,每一个限制都决定了“若有三个β随意取值了,第四个β得能确保连续,就不再自由了”,所以三个限制会减少3个自由度,每个联结点都如此,所以得再减去K*3个自由度。最后,K个联结点的三次样条自由度为 (K+1)*4 - K*3 = K+4
- 存在限制以保证在区域边界或称为结点的位置,使这些多项式得到光滑的连接
- 光滑样条(smoothing spline):一般是通过最小化一个带光滑惩罚项的残差平方和的式子来得到光滑样条的结果


- 局部回归(local regression):与样条结果比较相近,最大的差别在于局部回归中的区域之间是可以重叠的,这个条件保证了局部回归整体光滑的拟合结果

- 广义可加模型(generalized additive model,GAM)提供一种对标准线性模型进行推广的框架,框架中每个变量用一个非线性函数替换,同时保持着模型的整体可加性(以上描述的所有模型都属于广义可加模型)
基于树的方法
- 预测值/响应值:预测变量/响应变量的值
- 观测值:要观测的那个x值
- 回归树:预测定量变量
- 建树过程:
- 将预测变量集合划分为J个区域R1~RJ,并最终找到残差平方和RSS最小的区域

- 预测的y值应该是对应区域的训练集中响应值的平均
- 将预测变量集合划分为J个区域R1~RJ,并最终找到残差平方和RSS最小的区域
- 如何划分区域--贪婪方法:递归二叉分裂,即仅对每一步进行最优分裂,而不是全局的最优分裂,使RSS最小
- 建树过程:
- 树的剪枝Pruning:选出测试集预测误差最小的子树,避免过拟合
- 代价复杂性剪枝/最弱联系剪枝(cost complexity pruning/weakest link pruning):
- 仅考虑标记了α的一系列子树,得到一棵子树使得下列式子的值最小:

- 当α增大,终端结点数多的树的上述值会增大,也就是代价更大
- 仅考虑标记了α的一系列子树,得到一棵子树使得下列式子的值最小:
- 代价复杂性剪枝/最弱联系剪枝(cost complexity pruning/weakest link pruning):
- 分类树:预测定性变量
- 预测的y值应该是对应区域的训练集中最常出现的类
- 如何划分区域--递归二叉分裂,衡量指标有:
- 分类错误率(classification error rate):

- 基尼系数(Gini index):衡量结点的纯度(包含的观测值来自同一类别的比例)

- 互熵(cross-entropy):

- 分类错误率(classification error rate):
- 树与线性模型的比较:
| (回归)树 | 线性模型 | |
| 本质 | 对应区域的y的平均值 | 预测变量的线性组合 |
| 当模型有线性关系 | 不能掲示线性结构 | 拟合效果更好 |
| 当模型有强非线性关系 | 拟合效果更好 | 一般 |
- 树的优缺点:
- 解释性强,甚至比线性回归还强
- 更接近人的决策思维模式(同样论证了可解释性)
- 可以用图形表示,尤其是树规模较小时(同样论证了可解释性)
- (分类树)可以直接处理定性的预测变量,无需创建哑变量
- 缺点:预测准确性更差,但可以通过下面介绍的方法来提升效果
- 装袋法/自助法聚集(bootstrap aggregation):
- 与自助法类似,从某个单一的训练集中重复抽样,获得B个自助抽样训练集

- 装袋法对准确性的提升是以牺牲解释性为代价的
- 与自助法类似,从某个单一的训练集中重复抽样,获得B个自助抽样训练集
- 随机森林(random forests):在装袋法的基础上,强迫每个分裂点只考虑预测变量的一个子集
- 提升法:与装袋法类似,但每棵树的构建都需要用到之前生成的树的信息
















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









