







 本文介绍了如何使用Python爬虫获取四川大学在浙江省各专业的最低录取分数和位次数据,然后进行数据清洗、处理,进行可视化分析,并利用SVR预测2023年部分专业录取位次。
本文介绍了如何使用Python爬虫获取四川大学在浙江省各专业的最低录取分数和位次数据,然后进行数据清洗、处理,进行可视化分析,并利用SVR预测2023年部分专业录取位次。
爬取四川大学在浙江省其各专业2017-2022年的最低录取分数和最低录取位次,并对其进行可视化分析。并任意选择该高校的10个专业,根据过去几年信息预测2023年该校该专业考生录取位次。
数据源:https://www.gaokao.cn/school/search
(1)爬虫代码:
import csv
import json
import requests
import os
class crawler:
def __init__(self):
pass
def save_data(self, data):
with open('./高考志愿.csv', encoding='UTF-8', mode='a+', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(data)
f.close()
def get_data(self):
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.58'
}
# 添加表头
head = ['省份', '年份', '学校名称', '专业', '最低录取分', '最低录取名次', '选课要求']
# 清除已存在的同名文件
v_file = '高考志愿.csv'
if os.path.exists(v_file):
os.remove(v_file)
print('高考志愿存在,已清除:{}'.format(v_file))
with open('./高考志愿.csv', encoding='utf-8-sig', mode='w', newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(head)
f.close()
s1 = 'https://static-data.gaokao.cn/www/2.0/schoolspecialindex/'
s2 = '/33/3/16/' # 表示浙江省
for m in range(2017, 2023, 1):
for k in range(1, 7):
try: # 99是四川大学的编号
urll = s1 + str(m) + '/' + str(99) + s2 + str(k) + '.json'
print(urll)
htmll = requests.get(urll, headers=header).text
unicode = json.loads(htmll)
try:
da = unicode["data"]
except:
break
da = da["item"]
for w in da:
sc = w["min"] # 最低录取分
min_section = w["min_section"] # 最低录取名次
spname = w["spname"] # 专业名称
sp_info = w["sp_info"] # 选课要求
tap = ('四川', m, '四川大学', spname, sc, min_section, sp_info)
self.save_data(tap)
except:
pass# 爬取效果展示(仅部分)
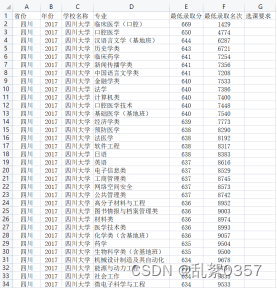
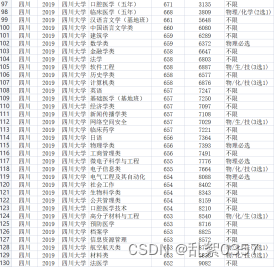
(2)数据清洗和处理:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import font_manager
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler, MinMaxScaler # 标准化和归一化
from sklearn.model_selection import GridSearchCV
my_font = font_manager.FontProperties(fname="C:/WINDOWS/Fonts/msyh.ttc")
plt.rcParams['font.sans-serif'] = ['SimHei']
# 该函数将把近六年都招生的专业和相应分数线与录取位次筛选出来,共21个专业
class analyse:
def __init__(self, conf: dict):
pd.set_option('display.max_rows', None)
self.conf = conf
self.data = None
self.data = pd.read_csv('高考志愿.csv', encoding='UTF-8')
self.subj_name = []
self.axis_scores = [] # 每年的分数线
self.axis_ranks = [] # 每年的最低录取位次
self.axis_year = np.arange(2017, 2023)
# 文理两组的索引和简称
self.subj_index1 = []
self.subj_index2 = []
self.subj_alias1 = []
self.subj_alias2 = []
def process(self):
# step1:删除无用信息
self.data = self.data.drop('省份', axis=1)
self.data = self.data.drop('学校名称', axis=1)
self.data = self.data.drop('选课要求', axis=1)
# print(self.data)
# step2:获得所有招生的专业
grouped = self.data.groupby('年份') # 根据年份分组
yr_of_subj = grouped.get_group(2017)['专业']
for y in range(2018, 2023):
tmp = grouped.get_group(y)['专业']
tmp.reset_index(drop=True, inplace=True)
yr_of_subj = pd.concat([yr_of_subj, tmp], axis=1)
yr_of_subj.index = range(1, self.conf['max_subj'] + 1) # 修改行列名
yr_of_subj.columns = range(2017, 2023)
print('每年招生的专业:')
print(yr_of_subj)
# step3:提取出每年都招收的专业
self.subj_name = list(set(yr_of_subj[yr_of_subj.columns[0]]).intersection(
*[set(yr_of_subj[col]) for col in yr_of_subj.columns]))
self.subj_name.sort()
print('筛选得到专业:', self.subj_name)
# step4:得到这些专业的分数线和最低录取位次
score = {}
rank = {}
for (_, subj) in enumerate(self.subj_name):
score[subj] = [self.data.iloc[index, 2] for index in range(self.conf['total_subj'])
if self.data.iloc[index, 1] == subj]
rank[subj] = [self.data.iloc[index, 3] for index in range(self.conf['total_subj'])
if self.data.iloc[index, 1] == subj]
print('专业分数线:', score)
print('专业录取位次', rank)
self.axis_scores = np.array(list(score.values()))
self.axis_ranks = np.array(list(rank.values()))(3)可视化分析:
def visulize(self):
# step1:可视化专业分数线和名词的统计属性,如均值,标准差,最低和最高录取线,得到统计图
grouped = self.data.groupby('年份') # 根据年份分组
print('录取分数线:\n', grouped['最低录取分'].describe())
print('录取位次:\n', grouped['最低录取名次'].describe())
# step2:将专业分成文理两组
self.subj_index1 = np.array([2, 3, 5, 6, 9, 11, 14, 16, 17, 18, 20])
self.subj_index2 = np.array([0, 1, 4, 7, 8, 10, 12, 13, 15, 19])
self.subj_alias1 = np.array(
['卫生检验', '口腔医学', '工程力学', '微电', '法医学', '电信', '网安', '药学', '计算机', '软工',
'高分子材料'])
self.subj_alias2 = np.array(
['中文', '公共管理', '工商管理', '新传', '日语', '法学', '社会工作', '经济学', '英语', '金融'])
# step3:可视化专业录取位次随年份的变化情况
fig = plt.figure(figsize=(13, 6))
ax1 = fig.add_subplot(221, projection='3d')
ax2 = fig.add_subplot(222, projection='3d')
ax3 = fig.add_subplot(223, projection='3d')
ax4 = fig.add_subplot(224, projection='3d')
# 分别对两组分数线和最低录取位次进行分析
for subNo in range(11):
ax1.plot(self.axis_year, self.axis_scores[self.subj_index1[subNo]], zs=subNo, zdir='y')
ax2.plot(self.axis_year, self.axis_ranks[self.subj_index1[subNo]], zs=subNo, zdir='y')
for subNo in range(10):
ax3.plot(self.axis_year, self.axis_scores[self.subj_index2[subNo]], zs=subNo, zdir='y')
ax4.plot(self.axis_year, self.axis_ranks[self.subj_index2[subNo]], zs=subNo, zdir='y')
# 聚合4个子图
axes = np.array([ax1, ax2, ax3, ax4])
for i in range(4):
# 设置x坐标轴
axes[i].set_xticks(self.axis_year)
axes[i].set_xticklabels(self.axis_year, fontproperties=my_font, fontsize=7)
axes[i].set_xlabel('年份', fontproperties=my_font, fontsize=7)
# 设置y坐标轴
if i == 0 or i == 1:
axes[i].set_yticks(range(11))
axes[i].set_yticklabels(self.subj_alias1, fontproperties=my_font, fontsize=5)
axes[i].set_ylabel('专业(理工类)', fontproperties=my_font, fontsize=7)
else:
axes[i].set_yticks(range(10))
axes[i].set_yticklabels(self.subj_alias2, fontproperties=my_font, fontsize=5)
axes[i].set_ylabel('专业(文管类)', fontproperties=my_font, fontsize=7)
# 设置z坐标轴
if i == 0 or i == 2:
axes[i].set_zticks(range(620, 661, 5))
axes[i].set_zticklabels(range(620, 661, 5), fontproperties=my_font, fontsize=7)
axes[i].set_zlabel('录取分数线', fontproperties=my_font, fontsize=7)
else:
axes[i].set_zticks(range(4000, 12001, 1000))
axes[i].set_zticklabels(range(4000, 12001, 1000), fontproperties=my_font, fontsize=7)
axes[i].set_zlabel('最低录取位次', fontproperties=my_font, fontsize=7)
axes[i].invert_zaxis()
plt.show()得到三维折线图
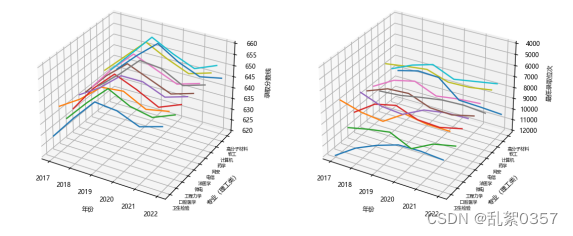
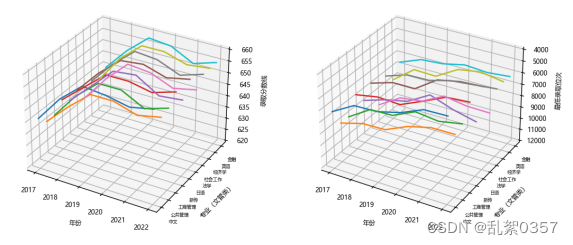
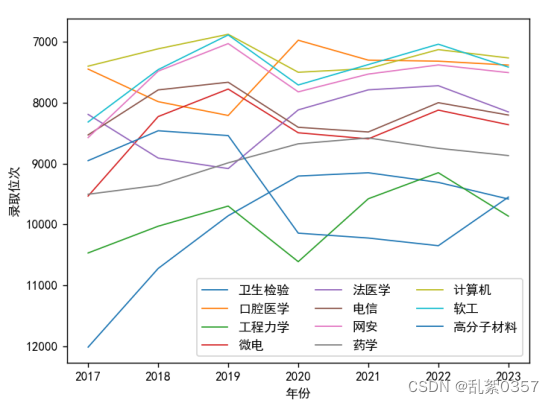
# 从排名的角度不难看出川大近年来的录取位次呈逐年上升的趋势,且近年来浙江考生也在逐年增多,由此可以看出上一个好大学变得越来越难
(4)采用SVR对理科组专业进行回归分析
# SVR适合处理小样本问题,有较好的泛化能力
def predict(self): # 采用支持向量回归对2023年这十个专业的录取位次进行预测
years = np.array([2017, 2018, 2019, 2020, 2021, 2022], dtype=np.float32)
f = open('指标.xlsx', 'r')
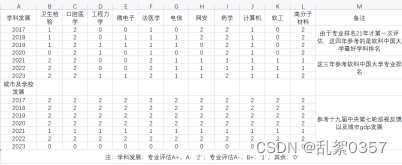
inds = pd.read_excel('指标.xlsx') # 该表格旨在提供非分数因素对于报考的影响
f.close()
ind_1 = inds[0:7]
ind_2 = inds[8:15]
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
x = np.append(years, 2023)
dic_ranks = {}
for i in range(11):
ranks = np.array(self.axis_ranks[self.subj_index1[i]], dtype=np.float32)
ind_1s = np.array(ind_1.iloc[0:6, i+1], dtype=np.float32)
ind_2s = np.array(ind_2.iloc[0:6, i+1], dtype=np.float32)
# 创建输入数据和标签
input_data = np.column_stack((years, ind_1s, ind_2s))
labels = ranks
# 标准化及归一化处理
input_data = StandardScaler().fit_transform(input_data)
input_data = MinMaxScaler().fit_transform(input_data)
# print(input_data)
# 创建支持向量回归模型实例
svr_model = SVR(kernel='rbf')
# 定义超参数网格
param_grid = {
'C': [0.1, 1, 10],
'gamma': [0.1, 0.01, 0.001]
}
grid_search = GridSearchCV(svr_model, param_grid, cv=3) # k折交叉验证
grid_search.fit(input_data, labels)
best_params = grid_search.best_params_
svr_model = SVR(kernel='rbf', C=best_params['C'], gamma=best_params['gamma'])
svr_model.fit(input_data, labels)
test_data = np.array([[2023, ind_1.iloc[6, i+1], ind_2.iloc[6, i+1]]],
dtype=np.float32)
predicted_ranks = svr_model.predict(test_data)
dic_ranks[self.subj_alias1[i]] = round(predicted_ranks[0]) # 四舍五入录取位次
# 可视化结果
y = np.append(ranks, predicted_ranks)
ax.plot(x, y, linewidth=1.0, label=self.subj_alias1[i])
ax.invert_yaxis()
ax.legend(loc='best', ncol=3)
plt.xlabel('年份')
plt.ylabel('录取位次')
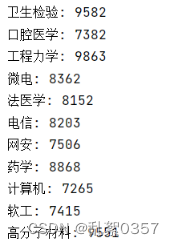
for i in range(11):
print(self.subj_alias1[i] +': '+ str(dic_ranks[self.subj_alias1[i]]))
plt.show()# 此表格则为 '指标.xlsx'
得到含预测点的二维折线图
预测结果:

















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









