







什么是统计学习
- 统计学习:是关于估计f的一系列方法,用来面向预测的统计模型建立,或者对一个或多个给定的输入估计某个输出
- 输入变量/预测变量/自变量/属性变量:X
- 输出变量/响应变量/因变量:Y
- 随机误差项:ε=Y-f(X),E(ε)=0
- 预测值/拟合值Ŷ=ŷ=f̂(X),其中f̂为f的预测,又叫做黑箱,只要能提供准确的Y,我们就无需知道f̂的确切形式
- 可约误差:当所选的f̂不是f的一个最佳估计时,模型估计的不准确性会引起的一些误差。模型假设产生的这类误差又叫做模型偏差
- 不可约误差:由于Y是一个关于ε的函数,即使得到f的精准估计,预测仍然存在一个不可测的变差,即ε
- 推断:研究X和Y的关系而不是去预测Y,即Y是怎样随着X的变化而变化的,故需要知道f的具体形式,f不能当作黑箱看待
- 观测点/训练数据:用来训练或引导的已观测到的样本点
- 参数方法:基于模型估计的方法把估计f简化到估计一组参数
- 非参数方法:不限定f 的具体形式,而是追求接近数据点的估计
- 指导学习:对于每一个预测变量观测值x都有响应的响应变量的观测y,通过建立X与Y的关系精准预测Y或理解X与Y的关系
- 无指导学习:只有预测变量x,没有对应的响应变量用于预测
- 定量变量:呈现数值性,如年龄、身高、收入
- 定性变量/分类变量:为k个类的其中一个值,如性别、品牌、是否违约。定量和定性变量在不同情景下可以相互转化
- 定性预测变量,又称为因子
评价模型精度
- 均方误差MSE(mean squared error):对预测的响应值和真实的响应值之间的接近程度的评价准则

公式和书上形式有一点不同,但结果都是预测的响应值和真实响应值的差
根据使用的数据集的不同,分为训练均方误差(用训练数据算出来的)和测试均方误差(用之前没有参与建模的新的观测点算出来的)
选择的模型应该力图使测试均方误差最小
- 自由度/光滑度/柔性:描述曲线光滑程度的量,限定性强且曲线平坦的模型比锯齿形有更小的自由度,一般来说,模型越复杂,光滑度越高
- 数据被过拟合:模型训练均方误差较小,但测试均方误差很大,暗示了降低模型的光滑度,可以减小测试均方误差
- 方差-偏差权衡:如果一个模型被称为测试性能好,那么要求模型有较小的方差和偏差。方差代表用一个不同的训练数据集估计f时,估计函数的改变量,如果一个模型有较大的方差,则训练数据集的微小改变则会导致f̂的较大改变,光滑度越高,方差也越高;偏差是为了选择一个简单的模型逼近真实函数而被带入的误差,光滑度越高,偏差越小
- 训练错误率:衡量估计f̂精度的方法,对训练数据使用估计模型f̂所造成的误差比例


I称为示性变量
- 回归分析问题:响应变量为定量的问题
- 分类问题:具有定性的响应变量
- 贝叶斯分类器:将每个观测值分配到它最大可能所在的类别中,将这个类作为他的预测值,通过给定X后Y的条件分布来分类
- 贝叶斯决策边界:这条线把数据集分成了不同类
- K最近邻分类器:通过与之最近的K个邻居来确定类别
K增加,光滑性减弱,更接近线性
1/K增加,方法的柔性增强
简单线性回归
- Y对X的回归:Y≈β0+β1x,通过计算ŷ=β0^+β1x来预测因变量,其中β0、β1称为模型的系数/参数
- 残差平方和RSS(residual sum of squares)最小化:测量模型与观测点接近程度的准则
 进而通过最小二乘选择β0 β1来使RSS达到最小
进而通过最小二乘选择β0 β1来使RSS达到最小

- 标准偏差/标准差SD(standard deviation):描述样本点的离散程度总体和样本都可以计算标准差
- 标准误差SE(standard error):原本描述样本统计量对总体的偏离程度,即样本对于总体的准确度。在这里则是反映了估计值偏离实际值的平均量,例如,估计均值μ^的标准误差


(其中σ是估计值yi的标准差)
标准误差用于计算置信区间


标准误差用于假设检验
- 残差标准误RSE(residual standard error):对σ2的估计(σ2是εi的方差,E(RSE)=σ2),是响应值偏离真正的回归线的平均量,用来量化模型拟合数据的程度

- t统计量:测量了β1^偏离0的标准偏差

- R2统计量:是数据中可被解释方差的比例,值在0到1之间

R2统计量接近于1说明回归可以解释响应变量大部分变异
接近0说明回归没有解释太多响应变量的变异,可能原因有:
- 模型错误
- 固有误差项σ2较大
多元线性回归
- Y对X的回归:
 ,其中自由度为p(有p个参数)
,其中自由度为p(有p个参数) - 流程:确定是否存在多元线性关系->选定重要变量->模型拟合->预测
- F统计量:用于假设检验,确定Y和X之间是否有关系
 ,其中RSS/(n-p-1)为多元线性模型中的残差标准误RSE
,其中RSS/(n-p-1)为多元线性模型中的残差标准误RSE
- 若F统计量接近1,则Y与X无关;若F统计量远大于1,则说明至少有一个X与Y有关
- 因子:定性预测变量
- 哑变量:一种用来表示分类变量的方法,比如某个因子只有两个水平/取值,则这个二值变量可以被量化为1和0
- 可加性假设:预测变量Xj的变化对响应变量Y产生的影响与其他预测变量取值无关
- 线性假设:无论Xj取何值,X变化一个单位引起的响应变量Y的变化恒定
- 协同效应/交互作用:多个因素能协同影响,去除了可加性假设在模型上表示为含有X1*X2这个交互项
- 实验分层原则:如果模型中含有交互项X1X2,即使X1、X2的p值很大(效应不显著),也应该包含在模型中
- 多项式回归:加入了预测变量的多项式函数,含有平方项、立方项等多次项变量,不仅仅是一次项
- 残差图:残差ei与预测变量xi(简单线性)或者与拟合值ŷ(多元线性)的散点图。
- 若存在明显规律,则表示线性模型的某些方面可能有问题

- 若残差图呈现漏斗形,则可能存在异方差性,解决方案是用凹函数对y做变换,如logY、√Y
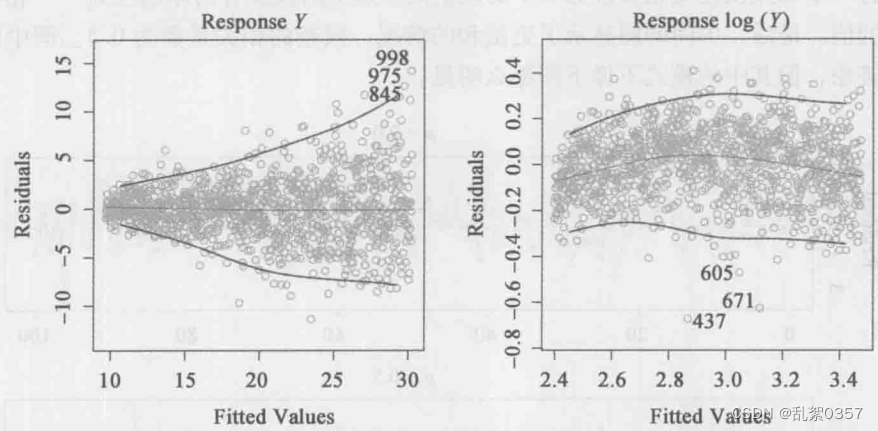
- 若残差图出现离群点(响应值yi远离模型预测值的点),很可能是数据记录错误,确定离群点的方法是是绘制学生化残差(t分布那玩意),由残差除以它的估计标准误,若绝对值>3,则说明可能有离群点

- 若残差图出现高杠杆点(观测点xi远离别的大部分x的异常点),则该点往往会对回归直线的估计由很大的影响,所以找出高杠杆点很重要

- 误差项自相关:如果误差项之间有相关性,那么95%置信区间内包含真实参数的概率会更低,p值也更低。这种相关性往往出现在时间序列数据,即在相邻的时间点观测到的数据
- 共线性:两个或更多的预测变量高度相关
- 假设检验的效力power:正确检测非零系数的概率,共线性会导致效力下降
- 方差膨胀因子VIF:一般来说VIF>5则有共线性问题

- 解决方案:
- 剔除问题变量
- 共线变量组合成单一变量
- 线性回归:将f(x)假设为线性函数,所需估计系数少,易拟合,易检验,但存在假设过强与实际相差太远的风险
- K最近邻回归:给定K值和预测点x0,首先确定K个最接近x0的训练观测,记为
 。然后用
。然后用 中所有训练数据的平均值来估计f(x0)
中所有训练数据的平均值来估计f(x0)
- 线性回归与K最近邻法的比较:
- 线性回归属于参数方法,KNN回归属于非参数方法
- 若真正关系为线性,则选择参数方法
- 若真正关系为非线性,KNN可能优于线性回归,但预测效果会随位数增加而恶化
- 对待回归问题的一般思路:
(1).确定研究对象,设研究对象为A、B、C.......
(2).A与B是否有关?(方法:设置零假设,分析F统计量及其p值)
(3).A与B之间的关系有多强? (方法:1.分析RSE 2.分析R²)
(4).是B对A的影响强还是C对A的影响强?
(方法:1.检查每个统计量的p值 2.检查组合项(B×C)的p值)
(5).如何精确估计B、C等统计量的影响?(方法:求置信区间)
(6).A与B之间的关系是否线性? (方法:分析残差图)
(7).B、C之间是否存在协同效应? (方法:加入交互项看p值与R²的变化程度)
















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









