










Wang D, Zhang M, Xu Y, et al. Metric-based meta-learning model for few-shot fault diagnosis under multiple limited data conditions[J]. Mechanical Systems and Signal Processing, 2021, 155: 107510
论文链接:Metric-based-meta-learning-model-for-few-shot-faul_2021_Mechanical-Systems-a.pdf
摘要:随着信息和传感器技术的发展,现实世界的大型工业数据变得逐渐丰富,基于数据驱动的故障诊断技术得到了蓬勃的发展和应用。这些先进的方法依赖于每种故障类型有足够的标记样本可用。然而,在一些实际情况下,收集足够的数据是极其困难的,例如,当突然发生灾难性故障,在系统关闭之前只能获得少量的样本。这种现象导致了要在非常有限的数据条件下准确区分故障属性的少量故障诊断。在本文中,我们提出了一种新的方法,称为基于特征空间度量的元学习模型(FSM3),将监督学习和情节度量元学习相结合,利用单个样本的属性信息和来自样本组的相似性信息以克服在多种有限数据条件下的故障诊断。实验结果表明,在各种少样本条件下,我们的方法在轴承和齿轮箱故障诊断的1样本和5样本学习任务上优于一系列基准方法。通过实验结果表明,该方法具有较高的可行性。
方法:基于这些分析,我们提出了一种新的基于特征空间度量的元学习模型(FSM3 ),依靠学习源域可用的转移知识克服目标域小样本学习问题,可用于多种有限数据条件下的故障诊断。
方法基于两个流行基于度量的元学习模型,即匹配网络(MN)和原型网络(PN),然而,仅仅基于度量的训练会使模型只关注来自样本组的相对相似性信息,因此每个特定类别的属性信息被忽略,这意味着所提供的标记源数据没有被充分利用。
怎么解决所提供的标记源数据没有被充分利用?
为了解决这个问题,我们设计了一种混合方法,结合了一般监督学习和度量元学习的优点。具体来说,模型的前几层被训练成以全局监督的方式识别源数据的故障类型。然后将这些层固定为特征提取器,将原始数据转换到基本特征空间。最后,用提取的特征通过度量元学习来训练模型的其余部分。这样,我们的模型不仅可以利用数据对之间的相对信息,还可以利用来自单个样本的监督信息。首次尝试利用基于深度神经网络的度量元学习来解决故障诊断中的少样本学习问题。
本文的贡献在于:
1.针对各种有限数据条件下的少样本故障诊断问题,提出了一种新的FSM3模型。通过创造性地组合来自样本组的相对相似性信息和来自带注释的源数据的每个特定类别中的监督信息。设计了一种混合训练策略来支持这种组合,该混合训练策略在学习的特征空间中具有全局监督训练和情节训练。
2.为了利用基于度量的元学习解决有限数据条件下的少样本故障诊断问题,讨论和分析了基于度量的元学习的可解释性和可行性。
3.通过在不同故障类型、速度和负载条件下的轴承数据集和齿轮箱数据集上的实验,验证了FSM3模型的有效性。结果表明,我们的方法优于其他先进的方法,并提出了很大的鲁棒性。
背景知识:
监督分类任务 包含训练集(支持集)和测试(查询集);前者包含用于训练模型的已标记数据,后者包含同一领域的未标记数据,用于评估模型性能。
最新提出的小样本学习大多利用来自某个源域的辅助集来提取知识,以帮助目标领域中给定的少样本支持集的模型训练,如图b所示。辅助集包含大量标记数据,并且其标记空间与目标域的标记空间脱节。利用源领域数据的一种方法是随机抽样一系列少样本学习任务。从这些任务和分类模型之间的交互过程中提取可转移的知识,以促进目标领域的任务,这形成了episodic训练机制,在这里,每个少样本的学习任务被认为是一个episodic,整个过程也可以被视为元学习,因为学习是在任务级而不是数据级进行的。在本文中,不同的数据域可以被认为是不同的工作条件或故障类别。
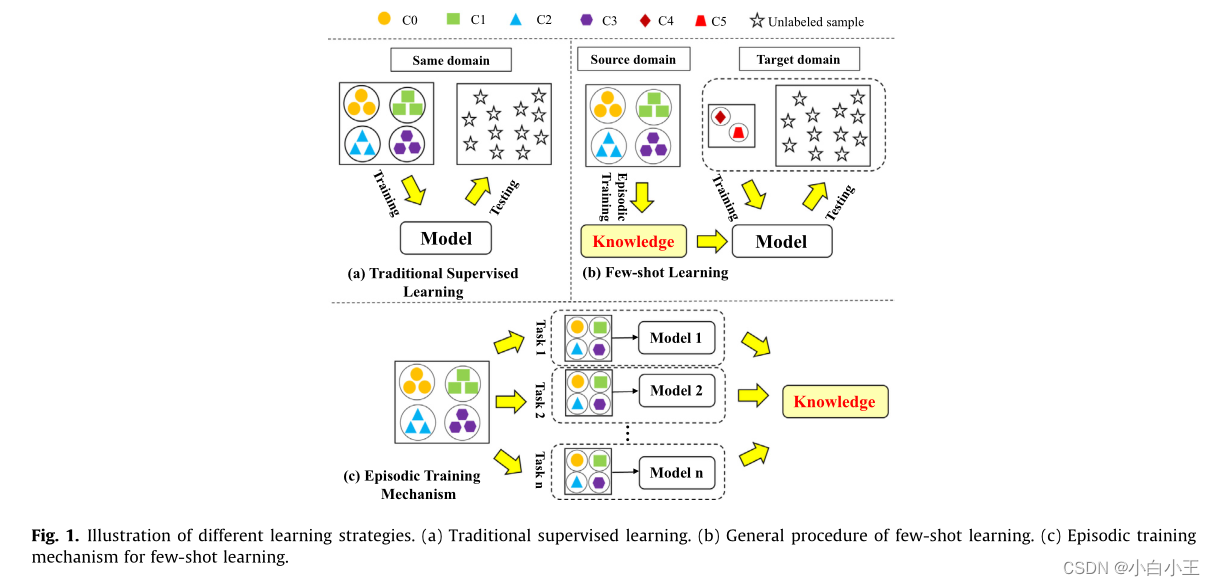
基于度量的元学习模型:试图学习一个统一的、独立于类别的特征空间,即样本的类内距离小于类间距离。查询样本根据它们到学习空间中每个支持样本的距离进行分类。(本文采用的方式)
基于优化的元学习模型:利用额外的可训练模型(元模型)来执行分类模型的参数更新,并且元模型被训练以通过在查询集上工作良好的有限支持集来生成合适的分类参数。
解决跨域问题的思想:通过最小化源域和目标域之间的分布差异学习高维数据上的共享特征
(基于数据驱动的方法:最大平均差异MMD和GAN,缺点:需要足够数据)
本文:提出一种基于度量的元学习模型,称为FSM3,它可以依靠学习源域的可转移知识来克服目标域的少样本学习问题。
模型构成:
FSM3:特征提取器(FE)、全局分类器(GC)、度量嵌入(ME)模块
输入:一维振动信号(机械振动波) 所以模型是一维卷积
FE:有5个卷积层,每个卷积后+Relu 在前四个卷积层中使用最大池化对特征进行下采样,将第一层的内核大小设置的很大
GC:由展平层和全连接层组成,其输出大小等于源数据域中的类别数。
ME:包含两个卷积层+展平层+全连接层,输出大小为100,将故障数据转换为100维特征用于度量学习。图中省略了展平层。
训练和评估过程:首先按照传统的监督学习用源域数据训练分类模型,然后固定特征提取器,并从以一系列小样本学习任务 以情节方式 训练度量嵌入模块,最后特征提取器和度量嵌入模块用于目标测试任务。
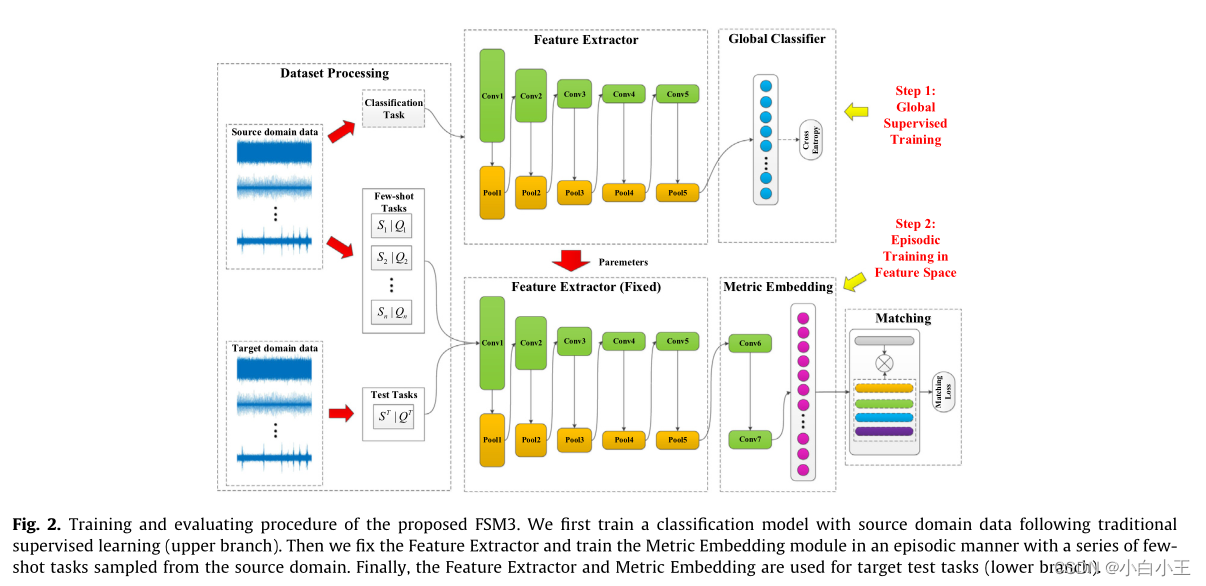
全局监督训练:
从源域抽取带标签的数据集Xs 以全局监督的方式,训练特征提取器FE,用函数fFE(.) 将故障数据输入到卷积,得到故障特征,特征被输入到全局分类器,随后是激活函数以获得可能性向量(用来表征输入数据属于每种故障类型的可能性)


特征空间的情景训练:
先从源域随机抽取一系列少样本故障诊断任务,通过预先训练好的特征提取器从所有原始故障数据中提取基本特征,提取的特征由度量嵌入模块进一步处理成度量特征,通过将查询样本的度量特征与支持特征进行匹配,从而对查询样本进行分类。

目标任务的评估
训练完成后,特征提取器和度量嵌入模块用于目标故障诊断任务,来自目标任务的所有样本被转移到基本特征空间,并进行相似性匹配工作,以支持有限的支持数据来预测查询数据的故障分类。
实验设置:
一样本学习:源域和目标域来自不同的工作条件(负载和速度);
在同一工况下,从不同类别中抽取源域和目标域,进行一样本学习;
5个样本学习的故障诊断对于解决1样本任务问题是个挑战。
对比的方法:

(1)到(4)基于在监督学习下用源域数据预训练FE + ME。
(1)和(2)然后在FE + ME之后附加新的分类器,并使用来自目标域的少量支持数据来分别微调最后一层(分类器)或整个模型。
(3)和(4)通过将从FE + ME主干提取的特征与支持样本或支持类原型的特征进行匹配,对目标数据进行分类。
(5)和(8)是以FE + ME为骨干的原始匹配网络和原型网络模型。整个模型完全是在原始数据空间中以情节的方式训练的。
(6)和(9)类似于(5)和(8),但是主干是用源数据预先训练的。
(7)和(10)是我们的MN和PN版本的模型,其中FE用监督学习训练,然后固定,ME以情节方式训练。
结果分析:
首先分析了不同工况下的1样本学习故障诊断问题。结果如表4所示,其中显示所有MN方法和特征Knn在这些任务中表现非常好,并且MN方法之间没有明显差异。这些结果表明,由变化的工作条件引起的不同领域的数据对之间的相似性是相对接近的,因此在这种情况下,一样本学习任务并不难解决。
Finetune Last: 基于监督学习下,利用源域预训练FE+ME,最后一层加分类器,用目标域的少量支持集去微调最后一层分类器
Finetune Whole: 基于监督学习下,利用源域预训练FE+MEFE + ME之后附加新的分类器,用目标域的少量支持集去微调整个模型;
Feature Knn: 基于监督学习下,利用源域预训练FE+ME从FE + ME主干提取的特征与支持样本的特征进行匹配,对目标数据进行分类;
DSMN:以FE + ME为骨干的原始匹配网络,整个模型完全是在原始数据空间中以情节的方式训练的.
DSMN-pre:FE + ME为骨干的原始匹配网络,FE + ME是用源数据预先训练的


结果:其中显示所有MN方法和特征Knn在这些任务中表现非常好,并且MN方法之间没有明显差异。这些结果表明,由变化的工作条件引起的不同领域的数据对之间的相似性是相对接近的,因此在这种情况下,一次性学习任务并不难解决。
表5显示了“最差IOB”、“滚珠”和“内圈”的单次任务的结果,这表明所有基于MN的方法在这三个单次任务中在4个不同的工作负荷下表现良好,甚至超过99%的准确度。由于“外环”场景的精度通常低于其他3种场景,我们在1样本和5样本设置中对其进行了测试。

结果如表6所示。这些结果证明,与其他基线方法相比,我们的FSM3性能最好,并且可以通过增加支持样本的数量来大大提高性能。很明显,负载2和负载3的精度高于低负载条件下的精度。我们认为,这种现象与源域区分故障类别的难易程度有关。源域中高负载的困难任务将提供训练有素的模型,这将极大地帮助目标域中使用的模型。否则,当源域为负载0或1时,模型更容易达到预期性能。这种模型不能为目标域中的少样本任务提供足够的支持。
受机制[7]的限制,我们只能在5次拍摄的情况下比较基于MN和基于PN的方法,结果证实这两种方法的性能非常接近,在某些条件下基于MN的方法更好


结论:本文将少样本学习引入到数据驱动的故障诊断领域,提出了一种新的多小数据条件下的少样本故障诊断方法FSM3。我们的方法的性能已经在轴承和齿轮箱数据集上进行了评估,其中在目标域中设置了1-shot和5-shot任务。从这些实验中可以得出四个结论:
1)与传统的基于finetune的方法相比,基于度量的元学习方法在两个数据集上都取得了更高的准确性;
2) 源域中难度较大的任务可以为目标域的深层模型提供更多可转移的知识,从而得到更有效的模型;
3) 在各种有限数据条件下,我们提出的FSM3在轴承和齿轮箱故障诊断的1样本和5样本学习上优于一系列基线方法,而FSM3-MN通常优于FSM3-PN;
4) 我们提议的FSM3的可行性相对较高。















 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









