









 本文介绍了一种利用周期振动表示动态场景特征的方法,提出了一种新的时间平滑机制和位置感知的自适应控制策略。通过结合图像、LiDAR点云和光学流,研究解决了如何处理动态场景中的时空一致性问题,特别强调了在自动驾驶等场景中动态元素的处理。
本文介绍了一种利用周期振动表示动态场景特征的方法,提出了一种新的时间平滑机制和位置感知的自适应控制策略。通过结合图像、LiDAR点云和光学流,研究解决了如何处理动态场景中的时空一致性问题,特别强调了在自动驾驶等场景中动态元素的处理。
1. What
What kind of thing is this article going to do (from the abstract and conclusion, try to summarize it in one sentence)
Utilizing periodic vibration-based temporal dynamics to represent the characteristics of various objects and elements in dynamic urban scenes. A novel temporal smoothing mechanism and a position-aware adaptive control strategy were also introduced to handle temporally coherent. Finish the reconstruction of dynamic scenes.
2. Why
Under what conditions or needs this research plan was proposed (Intro), what problems/deficiencies should be solved at the core, what others have done, and what are the innovation points? (From Introduction and related work)
Maybe contain Background, Question, Others, Innovation:
Introduction:
- NSG: Decomposes dynamic scenes into scene graphs
- PNF: Decomposes scenes into objects and backgrounds, incorporating a panoptic segmentation auxiliary task.
- SUDS: Use optical flow(Optical flow helps in identifying which parts of the scene are static and which are dynamic)
- EmerNeRF: Use a self-supervised method to reduce dependence on optical flow.
Related work:
- Dynamic scene models
- In one research direction, certain studies [2, 7, 11, 18, 38] introduce time as an additional input to the radiance field, treating the scene as a 6D plenoptic function. However, this approach couples positional variations induced by temporal dynamics with the radiance field, lacking geometric priors about how time influences the scene.
- An alternative approach [1, 20, 24–26, 33, 40] focuses on modeling the movement or deformation of specific static structures, assuming that the dynamics arise from these static elements within the scene.
- Gaussian-based
- Urban scene reconstruction
- One research avenue(NeRF-based) has focused on enhancing the modeling of static street scenes by utilizing scalable representations [19, 28, 32, 34], achieving high-fidelity surface reconstruction [14, 28, 39], and incorporating multi-object composition [43]. However, these methods face difficulties in handling dynamic elements commonly encountered in autonomous driving contexts.
- Another research direction seeks to address these challenges. Notably, these techniques require additional input, such as leveraging panoptic segmentation to refine the dynamics of reconstruction [PNF]. [Street Gaussians, Driving Gaussian] decompose the scene with different sets of Gaussian points by bounding boxes. However, they all need manually annotated or predicted bounding boxes and have difficulty reconstructing the non-rigid objects.
3. How
The input data contain images, represented as { I i , t i , E i , I i ∣ i = 1 , 2 , … N c } \{\mathcal{I}_{i},t_{i},\mathbf{E}_{i},\mathbf{I}_{i}|i=1,2,\ldots N_{c}\} {Ii,ti,Ei,Ii∣i=1,2,…Nc} and LiDAR point clouds represented as { ( x i , y i , z i , t i ) ∣ i = 1 , 2 , … N l } \{(x_i,y_i,z_i,t_i)|i=1,2,\ldots N_l\} {(xi,yi,zi,ti)∣i=1,2,…Nl}. The rendering process can be represented as I ^ = F θ ( E o , I o , t ) \hat{\mathcal{I}}=\mathcal{F}_{\theta}(\mathbf{E}_{o},\mathbf{I}_{o},t) I^=Fθ(Eo,Io,t), which shows the image at any timestamp t t t and camera pose ( E o , I o ) (\mathbf{E}_{o},\mathbf{I}_{o}) (Eo,Io).
3.1 PVG
The motivation behind this concept is to assign a distinct lifespan to each Gaussian
point, defining when it actively contributes and to what degree.
-
Overall pipeline:
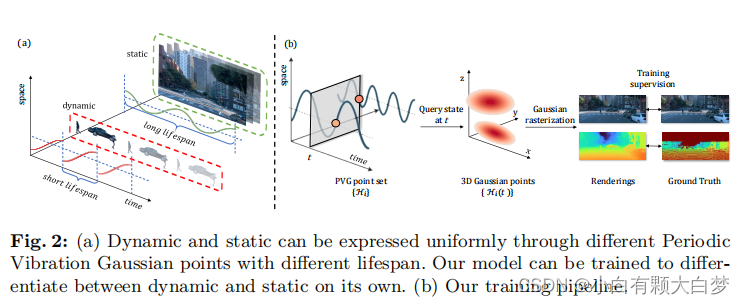
-
Mathematically,
The Gaussian model can be denoted as H ( t ) = { μ ~ ( t ) , q , s , o ~ ( t ) , c } , \mathcal H(t)=\{\widetilde{\boldsymbol\mu}(t),\boldsymbol q,\boldsymbol s,\widetilde o(t),\boldsymbol c\}, H(t)={μ (t),q,s,o (t),c}, where,
μ ~ ( t ) = μ + l 2 π ⋅ sin ( 2 π ( t − τ ) l ) ⋅ v o ~ ( t ) = o ⋅ e − 1 2 ( t − τ ) 2 β − 2 . \begin{aligned}\widetilde{\boldsymbol{\mu}}(t)&=\boldsymbol{\mu}+\frac{l}{2\pi}\cdot\sin(\frac{2\pi(t-\tau)}{l})\cdot\boldsymbol{v}\\\widetilde{o}(t)&=o\cdot e^{-\frac{1}{2}(t-\tau)^2\beta^{-2}}.\end{aligned} μ (t)o (t)=μ+2πl⋅sin(l2π(t−τ))⋅v=o⋅e−21(t−τ)2β−2.
These told me how the mean value and opacity change over time. And we list the parameters that need to be learned:
{ μ , q , s , o , c , τ , β , v } , \{\boldsymbol{\mu},\boldsymbol{q},\boldsymbol{s},o,\boldsymbol{c},\tau,\beta,\boldsymbol{v}\}, {μ,q,s,o,c,τ,β,v},
where τ \tau τ is the life span and v \boldsymbol{v} v is the velocity, indicating the direction and value at time t t t. Notice l l l is the scene prior that we don’t need to learn. -
Definition of staticness coefficient
We define ρ = β l \rho=\frac{\beta}{l} ρ=lβ to quantify the degree of staticness exhibited by a PVG point. In this formulation, β \beta β is the decay rate of opacity, which is positively related to lifespan, and l l l is a hyper-parameter as a prior. The dynamic aspects of a scene are particularly evident in points with small ρ. At a specific timestamp t t t, dynamic objects are more likely to be predominantly represented by points with τ \tau τ close to t t t.
3.2 Position-aware point adaptive control
The adaptive control method in the original Gaussian Splatting doesn’t fit the urban scene. So they use s \boldsymbol{s} s in the Gaussian model to adjust the size of Gaussian.
That is firstly defining a scale factor:
γ ( μ ) = { 1 if ∥ μ ∥ 2 < 2 r ∥ μ ∥ 2 / r − 1 if ∥ μ ∥ 2 ≥ 2 r \left.\gamma(\boldsymbol{\mu})=\left\{\begin{matrix}1&\text{if}\quad\|\boldsymbol{\mu}\|_2<2r\\\|\boldsymbol{\mu}\|_2/r-1&\text{if}\quad\|\boldsymbol{\mu}\|_2\geq2r\end{matrix}\right.\right. γ(μ)={1∥μ∥2/r−1if∥μ∥2<2rif∥μ∥2≥2r
Then compare m a x ( s ) max(s) max(s) with μ \boldsymbol{\mu} μ multiple a threshold g g g. If max ( s ) ≤ g ⋅ γ ( μ ) \max(\boldsymbol{s})\leq g\cdot\gamma(\boldsymbol{\mu}) max(s)≤g⋅γ(μ) the PVG points will clone and choose another threshold b b b to decide whether this point needs to be pruned.
3.3 Model training
-
Temporal smoothing by intrinsic motion
In PVG, individual points encompass only a narrow time window, resulting in constrained training data and an increased susceptibility to overfitting.
To eliminate the dependence on optical flow estimation, this paper introduces the average velocity metric:
v ˉ = d μ ~ ( t ) d t ∣ t = τ ⋅ exp ( − ρ 2 ) = v ⋅ exp ( − ρ 2 ) . \bar{\boldsymbol{v}}=\left.\frac{\mathrm d\widetilde{\boldsymbol{\mu}}(t)}{\mathrm dt}\right|_{t=\tau}\cdot\exp(-\frac{\rho}{2})=\boldsymbol{v}\cdot\exp(-\frac{\rho}{2}). vˉ=dtdμ (t) t=τ⋅exp(−2ρ)=v⋅exp(−2ρ).
Then considering that dynamic objects often maintain a constant speed
within a short time interval, so the update policy is:
H ^ ( t 2 ) = { μ ~ ( t 1 ) + v ˉ ⋅ Δ t , q , s , o ~ ( t 1 ) , c } . \widehat{\mathcal{H}}(t_2)=\{\widetilde{\boldsymbol{\mu}}(t_1)+\bar{\boldsymbol{v}}\cdot\Delta t,\boldsymbol{q},\boldsymbol{s},\widetilde{\boldsymbol{o}}(t_1),\boldsymbol{c}\}. H (t2)={μ (t1)+vˉ⋅Δt,q,s,o (t1),c}. -
Sky refinement
The calculation of color was corrected to:
C f = C + ( 1 − O ) C s k y , C_{f}=C+(1-O)C_{sky}, Cf=C+(1−O)Csky,
where O O O represents the rendered opacity. That is to say the remain opacity was filled by the sky. -
Loss function
L = ( 1 − λ r ) L 1 + λ r L s s i m + λ d L d + λ o L o + λ v ˉ L v ˉ \mathcal{L}=(1-\lambda_{r})\mathcal{L}_{1}+\lambda_{r}\mathcal{L}_{\mathrm{ssim}}+\lambda_{d}\mathcal{L}_{d}+\lambda_{o}\mathcal{L}_{o}+\lambda_{\bar{\boldsymbol{v}}}\mathcal{L}_{\bar{\boldsymbol{v}}} L=(1−λr)L1+λrLssim+λdLd+λoLo+λvˉLvˉ
It considers the impacts of the image, LiDAR, sky, and velocity.















 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









