









 文章讲述了如何在LinuxCentOS环境中使用Conda创建Python3.9环境,并安装PyOpenCL及其依赖。重点介绍了如何处理OpenCL实现的警告,包括使用pocl、oclgrind、IntelComputeRuntime等,以及如何通过ocl-icd-system整合已安装的NvidiaOpenCL运行时。最后,文章演示了如何验证OpenCL环境是否正确配置并执行计算任务。
文章讲述了如何在LinuxCentOS环境中使用Conda创建Python3.9环境,并安装PyOpenCL及其依赖。重点介绍了如何处理OpenCL实现的警告,包括使用pocl、oclgrind、IntelComputeRuntime等,以及如何通过ocl-icd-system整合已安装的NvidiaOpenCL运行时。最后,文章演示了如何验证OpenCL环境是否正确配置并执行计算任务。
前言
- 通常pyopencl与nvida的驱动版本没有严格的对应关系。我的驱动版本是530.41.03
- nvidia的显卡驱动默认携带opencl的运行时环境
环境:
linux:centos7.9 Linux xxx 4.18.0-372.9.1.el8.x86_64 #1 SMP Fri Apr 15 22:12:19 EDT 2022 x86_64 x86_64 x86_64 GNU/Linux
anaconda:Anaconda3-2022.10-Linux-x86_64
新建一个conda环境,安装以下3个包
python=3.9
ocl-icd-system
pyopencl=2022.1.1=py39hac2352c_0
当前conda环境完整包列表:
安装步骤:
首先安装python-3.9
conda install python=3.9
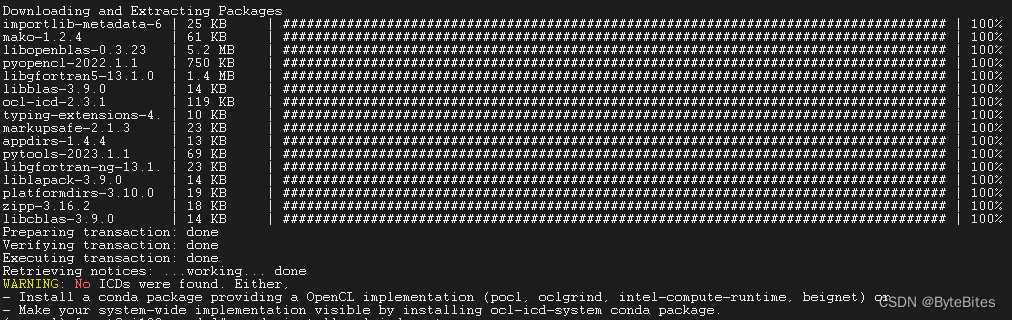
其次安装pyopencl=2022.1.1=py39hac2352c_0,这一步会显示警告:
conda install pyopencl=2022.1.1=py39hac2352c_0
什么意思?解释一下:
根据上面的conda命令的输出,我们成功地在名为"opencl"的conda环境中安装了pyopencl。但是在末尾,有一个警告提示我们当前没有任何OpenCL ICD(Installable Client Driver)可用。这意味着我们的系统上没有检测到OpenCL的实现。
为了运行PyOpenCL程序,我们需要一个OpenCL实现。有多种选择,取决于我们的硬件和需要:
pocl:这是一个纯CPU实现的OpenCL,意味着它不会利用GPU(如果我们有的话),但它是一个很好的起点,尤其是在没有GPU或不支持OpenCL的GPU的系统上。
安装命令:conda install pocl
oclgrind:这是一个OpenCL调试器,它提供了一个软件实现的OpenCL设备,用于程序的运行时检查。
安装命令:conda install oclgrind
intel-compute-runtime / beignet:这是针对Intel集成图形和一些老的Xeon处理器的OpenCL实现。
安装命令:
对于intel-compute-runtime:conda install intel-compute-runtime
对于beignet(老的Intel硬件):conda install beignet
ocl-icd-system:如果我们已经在我们的系统上安装了一个OpenCL实现(例如,通过NVIDIA或AMD的驱动程序),但conda无法看到它,我们可以尝试安装这个包来使其可见。
安装命令:conda install ocl-icd-system
选择适合我们的OpenCL实现并安装它。如果我们有一个支持OpenCL的GPU,我们可能还需要从该GPU的制造商那里获取和安装适当的驱动程序。
此处我们选择安装ocl-icd-system,因为我的机器上安装了nvidia的显卡驱动,它默认携带opencl运行时环境(这跟cuda不一样,运行cuda还需要额外安装toolkit)
最后安装ocl-icd-system
conda install ocl-icd-system
验证上面的告警是否解决
import pyopencl as cl
platforms = cl.get_platforms()
if not platforms:
print("No OpenCL platforms detected.")
else:
for platform in platforms:
print(f"Platform: {platform.name}")
devices = platform.get_devices()
for device in devices:
print(f" Device: {device.name}")
保存并运行

看到类似上图的输出则标明pyopencl已经找到opencl的实现,pyopencl环境正常
跑一个opencl程序吧
import numpy as np
import pyopencl as cl
# 创建两个numpy数组
a_np = np.array(range(10), dtype=np.float32)
b_np = np.array(range(10), dtype=np.float32)
c_np = np.empty_like(a_np)
# 创建OpenCL上下文和队列
platform = cl.get_platforms()[0]
device = platform.get_devices()[0]
context = cl.Context([device])
queue = cl.CommandQueue(context)
# 创建缓冲区
a_g = cl.Buffer(context, cl.mem_flags.READ_ONLY | cl.mem_flags.COPY_HOST_PTR, hostbuf=a_np)
b_g = cl.Buffer(context, cl.mem_flags.READ_ONLY | cl.mem_flags.COPY_HOST_PTR, hostbuf=b_np)
c_g = cl.Buffer(context, cl.mem_flags.WRITE_ONLY, a_np.nbytes)
# 创建并编译OpenCL程序
prg_src = """
__kernel void sum_arrays(__global const float* a, __global const float* b, __global float* c)
{
int gid = get_global_id(0);
c[gid] = a[gid] + b[gid];
}
"""
prg = cl.Program(context, prg_src).build()
# 执行OpenCL程序
prg.sum_arrays(queue, a_np.shape, None, a_g, b_g, c_g)
# 将结果从设备复制回主机
cl.enqueue_copy(queue, c_np, c_g)
# 打印结果
print("a:", a_np)
print("b:", b_np)
print("c:", c_np)
这个示例首先在主机端创建两个数组,然后在OpenCL设备上创建缓冲区来保存这些数组。接着,它定义并编译了一个OpenCL程序,该程序将两个数组中的元素相加。最后,这个程序在OpenCL设备上执行,并将结果复制回主机内存。
我们可以运行上述代码以验证我们的OpenCL环境是否工作正常。如果一切正常,我们应该会看到两个数组以及它们的和被打印出来。
保存并运行

如果你看到以上输出,恭喜你,你的opencl环境已经正确配置,并且能够执行计算!

















 280
280

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









